
아래의 글을 보며 적는 글입니다.
Zedd님의 블로그
오늘은 Swift의 성능에 대해서 알아보겠다.
어떻게 하면 더 빠르게, 효율적으로 코드를 짤 수 있을지 알아보자.
Swift 성능 이해하기
Swift의 추상화 메커니즘이 성능에 미치는 영향을 이해하는 가장 좋은 방법은 기본 구현을 이해하는 것이다.
추상화를 만들고, 추상화 메커니즘을 선택 할 때 3가지를 생각해봐야 한다.

- 나의 인스턴스가 Stack에 할당되는지, Heap에 할당되는지?
- 내가 인스턴스를 전달할 때, 얼마나 많은 Reference Counting Overhead가 일어나는지?
- 내가 내 인스턴스의 메서드를 호출 할 때, 그게 Static Dispatch를 통해 일어나는지 Dynamic Dispatch를 통해 일어나는지?
위 사진에서 오른쪽으로 갈 수록 성능은 저하되고, 왼쪽으로 갈 수록 성능은 좋아진다.

그럼 먼저 할당(Allocation)부터 시작하자.
할당(Allocation)
Swift는 자동으로 메모리를 할당하고, 해제한다. 그리고 메모리 중 일부는 Stack에 할당된다. 그리고 Stack은 LIFO(Last In First Out)로 매우 단순한 데이터 구조이다.
Stack의 마지막, 즉 Top으로만 Push가 가능하고 Pop역시 Top에서만 가능하다. 그러니까 Stack끝에 포인터만 유지를 한다면, Push, Pop을 구현할 수 있게 된다. 우리는 이를 Stack Pointer 라고 부른다.
그래서 우리는 함수를 호출 할 때, 메모리를 먼저 할당해야 한다.
메모리를 Stack Pointer가 가리킴으로서 메모리를 할당할 수가 있다.
그리고 함수가 끝나면 Stack Pointer를 줄이기 전에 있던 곳으로 증가 시킴으로 써 그 메모리를 할당 해제 할 수 있다.

모두 O(1) 으로 굉장히 빠르다. Push, Pop 모두 한 곳에서 처리하기 때문이다.
하지만, 대조적인 위치에는 Heap 이라는 데이터 구조가 있다.
Heap은 Stack보다는 더 동적이지만, 효율은 Stack 보다는 덜 하다.
Heap을 사용하면 Stack이 할 수 없는 일을 할 수 있다!
바로 Dynamic LifeTime을 가진 메모리를 할당 할 수 있다.

Heap에 메모리를 할당하려고 하면, 실제로 Heap 데이터 구조를 검색하여 사용되지 않은 적절한 크기의 블록을 찾아야한다. 그리고 모든 작업이 끝나고, 할당을 해제하려면 해당 메모리는 또 적절한 위치로 다시 삽입 해야한다.
Stack보단 훨씬 복잡하다. 그냥 그렇게 보인다.
그런데 가장 복잡한 것은, 여러 스레드가 동시에 Heap 메모리를 할당할 수 있기 때문에, Heap은 Locking 또는 동기화 메커니즘을 사용해서 무결성을 보호해야 한다.
그러니까, Heap 메모리를 여러 스레드에서 사용할 수 없게 해야한다는 것이다. 여기저기 사용하다보면 생기는 문제가 한두가지가 아니기때문에 이런 부분에서 가장 큰 비용이 발생한다고 한다.
이렇게 속도가 오래 걸리는 부분들도 조금만 신중히 생각하면, 성능이 크게 향상될 수 있다.
각 호출에 대한 할당 방법
CallByValue

위 코드를 살펴보자.
먼저 Point 라는 구조체를 만들었다. 그리고 x,y 프로퍼티와 draw() 라는 메서드가 존재한다.
그리고 그 아래에는 만든 구조체를 point1 인스턴스를 만들어서 넣고, point2 에 point1 을 복사하고, point2의 x 프로퍼티에 5를 넣었다!
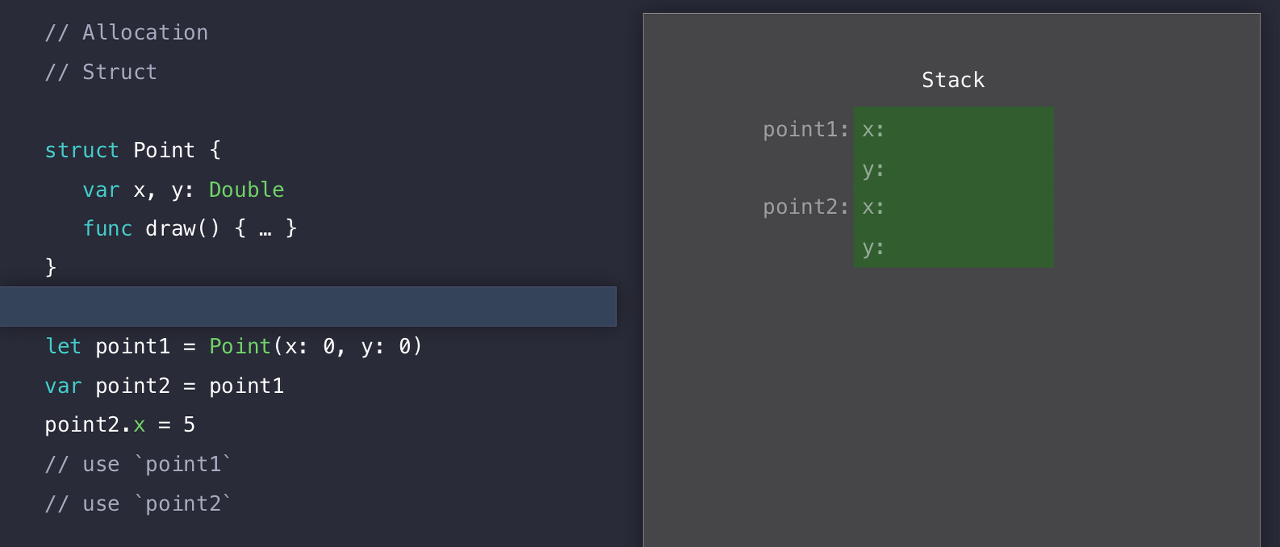
우리가 코드를 실행하기 전에 point1 , point2 인스턴스에 대해, Stack 에 공간을 할당했다. Point는 구조체이기 때문에 Stack에 저장된다.
따라서 우리가 Point(x:0, y:0) 인 인스턴스를 만들 때, Stack에 이미 할당된 메모리를 초기화하는 것 뿐이다. 여기서 할당하고 초기화 하는게 아니란 소리다! (아하!)
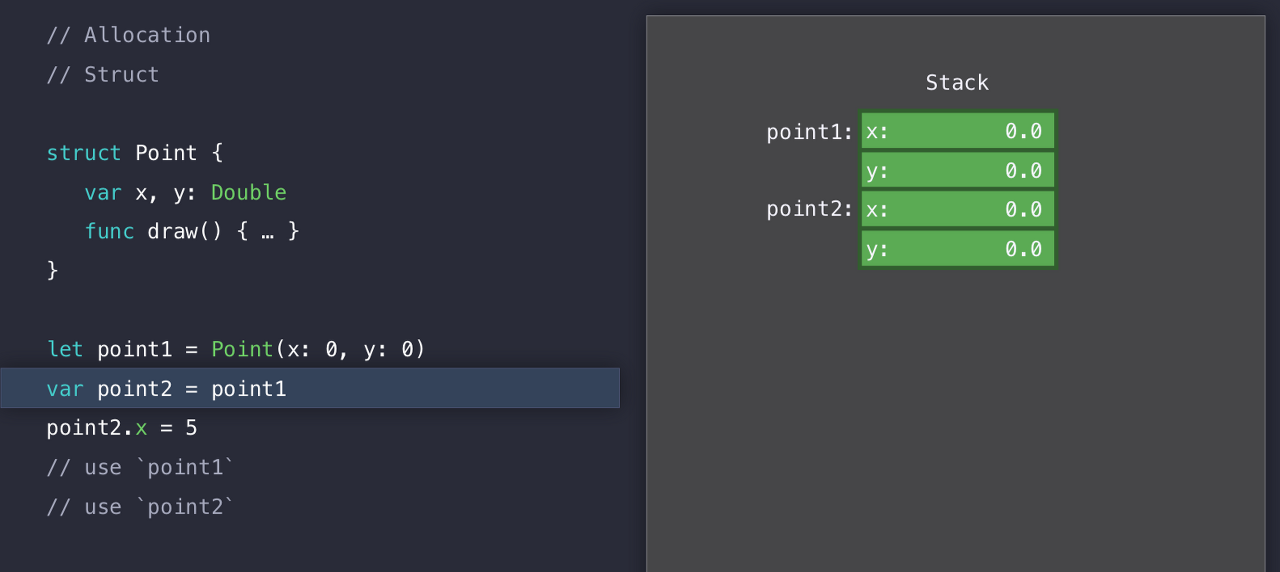
그리고 아래의 point2에 point1을 초기화할 때에는 이미 만들어놓은 복사본을 만들고, Stack 상에서는 이미 할당했던 메모리에 초기화 하는 것이다.
즉, point1과 point2는 독립적인 인스턴스이다.
