MSDN: Mutually Semantic Distillation Network for Zero-Shot Learning 제2부
Instroduction
Recently, deep learning performs achievements on object recognition [12, 39, 40].
최근 딥 러닝은 객체 인식에 대한 성과를 수행합니다[12, 39, 40].
Based on the prior knowledge of seen classes, humans possess a remarkable ability to recognize new concepts (classes) using shared and distinct attributes of both seen and unseen classes [17].
보이는 클래스에 대한 사전 지식을 바탕으로 인간은 보이는 클래스와 보이지 않는 클래스의 공유되고 구별되는 속성을 사용하여 새로운 개념(클래스)을 인식하는 놀라운 능력을 가지고 있습니다[17].
Inspired by this cognitive competence, zero-shot learning (ZSL) is proposed under a challenging image classification setting to mimic the human cognitive process [19, 28].
cognitive 인지의, 인식의 competence 능숙도, 역량 mimic 모방하다, 흉내내다.
이러한 인지 역량에 영감을 받아, 인간의 인지 과정을 모방하기 위한 도전적인 이미지 분류 설정 하에서 제로샷 학습(ZSL)이 제안된다[19, 28].
ZSL aims to tackle the unseen class recognition problem by transferring semantic knowledge from seen classes to unseen ones.
ZSL은 의미론적 지식을 보이는 클래스에서 보이지 않는 클래스로 전달하여 보이지 않는 클래스 인식 문제를 해결하는 것을 목표로 합니다.
It is usually based on the assumption that both seen and unseen classes can be described through the shared semantic descriptions (e.g., attributes) [18].
일반적으로 보이는 클래스와 보이지 않는 클래스가 공유된 의미론적 설명(예: 속성)을 통해 설명될 수 있다는 가정에 기반합니다[18].
Based on the classes that a model sees in the testing phase, ZSL methods can be categorized into conventional ZSL (CZSL) and generalized ZSL (GZSL) [44], where CZSL aims to predict unseen classes, while GZSL can predict both seen and unseen ones.
모델이 테스트 단계에서 보는 클래스를 기반으로, ZSL 방법은 기존의 ZSL(CZSL)과 일반화된 ZSL(GZSL)[44]로 분류될 수 있으며, 여기서 CZSL은 보이지 않는 클래스를 예측하는 것을 목표로 하고, GZSL은 보이는 클래스와 보이지 않는 클래스를 모두 예측할 수 있다.
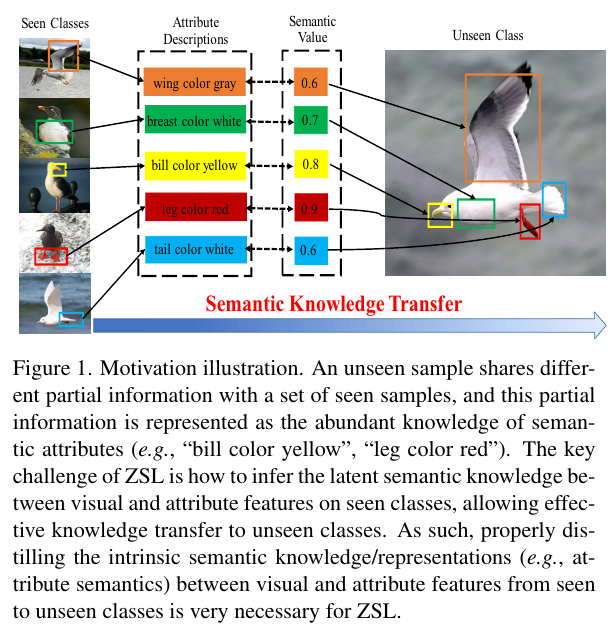
Motivation illustration. An unseen sample shares different partial information with a set of seen samples, and this partial information is represented as the abundant knowledge of semantic attributes (e.g., “bill color yellow”, “leg color red”).
partial information 부분정보abundant 풍부한
동기부여 설명. 보이지 않는 샘플은 보이는 샘플 세트와 서로 다른 부분 정보를 공유하며, 이 부분 정보는 의미 속성(예: "bill color yellow", "leg color red")에 대한 풍부한 지식으로 표현된다.
The key challenge of ZSL is how to infer the latent semantic knowledge between visual and attribute features on seen classes, allowing effective knowledge transfer to unseen classes.
infer 추론하다
ZSL의 주요 과제는 보이는 클래스의 시각적 기능과 속성 사이의 잠재적 의미 지식을 추론하여 보이지 않는 클래스에 효과적인 지식 전달을 허용하는 것입니다.
