TransFG: A Transformer Architecture for Fine-Grained Recognition 제1부
TransFG: A Transformer Architecture for Fine-Grained Recognition
TRANSFG : 세밀한 인식을위한 변압기 아키텍처
Abstract
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Most existing works mainly tackle this problem by reusing the backbone network to extract features of detected discriminative regions.
하위 범주에서 개체를 인식하는 것을 목표로 하는 세분화된 시각적 분류(FGVC)는 본질적으로 미묘한 클래스 간 차이로 인해 매우 어려운 작업이다. 대부분의 기존 연구는 주로 백본 네트워크를 재사용하여 탐지된 차별적 영역의 특징을 추출함으로써 이 문제를 해결한다.
However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects thus fails to locate the really important parts. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The selfattention mechanism of the transformer links every patch token to the classification token. In this work, we first evaluate the effectiveness of the ViT framework in the fine-grained recognition setting.
그러나 이 전략은 필연적으로 파이프라인을 복잡하게 만들고 제안된 영역이 객체의 대부분을 포함하도록 밀어붙이기 때문에 정말 중요한 부분을 찾는 데 실패한다. 최근 비전 변압기(ViT)는 전통적인 분류 작업에서 강력한 성능을 보여준다. 트랜스포머의 셀프 어텐션 메커니즘은 모든 패치 토큰을 분류 토큰에 연결합니다. 본 연구에서는 먼저 세분화된 인식 설정에서 ViT 프레임워크의 효과를 평가한다.
Then motivated by the strength of the attention link can be intuitively considered as an indicator of the importance of tokens, we further propose a novel Part Selection Module that can be applied to most of the transformer architectures where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations.
그런 다음 주의 링크의 강도에 의해 동기 부여를 받아 토큰의 중요성에 대한 지표로 직관적으로 고려할 수 있으며, 변압기의 모든 원시 주의 가중치를 네트워크를 안내하는 주의 맵에 통합하는 대부분의 변압기 아키텍처에 적용할 수 있는 새로운 부품 선택 모듈을 추가로 제안한다 차별적 이미지 패치를 효과적이고 정확하게 선택하고 관계를 계산합니다.
A contrastive loss is applied to enlarge the distance between feature representations of confusing classes. We name the augmented transformer-based model TransFG and demonstrate the value of it by conducting experiments on five popular fine-grained benchmarks where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model.
혼란스러운 클래스의 특징 표현 사이의 거리를 확대하기 위해 대조적 손실이 적용된다. 우리는 증강된 변압기 기반 모델의 이름을 TransFG로 지정하고 최첨단 성능을 달성하는 5가지 인기 있는 세분화 벤치마크에 대한 실험을 수행하여 그 가치를 입증한다. 우리 모델을 더 잘 이해하기 위해 정성적 결과가 제시된다.
Conclusion
In this work, we propose a novel fine-grained recognition framework TransFG and achieve state-of-the-art results on four common fine-grained benchmarks. We exploit selfattention mechanism to capture the most discriminative regions. Compared to bounding boxes produced by other methods, our selected image patches are much smaller thus becoming more meaningful by showing what regions really contribute to the fine-grained classification. The effectiveness of such small image patches also comes from the Transformer Layer to handle the inner relationships between these regions instead of relying on each of them to produce results separately.
본 연구에서는 새로운 세분화된 인식 프레임워크 TransFG를 제안하고 4개의 일반적인 세분화 벤치마크에서 최첨단 결과를 달성한다. 우리는 가장 차별적인 영역을 포착하기 위해 자기 주의 메커니즘을 활용한다. 다른 방법으로 생성된 경계 상자에 비해 선택한 이미지 패치는 훨씬 작기 때문에 세분화된 분류에 실제로 기여하는 영역이 무엇인지 보여줌으로써 더 의미가 있다. 이러한 작은 이미지 패치의 효과는 개별적으로 결과를 생성하기 위해 각 영역에 의존하는 대신 이러한 영역 간의 내부 관계를 처리하는 변압기 계층에서 비롯된다.
