Continental-Scale Building Detection from High Resolution Satellite Imagery 제3-2부
3.1 Supervised learning and evaluation data
We collected a training set of 99,902 RGB satellite images of size 600×600 pixels, of locations across the African continent.
우리는 아프리카 대륙 전역의 위치에서 600×600 픽셀 크기의 RGB 위성 이미지 99,902개의 훈련 세트를 수집했습니다.
Figure 2 shows the geographical distribution of these images. Given data resources available to us, these were composed of two different sets with different geographical densities.
그림 2는 이러한 이미지의 지리적 분포를 보여줍니다. 우리에게 주어진 데이터 자원은 지리적 밀도가 다른 두 개의 다른 세트로 구성되었습니다.
The resulting training set has broad coverage across the continent, with particular concentrations of images for locations in East and West Africa.
결과 훈련 세트는 동부 및 서부 아프리카의 위치에 대한 특정 집중 이미지와 함께 대륙 전체에 걸쳐 광범위하게 적용됩니다.
Test locations were chosen according to more specific criteria. When sampling random locations across large areas, most images do not contain any buildings.
criteria 기준
테스트 위치는 보다 구체적인 기준에 따라 선택되었습니다. 넓은 지역에서 임의의 위치를 샘플링할 때 대부분의 이미지에는 건물이 포함되어 있지 않습니다.
In order to avoid having an evaluation set which was biased towards rural and empty areas, a set of 47 specific regions of interest was selected.
시골과 빈 지역에 편향된 평가 세트를 피하기 위해 47개의 특정 관심 지역 세트를 선택했습니다.
These were chosen to contain a mix of rural, medium-density and urban areas in different regions of the continent, including informal settlements in urban areas as well as refugee facilities.
refugee 난민 facilities 시설
이들은 도시 지역의 비공식 정착촌과 난민 시설을 포함하여 대륙의 여러 지역에 있는 농촌, 중밀도 및 도시 지역이 혼합된 지역을 포함하도록 선택되었습니다.

Examples of building labelling policy, taking into account characteristics of different areas across the African continent.
아프리카 대륙 전역의 다양한 지역 특성을 고려한 건물 라벨링 정책의 예.
(1) Example of a compound containing both dwelling places as well as smaller outbuildings such as grain stores: the smaller buildings should be ignored.
dwelling 주택, 거주지
(1) 주거지와 곡물 저장고와 같은 작은 별채를 모두 포함하는 복합 건물의 예: 작은 건물은 무시해야 합니다.
(2) Example of a round, thatched-roof structure which is difficult to distinguish from trees: use cues about pathways, clearings and shadows to disambiguate.
distinguish 구별하다
(2) 나무와 구별하기 어려운 둥근 초가 지붕 구조의 예: 경로, 공터 및 그림자에 대한 단서를 사용하여 명확하게 합니다.
(3) Example of internal shadow, indicating that this is an enclosure wall and not a building.
(3) 건물이 아닌 인클로저 벽임을 나타내는 내부 그림자의 예.
(4) Example of several contiguous buildings for which the boundaries cannot be distinguished, where the ‘dense buildings’ class should be used.
(4) 경계를 구분할 수 없는 여러 인접 건물의 예로서 '밀집한 건물' 등급을 사용해야 합니다.
The labelling policy was developed to take into account characteristic settings across the continent, with some examples shown in Figure 3.
레이블 지정 정책은 대륙 전체의 특성 설정을 고려하도록 개발되었으며 몇 가지 예가 그림 3에 나와 있습니다.
One challenge is the labelling of small buildings, as structures a few metres across can be close to the limit of detectability in 50 cm imagery.
detectability 탐지 가능성
한 가지 과제는 작은 건물의 라벨링이다. 가로 몇 미터 되는 구조물은 50cm 이미지에서 탐지 가능성의 한계에 근접할 수 있기 때문이다.
Another challenge is the labelling of buildings which are densely positioned in close proximity to each other.
densely 밀접한
또 다른 과제는 서로 밀접하게 밀집되어 있는 건물에 라벨을 붙이는 것입니다.
We introduced a dense building class for labelling, when a human annotator was not able to ascertain the exact boundary between individual buildings.
ascertain 알아내다 확인하다
우리는 인간 애노테이터가 개별 건물 사이의 정확한 경계를 확인할 수 없을 때 라벨링을 위해 밀집된 건물 클래스를 도입했습니다.
This is analogous to the crowd type in COCO [10]
이것은 COCO [10]의 군중 유형과 유사합니다.