As such, properly distilling the intrinsic semantic knowledge/representations (e.g., attribute semantics) between visual and attribute features from seen to unseen classes is very necessary for ZSL.
intrinsic 본질적인
따라서 시각적 및 속성 기능 간의 본질적 의미론적 지식/표현(예: 속성 의미론)을 보이는 클래스에서 보이지 않는 클래스로 적절하게 증류하는 것은 ZSL에 매우 필요합니다.

Four investigated ZSL paradigms. (a) Embedding-based method. (b) Generative method. (c) Common space learning-based method. (d) Ours proposed mutually semantic distillation network (MSDN).
4개의 ZSL 패러다임을 조사했습니다. (a) 임베딩 기반 방법. (b) 생성 방법. (c) 공통 공간 학습 기반 방법. (d) 우리가 제안한 상호 의미 증류 네트워크(MSDN).
The semantic space S is represented by the class semantic vector annotated by humans based on the attribute descriptions.
annoated 주석을 단
의미 공간 S는 속성 설명을 기반으로 사람이 주석을 추가한 클래스 의미 벡터로 표현됩니다.
The visual space V is learned by a CNN backbone (e.g., ResNet101).
시각적 공간 V는 CNN 백본(예: ResNet101)에 의해 학습됩니다.
The common space O is a shared latent space between visual mapping and semantic mapping.
공통 공간 O는 시각적 매핑과 의미 매핑 사이의 공유 잠재 공간입니다.
The attribute space A is learned by a language model (e.g., Glove [31]).
속성 공간 A는 언어 모델(예: Glove [31])에 의해 학습됩니다.
Filled triangles, circles, squares and diamonds denote the sample features in S, V, O and A, respectively.
채워진 삼각형, 원, 사각형 및 다이아몬드는 각각 S, V, O 및 A의 샘플 기능을 나타냅니다.
ZSL has achieved significant progress, with many efforts focus on embedding-based methods, generative methods, and common space learning-based methods.
ZSL은 임베딩 기반 방법, 생성 방법 및 공통 공간 학습 기반 방법에 많은 노력을 기울이면서 상당한 진전을 이뤘습니다.
As shown in Fig. 2 (a), embedding-based methods aim to learn a visual→semantic mapping to map the visual feaures into the semantic space for visual-semantic interaction [2, 4, 5, 32, 46, 48].
그림 2(a)에서 볼 수 있듯이 임베딩 기반 방법은 시각적-의미적 상호 작용을 위해 시각적 기능을 의미적 공간에 매핑하는 시각적 → 의미적 매핑을 학습하는 것을 목표로 합니다[2, 4, 5, 32, 46, 48].
The embedding-based methods usually have a large bias towards seen classes under the GZSL setting, since the embedding function is solely learned by seen class samples.
임베딩 기반 방법은 일반적으로 GZSL 설정에서 본 클래스에 대한 큰 편향을 가지고 있습니다. 임베딩 기능은 본 클래스 샘플에 의해서만 학습되기 때문입니다.
To solve this issue, the generative ZSL methods (see Fig. 2(b)) are proposed to learn semantic→visual mapping to generate visual features of unseen classes [3, 6, 8, 34, 35, 38, 43, 50], and thus converting ZSL into a conventional classification problem.
이러한 문제를 해결하기 위해 의미론적 → 시각적 매핑을 학습하여 보이지 않는 클래스의 시각적 특징을 생성하는 생성적 ZSL 방법(그림 2(b) 참조)이 제안됩니다[3, 6, 8, 34, 35, 38, 43, 50] , 따라서 ZSL을 기존 분류 문제로 변환합니다.
As shown in Fig. 2(c), common space learning learns a common representation space where both visual features and semantic representations are projected for knowledge transfer [7, 10, 23, 34, 37, 41].
그림 2(c)와 같이 공통 공간 학습은 지식 전달을 위해 시각적 특징과 의미 표현이 모두 투영되는 공통 표현 공간을 학습합니다[7, 10, 23, 34, 37, 41].
However, they simply utilize the global features representations and have neglected the finegrained details in the training images.
neglected 무시하다 finegrained 세밀한
그러나 그들은 단순히 전역 기능 표현을 활용하고 훈련 이미지의 세밀한 세부 사항을 무시했습니다.