Contrastive loss is introduced to increase the discriminative ability of the classification tokens. Experiments are conducted on both traditional academy datasets and large-scale competition datasets to prove the effectiveness of our model in multiple scenarios. Qualitative visualizations further show the interpretability of our method.
대조적 손실은 분류 토큰의 식별 능력을 높이기 위해 도입된다. 실험은 여러 시나리오에서 우리 모델의 효과를 입증하기 위해 기존 아카데미 데이터 세트와 대규모 경쟁 데이터 세트 모두에서 수행된다. 정성적 시각화는 우리 방법의 해석 가능성을 더 보여준다.
With the promising results achieved by TransFG, we believe that the transformer-based models have great potential on fine-grained tasks and our TransFG could be a starting point for future works.
TransFG에 의해 달성된 유망한 결과로, 우리는 변압기 기반 모델이 세분화된 작업과 우리의 Trans에 큰 잠재력을 가지고 있다고 믿는다FG는 향후 작업의 출발점이 될 수 있다.
Introduction
Fine-grained visual classification aims at classifying subclasses of a given object category, e.g., subcategories of birds (Wah et al. 2011; Van Horn et al. 2015), cars (Krause et al. 2013), aircrafts (Maji et al. 2013).
It has long been considered as a very challenging task due to the small interclass variations and large intra-class variations along with the deficiency of annotated data, especially for the longtailed classes. Benefiting from the progress of deep neural networks (Krizhevsky, Sutskever, and Hinton 2012; Simonyan and Zisserman 2014; He et al. 2016), the performance of FGVC has obtained a steady progress in recent years.
To avoid labor-intensive part annotation, the community currently focuses on weakly-supervised FGVC with only image-level labels. Methods now can be roughly classified into two categories, i.e., localization methods and feature-encoding methods. Compared to feature-encoding methods, the localization methods have the advantage that they explicitly capture the subtle differences among subclasses which is more interpretable and yields better results.
세분화된 시각적 분류는 주어진 개체 범주의 하위 분류, 예를 들어 새의 하위 분류(Wah et al. 2011; Van Horn et al. 2015), 자동차(Kruse et al. 2013), 항공기(Maji et al. 2013)를 분류하는 것을 목표로 한다.
특히 긴 단축 클래스의 경우 주석이 달린 데이터의 부족과 함께 클래스 간 변동이 작고 클래스 내 변동이 크기 때문에 오랫동안 매우 어려운 작업으로 간주되어 왔다. 심층 신경망(Krizhevsky, Sutskever, Hinton 2012; Simonyan and Zisserman 2014; He et al. 2016)의 발전에 힘입어 FGVC의 성능은 최근 몇 년 동안 꾸준한 발전을 이루었다.
노동 집약적인 부품 주석을 피하기 위해 커뮤니티는 현재 이미지 수준 레이블만 있는 약하게 감독되는 FGVC에 초점을 맞추고 있다. 이제 방법은 대략 두 가지 범주, 즉 현지화 방법과 기능 인코딩 방법으로 분류할 수 있다. 기능 인코딩 방법과 비교하여 현지화 방법은 하위 클래스 간의 미묘한 차이를 명시적으로 포착한다는 장점이 있으며, 이는 해석 가능성이 높고 더 나은 결과를 산출한다.
Early works in localization methods rely on the annotations of parts to locate discriminative regions while recent works (Ge, Lin, and Yu 2019a; Liu et al. 2020; Ding et al. 2019) mainly adopt region proposal networks (RPN) to propose bounding boxes which contain the discriminative regions. After obtaining the selected image regions, they are resized into a predefined size and forwarded through the backbone network again to acquire informative local features.
A typical strategy is to use these local features for classification individually and adopt a rank loss (Chen et al. 2009) to maintain consistency between the quality of bounding boxes and their final probability output.
