Continental-Scale Building Detection from High Resolution Satellite Imagery 제4부
4 Model
Our experiments are based on the U-Net model [1], which is commonly used for segmentation of satellite images.
우리의 실험은 위성 이미지의 분할에 일반적으로 사용되는 U-Net 모델[1]을 기반으로 합니다.
As this is a semantic segmentation model, we use it to classify each pixel in an input image as building or non-building.
이것은 의미론적 분할 모델이므로 입력 이미지의 각 픽셀을 건물 또는 비건물로 분류하는 데 사용합니다.
To convert this to an instance segmentation, we threshold the predictions at some confidence level, and search for connected components (shown in Figure 1, where we convert from pixel-wise confidences in panels (b) and (e) to detected instances in panels (c) and (f)).
이를 인스턴스 세분화로 변환하기 위해 일부 신뢰 수준에서 예측을 임계값으로 설정하고 연결된 구성 요소를 검색합니다(그림 1 참조: 패널 (b) 및 (e)의 픽셀 단위 신뢰도에서 패널 (c) 및 (f)의 감지된 인스턴스로 변환).
U-Net is an encoder-decoder architecture, and we use an encoder based on ResNet-50-v2 [13].
U-Net은 인코더-디코더 아키텍처이며 우리는 ResNet-50-v2[13] 기반의 인코더를 사용합니다.
Preliminary experiments with ResNet-v2-101 and ResNet-v2-152 suggested that deeper encoder architectures did not improve accuracy.
preliminary 사전의 예비의
ResNet-v2-101 및 ResNet-v2-152에 대한 예비 실험은 더 깊은 인코더 아키텍처가 정확도를 향상시키지 않았음을 시사했다.
Residual decoder
U-Net [1] and TernausNet-v2 [4] both employ simple decoder blocks consisting of two (UNet) or one (TernausNet-v2) convolutional layer(s) and an upconvolution (also known as transposed convolution or deconvolution) for upscaling the feature map by a factor of 2.
U-Net [1] 및 TernausNet-v2 [4] 모두 피처 맵을 2 배 업스케일링하기 위해 2 (UNet) 또는 하나 (TernausNet-v2) 컨볼루션 레이어 (들) 및 업컨볼루션 (전이 컨볼루션 또는 디컨볼루션이라고도 함)으로 구성된 간단한 디코더 블록을 사용합니다.
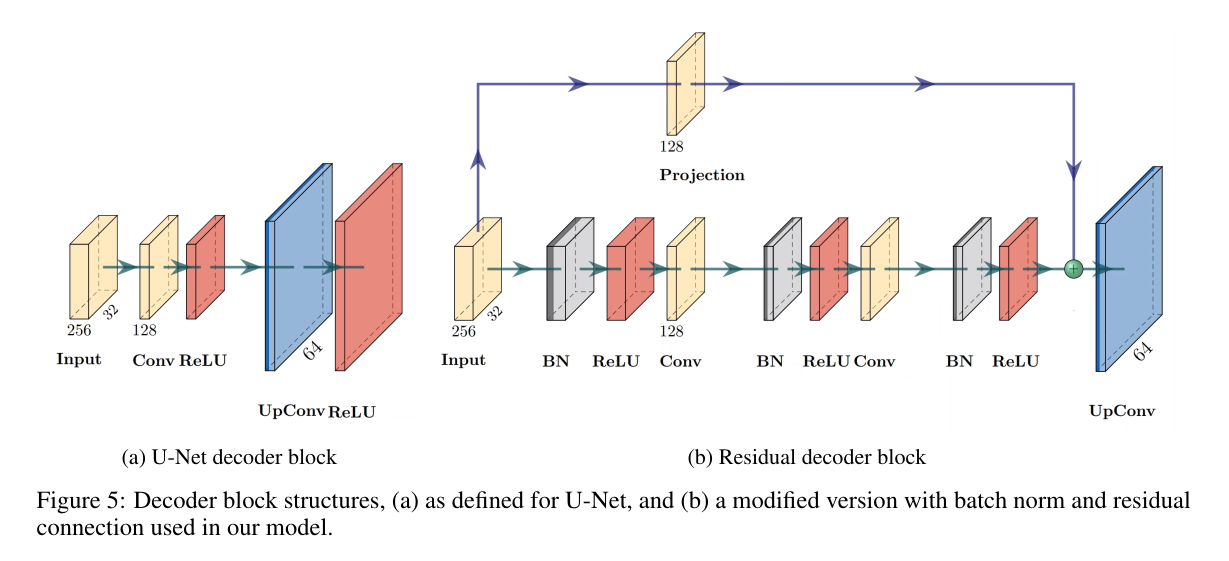
Figure 5: Decoder block structures, (a) as defined for U-Net, and (b) a modified version with batch norm and residual connection used in our model.
그림 5: 디코더 블록 구조, (a) U-Net에 대해 정의된 대로, (b) 모델에 사용된 배치 표준 및 잔여 연결이 있는 수정된 버전.
