Semantics Disentangling for Generalized Zero-Shot Learning 제2-2부
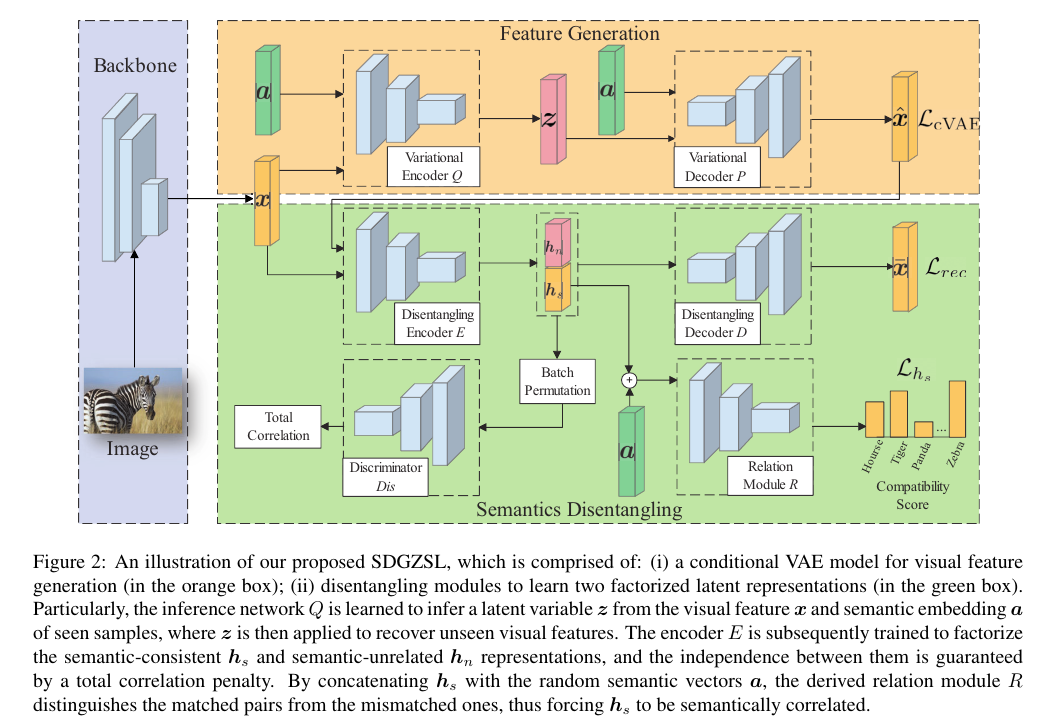
Figure 2: An illustration of our proposed SDGZSL, which is comprised of: (i) a conditional VAE model for visual feature generation (in the orange box); (ii) disentangling modules to learn two factorized latent representations (in the green box).
disentangling 구분하다
그림 2: 제안된 SDGZSL의 설명은 다음으로 구성됩니다. (i) 시각적 기능 생성을 위한 조건부 VAE 모델(주황색 상자) (ii) 2개의 분해된 잠재 표현(녹색 상자)을 학습하기 위해 모듈을 분리합니다.
Particularly, the inference network Q is learned to infer a latent variable z from the visual feature x and semantic embedding a of seen samples, where z is then applied to recover unseen visual features.
특히, 추론 네트워크 Q는 시각적 특징 x 및 본 샘플의 시맨틱 임베딩 a로부터 잠재 변수 z를 추론하도록 학습되며, 여기서 z는 보이지 않는 시각적 특징을 복구하기 위해 적용됩니다.
The encoder E is subsequently trained to factorize the semantic-consistent and semantic-unrelated representations, and the independence between them is guaranteed by a total correlation penalty.
subsequnetly 그 뒤에, 나중에
인코더 E는 의미론적으로 일관된 및 의미론적으로 관련되지 않은 표현을 인수분해하도록 후속적으로 훈련되며, 이들 사이의 독립성은 전체 상관 패널티에 의해 보장됩니다.
By concatenating with the random semantic vectors a, the derived relation module R distinguishes the matched pairs from the mismatched ones, thus forcing to be semantically correlated.
derived 유래된, 파생된,correlated 연관된
를 임의의 의미 벡터 a와 연결함으로써, 도출된 관계 모듈 R은 일치하는 쌍과 일치하지 않는 쌍을 구별하여 가 의미적으로 상관되도록 한다.
