재해 disaster
비즈니스 연속성 또는 재무 상태에 부정적인 영향을 미치는 모든 것
- HW/SW 장애
- 네트워크 중단
- 건물의 물리적인 손상
- 정전
- 화재
- 수해
- 사람의 실수
동작 방식
Set up the service
DRS must first be initialized in this region by creating the default replication settings. This will create the required IAM permissions.
재해복구 시스템은 먼저 현재 리전에서 default replication 설정을 생성해야 한다(초기화 작업).
이는 필수 IAM 권한을 생성할 것이다.
Install agents
Install the AWS replication agent on your source servers.
AWS replication agent를 source server에 설치한다.
즉 복제의 대상에 복제를 수행할 agent를 설치하는 것이다.
Replicate to AWS
AWS Elastic Disaster Recovery automatically replicates entire servers, including operating system, applications, data, and configurations.
AWS 탄력적 재해복구 AWS Elastic Disaster Recovery는 자동으로 전체 서버를 복제한다.
여기에는 운영체제, 애플리케이션, 데이터, configuration들도 포함된다.
Perform drills
Perform frequent drills by launching drill and recovery instances on AWS. The 'Initiate recovery job' action launches drills and recovery instances.
AWS에서는 drill과 복구 인스턴스를 시작함으로써 정기적인 drill을 수행할 수 있다.
'복구 작업 시작하기(initiate)' 액션은 drill과 복구 인스턴스를 실행한다.
- Drill(ChatGPT 피셜)
drill은 재해 복구 전에 복구 시나리오를 테스트하는 과정을 말하며, 이 과정에서 다음을 평가한다.- 시스템 복구 절차
- 시스템 복구 소요 시간
- 시스템 복구 성능
이 작업을 통해 복구 전략을 구체화하고 복구 작업의 신뢰성을 향상할 수 있다.
AWS에서는 EC2, RDS, S3 Bucket를 사용해 drill을 수행할 수 있다.
Recover and failback
Use this console to quickly recover to AWS. After recovery, you can use this console to fail back to your original source servers at any time.
AWS로의 빠른 복구를 위해 이 console을 사용한다.
복구 후에는 아무 때나 이 console을 쓰면 원래의 source server로 돌아갈 수 있다(fail back).
요약
- AWS에 서버 복제해놓고 일 생기면 거기로 갈아타서 서비스 함
- AWS에 복제된 걸로 서비스하는 동안 복구 작업함
- 복구 후에는 아무 때나 다시 돌아갈 수 있음.
과금
Rate per replicating source server: $0.028/hr
서버 하나에 시간당 $0.028 (원/달러 환율 1301.00 기준 36.43원)
복구 목표
복구 시간 목표 RTO; Recovery Time Objective
재해 발생 후 복구까지 소요되는 시간 및 복구되어야 할 서비스 수준
재해 발생 시점이 12:00이고 RTO가 8시간이라면 20:00까지는 수용 가능한 서비스 수준으로의 복구가 (가능하도록 적절한 조치가) 이루어져야 한다.
즉 RTO가 8시간이라면 재해 발생 후 8시간 안에 일정 수준으로의 복구가 이루어져야 한다.
복구 시점 목표 RPO; Recovery Point Objective
시간으로 측정된 수용 가능한 데이터 손실량
재해 발생 시점이 12:00이고 RPO가 1시간이라면 적어도 11:00까지 저장되어 있던 모든 데이터가 복구된 시스템에 포함되어 있어야 한다.
즉 RPO가 1시간이라면 1시간치 데이터만 손실되어야 한다.
필요한 AWS 서비스
Region
- 시스템을 배포할 리전을 선택할 수 있다.
- 재해 복구에 적합한 리전을 선택할 수 있다.
Storage
S3; Simple Storage Service
- 기본적인 데이터부터 mission-critical한 데이터까지 저장할 수 있다.
- object는 region 내에서 여러 시설의 여러 장치에 중복저장된다.
Amazon EBS; Elastic Block Store
- 데이터 볼륨의 PIT snapshot ; Point in Time snapshot을 생성한다.
대충 특정 시점의 storage volume, 파일, 데이터베이스의 복사본을 만들어둔다는 얘기. - 스냅샷은 Amazon EBS volume을 시작하는 기점이 될 수 있으며,
데이터의 장기간 보호에 도움이 된다. - EBS volume이 생성되면 EC2 instance에 연결할 수 있다.
