MPViT : Multi-Path Vision Transformer for Dense Prediction 제2부
1. Introduction
Since its introduction, the Transformer [48] has had a huge impact on natural language processing (NLP) [4, 13, 39]. Likewise, the advent of Vision Transformer (ViT) [15] has moved the computer vision community forward. As a result, there has been a recent explosion in Transformerbased vision works, spanning tasks such as static image classification [16, 33, 45, 46, 52, 53, 59, 60], object detection [5, 11, 63], and semantic segmentation [49, 57] to temporal tasks such as video classification [1, 3, 17] and object tracking [7, 37, 51].
Transformer[48]는 도입 이후 자연어 처리(NLP)[4, 13, 39]에 큰 영향을 미쳤습니다. 마찬가지로 ViT(Vision Transformer)[15]의 출현은 컴퓨터 비전 커뮤니티를 발전시켰습니다. 그 결과 최근 정적 이미지 분류[16, 33, 45, 46, 52, 53, 59, 60], 물체 감지[5, 11, 63], 비디오 분류 [1, 3, 17] 및 객체 추적 [7, 37, 51]과 같은 시간 작업에 대한 의미론적 분할 [49, 57].
It is crucial for dense prediction tasks such as object detection and segmentation to represent features at multiple scales for discriminating between objects or regions of varying sizes. Modern CNN backbones which show better performance for dense prediction leverage multiple scales at the convolutional kernel level [18, 28, 29, 42, 43], or feature level [30, 38, 50].
다양한 크기의 객체 또는 영역을 구별하기 위해 여러 축척으로 특징을 나타내는 객체 감지 및 분할과 같은 조밀한 예측 작업에 중요합니다. 조밀한 예측에 대해 더 나은 성능을 보여주는 최신 CNN 백본은 컨볼루션 커널 수준[18, 28, 29, 42, 43] 또는 기능 수준[30, 38, 50]에서 여러 척도를 활용합니다.
Inception Network [42] or VoVNet [28] exploits multi-grained convolution kernels at the same feature level, yielding diverse receptive fields and in turn boosting detection performance. HRNet [50] represents multi-scale features by simultaneously aggregating fine and coarse features throughout the convolutional layers.
Inception Network[42] 또는 VoVNet[28]은 동일한 기능 수준에서 multi-grained convolution kernel을 활용하여 다양한 수용 필드를 생성하고 차례로 탐지 성능을 향상시킵니다. HRNet[50]은 컨볼루션 레이어 전체에서 미세 및 거친 특징을 동시에 집계하여 다중 스케일 특징을 나타냅니다.
Although CNN models are widely utilized as feature extractors for dense predictions, the current state-of-the-art (SOTA) Vision Transformers [16, 33, 52–54, 59–61] have surpassed the performance of CNNs.
CNN 모델은 조밀한 예측을 위한 특징 추출기로 널리 사용되지만 현재의 최첨단(SOTA) Vision Transformers[16, 33, 52–54, 59–61]는 CNN의 성능을 능가했습니다.
While the ViTvariants [16, 33, 53, 54, 60, 61] focus on how to address the quadratic complexity of self-attention when applied to dense prediction with a high-resolution, they pay less attention to building effective multi-scale representations. For example, following conventional CNNs [21, 40], recent Vision Transformer backbones [33, 53, 60, 61] build a simple multi-stage structure (e.g., fine-to-coarse structure) with single-scale patches (i.e., tokens).
ViTvariants[16, 33, 53, 54, 60, 61]는 고해상도로 조밀한 예측에 적용될 때 자기 주의의 2차 복잡성을 해결하는 방법에 중점을 두지만 효과적인 다중 스케일 표현을 구축하는 데는 덜 주의합니다. . 예를 들어, 기존의 CNN[21, 40]에 이어 최근의 Vision Transformer 백본[33, 53, 60, 61]은 단일 스케일 패치(즉, 토큰).