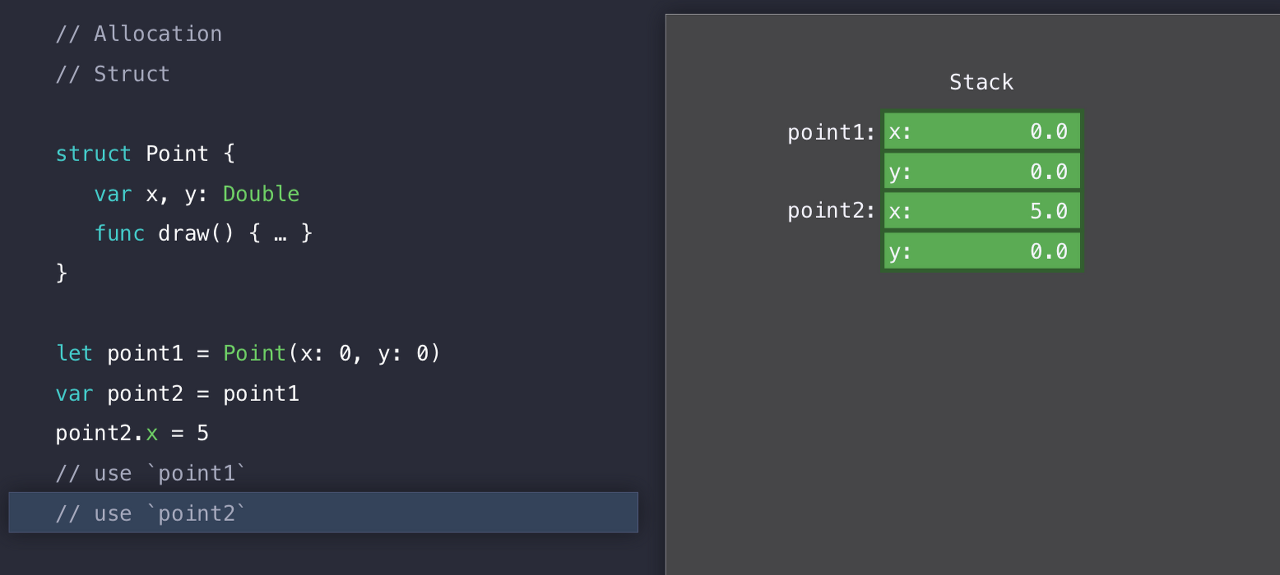
자 그리고 마지막 코드를 보면, point2의 x 프로퍼티에 5를 넣었다.
하지만, point1과 point2는 독립적인 인스턴스이기 때문에, 2의 x 프로퍼티가 5가 됐다고 해서 1의 x 프로퍼티가 5가 되진 않는다. 당연한 소리이다. 서로 다른 인스턴스이기 때문에 그렇게 일어나는 것이다.
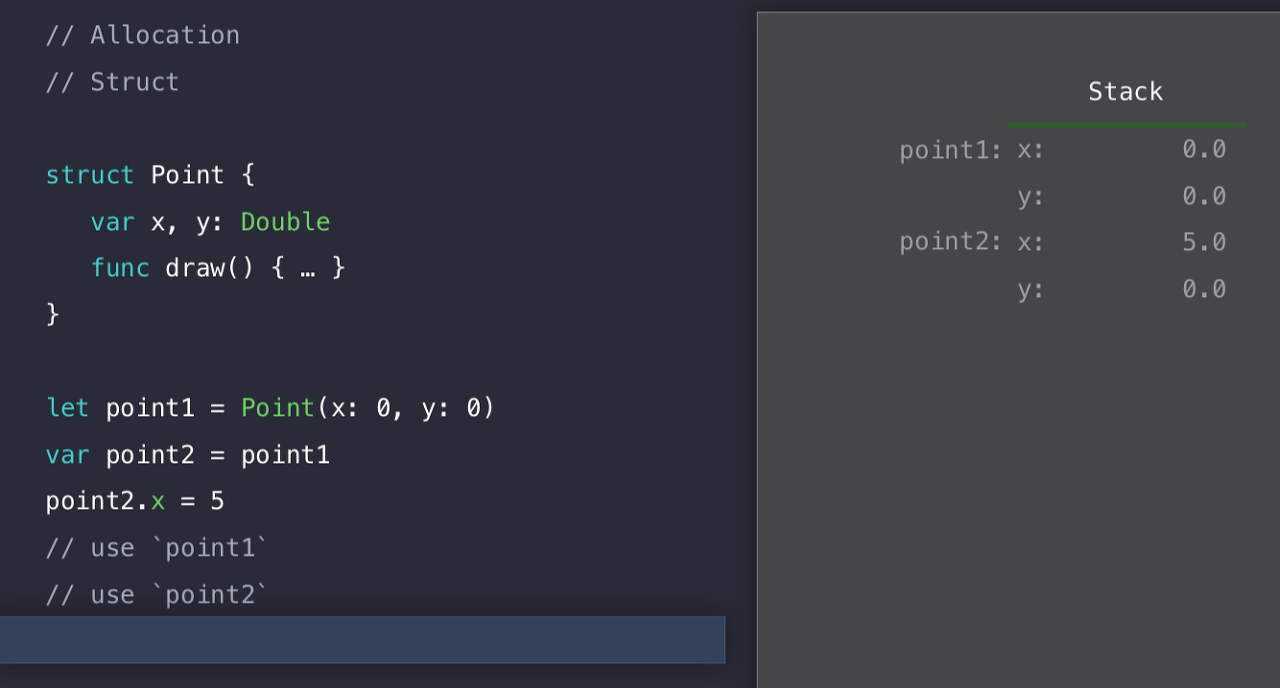
우리가 point1 을 사용하고, point2를 사용하고 이제 다 끝나면, Stack 포인터를 점차적으로 증가시키면서 point1과 point2에 대한 메모리 할당을 쉽게 해제 할 수 있게 된다.
자! 그럼 똑같은 코드를 Class로 만들어보자.
CallByReference
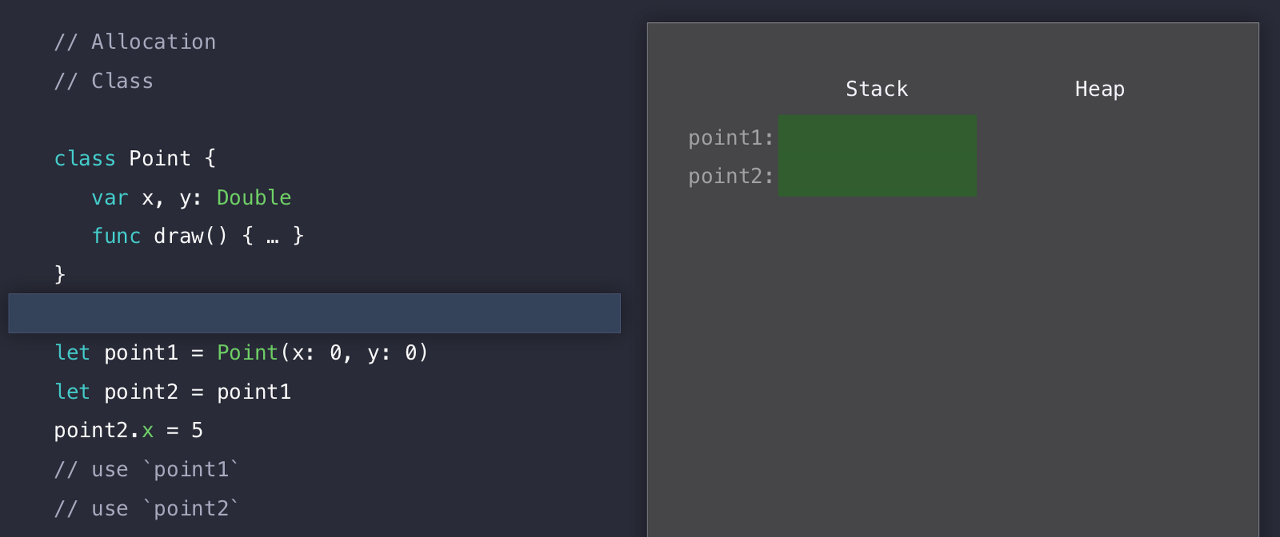
이름과 프로퍼티, 인스턴스 모두 다 똑같이 생성했다. 단지 선언을 Class로 선언한 것이다. 코드를 실행하기 전에 이미 Stack에 point1과 point2에 대한 메모리가 할당이 된다.
하지만, 실제로 아까처럼 Stack의 line에 프로퍼티를 저장하는 것이 아니라, point1과 point2에 대한 레퍼런스를 위해 메모리를 할당한 것이다. 우리가 Heap에 할당할 메모리에 대한 참조인 것이다! 실질적으로 클래스에서 메모리를 사용하는 곳은 힙인 것이다. Stack은 그저 레퍼런스를 위해서 할당한 것 뿐이다.
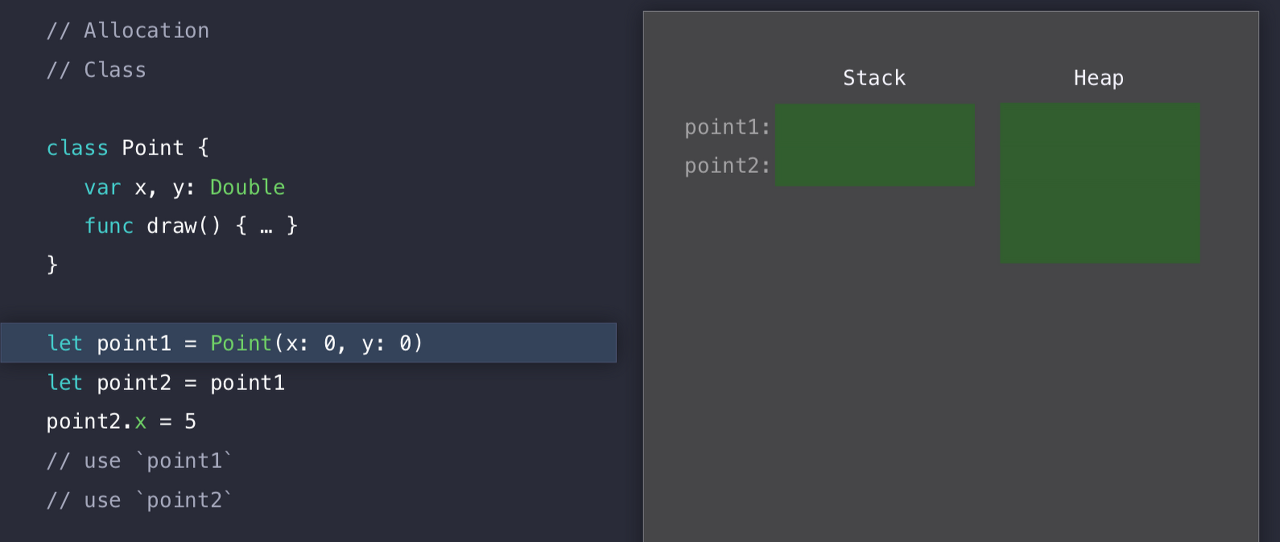
따라서 우리가 Point(x:0, y:0) 이라는 인스턴스를 만들면, Swift는 Heap을 lock 하고 (무결성을 위해서) 해당 크기의 메모리 블록을 검색하게 된다.