이 EBS volume은 EC2 instance의 수명과 관계없이 지속될 수 있다(Off-instance storage)
Computing
Amazon EC2; Elastic Compute Cloud
- 사용자에게 온전한 제어 권한이 있는 가상 머신
- 재해 복구 측면으로 봤을 때, 사용자 입장에서는 제어 가능한 가상 머신을 신속하게 생성하는 기능이 필수적이다.
- 여러 기능이 있지만 다음이 재해 복구와 밀접한 관련이 있다.
- AMI; Amazon Machine Image
- Amazon EC2 RI; Reserved Instance
- 내가 원할 때 생성하는 on-demand에 비해 가격이 싸다.
- 용량 예약도 제공되어 필요한 용량을 필요할 때에 사용할 수 있다.
- 가용 영역 AZ; Availability Zone
- 다른 AZ에 장애가 발생할 경우 분리되도록 설계된 별개의 위치
- 동일 리전의 다른 AZ에 저렴하고 빠른 네트워크 연결을 제공한다.
- Amazon EC2 VM Import
- 기존 환경에서 EC2 인스턴스로 빠르게 import할 수 있다.
Networking
Amazon Route53
- DNS; Domain Name System 웹 서비스
- 그냥 AWS에서 쓰는 DNS임
EIP; Elastic IP address
- 인터넷에서 연결 가능한 퍼블릭 IPv4 주소
- 근데이제 고정을 곁들인
- EIP를 할당하지 않으면 EC2 껐다 켜면 공인 IP 주소 바뀜
ELB; Elastic Load Balancing
- 그냥 로드 밸런싱
- 하나 이상의 가용 영역 AZ; Availability Zone에 있는 여러 대상에서 들어오는 L7 traffic을 자동으로 분산한다.
AWS Storage Gateway
- AWS cloud storage와 on-premise application 간 data migration이 원활하게 이루어지도록 한다.
- 볼륨 데이터를 사용자의 인프라 및 AWS에 local로 저장한다.
- 데이터를 AWS storage infra에 원활하게 저장할 수 있다.
- 그 데이터에 액세스할 때 발생하는 delay time을 줄인다.
Database
Amazon RDS; Relational Database System
- 관계형 데이터베이스
- 지겹게 써먹은 MySQL, MariaDB, PostgreSQL, Aurora 등이 제공된다.
- 재해 복구 준비 단계에서 RDS를 쓰면 production DB(실제로 쓰고 있던 DB)에 있는 데이터를 보존할 수 있다.
- 복구 단계에서 사용하면 production DB를 실행할 수 있다.
재해의 영향 범위와 그에 대한 전략
다중 가용 영역 전략 Multi-AZ strategy
- 모든 리전은 여러 개의 AZ로 구성된다.
- 각 AZ는 지리적으로 독립된 위치의 하나 이상의 데이터 센터로 구성된다.
- 따라서 장애 원인이 여러 개의 AZ에 한 번에 영향을 미칠 가능성을 줄인다.
다중 리전 전략 Multi-Region strategy
- 광범위한(넓은 지역의 여러 데이터 센터에 영향을 미치는) 재해 상황에 대한 대응책이다.