현지화 방법의 초기 연구는 차별적 영역을 찾기 위해 부품의 주석에 의존하는 반면, 최근 연구(Ge, Lin, Yu 2019a; Liu et al. 2020; Ding et al. 2019)는 차별적 영역을 포함하는 경계 상자를 제안하기 위해 주로 지역 제안 네트워크(RPN)를 채택한다. 선택한 이미지 영역을 얻은 후에는 미리 정의된 크기로 크기가 조정되고 백본 네트워크를 통해 다시 전달되어 유용한 로컬 기능을 획득합니다.
일반적인 전략은 이러한 국소 특징을 개별적으로 분류에 사용하고 순위 손실을 채택하는 것이다(Chen et al. 2009) 경계 상자의 품질과 최종 확률 출력 사이의 일관성을 유지한다.
However, this mechanism ignores the relation between selected regions and thus inevitably encourages the RPN to propose large bounding boxes that contain most parts of the objects which fails to locate the really important regions.
Sometimes these bounding boxes can even contain large areas of background and lead to confusion. Additionally, the RPN module with different optimizing goals compared to the backbone network makes the network harder to train and the re-use of backbone complicates the overall pipeline.
그러나 이 메커니즘은 선택된 영역 간의 관계를 무시하므로 RPN이 정말 중요한 영역을 찾지 못하는 객체의 대부분을 포함하는 큰 경계 상자를 제안하도록 불가피하게 장려한다.
때때로 이러한 경계 상자는 배경의 넓은 영역을 포함하여 혼란을 초래할 수 있다. 또한 백본 네트워크와 비교하여 최적화 목표가 다른 RPN 모듈은 네트워크를 훈련하기 어렵게 만들고 백본의 재사용은 전체 파이프라인을 복잡하게 만든다.
Recently, the vision transformer (Dosovitskiy et al. 2020) achieved huge success in the classification task which shows that applying a pure transformer directly to a sequence of image patches with its innate attention mechanism can capture the important regions in images.
A series of extended works on downstream tasks such as object detection (Carion et al. 2020) and semantic segmentation (Zheng et al. 2021;
Xie et al. 2021; Chen et al. 2021) confirmed the strong ability for it to capture both global and local features.
최근 비전 변압기(Dosovitskii 외 2020)는 고유한 주의 메커니즘으로 순수 변압기를 일련의 이미지 패치에 직접 적용하면 이미지의 중요한 영역을 캡처할 수 있다는 것을 보여주는 분류 작업에서 큰 성공을 거두었다.
물체 감지(Carion et al. 2020) 및 의미 분할(Zheng et al. 2021)과 같은 다운스트림 작업에 대한 일련의 확장된 연구;
Xie et al. 2021; Chen et al. 2021)은 글로벌 및 로컬 특징을 모두 포착할 수 있는 강력한 능력을 확인했다.
These abilities of the Transformer make it innately suitable for the FGVC task as the early long-range “receptive field” (Dosovitskiy et al. 2020) of the Transformer enables it to locate subtle differences and their spatial relation in the earlier processing layers.
In contrast, CNNs mainly exploit the locality property of image and only capture weak longrange relation in very high layers.
Besides, the subtle differences between fine-grained classes only exist in certain places thus it is unreasonable to convolve a filter which captures the subtle differences to all places of the image.
트랜스포머의 초기 장거리 "수용 필드"(Dosovitskyy et al. 2020)를 통해 초기 처리 계층에서 미묘한 차이와 공간 관계를 찾을 수 있기 때문에 트랜스포머의 이러한 능력은 FGVC 작업에 본질적으로 적합하다.
대조적으로, CNN은 주로 이미지의 국부적 특성을 이용하고 매우 높은 계층에서 약한 장거리 관계만 포착한다.
게다가 세분화된 클래스 간의 미묘한 차이는 특정 장소에만 존재하므로 이미지의 모든 장소에 미묘한 차이를 포착하는 필터를 수렴하는 것은 불합리하다.
Motivated by this opinion, in the paper, we present the first study which explores the potential of vision transformers in the context of fine-grained visual classification. We find that directly applying ViT on FGVC already produces satisfactory results while a lot of adaptations according to the characteristics of FGVC can be applied to further boost the performance.