3.2 Pre-training data
We generated further datasets of satellite imagery, with classification labels for alternative tasks which were used as the basis for representation learning experiments and pre-training.
우리는 표현 학습 실험 및 사전 훈련의 기초로 사용된 대체 작업에 대한 분류 레이블과 함께 위성 이미지의 추가 데이터 세트를 생성했습니다.
A convenient feature of satellite imagery is that every pixel is associated with a longitude and latitude, so that it can be linked to various other geospatial data.
위성 이미지의 편리한 기능은 모든 픽셀이 경도와 위도와 연결되어 다른 다양한 지리 공간 데이터와 연결할 수 있다는 것입니다.
For example, Jean et al. [11] demonstrated the use of nighttime lights data to be the basis of a pretext task, such that a model trained to predict how bright a location is at night from daytime imagery learns a representation of satellite imagery which helps as a starting point for other tasks.
예를 들어, Jean 외. [11]은 pretext task의 기초가 되는 야간 조명 데이터의 사용을 입증하여 낮 이미지에서 밤에 위치가 얼마나 밝은지 예측하도록 훈련된 모델이 다른 작업의 시작점으로 도움이 되는 위성 이미지 표현을 학습한다.
We sampled one million images of size 600×600 pixels, at 50 cm per pixel resolution from across the continent of Africa.
우리는 아프리카 대륙 전역에서 픽셀당 50cm 해상도로 600×600 픽셀 크기의 이미지 100만 개를 샘플링했습니다.
Sampling density was not completely uniform, as source imagery was limited e.g. within large deserts and other uninhabited areas.
소스 이미지가 제한되어 샘플링 밀도가 완전히 균일하지 않았습니다. 큰 사막 및 기타 무인 지역 내.
For each of these images, we computed information which could be used as pretext task labels.
이러한 각 이미지에 대해 pretext task 로 사용할 수 있는 정보를 계산했습니다.
We used the location of the image as a classification target, by binning the Earth’s surface into parcels of roughly equal area based on S2 geometry 2 , as shown in Figure 4.
그림 4와 같이 S2 기하학 2를 기반으로 지구 표면을 대략 동일한 면적의 구획으로 묶음으로써 이미지의 위치를 분류 대상으로 사용했습니다.
This gives us a classification task, in which the goal is to predict for an image patch which part of the world it comes from.
이것은 우리에게 세계의 어느 부분에서 오는 이미지 패치를 예측하는 것이 목표인 분류 작업을 제공합니다.
The intuition is that in order to obtain good performance on this task, a model might learn to distinguish different vegetation, architectural or geographical features.
직관은 이 작업에서 좋은 성능을 얻기 위해 모델이 다양한 식물, 건축 또는 지리적 특징을 구별하는 방법을 학습할 수 있다는 것입니다.
We also computed nighttime lights data, using DMSP OLS sensor data.
또한 DMSP OLS 센서 데이터를 사용하여 야간 조명 데이터를 계산했습니다.
This data is computed by averaging nighttime light luminance over the course of a year, in order to correct for temporal factors such as cloud cover.
luminance 밝기
이 데이터는 구름 덮개와 같은 시간적 요인을 보정하기 위해 1년 동안 야간 조명 휘도를 평균하여 계산됩니다.
Following the methodology in [12], we binned the luminance values into four classes, and also retained the original values.
[12]의 방법론에 따라 휘도 값을 4개의 클래스로 비닝하고 원래 값도 유지했습니다.
Using this as a supervision label predisposes the model to pay attention to human-constructed features such as buildings, which emit light.
이것을 감독 레이블로 사용하면 모델이 건물과 같이 빛을 방출하는 사람이 만든 기능에 주의를 기울이게 됩니다.
The methods used to create pre-trained checkpoints with these datasets are described in Section 7.
이러한 데이터 세트로 사전 훈련된 체크포인트를 생성하는 데 사용되는 방법은 섹션 7에 설명되어 있습니다.