복구 전략
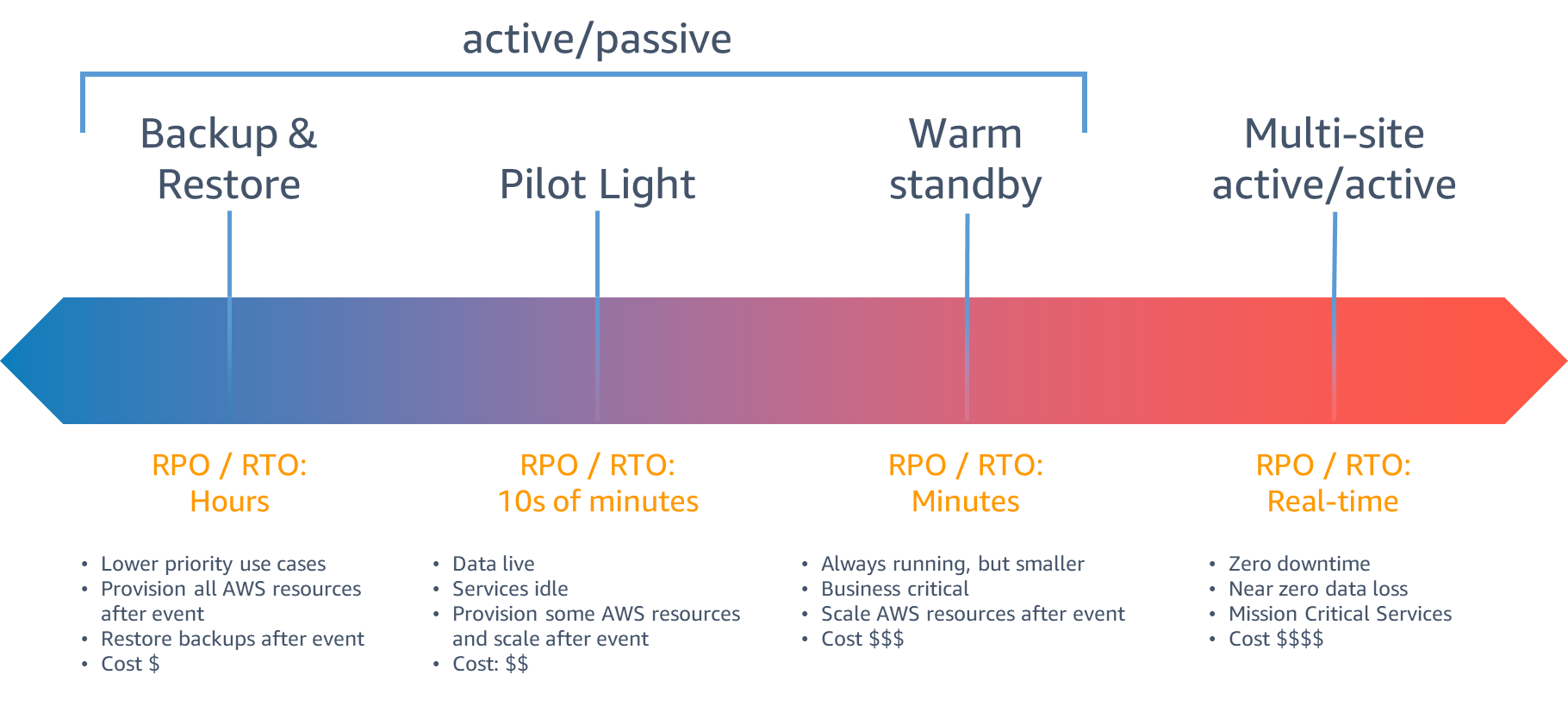
RPO/RTO와 비용의 관계를 나타낸다.
Active/passive와 Active/active
Active/passive
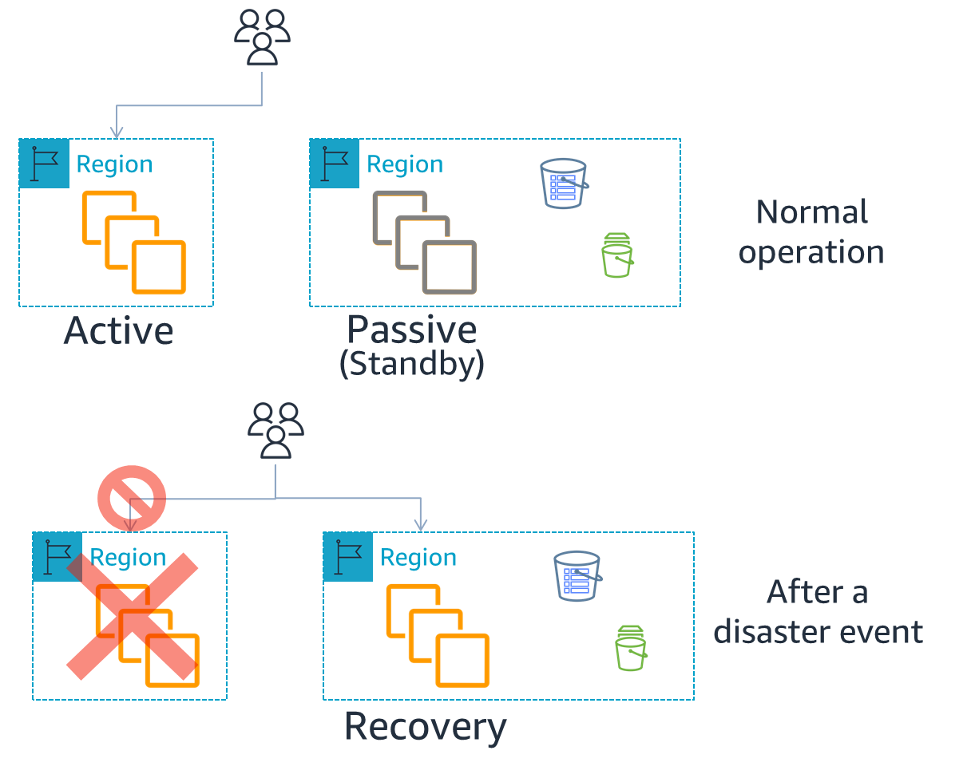
- 모든 서비스(요청에 대한 처리)는 Active 리전에서 처리된다.