To unravel semantic-consistent and semantic-unrelated features from the original visual spaces, we present a novel framework, namely Semantics Disentangling for Generalized Zero-Shot Learning (SDGZSL), as shown in Figure 2.
unravel 시작하다, 풀다
원래 시각적 공간에서 의미 일치 및 의미와 무관한 기능을 풀기 위해 그림 2와 같이 SDGZSL(Semantics Disentangling for Generalized Zero-Shot Learning)이라는 새로운 프레임워크를 제시한다.
Specifically, we disentangle the underlying information of the extracted visual features into two disjoint latent vectors and .
disjoint 분리하다, 해제하다 disentagle 분리하다 underlying 근본적인, 기본적인
구체적으로, 우리는 추출된 시각적 기능의 기본 정보를 두 개의 분리된 잠재 벡터 와 로 분리한다.
They are learned in an encoder-decoder architecture with a relation module and a total correlation penalty.
그것들은 관계 모듈과 총 상관 패널티가 있는 인코더-디코더 아키텍처에서 학습됩니다.
The encoder network projects the original visual features to and .
인코더 네트워크는 원래의 시각적 기능을 및 에 투영합니다.
To make consistent with the semantic embeddings, the relation module calculates a compatibility score between and semantic information to guide the learning of .
가 시맨틱 임베딩과 일치하도록 하기 위해 관계 모듈은 와 학습을 안내하는 시맨틱 정보 간의 호환성 점수를 계산합니다.
We further apply the total correlation penalty to enforce the independence between and .
우리는 와 사이의 독립성을 적용하기 위해 총 상관 패널티를 추가로 적용한다.
Afterward, we reconstruct the original visual features from the two latent representations.
그 후, 우리는 두 개의 잠재된 표현으로부터 원래의 시각적 특징 를 재구성합니다.
This reconstruction objective ensures the two latent representations to cover both semantic-consistent and semantic-unrelated information.
이 재구성 목표는 의미론적 일관성 및 의미론적 관련 없는 정보를 모두 포함하는 두 가지 잠재적 표현을 보장합니다.
The disentangling modules are incorporated into a conditional variational autoencoder and trained in an end-to-end manner.
분리형 모듈은 조건부 변형 오토인코더에 통합되고 종단 간 방식으로 학습됩니다.
The proposed framework is evaluated on various GZSL benchmarks and achieves better performance compared to the state-of-the-art methods.
제안된 프레임워크는 다양한 GZSL 벤치마크에서 평가되었으며 최신 방법에 비해 더 나은 성능을 달성합니다.
The main contributions of this work are summarized as follows:
이 작업의 주요 기여는 다음과 같이 요약됩니다.
-
We propose a novel feature disentangling framework, namely Semantic Disentangling for Generalized ZeroShot Learning (SDGZSL), to disentangle the underlying information of visual features into two latent representations that are semantic-consistent and semantic-unrelated, respectively.
namely 즉, 다시말해
우리는 시각적 기능의 기본 정보를 각각 의미적으로 일관되고 의미적으로 관련이 없는 두 가지 잠재 표현으로 분리하기 위해 새로운 기능 분리 프레임워크인 SDGZSL을 제안한다.
Exploiting the semantic-consistent representations can substantially increase the performance in GZSL comparing to directly using entangled visual features that are extracted from the pre-trained CNN models.
exploit 이용하다substantially 상당히entangled 얼기설기 얽힌
의미적으로 일관된 표현을 활용하면 사전 훈련된 CNN 모델에서 추출한 얽힌 시각적 기능을 직접 사용하는 것에 비해 GZSL의 성능을 크게 높일 수 있다. -
To facilitate the feature disentanglement of the semantic-consistent and semantic-unrelated representations, by introducing a total correlation penalty in our framework we arrive at a more accurate characterization of the semantically annotated features.
시맨틱 일관성 및 시맨틱 관련 없는 표현의 기능 분리를 용이하게 하기 위해 프레임워크에 전체 상관 패널티를 도입하여 시맨틱 주석이 달린 기능의 보다 정확한 특성화에 도달합니다. -
Extensive experiments conducted on four benchmark datasets evidence that the proposed method performs better than the state-of-the-art methods.
4개의 벤치마크 데이터 세트에 대해 수행된 광범위한 실험을 통해 제안된 방법이 최신 방법보다 성능이 더 우수함을 보여줍니다.