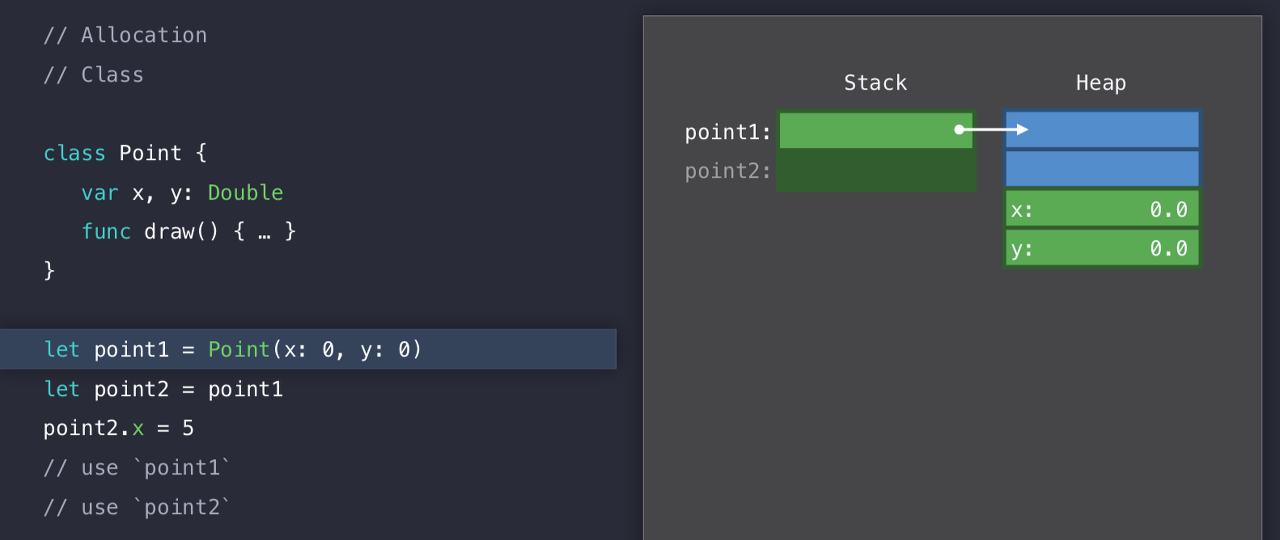
이렇게 공간을 찾고?
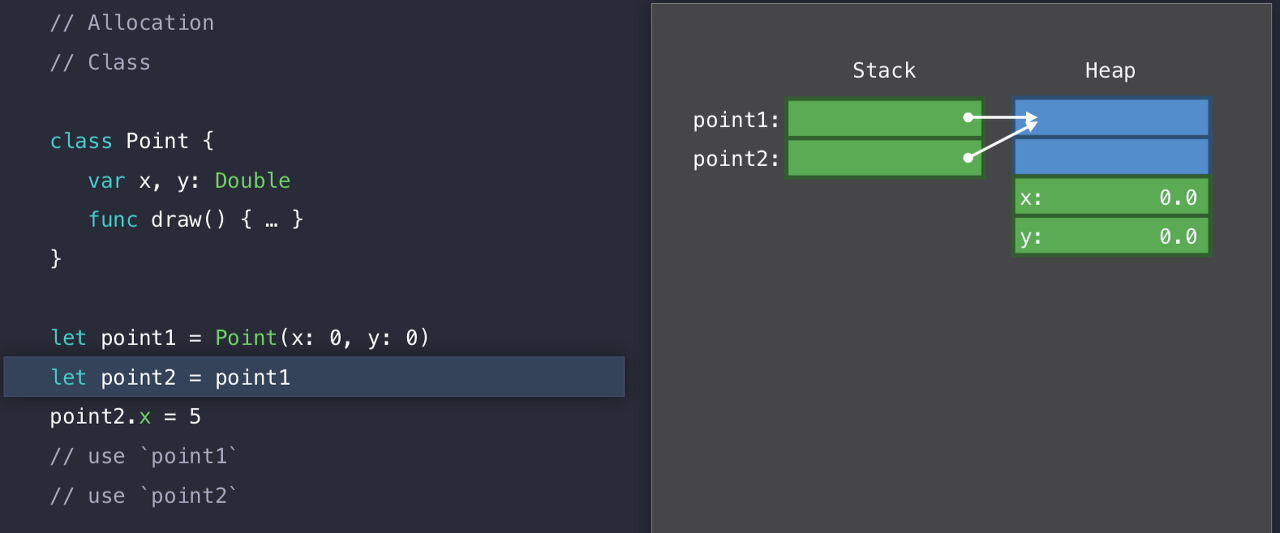
다음 것도 복사개념이 아닌 주소를 공유하고 있는 개념으로 Stack에 할당된다.
그런데 Heap에 공간이 이상하다. Stack에서는 2개만 할당을 받았는데, Heap은 4개를 할당받았다. 이유는 Point가 클래스이기 때문에, x와 y를 저장할 공간 이외에도, Swift가 우리를 대신하여 관리하기 위한 공간을 더 할당하게 된다. point2에 point1을 넣을 때, 구조체 처럼 내용을 복사하지 않고 '레퍼런스'를 복사하게 된다.
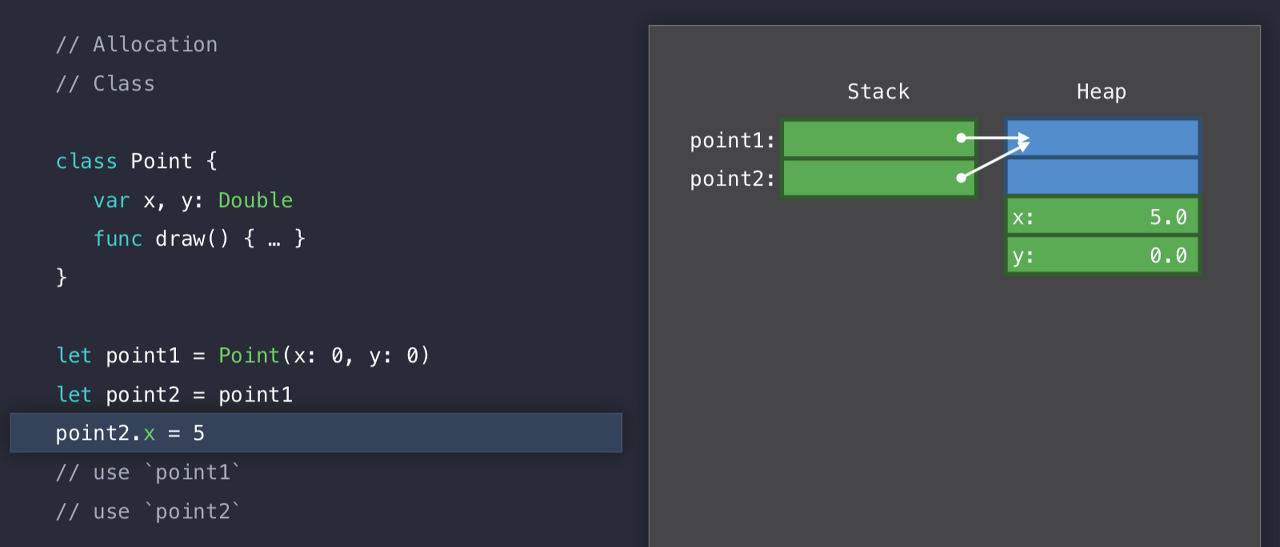
따라서 point2의 x 프로퍼티에 5를 넣어도, point1 과 point2가 똑같은 곳을 참조하고 있기 때문에, point1의 x 값도 5가 나오는 것이다.
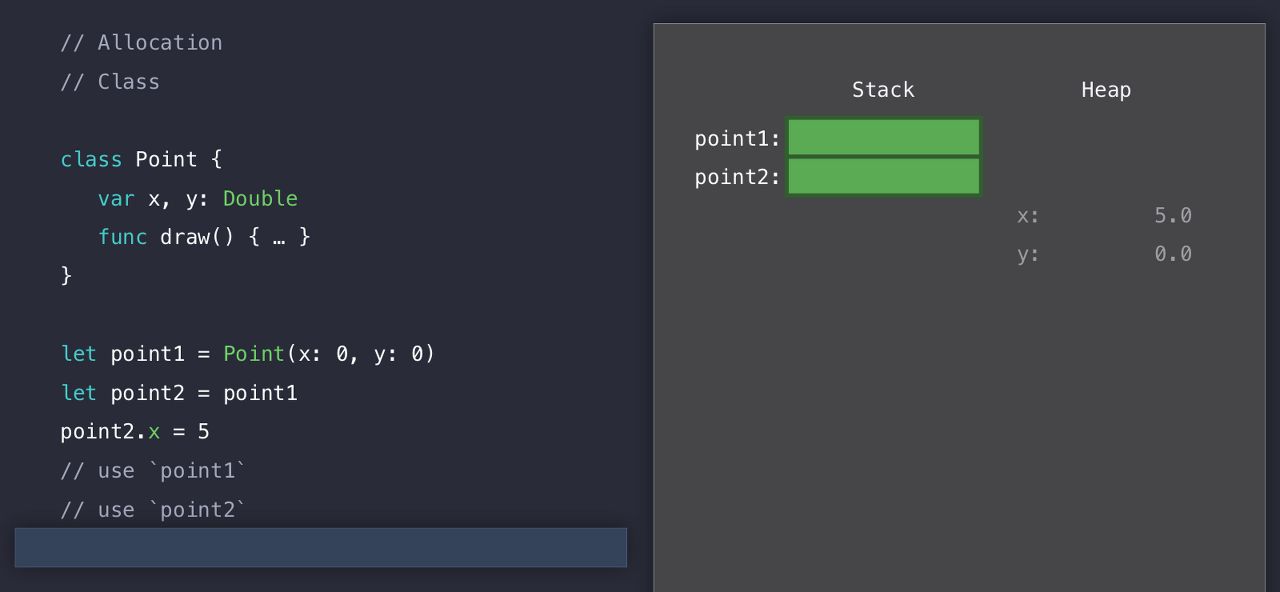
자, 이렇게 다 사용하고 난 뒤에는 Heap을 잠그고(lock) 사용하지 않는 블록들을 적절한 위치로 재삽입을 하게 된다.