CoaT [59] simultaneously represents fine and coarse features by using a co-scale mechanism allowing cross-layer attention in parallel, boosting detection performance. However, the co-scale mechanism requires heavy computation and memory overhead as it adds extra cross-layer attention to the base models (e.g., CoaT-Lite). Thus, there is still room for improvement in multi-scale feature representation for ViT architectures.
CoaT[59]는 병렬로 교차 레이어 주의를 허용하는 co-scale 메커니즘을 사용하여 미세하고 거친 특징을 동시에 나타내므로 탐지 성능이 향상됩니다. 그러나 공동 규모 메커니즘은 기본 모델(예: CoaT-Lite)에 추가적인 교차 계층 주의를 추가하므로 많은 계산과 메모리 오버헤드가 필요합니다. 따라서 ViT 아키텍처에 대한 다중 규모 기능 표현에서 여전히 개선의 여지가 있습니다.
In this work, we focus on how to effectively represent multi-scale features with Vision Transformers for dense prediction tasks. Inspired by CNN models exploiting the multi-grained convolution kernels for multiple receptive fields [18, 28, 42], we propose a multi-scale patch embedding and multi-path structure scheme for Transformers, called Multi-Path Vision Transformer (MPViT).
이 작업에서는 고밀도 예측 작업을 위해 Vision Transformers를 사용하여 다중 스케일 기능을 효과적으로 표현하는 방법에 중점을 둡니다. 다중 수신 필드[18, 28, 42]에 대해 다중 단위 컨볼루션 커널을 활용하는 CNN 모델에서 영감을 받아 다중 경로 비전 변환기(MPViT)라고 하는 다중 크기 패치 임베딩 및 다중 경로 구조 체계를 Transformer에 제안합니다.
As shown in Fig. 1, the multi-scale patch embedding tokenizes the visual patches of different sizes at the same time by overlapping convolution operations, yielding features having the same sequence length (i.e., feature resolution) after properly adjusting the padding/stride of the convolution.
그림 1에 표시된 바와 같이, 다중 스케일 패치 임베딩은 컨볼루션 작업을 겹쳐서 서로 다른 크기의 시각적 패치를 동시에 토큰화하여 컨볼루션의 패딩/보폭을 적절히 조정한 후 동일한 시퀀스 길이(즉, 피쳐 해상도)를 갖는 피쳐를 생성합니다.
Then, tokens from different scales are independently fed into Transformer encoders in parallel. Each Transformer encoder with different-sized patches performs global self-attention. Resulting features are then aggregated, enabling both fine and coarse feature representations at the same feature level.
그런 다음 다른 규모의 토큰이 Transformer 인코더에 병렬로 독립적으로 공급됩니다. 서로 다른 크기의 패치가 있는 각 Transformer 인코더는 전역 자가 주의를 수행합니다. 그런 다음 결과 피쳐가 집계되어 동일한 피쳐 수준에서 미세 및 대략적인 피쳐 표현이 모두 가능합니다.
In the feature aggregation step, we introduce a global-to-local feature interaction (GLI) process which concatenates convolutional local features to the transformer’s global features, taking advantage of both the local connectivity of convolutions and the global context of the transformer.
피쳐 집계 단계에서 우리는 컨볼루션의 로컬 연결성과 트랜스포머의 글로벌 컨텍스트를 모두 활용하여 컨볼루션 로컬 피쳐를 트랜스포머의 글로벌 피쳐에 연결하는 글로벌-로컬 피쳐 상호작용(GLI) 프로세스를 도입합니다.