- Active 리전에서 처리할 수 없는 경우 Passive 리전으로 복구된다.
- 이후 복구된 시스템(Passive 리전)이 서비스를 할 수 있도록 failover를 취한다.
- failover 이후 모든 요청은 새로 복구된 리전(Passive 리전)에서 처리된다.
이 과정에서 RTO/RPO에 따라 데이터 유실이 발생하며,
failover 전 추가 조치가 필요한 경우 복구 시간은 증가할 수 있다.
비즈니스 목표만 달성되면 RTO/RPO는 충분히 높아질 수 있다.
Active/Active
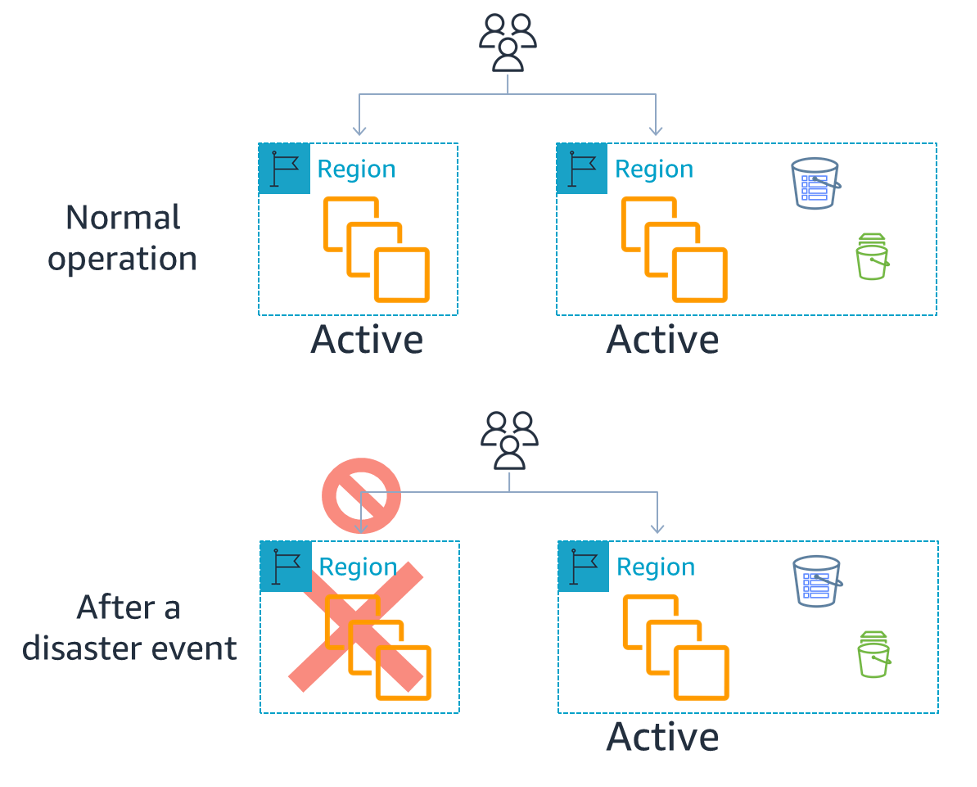
- 두 개 이상의 리전에서 서비스를 나눠 처리한다.