이 의견에 자극을 받아 본 논문에서는 세분화된 시각 분류의 맥락에서 비전 변압기의 잠재력을 탐구하는 첫 번째 연구를 제시한다. 우리는 FGVC에 ViT를 직접 적용하면 이미 만족스러운 결과가 나오는 반면 FGVC의 특성에 따른 많은 적응을 적용하여 성능을 더욱 향상시킬 수 있다는 것을 발견했다.
We name this novel yet simple transformer-based framework TransFG, and evaluate it extensively on five popular fine-grained visual classification benchmarks (CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds, iNat2017). An overview of the performance comparison can be seen in Fig 1 where our TransFG outperforms existing SOTA CNN methods with different backbones on most datasets. In summary, we make several important contributions in this work:
우리는 이 참신하면서도 간단한 변압기 기반 프레임워크의 이름을 TransFG라고 짓고, 5가지 인기 있는 세분화된 시각적 분류 벤치마크(CUB-200-2011, Stanford Cars, Stanford Dogs, NAbirds, iNat2017)에 대해 광범위하게 평가한다. 성능 비교의 개요는 그림 1에서 확인할 수 있습니다. 여기서 TransFG는 대부분의 데이터 세트에서 서로 다른 백본을 사용하여 기존 SOTA CNN 방법을 능가한다. 요약하면, 우리는 이 작업에서 몇 가지 중요한 기여를 한다:
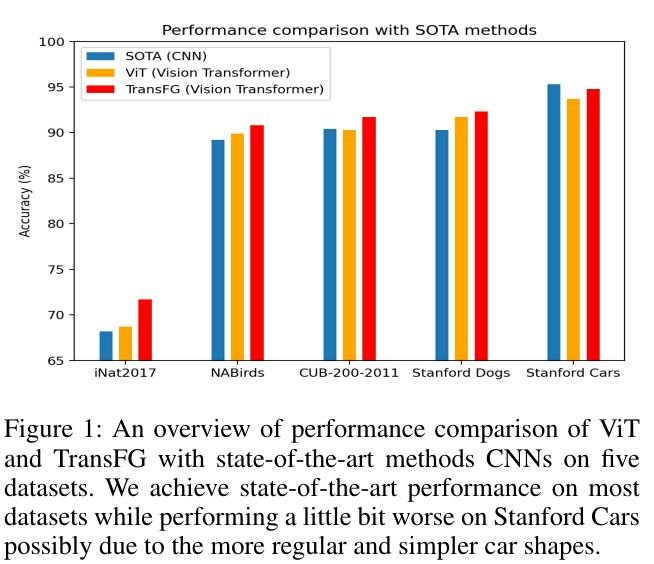
Figure 1: An overview of performance comparison of ViT and TransFG with state-of-the-art methods CNNs on five datasets. We achieve state-of-the-art performance on most datasets while performing a little bit worse on Stanford Cars possibly due to the more regular and simpler car shapes.
-
To the best of our knowledge, we are the first to verify the effectiveness of vision transformer on fine-grained visual classification which offers an alternative to the dominating CNN backbone with RPN model design.
우리가 아는 한, 우리는 RPN 모델 설계로 지배적인 CNN 백본에 대한 대안을 제공하는 세분화된 시각 분류에서 비전 변압기의 효과를 최초로 검증했다. -
We introduce TransFG, a novel neural architecture for fine-grained visual classification that naturally focuses on the most discriminative regions of the objects and achieve SOTA performance on several benchmarks.
우리는 객체의 가장 차별적인 영역에 자연스럽게 초점을 맞추고 여러 벤치마크에서 SOTA 성능을 달성하는 세분화된 시각적 분류를 위한 새로운 신경 아키텍처인 TransFG를 소개한다. -
Visualization results are presented which illustrate the ability of our TransFG to accurately capture discriminative image regions and help us to better understand how it makes correct predictions.
트랜스의 능력을 보여주는 시각화 결과가 제시된다FG는 차별적인 이미지 영역을 정확하게 캡처하고 정확한 예측을 하는 방법을 더 잘 이해할 수 있도록 도와준다.