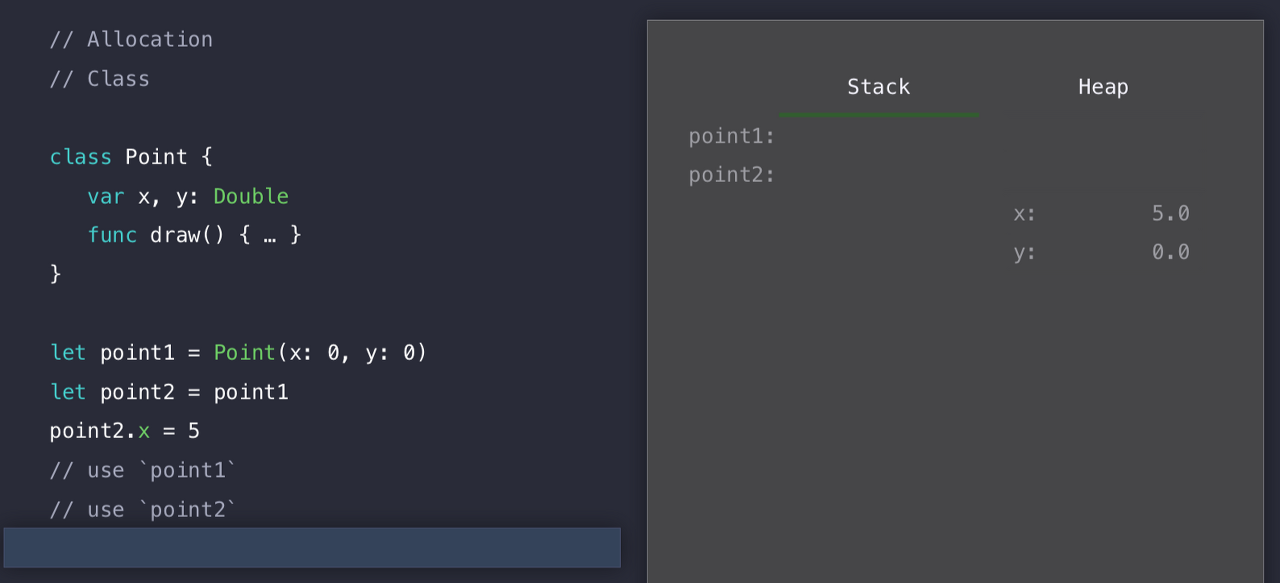
그러고 나서, Stack을 Pop 할 수 있다.
호출 정리
이렇게 Struct, Class로 메모리 할당을 해봤다.
Class는 Heap 할당을 필요로 하기 때문에 Class 가 Struct보다 생성하는 비용이 더 많이 들게 된다. Class는 Heap에 할당되고, 레퍼런스 체계를 가지므로 Class에는 ID 및 간접 저장소와 같은 특성이 존재한다.
만약 우리가 추상화를 할 때 이런 특성(ID, 간접 저장소)이 필요하지 않다! 라고 하면 우리는 Struct를 사용하는 것이 효율성 측면에선 좋은 것이다.
다른 한 가지 예
WWDC에서 다른 한가지 예를 더 들어줬다.
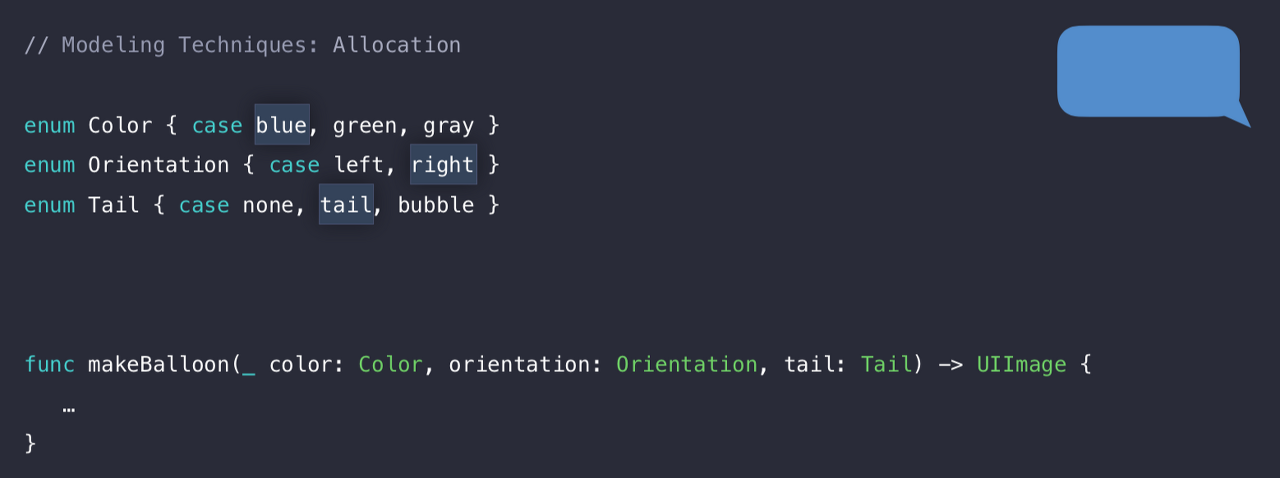
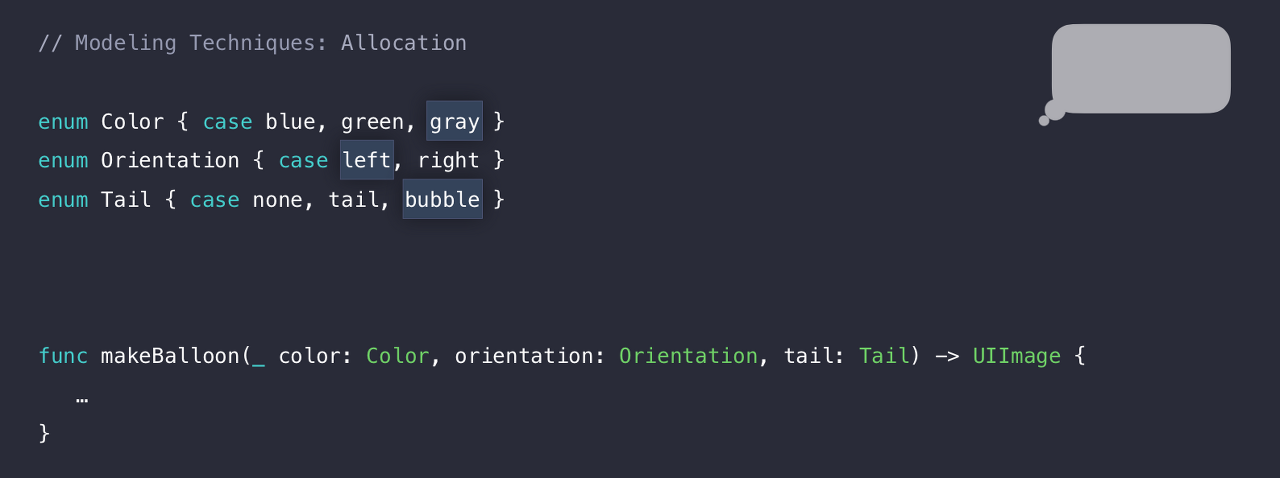
enum의 case들을 이용하여 여러가지 모양의 말풍선을 만드는 코드이다.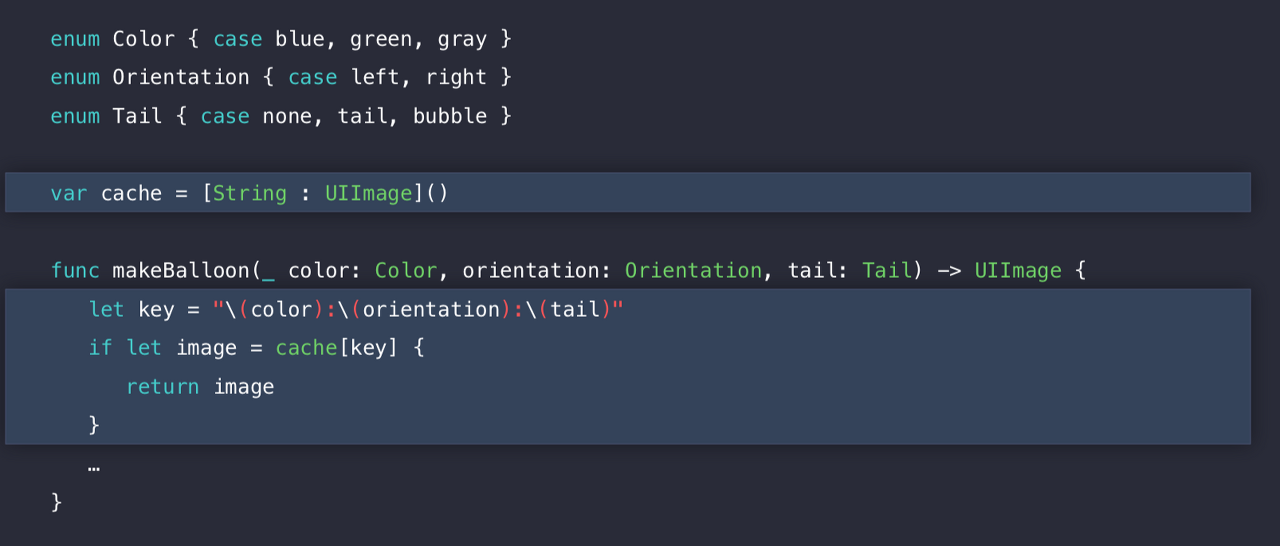
위 코드의 makeBallon 함수는 사용자가 스크롤 중에 빈번히 호출한다고 가정해보자. 그래서 빠를 필요가 있고 cache를 Dictionary로 만들었다. 즉, 같은 말풍선을 한번 더 만들 필요가 없다라는 뜻이다.
