1. Introduction
Convolutional neural networks have been the main design paradigm for image understanding tasks, as initially demonstrated on image classification tasks.
컨볼루션 신경망은 이미지 분류 작업에서 처음 입증되었듯이 이미지 이해 작업을 위한 주요 설계 패러다임이었
One of the ingredient to their success was the availability of a large training set, namely Imagenet. ingredient : 요소
성공의 요소 중 하나는 대규모 훈련 세트, 즉 Imagenet [13, 42]의 이용 가능성이었다.
Motivated by the success of attention-based models in Natural Language Processing, there has been increasing interest in architectures leveraging attention mechanisms within convets.
convnets : cnn 줄인말
자연어 처리[14, 52]에서 주의 기반 모델의 성공에 자극을 받아, 컨넷 내의 주의 메커니즘을 활용하는 아키텍처에 대한 관심이 증가하고 있다[
More recently several researchers have propsed hybrid architectrure transplanting transformer ingredients to convets to solve vision tasks.
최근 몇 명의 연구자가 비전 과제를 해결하기 위해 변압기 성분을 컨넷에 이식하는 하이브리드 아키텍처를 제안했다
The vision transformer (ViT) introduced by Dosovitskiy et al. is an architecture directly inherited from Natural Language Processing, but applied to image classification with raw image patches as input.
비전은 변압기(ViT)Dosovitskiy에 소개했다.[15]아키텍처가 직접적으로 자연어 정보 처리에서[52]지만, 입력으로 원이미지 조각으로 분류 촬영에 지원 상속됩니다.
Their paper presented excellent results with transformers trained with a large private labelled image dataset (JFT-300M [46], 300 millions images).
그들의 논문은 대규모 개인 레이블이 지정된 이미지 데이터 세트(JFT-300M[46], 3억 개의 이미지)로 훈련된 변압기로 우수한 결과를 제시했다.
The paper concluded that transformers "do not generalize well when trained on insufficient amounts of data", and the training of these models involved extensive computing resources. involve : 수반(포함)하다
이 논문은 변환기가 "불충분한 양의 데이터에 대해 훈련될 때 잘 일반화되지 않는다"고 결론지었고 이러한 모델의 훈련에는 광범위한 컴퓨팅 리소스가 필요했습니다.
In this paper, we train a vision transformer on a single 8-GPU node in two to three days(53 hours of pre-training, and optionally 20 hours of fine-tuning) that is competitive with convets having a similar number of parameters and efficiecy.
number of parameters : 매개변수
본 논문에서는 매개 변수 수와 효율성이 유사한 컨베네트와 경쟁하는 단일 8-GPU 노드에서 2~3일(사전 교육 53시간, 선택적으로 미세 조정 20시간)에 비전 트랜스포머를 교육한다.
It uses Imagenet as the sole training set.
그것은 Imagenet을 단독 훈련 세트로 사용한다.
We build upon the visual transformer architecture from Dosovitskiy et al. and imporvements included in the timm library.
우리는 Dosovitskyy 등의 시각적 트랜스포머 아키텍처를 기반으로 한다. [15] 및 개선사항은 timm 라이브러리에 포함되어 있습니다 [55].
With our Data-efficient image Transformers(DeiT), we report large improvements over previous results, see Figure 1.
우리 Data-efficient 이미지 트랜스포머(DeiT)을 가지고, 우리는, 그림 1참조하십시오.
Our ablation study details the hyper-parameters and key ingredients for a successful training, such as repeated augmentation.
ablation : 절제, 제거
우리의 절제 연구는 반복적인 증강과 같은 성공적인 훈련을 위한 하이퍼 매개변수와 핵심 요소에 대해 자세히 설명합니다.
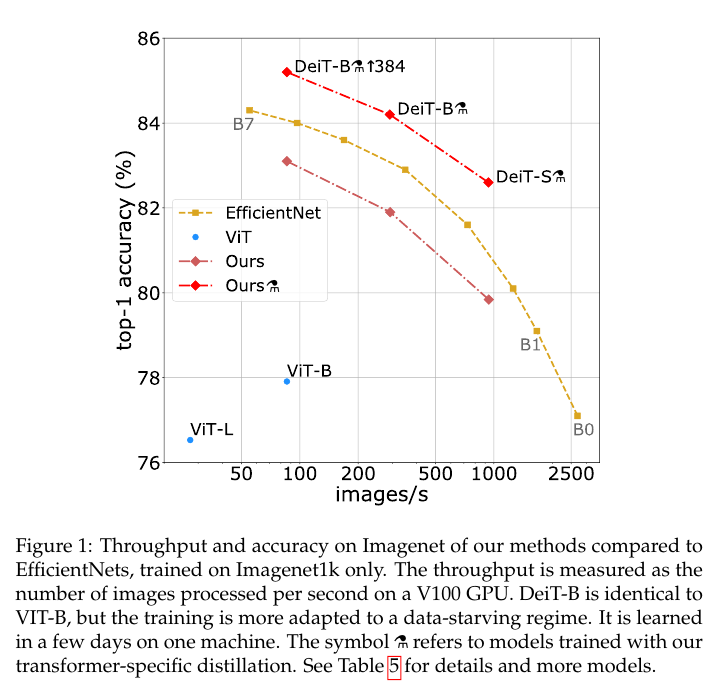
Throughput and accuracy on Imagenet of our methods compared to EfficientNets, trained on Imagenet1k only.
