En-Compactness: Self-Distillation Embedding & Contrastive Generation for Generalized Zero-Shot Learning 제 2부
Introduction
Image classification tasks relying on large amounts of labeled data [6, 16, 23] have made tremendous progress due to the advancement of deep learning [13, 21, 55].
많은 양의 레이블이 지정된 데이터에 의존하는 이미지 분류 작업[6, 16, 23]은 딥 러닝의 발전으로 인해 엄청난 발전을 이루었습니다[13, 21, 55].
However, the data hunger nature of deep models leads them to perform unsatisfyingly when some categories have scarce or even no labeled data [47].
그러나 심층 모델의 데이터 기아 특성은 일부 범주에 레이블이 지정된 데이터가 부족하거나 아예 없을 때 불만족스럽게 수행하게 됩니다[47].
Zero-Shot Learning (ZSL) [24, 35] is proposed to tackle this data absence issue by recognizing objects from unseen classes.
ZSL(Zero-Shot Learning)[24, 35]은 보이지 않는 클래스의 객체를 인식하여 이러한 데이터 부재 문제를 해결하기 위해 제안되었습니다.
They first learn a classification model on the seen classes, of which the training samples are provided, then transfer the model to unseen classes using the class-level semantic descriptors [10, 24, 31, 32], such as visual attributes [10, 24] or word vectors [31, 32].
transfer 전송하다
그들은 먼저 훈련 샘플이 제공되는 보이는 클래스에 대한 분류 모델을 학습한 다음 시각적 속성 [10, 24] 또는 단어 벡터 [31, 32]와 같은 클래스 수준의 의미 설명자 [10, 24, 31, 32]를 사용하여 모델을 보이지 않는 클래스에 전송한다.
Unlike ZSL, Generalized Zero-Shot Learning (GZSL) [7, 50] has been proposed to identify test samples from both seen and unseen classes, which is more challenging.
identify 확인하다, 식별하다
ZSL과 달리 GZSL(Generalized Zero-Shot Learning)[7, 50]은 보이는 클래스와 보이지 않는 클래스 모두에서 테스트 샘플을 식별하기 위해 제안되었으며 이는 더 어렵습니다.
Since the training set only contains seen classes samples, during testing, GZSL methods tend to misclassify unseen classes samples into seen classes, which is the widespread strong bias problem.
widespread 널리문제
훈련 세트에는 보이는 클래스 샘플만 포함되어 있기 때문에 테스트 중에 GZSL 방법은 보이지 않는 클래스 샘플을 보이는 클래스로 잘못 분류하는 경향이 있는데, 이는 널리 퍼진 강한 편향 문제입니다.
Recently, feature generation based GZSL methods [11, 14, 15, 26, 28, 38] have been proposed to mitigate the strong bias problem by synthesizing training samples for unseen classes conditioned on the semantic descriptors.
최근에 특징 생성 기반 GZSL 방법[11, 14, 15, 26, 28, 38]이 의미론적 디스크립터를 조건으로 하는 보이지 않는 클래스에 대한 훈련 샘플을 합성함으로써 강한 편향 문제를 완화하기 위해 제안되었습니다.
Merging the real seen training features and the synthetic unseen features, they obtain a fully-observed dataset to train a GZSL classification model, such as a softmax classifier.
실제 보이는 훈련 기능과 보이지 않는 합성 기능을 병합하여 softmax 분류기와 같은 GZSL 분류 모델을 훈련하기 위해 완전히 관찰된 데이터 세트를 얻습니다.
Early feature generation methods [11, 26, 28, 38] synthesize features in the visual features space which lacks of discriminative ability [8,14].
초기 특징 생성 방법[11, 26, 28, 38]은 식별 능력이 부족한 시각적 특징 공간에서 특징을 합성한다[8,14].
Lately, some methods [14,15] search for a new embedding space based on the inter-class relationships for GZSL classifier training.
최근에 몇몇 방법[14,15]은 GZSL 분류기 훈련을 위해 클래스 간 관계를 기반으로 새로운 임베딩 공간을 검색합니다.
Specifically, RFF-GZSL [15] maps the visual features into a redundancy-free space and uses center loss [48] to strengthen seen classes relationships in that space.
redundancy 중복
특히, RFF-GZSL[15]은 시각적 특징을 중복이 없는 공간에 매핑하고 중심 손실[48]을 사용하여 해당 공간에서 보이는 클래스 관계를 강화합니다.
CE-GZSL [14] conducts instance-level and class-level contrastive supervision to improve the discrimination of the embedding space.
CE-GZSL[14]은 임베딩 공간의 식별을 개선하기 위해 인스턴스 수준 및 클래스 수준 대조 감독을 수행합니다.
However, in the above methods, the embedding space is strictly constrained by the relationships between seen classes, which is unfriendly to the synthetic unseen classes features.
unfriendly 비우호적
그러나 위의 방법에서 임베딩 공간은 보이는 클래스 간의 관계에 의해 엄격하게 제한되어 합성 보이지 않는 클래스 기능에 비우호적입니다.
Moreover, the synthetic features of unseen classes have various distributions, as a consequence, mapping them into the embedding space will form confusing distributions.
더욱이, 보이지 않는 클래스의 합성 기능은 다양한 분포를 가지므로 결과적으로 포함 공간에 매핑하면 혼란스러운 분포가 형성됩니다.
As depicted in Fig1 (a), the embeddings of seen classes have large inter-class distances, while the unseen classes embeddings are overlapping and lack of discrimination.