딕셔너리의 key는 String, Value는 UIImage이다. 그럼 Key를 조금 살펴보자.
"String" 이란 타입은 여기서 강력한 타입은 아니다. 내가 그냥 이 캐시라는 딕셔너리에 Key로 "Kirri"를 넣을 수도 있다. 그렇다. 안전하지 않다라는 의미이다. 또한, String은 실제로 Heap에 간접적으로 캐릭터들의 컨텐츠를 저장하기 때문에 많은 것을 나타낼 수 있다. 이게 무슨 말이냐면, 우리가 cache 라는 딕셔너리를 야심차게 만들었지만, cache 가 hit 됐어도 Heap할당이 발생한다라는 것을 의미한다.
그럼 이걸 조금 개선을 해보는 것이 좋겠다.
개선 정리

Attributes 라는 구조체를 만들고 딕셔너리의 Key가 될 수 있도록 Hashable을 준수시켜줬다. 그리고 이 Attributes를 우리 cache 딕셔너리의 Key 값으로 줬다.
이건 어떤 것을 의미하게 되는 건가?
우리가 아까 살펴본대로 Attributes는 구조체이기 때문에 Stack에 프로퍼티들을 할당할 것이다.
그렇다라는 말은 Heap할당이 필요하지 않게 된다 라는 말과 동일하다.
즉, 메모리 할당에 대한 Overhead가 없다. 그리고 String때와 달리, 우리가 실수로 "Kirri"와 같은 Key를 넣을 위험도 사라지게 됐다.
이렇게 안전하고 Heap 할당이 없으니 훨씬 더 빨라질 것이다.
Reference Counting
이제 두번째 매커니즘인 Reference Counting에 대해 알아보자.
Swift 는 Heap에 할당된 메모리를 할당 해제하는 것이 안전 하다라는 것을 어떻게 알까?
Swift는 Heap에 있는 인스턴스에 대한 총 레퍼런스 카운트를 유지한다. 레퍼런스 카운트는 인스턴스 내부에 존재한다. 인스턴스 자체에 레퍼런스 카운트를 유지한다. 레퍼런스를 추가하거나 제거하게 되면, 해당 레퍼런스 카운트가 증가/감소 하게 된다.
이 카운트가 0이 되면 Swift는 아무도 Heap에서 이 인스턴스를 가리키고 있지 않으며, 메모리를 할당해제 하는 것이 안전하다는 것을 알게 된다.

우리가 Reference Counting 에서 염두에 두어야 할 것은, 실제로 단순히 +1,-1 하는것 이상으로 이 카운팅 작업은 실제로 빈번히 수행된다. 먼저, 단순히 증가 / 감소를 위해 몇가지 간접적인 단계가 존재한다.
그러나, 더 중요한 것은 Heap할당과 마찬가지로 레퍼런스가 여러 스레드에 의해 동시에 추가 또는 제거될 수 있기 때문에 Thread Safety를 고려해야 한다. 실제로 Atomically 하게 레퍼런스 카운트가 증가 또는 감소가 되어야 한다. 그리고 참조 카운팅의 빈도로 인해 이 비용이 증가할 수 있게 된다.

다시 Class로 선언했던 코드로 가보자.
Class이니 Heap 할당이 일어난 것이고, 레퍼런스 카운트가 있게 될 것이다.
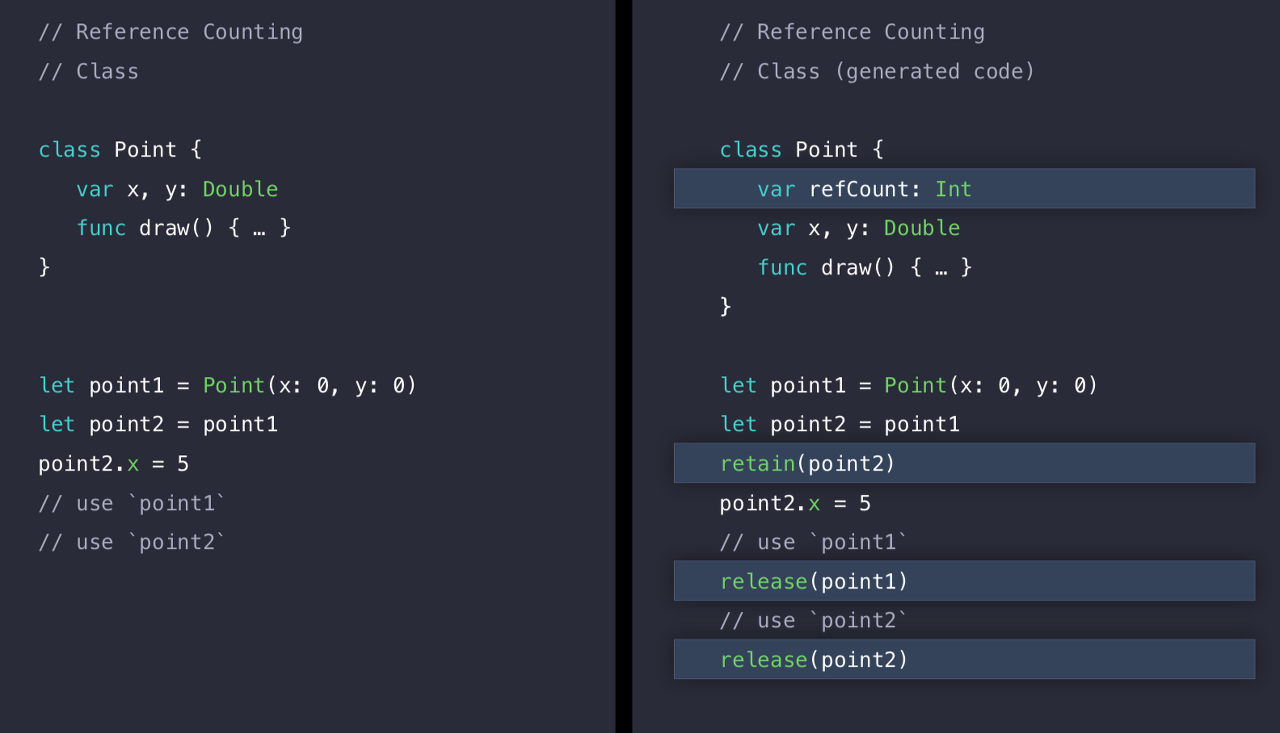
코드를 수행하게 되면 Swift 컴파일러는 오른쪽의 코드를 삽입하게 된다.
아까 인스턴스 자체에 레퍼런스 카운트를 유지한다고 했었다. 그래서 Point Class 안에 refCount 라는 프로퍼티가 생겼고, point1을 point2에 넣을 때, 레퍼런스 카운트가 하나 증가한 것이니 retain을 시켜주고, point1, point2를 각각 다 사용하면 release를 시켜주는 것을 볼 수 있다.