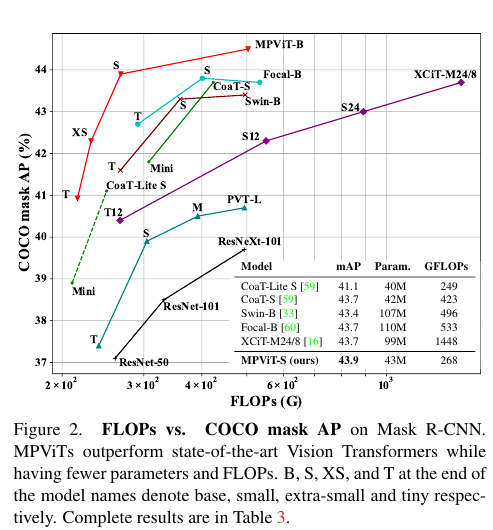
FLOPs vs. COCO mask AP on Mask R-CNN.
MPViTs outperform state-of-the-art Vision Transformers while having fewer parameters and FLOPs. B, S, XS, and T at the end of the model names denote base, small, extra-small and tiny respectively. Complete results are in Table 3.
FLOPs vs. COCO 마스크 AP on Mask R-CNN.
MPViT는 매개 변수와 FLOP가 적으면서도 최첨단 비전 트랜스포머를 능가한다. 모델 이름 끝에 있는 B, S, XS 및 T는 각각 베이스, 스몰, 엑스트라 스몰 및 스몰을 나타낸다. 전체 결과는 표 3에 나와 있습니다.
Following the standard training recipe as in DeiT [45], we train MPViTs on ImageNet-1K [12], which consistently achieve superior performance compared to recent SOTA Vision Transformers [16, 33, 54, 59, 60]. Furthermore, We validate MPViT as a backbone on object detection and instance segmentation on the COCO dataset and semantic segmentation on the ADE20K dataset, achieving statethe-art performance. In particular, MPViT-Small (22M & 4GFLOPs) surpasses the recent, and much larger, SOTA Focal-Base [60] (89M & 16GFLOPs) as shown in Fig. 2.
DeiT[45]에서와 같은 표준 교육 방법에 따라 우리는 ImageNet-1K[12]에서 MPViT를 교육하며, 이는 최근 SOTA Vision Transformers[16, 33, 54, 59, 60]에 비해 지속적으로 우수한 성능을 달성합니다. 또한 MPViT를 COCO 데이터 세트의 객체 감지 및 인스턴스 세분화 및 ADE20K 데이터 세트의 의미론적 세분화에 대한 백본으로 검증하여 최첨단 성능을 달성합니다. 특히 MPViT-Small(22M & 4GFLOPs)은 그림 2에 표시된 것처럼 최근의 훨씬 더 큰 SOTA Focal-Base[60](89M & 16GFLOPs)를 능가합니다.
To summarize, our main contributions are as follows:
요약하자면, 우리의 주요 기여는 다음과 같습니다:
• We propose a multi-scale embedding with a multipath structure for simultaneously representing fine and coarse features for dense prediction tasks.
• 우리는 조밀한 예측 작업을 위해 미세 및 거친 특징을 동시에 표현하기 위해 다중 경로 구조를 사용한 다중 스케일 임베딩을 제안합니다.
• We introduce global-to-local feature interaction (GLI) to take advantage of both the local connectivity of convolutions and the global context of the transformer.
• 우리는 컨볼루션의 로컬 연결성과 변환기의 글로벌 컨텍스트를 모두 활용하기 위해 글로벌-로컬 기능 상호작용(GLI)을 도입합니다.
• We provide ablation studies and qualitative analysis, analyzing the effects of different path dimensions and patch scales, discovering efficient and effective configurations.
• 절제 연구 및 정성적 분석을 제공하여 다양한 경로 치수 및 패치 규모의 영향을 분석하고 효율적이고 효과적인 구성을 찾습니다.
• We verify the effectiveness of MPViT as a backbone of dense prediction tasks, achieving state-of-the-art performance on ImageNet classification, COCO detection and ADE20K segmentation.
• 우리는 ImageNet 분류, COCO 감지 및 ADE20K 세분화에 대한 최첨단 성능을 달성함으로써 고밀도 예측 작업의 백본으로서 MPViT의 효율성을 검증합니다.
