Satellite Image Semantic Segmentation 제2부
3.2 Dataset preparation
Our training and test datasets are composed of tiles prepared from IGN open data. Each tile has a 1000x1000 resolution representing a 500m x 500m footprint (the resolution is 50cm per pixel).
우리의 훈련 및 테스트 데이터 세트는 IGN 오픈 데이터에서 준비된 타일로 구성됩니다. 각 타일의 해상도는 500m x 500m(해상도는 픽셀당 50cm)를 나타내는 1000x1000 해상도입니다.
We mainly used data from the Hautes-Alpes department, and we took spatially spaced data to have as much diversity as possible and to limit the area without information (unfortunately, some places lack information).
주로 오트알프(Hautes-Alpes) 부서의 데이터를 사용했고, 최대한 다양하고 정보가 없는 영역을 제한하기 위해 공간적 데이터를 사용했습니다(안타깝게도 정보가 부족한 곳도 있음).
A total of 600 tiles have been used to train the model.
The file structure of the dataset is as follows:
모델 훈련에 총 600개의 타일이 사용되었습니다.
데이터 세트의 파일 구조는 다음과 같습니다.


3.3 Information on the training
During the training, an ImageNet-22K pretrained model was used and we added weights on each class because the dataset was not balanced in classes distribution.
훈련 중에는 ImageNet-22K 사전 훈련된 모델이 사용되었으며 데이터 세트가 클래스 분포에서 균형을 이루지 않았기 때문에 각 클래스에 가중치를 추가했습니다.
The empirically chosen weights we have used are:
우리가 사용한 경험적으로 선택된 가중치는 다음과 같습니다.
• Dense forest: 0.5
• Sparse forest: 1.31237
• Moor: 1.38874
• Herbaceous formation: 1.39761
• Building: 1.5
• Road: 1.47807
• 울창한 숲: 0.5
• 희소 숲: 1.31237
• 무어: 1.38874
• 초본 형성: 1.39761
• 건물: 1.5
• 도로: 1.47807
4. Experimental results

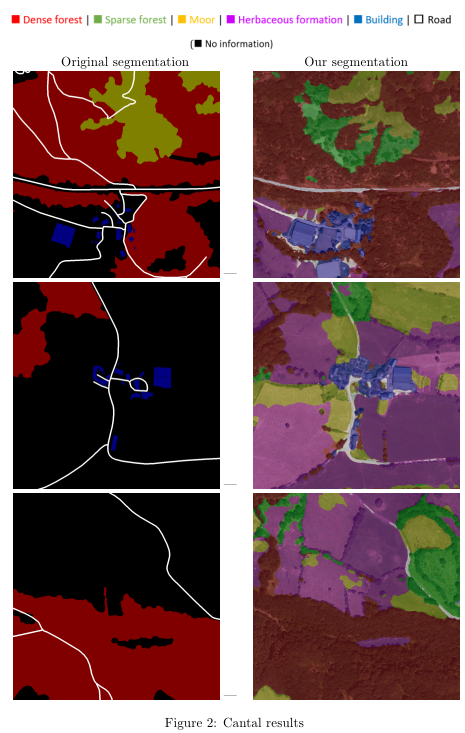
Figure 1 shows some comparison between the original segmentation and the segmentation that has been obtained after the training (Hautes-Alpes dataset).
그림 1은 원래 분할과 훈련 후 얻은 분할 간의 일부 비교를 보여줍니다(Hautes-Alpes 데이터 세트).
We have also tested the model on satellite photos from another French department to see if the trained model generalizes to other locations.
또한 훈련된 모델이 다른 위치에 일반화되는지 확인하기 위해 다른 프랑스 부서의 위성 사진에서 모델을 테스트했습니다.
We chose Cantal and a few samples of the obtained results can be seen in figure 2.
우리는 Cantal을 선택했고 얻은 결과의 몇 가지 샘플을 그림 2에서 볼 수 있습니다.
These latest results show that the model is capable of producing a segmentation even if the photos are located in another department and even if there are a lot of pixels without information (in black), which is encouraging.
capable ~ 할 수 있음을
이러한 최근 결과는 사진이 다른 부서에 위치하고 정보가 없는 픽셀(검정색)이 많은 경우에도 모델이 분할을 생성할 수 있음을 보여 고무적입니다.