이제 이 코드들을 하나씩 살펴보자.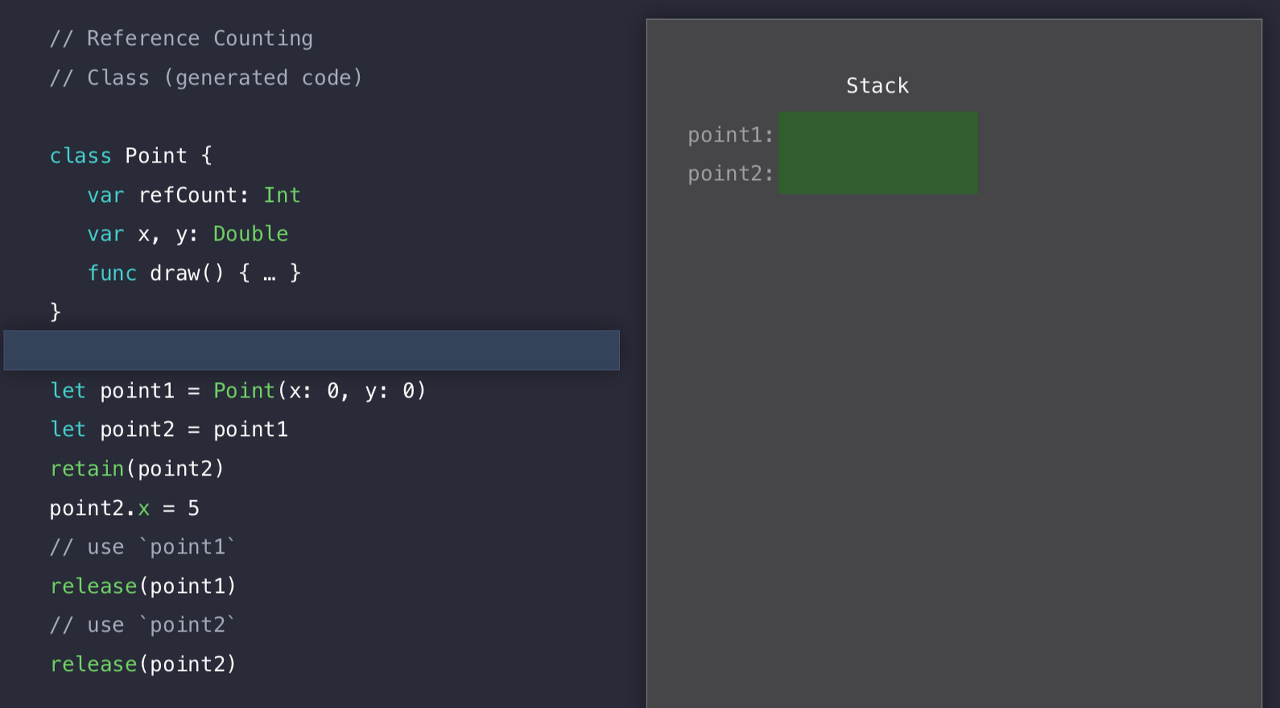
아까처럼 코드가 실행되기도 전에 point1과 point2에 대한 메모리 공간을 Stack에 할당하고,
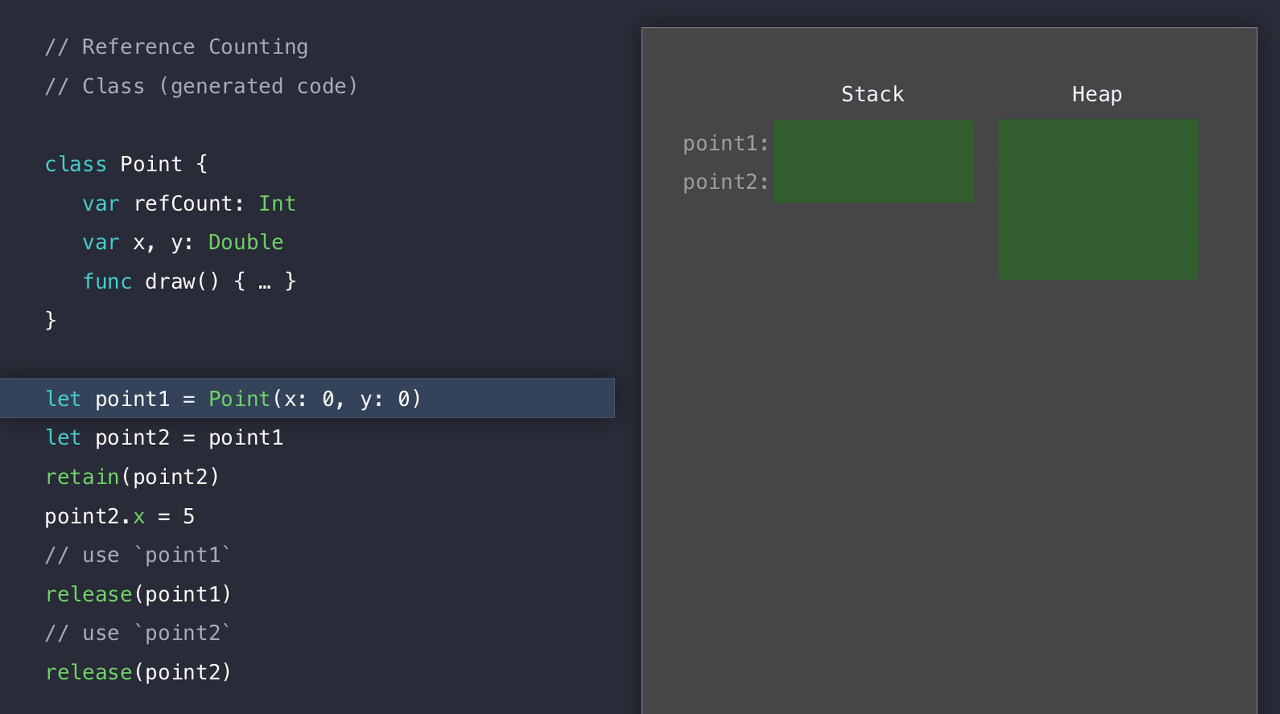
여기서 Heap할당이 시작된다. 똑같이 공간을 검색하고 메모리 할당을 하는 그런 스탠스..
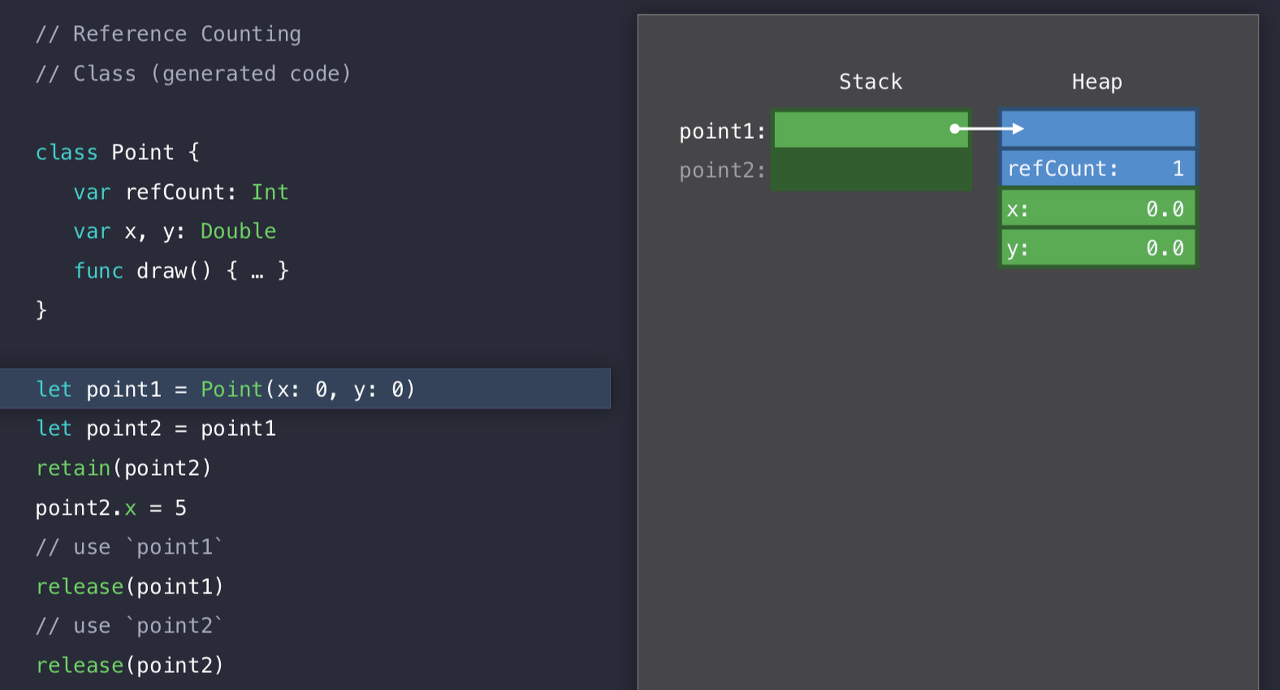
그럼 레퍼런스 카운트가 1이 된다.
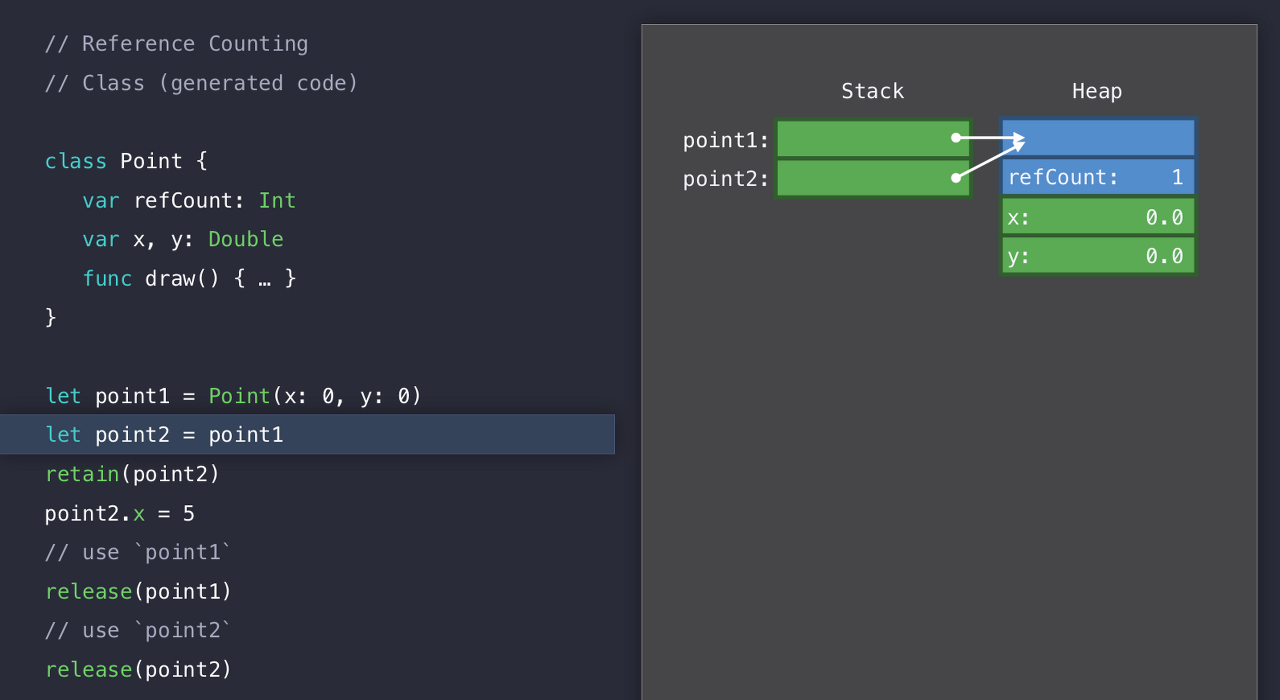
여기서 point2에 point1을 넣긴 하지만, 아직 refCount는 1이다. 아직 retain을 하지 않았기 때문이다.