(Load balancing이 쓰이는 듯 함) - 따라서 모든 리전이 Active 리전이다.
- 이 때 각 리전 간의 데이터 복제가 일어난다.
하지만 리전 간 복제와 더불어 데이터를 따로 백업한다. - 한 리전에서 재해가 발생하면 그 리전의 traffic은 다른 (Active) 리전으로 전달된다.
복구 전략
- 백업 및 복구 Backup & Restore
- 파일럿 라이트 Pilot Light
- 웜 대기 Warm Standby
백업 및 복구 Backup & Restore
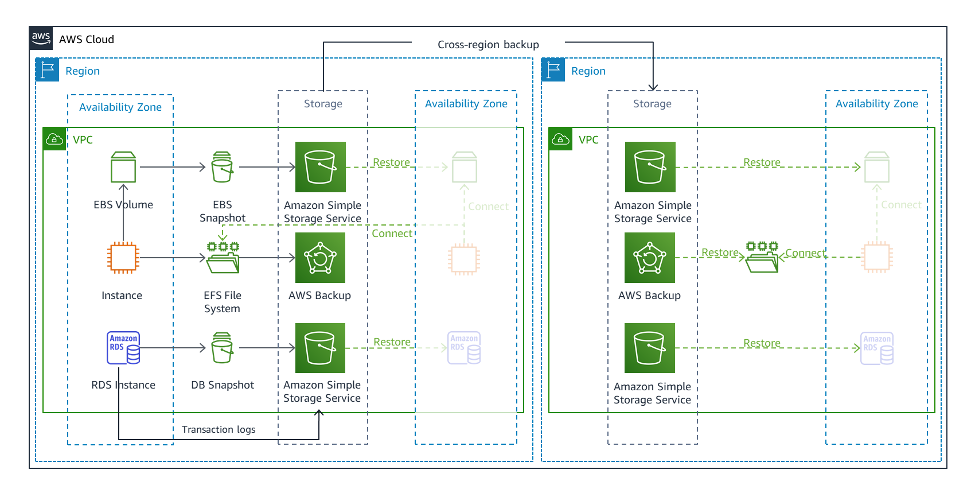
- S3등 다양한 저장소를 활용해 백업 데이터를 저장한다.
- 백업 데이터는 현재 리전 외에 다른 리전으로도 저장한다(Cross-region backup).
→ 백업 데이터로부터 현재 리전에 인프라를 복구할 수도 있고 다른 리전에서 복구할 수도 있다. - 다른 전략에 비해 RTO가 가장 길다.
Amazon EventBridge를 활용해 복구 시간을 줄이고 자동화할 수 있다.
파일럿 라이트 Pilot Light
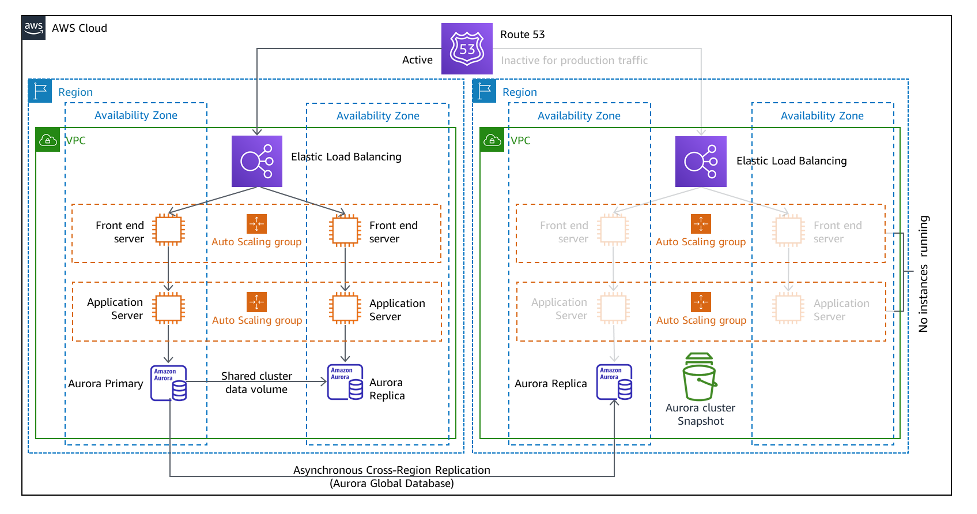
데이터는 실시간으로 복구될 리전 또는 AZ로 복제된다. 복구될 리전은 유휴 상태지만 데이터 저장소와 데이터베이스는 (거의) 최신 상태를 유지하며 읽기 작업을 서비스할 준비가 되어 있다.
