Contrastive Embedding for Generalized Zero-Shot Learning 제 2부
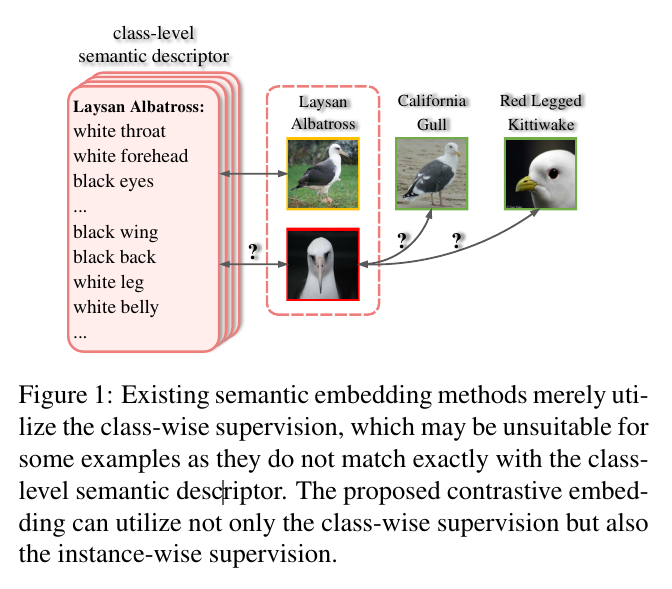
Existing semantic embedding methods merely utilize the class-wise supervision, which may be unsuitable for some examples as they do not match exactly with the classlevel semantic descriptor.
merely 단지, 그저
기존의 의미 임베딩 방법은 단지 클래스별 감독을 활용하는데, 이는 클래스 수준 의미 설명자와 정확히 일치하지 않기 때문에 일부 예제에 적합하지 않을 수 있다.
The proposed contrastive embedding can utilize not only the class-wise supervision but also the instance-wise supervision.
제안된 대조 임베딩은 클래스별 감독뿐만 아니라 인스턴스별 감독을 활용할 수 있습니다.
Introduction
Object recognition is a core problem in computer vision.
물체 인식은 컴퓨터 비전의 핵심 문제입니다.
This problem on a fixed set of categories with plenty of training samples has progressed tremendously due to the ad-vent of deep convolutional neural networks [37].
advent 도래, 출현 tremendously 엄청나게
많은 훈련 샘플이 있는 고정 범주 집합에서 이 문제는 심층 컨볼루션 신경망의 출현으로 인해 엄청나게 진전되었다[37].
However, realistic object categories often follow a long-tail distribution, where some categories have abundant training samples and the others have few or even no training samples available.
그러나 실제 객체 범주는 종종 롱테일 분포를 따르며, 일부 범주에는 훈련 샘플이 풍부하고 다른 범주에는 사용 가능한 훈련 샘플이 거의 또는 전혀 없습니다.
Recognizing the long-tail distributed object categories is challenging, mainly because of the imbalanced training sets of these categories.
롱테일 분산 객체 범주를 인식하는 것은 주로 이러한 범주의 불균형한 훈련 세트로 인해 어렵습니다.
Zero-Shot Learning (ZSL) [39, 54] holds the promise of tackling the extreme data imbalance between categories, thus showing the potential of addressing the long-tail object recognition problem.
ZSL(Zero-Shot Learning) [39, 54]은 범주 간의 극단적인 데이터 불균형을 해결하여 롱테일 객체 인식 문제를 해결할 수 있는 가능성을 보여줍니다.
Zero-shot learning aims to classify objects from previously unseen categories without requiring the access to data from those categories.
Zero-shot learning은 이전에 볼 수 없었던 범주의 데이터에 액세스할 필요 없이 해당 범주의 객체를 분류하는 것을 목표로 합니다.
In ZSL, a recognition model is first learned on the seen categories, of which the training samples are provided.
ZSL에서 인식 모델은 먼저 보이는 범주에 대해 학습되며 그 중 훈련 샘플이 제공됩니다.
Relying on the category-level semantic descriptors, such as visual attributes [16, 39] or word vectors [47, 48], ZSL can transfer the recognition model from seen to unseen object categories in a data-free manner.