그림 1(a)에서 볼 수 있듯이 보이는 클래스의 임베딩은 클래스 간 거리가 큰 반면 보이지 않는 클래스의 임베딩은 겹치고 식별이 부족합니다.
Therefore, training the GZSL classifier in this kind of embedding space will end with inferior performance.
inferior 낮은, 더 낮은
따라서 이러한 종류의 임베딩 공간에서 GZSL 분류기를 훈련하면 성능이 저하됩니다.
Instead, as the intra-class relationships are class-independent, if we strengthen these relationships of seen classes, the embedding space can also separate different classes but with better generalization ability on unseen classes.
대신 클래스 내 관계가 클래스 독립적이므로 본 클래스의 이러한 관계를 강화하면 임베딩 공간이 다른 클래스를 분리할 수도 있지만 보이지 않는 클래스에 대한 일반화 능력이 향상됩니다.
As depicted in Fig1 (b), although the inter-class relationships are not highly restricted, a compact intra-class distribution can help all the classes (seen and unseen) distinguish from each other.
그림 1(b)에 도시된 바와 같이, 클래스 간 관계가 크게 제한되지는 않지만 컴팩트한 클래스 내 분포는 모든 클래스(보이는 것과 보이지 않는)를 서로 구별하는 데 도움이 될 수 있습니다.
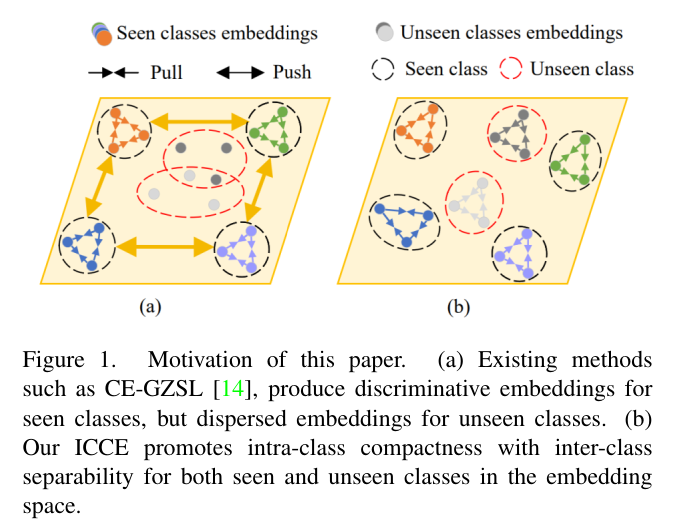
Motivation of this paper. (a) Existing methods such as CE-GZSL [14], produce discriminative embeddings for seen classes, but dispersed embeddings for unseen classes.
dispersed 분산된
이 논문의 동기. (a) CE-GZSL[14]과 같은 기존 방법은 보이는 클래스에 대해 차별적인 임베딩을 생성하지만 보이지 않는 클래스에 대해서는 분산 임베딩을 생성합니다.
(b) Our ICCE promotes intra-class compactness with inter-class separability for both seen and unseen classes in the embedding space.
separability 분리성
(b) ICCE는 임베딩 공간에서 보이는 클래스와 보이지 않는 클래스 모두에 대한 클래스 간 분리성을 통해 클래스 내 압축성을 촉진합니다.
In this paper, we propose an Intra-Class Compactness Enhancement method (ICCE) for GZSL.
본 논문에서는 GZSL을 위한 ICCE(Intra-Class Compactness Enhancement) 방법을 제안한다.
Our ICCE promotes intra-class compactness with inter-class separability on both seen and unseen classes in the embedding space and visual feature space.
우리의 ICCE는 임베딩 공간과 시각적 특징 공간에서 보이는 클래스와 보이지 않는 클래스 모두에 대한 클래스 간 분리성을 통해 클래스 내 압축성을 촉진합니다.
By putting more emphasis on intra-class relationships but the inter-class structures, we can distinguish different classes with better generalization.
클래스 내 관계가 아닌 클래스 간 구조에 더 중점을 둠으로써 더 나은 일반화로 다른 클래스를 구별할 수 있습니다.
Specifically, we produce compact intra-class distributions via a Self-Distillation Embedding (SDE) module and a Semantic-Visual Contrastive Generation (SVCG) module.
특히, SDE(Self-Distillation Embedding) 모듈과 SVCG(Semantic-Visual Contrastive Generation) 모듈을 통해 콤팩트한 클래스 내 분포를 생산합니다.
The SDE module is built with a teacher-student structure, which aligns the representations and the predicted logits between two different samples from the same class.
SDE 모듈은 동일한 클래스의 서로 다른 두 샘플 간의 표현과 예측된 로짓을 정렬하는 교사-학생 구조로 구축되었습니다.
Using SDE, we can reduce the intra-class variations and obtain compact distribution for each class in the embedding space.
SDE를 사용하여 클래스 내 변동을 줄이고 임베딩 공간의 각 클래스에 대한 압축 분포를 얻을 수 있습니다.
The SVCG module is a conditional GAN, which synthesizes compact distributed features for unseen classes in the visual feature space with instance-wise semanticvisual contrastive loss.
SVCG 모듈은 조건부 GAN으로, 시각적 기능 공간에서 보이지 않는 클래스에 대한 압축 분산 기능을 인스턴스별 의미 론적 대조 손실과 합성합니다.
The experiments demonstrate that our ICCE outperforms the state-of-the-arts on four datasets and achieves competitive results on the remaining dataset.
실험은 우리 ICCE가 4개의 데이터 세트에서 최첨단 기술을 능가하고 나머지 데이터 세트에서 경쟁력 있는 결과를 달성한다는 것을 보여줍니다.