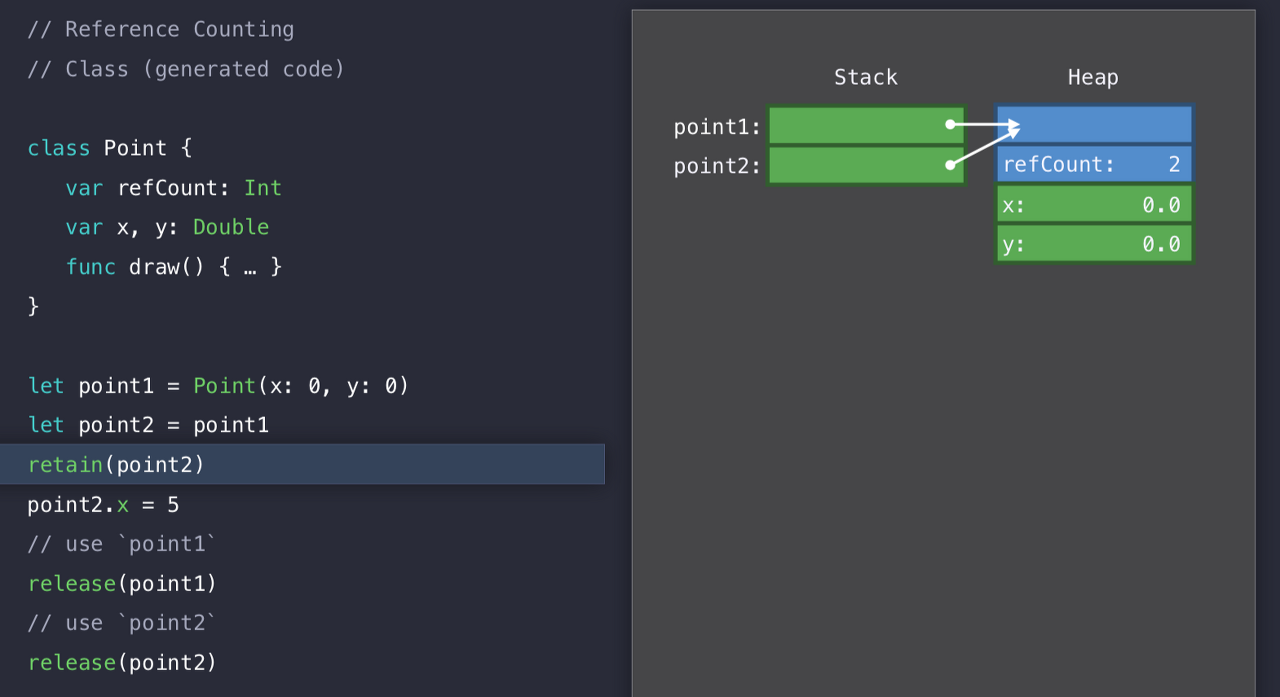
이렇게 point2에 대해 retain을 하면, 그제서야 refCount가 2가 된다. 주소를 공유하기 때문에 x를 바꾸면 다 같이 바뀐 모습으로 보일 테고..
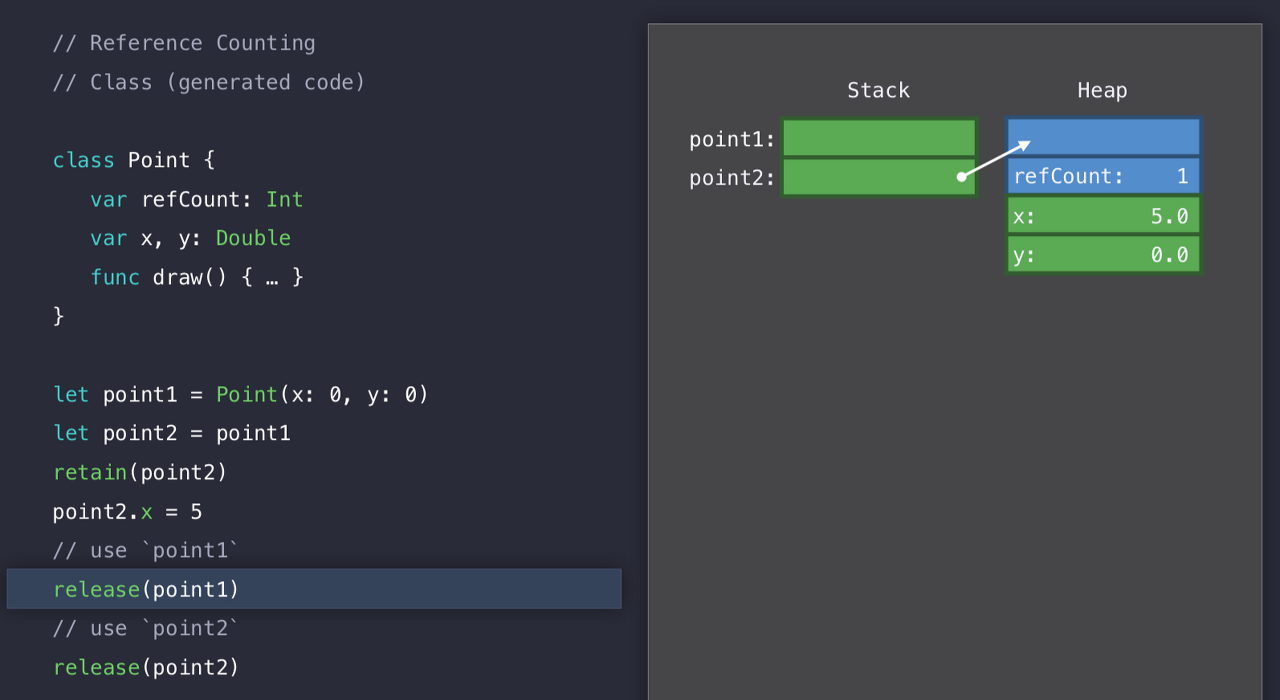
point1을 다 쓰면, point1 을 release 한다. 그럼 refCount는 1이 된다.
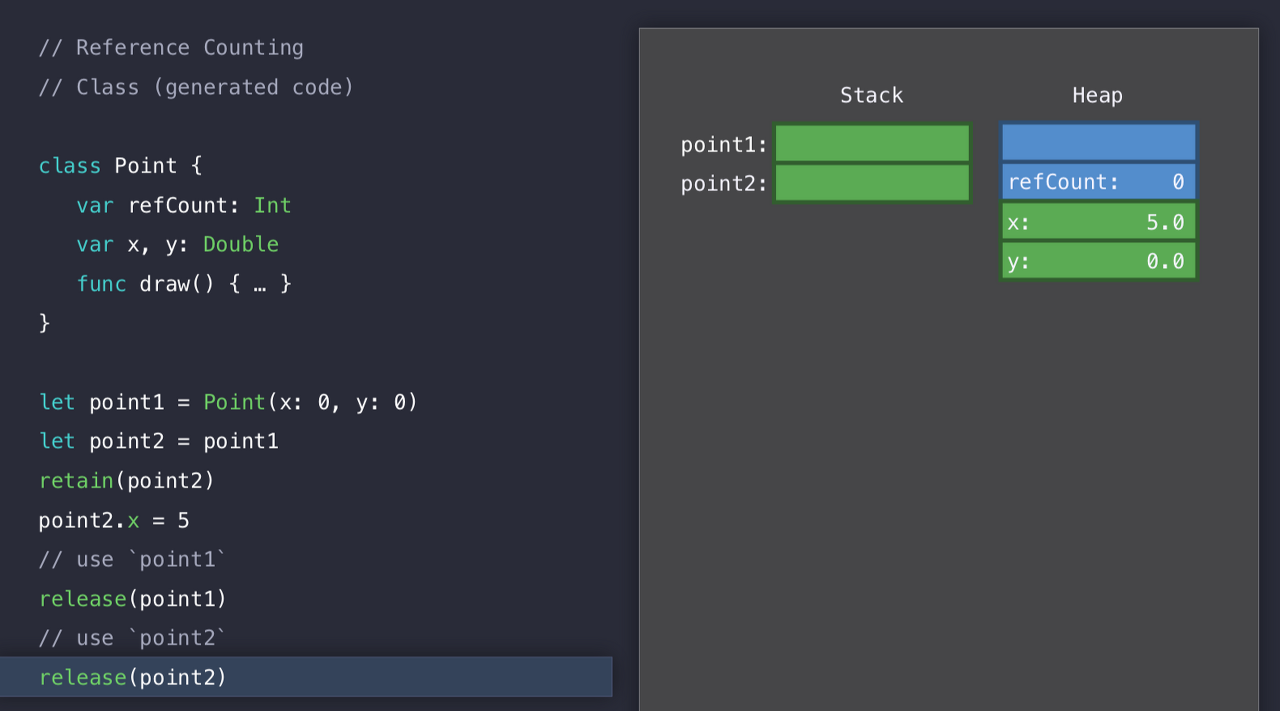
같은 이치로 point2도 release 하면 refCount는 0이 된다.
이 때 Swift는 메모리 해제를 해도 안전하다라는 것을 알게 된다.
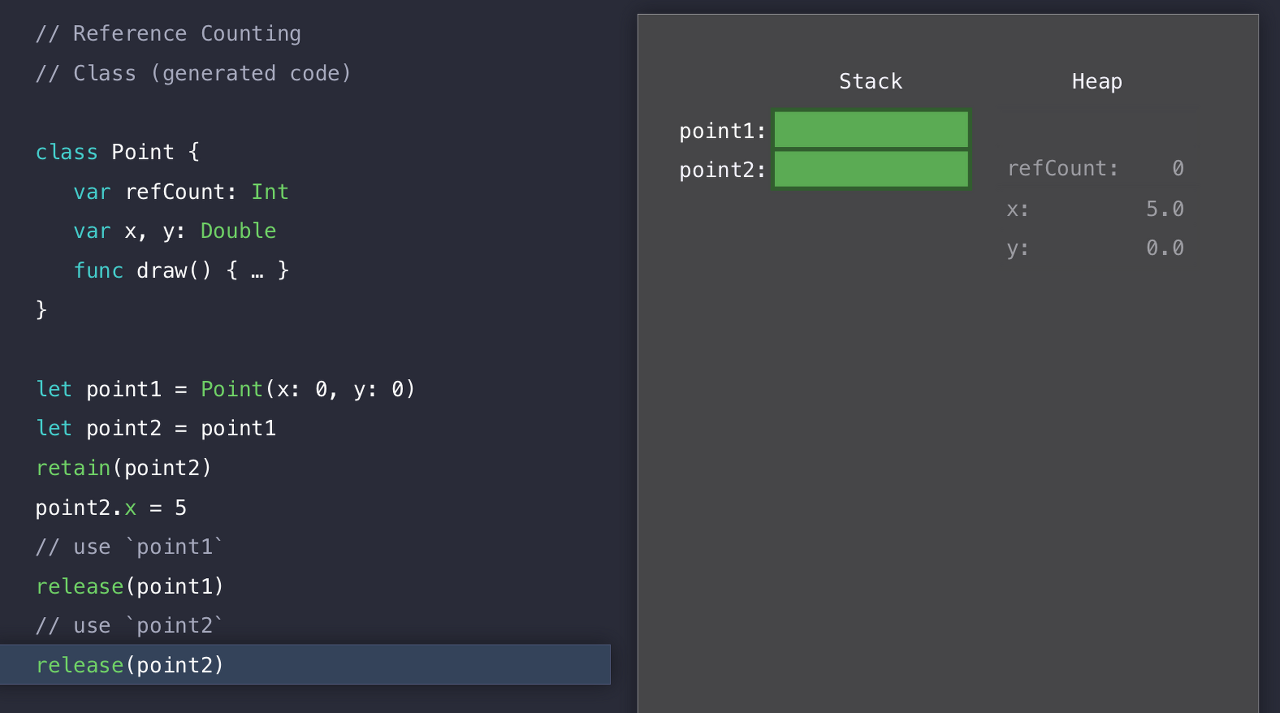
더이상 point인스턴스를 사용하는 참조가 없기 때문이다. 따라서 Swift는 Heap를 lock 하고, 해당 메모리 블록을 반환하게 된다.