시각적 속성[16, 39] 또는 단어 벡터[47, 48]와 같은 범주 수준 의미 설명자에 의존하는 ZSL은 데이터가 없는 방식으로 인식 모델을 보이는 객체 범주에서 보이지 않는 객체 범주로 전송할 수 있습니다.
In zero-shot learning, we have the available data from seen classes for training.
제로샷 학습에서는 훈련을 위해 본 클래스에서 사용 가능한 데이터가 있습니다.
Conventional zero-shot learn-ing [1, 62] assumes that the test set contains the samples from unseen classes only, while in the recent proposed Generalized Zero-Shot Learning (GZSL) [10, 71], the test set is composed of the test samples from both seen and unseen classes.
기존의 제로샷 학습[1, 62]은 테스트 세트가 보이지 않는 클래스의 샘플만 포함한다고 가정하는 반면, 최근 제안된 일반화 제로샷 학습(GZSL)[10, 71]에서 테스트 세트는 다음으로 구성됩니다. 보이는 클래스와 보이지 않는 클래스의 테스트 샘플.
A large body of conventional ZSL methods learns a semantic embedding function to map the visual features into the semantic descriptor space [18, 2, 58, 75, 22].
기존 ZSL 방법의 대부분은 시각적 특징을 의미론적 설명자 공간으로 매핑하기 위해 의미론적 임베딩 기능을 학습한다[18, 2, 58, 75, 22].
In the semantic space, we can conduct the ZSL classification by directly comparing the embedded data points with the given class-level semantic descriptors.
의미 공간에서 임베디드 데이터 포인트를 주어진 클래스 수준 의미 설명자와 직접 비교하여 ZSL 분류를 수행할 수 있습니다.
Semantic embedding methods excel in conventional ZSL, yet their performance degrades substantially in the more challenging GZSL scenario, owing to their serious bias towards seen classes in the testing phase [69].
excel 뛰어나다 degrade 저하시키다 substantially 상당히 , scenario 시나리오
의미론적 임베딩 방법은 기존의 ZSL에서 우수하지만 테스트 단계에서 보이는 클래스에 대한 심각한 편향으로 인해 더 까다로운 GZSL 시나리오에서는 성능이 크게 저하된다[69].
Conventional ZSL is unnecessary to worry about the bias problem towards seen classes as they are excluded from the testing phase.
기존의 ZSL은 테스트 단계에서 제외되기 때문에 보이는 클래스에 대한 편향 문제에 대해 걱정할 필요가 없습니다.
But in GZSL the bias towards seen classes will make the GZSL model misclassify the testing images from unseen classes.
toward ~쪽으로, 향하여
그러나 GZSL에서 보이는 클래스에 대한 편향은 GZSL 모델이 보이지 않는 클래스의 테스트 이미지를 잘못 분류하게 만듭니다.
To mitigate the bias problem in GZSL, feature generation based GZSL methods have been proposed [7, 50, 38, 70, 72, 61] to synthesize the training samples for unseen classes.
mitigate 완화시키다 synthesize 합성하다
GZSL의 편향 문제를 완화하기 위해 보이지 않는 클래스에 대한 훈련 샘플을 합성하기 위해 기능 생성 기반 GZSL 방법[7, 50, 38, 70, 72, 61]이 제안되었다.
The feature generation method can compensate for the lack of training samples of unseen classes.
compensate 보상하다, 보안하다
특징 생성 방법은 보이지 않는 클래스의 훈련 샘플 부족을 보완할 수 있습니다.
Merging the real seen training features and the synthetic unseen features yields a fully-observed training set for both seen and unseen classes.
실제 보이는 훈련 기능과 보이지 않는 합성 기능을 병합하면 보이는 클래스와 보이지 않는 클래스 모두에 대해 완전히 관찰된 훈련 세트가 생성됩니다.
Then we can train a supervised model, such as a softmax classifier, to implement the GZSL classification.
implement 시행하다, 이행하다
그런 다음 GZSL 분류를 구현하기 위해 softmax 분류기와 같은 지도 모델을 훈련할 수 있습니다.
However, the feature generation methods produce the synthesized visual features in the original feature space.
그러나 특징 생성 방법은 원래 특징 공간에서 합성된 시각적 특징을 생성합니다.