4.1 Limitations
As illustrated in the previous images, the results are not perfect.
이전 이미지에서 볼 수 있듯이 결과는 완벽하지 않습니다.
This is caused by the inherent limits of the data used during the training phase. The main limitations are:
이는 훈련 단계에서 사용되는 데이터의 고유한 한계로 인해 발생합니다. 주요 제한 사항은 다음과 같습니다.
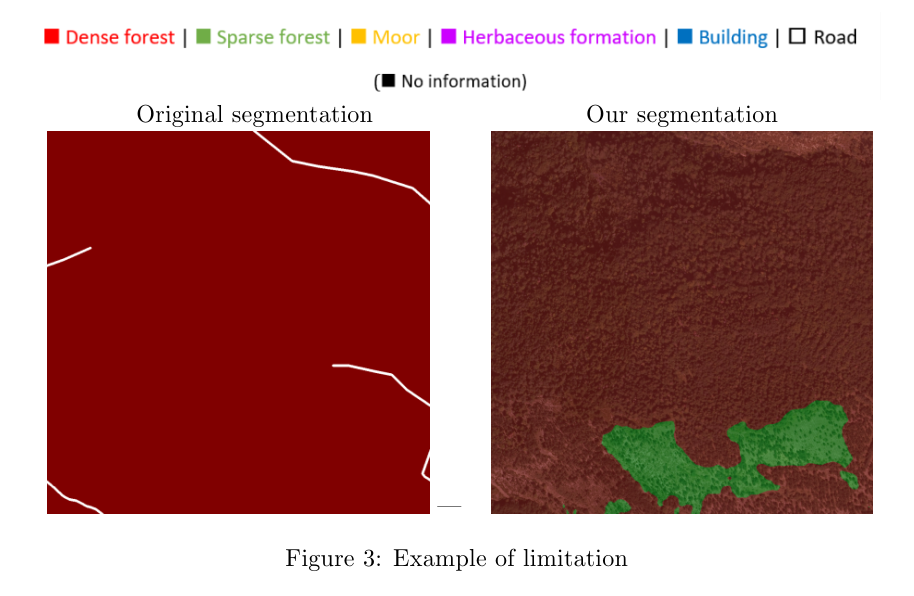
1.The satellite photos and the original segmentation were not made at the same time, so the segmentation is not always accurate.
1.위성 사진과 원본 분할이 동시에 이루어지지 않아 분할이 항상 정확하지는 않습니다.
For example, we can see in figure 3 a zone is segmented as ”dense forest” even if there are not many trees (that is why the segmentation after training, on the right, classed it as ”sparse forest”).
예를 들어, 그림 3에서 나무가 많지 않은 경우에도 영역이 "밀집한 숲"으로 분할된 것을 볼 수 있습니다(그래서 오른쪽의 훈련 후 분할에서 "희소한 숲"으로 분류됨).
2.Sometimes there are zones without information (represented in black) in the dataset.
2.때때로 데이터 세트에 정보가 없는 영역(검정색으로 표시됨)이 있습니다.
Fortunately, we can ignore them during the training phase, but we also lose some information, which is a problem: we thus removed the tiles that had more than 50% of unidentified pixels to try to improve the training.
다행스럽게도 훈련 단계에서 무시할 수 있지만 일부 정보도 잃어버리는 문제가 있습니다. 따라서 훈련을 개선하기 위해 식별되지 않은 픽셀이 50% 이상 있는 타일을 제거했습니다.
3. Road segmentation is not accurate because sometimes the information is not visible in the image (hidden by trees for example), which obviously prevents it from being detected.
3. 때때로 정보가 이미지에서 보이지 않기 때문에(예: 나무에 가려져) 도로 분할이 정확하지 않아 분명히 감지되지 않습니다.
5 Repository
The source code, which is only a fork from the implementation of Swin Transformer can be found on github together with usage details 6 .
Swin Transformer 구현의 포크인 소스 코드는 사용법 세부 정보와 함께 github에서 찾을 수 있습니다.