그림 상에서 Aurora는 글로벌 데이터베이스로서 복구될 리전의 읽기 전용 클러스터로 데이터를 복제하며, Aurora DB cluster에 대한 백업(Aurora cluster Snapshot)도 필요하다. Aurora에 대한 내용은 다른 분의 블로그 참조.
복구 대상(destination)의 컴퓨팅(EC2 등) 등의 기능적 요소는 기본적으로 비활성화 상태(inactive for production traffic)다. 즉 복구될 리전 또는 AZ는 유휴 상태(idle)다. 이를 구현하는 가장 좋은 방법은 EC2 인스턴스를 배포하지 않는 것이다.
즉 인스턴스를 만들어두지 말고 동작시켜야 할 때 새로 실행하는 것이다. 이를 위해서는 미리 구축된 서버(AMI 등)가 모든 리전에 복사되어 있어야 한다. 따라서 장애 발생 시 복구될 리전 또는 AZ의 모든 인프라 생성 및 동작이 제대로 되기 전까지 어떤 요청도 처리할 수 없다(데이터 손실이 필연적이다).
요약
- DB 데이터는 DB 클러스터와 클러스터의 스냅샷으로 백업한다.
- 모든 컴퓨팅 요소(서버 등)은 AMI로 사전에 구성되며, 모든 리전에 복사되어 있다.
즉 복구될 리전에는 EC2 인스턴스가 있는 게 아니라 빠른 복구를 위한 이미지만 있다. - 장애 발생 시 AMI를 바탕으로 서비스를 복구한다.
DB의 데이터는 당연히 살아있다.
웜 대기 Warm standby
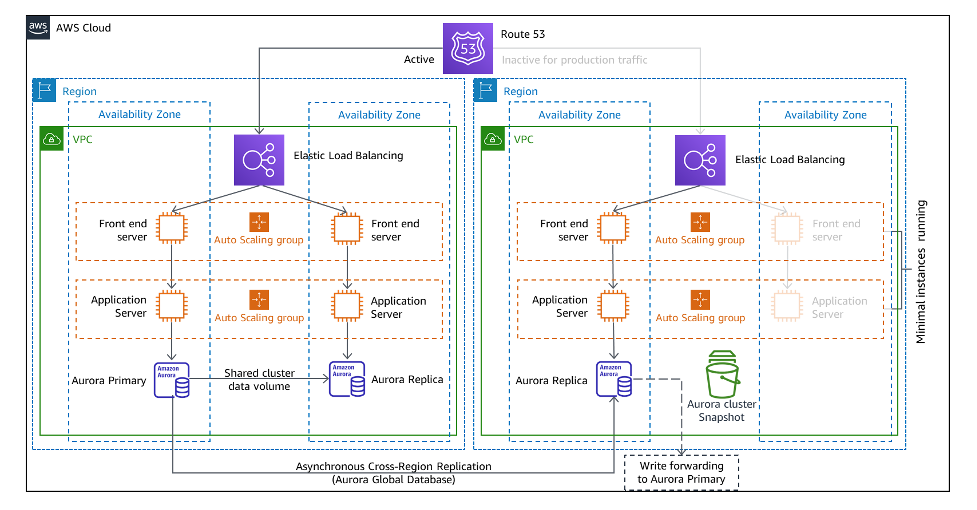
Pilot Light와 마찬가지로 주기적인 백업과 더불어 데이터를 최신 상태로 유지한다.
Pilot Light와의 차이점은 중요 데이터(코어) 뿐만 아니라 인프라도(일부만) 복구될 리전에 백업한다는 것.
단 복구 리전에서는 요청을 처리할 수는 있지만, 적은 용량을 가지고 있으므로 운영 수준의 트래픽(production 수준의 트래픽을 말하는 듯)은 처리할 수는 없다.