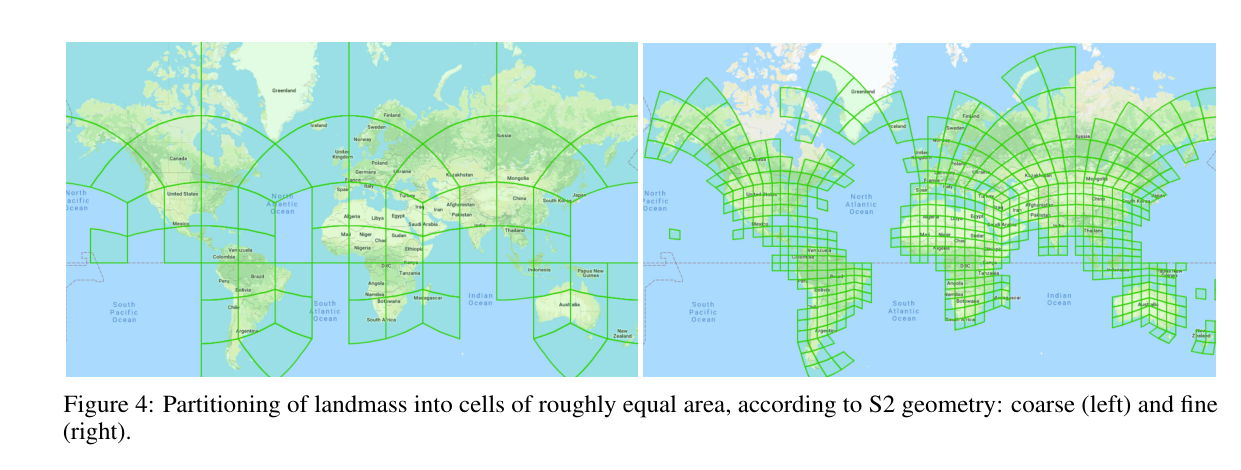
Partitioning of landmass into cells of roughly equal area, according to S2 geometry: coarse (left) and fine (right).
S2 기하학에 따라 대략적으로 동일한 면적의 셀로 육지를 분할: 거친(왼쪽) 및 미세(오른쪽).
3.3 Self-training data
This unlabeled dataset was created by sampling 100M 640×640 pixel satellite images from the African continent.
이 레이블이 지정되지 않은 데이터 세트는 아프리카 대륙에서 1억 640×640 픽셀의 위성 이미지를 샘플링하여 생성되었습니다.
More than 90% of images contained no buildings, therefore we subsampled the dataset using our best supervised model, so that only around of images did not contain buildings.
이미지의 90% 이상이 건물을 포함하지 않았으므로 최상의 지도 모델을 사용하여 데이터 세트를 서브샘플링하여 이미지 주변에만 건물이 포함되지 않도록 했습니다.
The final dataset after filtering contained 8.7M images.
필터링 후 최종 데이터 세트에는 870만 이미지가 포함되었습니다.
3.4 Additional evaluation data
This sparsely labeled dataset contains 0.9M 448×448 pixel satellite images from the African continent and is a by-product of the internal Google Maps evaluation process.
이 희박하게 레이블이 지정된 데이터 세트는 아프리카 대륙의 0.9M 448×448픽셀 위성 이미지를 포함하고 있으며 내부 구글 맵 평가 프로세스의 부산물이다.
Each image is centered on one building detection (not necessarily from our model), and therefore contains a mixture of images with buildings and images with features that are easily confused as buildings, such as rocks or vegetation.
각 이미지는 하나의 건물 감지에 중심을 두고 있으므로(반드시 우리 모델이 아님) 건물이 있는 이미지와 바위나 초목과 같이 건물로 쉽게 혼동될 수 있는 특징이 있는 이미지가 혼합되어 있습니다.
For each image, a human evaluator assessed whether that central point contains a building.
각 이미지에 대해 평가자는 해당 중앙 지점에 건물이 포함되어 있는지 여부를 평가했습니다.
If so, they created a label with the footprint of that single building, and if not the label is empty.
그렇다면 해당 단일 건물의 발자국으로 레이블을 만들었으며 그렇지 않은 경우 레이블이 비어 있습니다.
Around of the images in this dataset were centered on non-buildings.
이 데이터 세트의 이미지 주변은 건물이 아닌 것을 중심으로 했습니다.
This dataset can therefore be used for estimating precision, but not recall.
따라서 이 데이터 세트는 정밀도를 추정하는 데 사용할 수 있지만 회수는 할 수 없습니다.
It has good coverage of the African continent, but due to the sampling process, the density of images does not match the real building density in all locations.
아프리카 대륙을 잘 커버하지만 샘플링 프로세스로 인해 이미지 밀도가 모든 위치에서 실제 건물 밀도와 일치하지 않습니다.
See Section 11 for how we used this dataset.
이 데이터 세트를 사용하는 방법은 섹션 11을 참조하세요.