We conjecture that the original feature space, far from the semantic information and thus lack of discriminative ability, is suboptimal for GZSL classification.
conjecture 추측하다 suboptimal 차선의
우리는 의미 정보와는 거리가 멀고 따라서 차별적 능력이 없는 원래의 특징 공간이 GZSL 분류에 차선책이라고 추측한다.
To get the best of both worlds, in this paper, we propose a hybrid GZSL framework, grafting an embedding model on top of a feature generation model.
grafting 접목
두 세계의 장점을 최대한 활용하기 위해 이 논문에서는 기능 생성 모델 위에 임베딩 모델을 접목한 하이브리드 GZSL 프레임워크를 제안합니다.
In our framework, we map both the real seen features and the synthetic unseen features produced by the feature generation model to a new embedding space.
synthetic 합성의
우리의 프레임워크에서 우리는 실제 보이는 특징과 특징 생성 모델에 의해 생성된 합성 보이지 않는 특징을 새로운 임베딩 공간에 매핑합니다.
We perform the GZSL classification in the new embedding space, but not in the original feature space.
새로운 임베딩 공간에서 GZSL 분류를 수행하지만 원래 기능 공간에서는 수행하지 않습니다.
Instead of adopting the commonly-used semantic embedding model [18, 2], we propose a contrastive embedding in our hybrid GZSL framework.
일반적으로 사용되는 의미적 임베딩 모델[18, 2]을 채택하는 대신 하이브리드 GZSL 프레임워크에서 대조적 임베딩을 제안합니다.
The traditional semantic embedding in ZSL relies on a ranking loss, which requires the correct (positive) semantic descriptor to be ranked higher than any of wrong (negative) descriptors with respect to the embedding of a training sample.
ZSL의 전통적인 의미 임베딩은 순위 손실에 의존하며, 이는 훈련 샘플 임베딩과 관련하여 올바른(긍정적인) 의미 설명자가 잘못된(부정적인) 설명자보다 높은 순위를 매길 것을 요구한다.
The semantic embedding methods only utilize the class-wise supervision.
시맨틱 임베딩 방법은 클래스별 감독만 활용합니다.
In contrastive embedding, we wish to exploit not only the class-wise supervision but also the instance-wise supervision for GZSL, as depicted in Figure 1.
대조 임베딩에서, 우리는 그림 1에 설명된 것처럼 GZSL에 대한 클래스별 감독뿐만 아니라 인스턴스별 감독도 활용하고자 한다.
Our proposed contrastive embedding learns to discriminate between one positive sample (or semantic descriptor) and a large number of negative samples (or semantic descriptors) from different classes by leveraging the contrastive loss [24, 53, 67].
우리가 제안한 대조 임베딩은 대조 손실을 활용하여 다른 클래스에서 하나의 긍정적인 샘플(또는 의미론적 설명자)과 많은 수의 부정적인 샘플(또는 의미론적 설명자)을 구별하는 방법을 학습합니다[24, 53, 67].
We evaluate our method on five benchmark datasets, and to the best of our knowledge, our method can outperform the state-of-the-arts on three datasets by a large margin and achieve competitive results on the other two datasets.
우리는 5개의 벤치마크 데이터 세트에서 우리의 방법을 평가하고 우리가 아는 한 우리의 방법은 3개의 데이터 세트에서 최신 기술을 크게 능가하고 다른 두 데이터 세트에서 경쟁력 있는 결과를 얻을 수 있습니다.
Our contributions are three-fold: (1) we propose a hybrid GZSL framework combining the embedding based model and the feature generation based model; (2) we propose a contrastive embedding, which can utilize both the classwise supervision and the instance-wise supervision, in our hybrid GZSL framework; and (3) we evaluate our GZSL model on five benchmarks and our method can achieve the state-of-the-arts or competitive results on these datasets.
우리의 기여는 세 가지입니다. (1) 임베딩 기반 모델과 기능 생성 기반 모델을 결합한 하이브리드 GZSL 프레임워크를 제안합니다. (2) 하이브리드 GZSL 프레임워크에서 클래스별 감독과 인스턴스별 감독을 모두 사용할 수 있는 대조 임베딩을 제안합니다. (3) 우리는 5가지 벤치마크에서 GZSL 모델을 평가하고 우리의 방법은 이러한 데이터 세트에서 최첨단 또는 경쟁력 있는 결과를 얻을 수 있습니다.