Throughput : 처리량
Imagenet1k에서만 훈련된 EfficientNet과 비교한 우리 방법의 Imagenet에서의 처리량 및 정확도.
The throughput is emasured as the number of images processed per second on a V100GPU. DeiT-B is identical to VIT-B, but the training is more adapted to a data-starving regime.
regime : 제도, 체계, starve : 굶주리다 부족하다., adapt : 적용하다 알맞다
처리량은 V100 GPU에서 초당 처리되는 이미지 수로 측정됩니다. DeiT-B는 VIT-B와 동일하지만 훈련은 데이터 부족 체제에 더 적합합니다.
It is learne din a few days on one machine.
The symbol ⚗ refers to models trained with our transformer-specific distillation.
기호 ⚗는 당사의 변압기 전용 증류로 훈련된 모델을 나타냅니다.
See Table 5 for details and more models.
We address another question: how to distill these models?
우리는 이 모델들을 어떻게 증류할 것인가 하는 또 다른 질문을 다룬다.
We introduce a token-based strategy, speicfic to transformers and denoted by DeiT⚗, and show that it advantageoulsy replaces the usual distillation.
우리는 DeiT⚗로 표시된 변압기에 특화된 토큰 기반 전략을 소개하고 그것이 일반적인 증류를 유리하게 대체한다는 것을 보여준다.
In summary, our work makes the following contributions:
-
We show that our neural networks that contains no convolutional layer can achiece competitive results against the state of the art on ImageNet with no external data.
우리는 컨볼루션 레이어를 포함하지 않는 우리의 신경망이 외부 데이터 없이 ImageNet의 최첨단 기술과 경쟁적인 결과를 달성할 수 있음을 보여준다.
They are learned on a single node with 4 GPUs in three daya 1.
Our two new models Deit-S and DeiT-Ti have fewer parameters and can be seen as the counterpart of ResNet-50 and ResNet-18
counterpart: 대항마
3일 동안 4개의 GPU가 있는 단일 노드에서 학습된다.1. 우리의 두 가지 새로운 모델 DeiT-S와 DeiT-Ti는 매개 변수가 더 적으며 ResNet-50과 ResNet-18의 대항마로 볼 수 있다. -
We introduce a new distillation procedure based on a distillation token, which plays the same role as the class token, except that it aims at reproducing the label estimated by the teacher.
reproducing : 재현, 재구성
교사가 평가한 레이블을 재현하는 것을 목표로 한다는 점을 제외하고는 클래스 토큰과 동일한 역할을 하는 증류 토큰을 기반으로 하는 새로운 증류 절차를 소개합니다.
Both tokens interact in the transformer through attention.
두 토큰은 주의를 통해 변압기에서 상호 작용한다.
This transformer-specific strategy outpuerforms vanilla distillation by a significant margin.
margin : 차이
변압기별 전략은 바닐라 증류보다 성능이 훨씬 뛰어납니다.
-
Interestingly, with out distillation, image transformers learn more from a convnet than from another transformer with comparalbe performance.
흥미롭게도 우리의 증류를 통해 이미지 변환기는 비슷한 성능의 다른 변환기보다 convnet에서 더 많은 것을 배웁니다. -
Our models pre-earned on Imagenet are competitive when transferred to different downstream tasks such as fine-grained classification, on several popular public benchmarks: CIFA-10, CIFAR-100, Oxford-102 flowers, Stansfor Cars and Inaturlist-18/19
Imagenet에서 사전 학습된 우리 모델은 CIFAR-10, CIFAR-100, Oxford-102 꽃, Stanford Cars 및 iNaturalist-18/19와 같은 몇 가지 인기 있는 공개 벤치마크에서 세분화된 분류와 같은 다양한 다운스트림 작업으로 전송될 때 경쟁력이 있습니다.
This paper is organized as follows: we review related works in Section 2, and focus on transformers for image classification in Section 3.
본 논문은 2장에서 관련 연구를 검토하고 3장에서 영상분류를 위한 변환기를 중심으로 구성하였다.
We introduce our distillation strategy for transformers in Section 4.
Te experimental section 5 provides analysis and comparisons against both converts and recent transformers, as well as a comparactive evaluation of our transformer-specific distillation.
against both : 둘 다에 대해
실험 섹션 5에서는 convnet과 최신 변압기에 대한 분석 및 비교는 물론 변압기별 증류에 대한 비교 평가를 제공합니다.
Section 6 details our training shceme.
scheme : 책략
6절에서는 교육 계획을 자세히 설명합니다.
It includes an extensive ablation of our data-efficient training choices, which gives some insight on the key ingredients involved in DeiT.
여기에는 데이터 효율적인 교육 선택의 광범위한 절제 작업이 포함되어 있으며, 이는 DeiT와 관련된 주요 요소에 대한 통찰력을 제공한다.
We conclude in Section 7.