Reference Counting을 Struct 관점에서 보기
이 레퍼런스 카운팅을 Struct로 얘기 해보자.
근데 Struct에 Heap 할당은 없다. 즉, Struct는 레퍼런스 카운팅에 대한 오버헤드가 없다.

애플이 복잡하다고 보여준 Struct이다.
Label이라는 Struct를 만들고 그 안에 String, UIFont 타입을 생성했다. 참고로 UIFont는 Class이다.
그리고 앞에서 얘기 했듯이 String은 Contents를 Heap에 저장한다.
String은 Contents를 Heap에 저장한다.
UIFont는 Class이다.
둘 다 레퍼런스 카운트를 계산해야하는 것들이다.
Struct라고 레퍼런스 카운트를 하지 않아도 될 것 같았지만, 막상 까보면 필요한 부분이 무조건 있었다라는 의미이다.
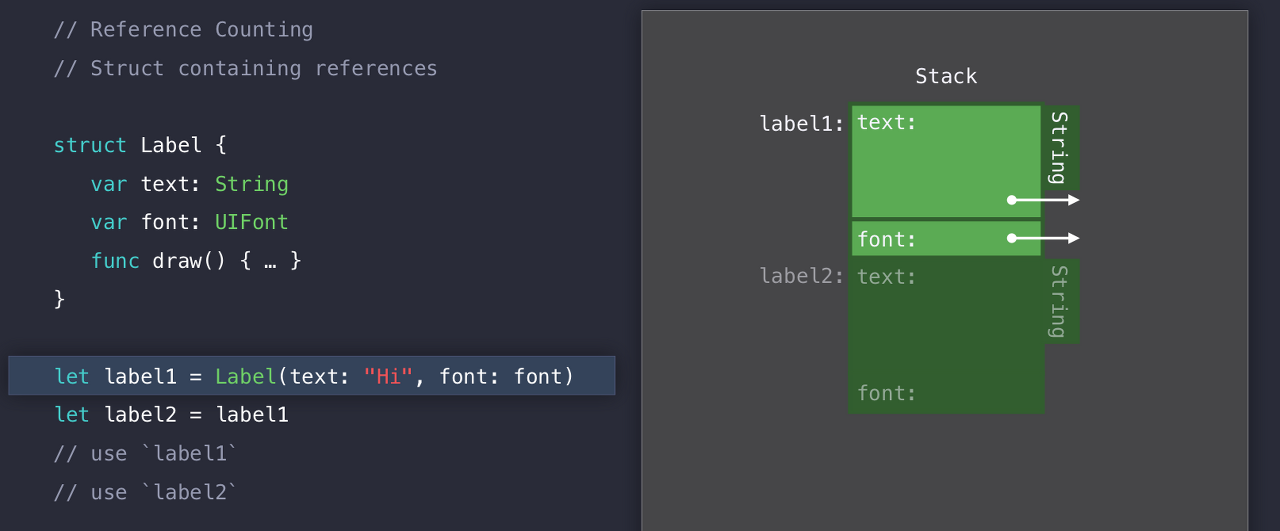
그래서 위에서 했던것과 같이 일단 label1과 label2에 대한 Stack메모리 공간을 할당하게 된다. 여기에는 레퍼런스를 저장한다. text,font 둘 다 Heap을 사용하니 label1 을 생성했을 때는 위와 같은 그림이 된다.
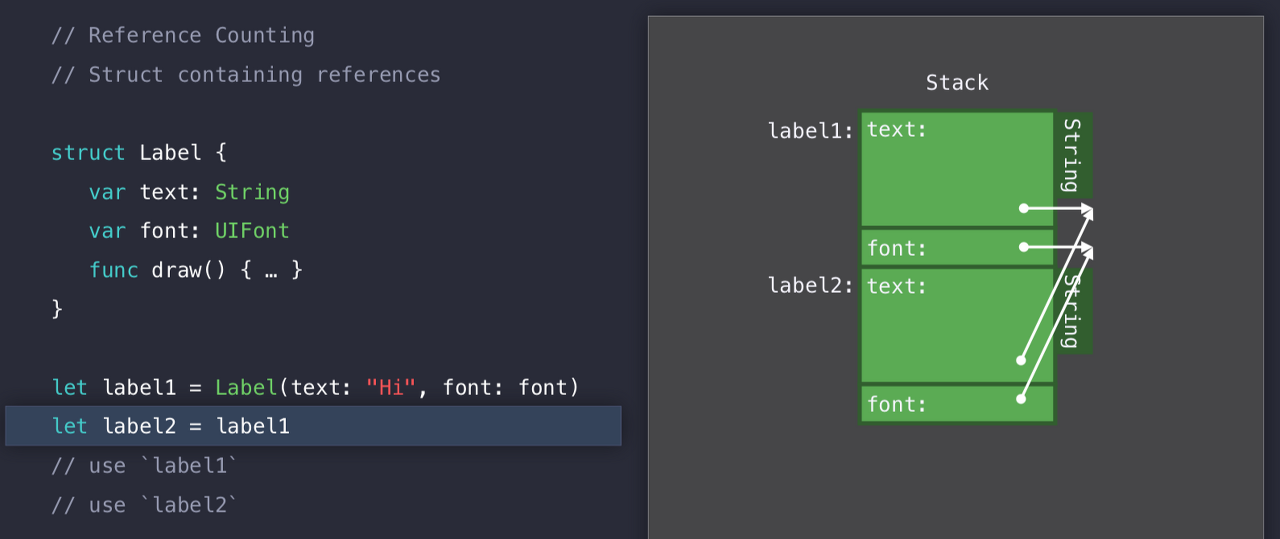
label1을 label2에 넣을 때는 위와 같은 그림이 될 테다.
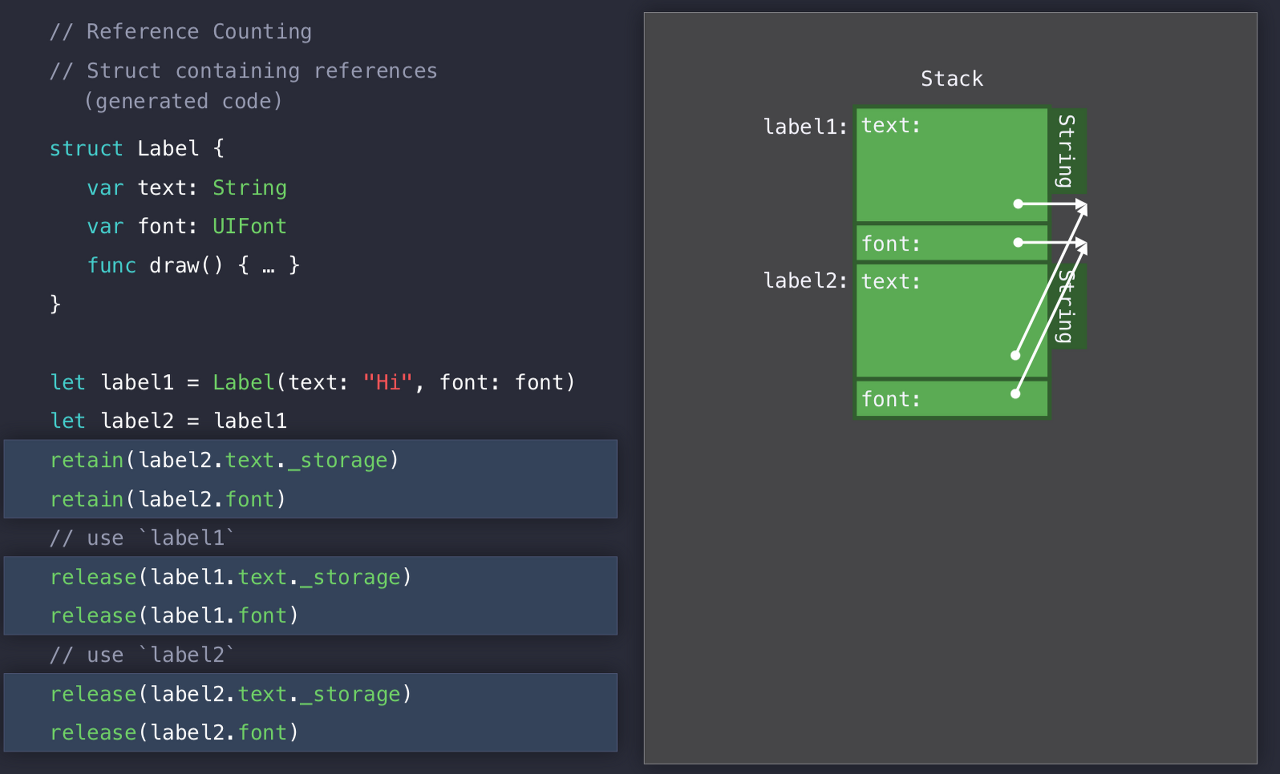
컴파일러가 구성하는 코드는 위와같이 될 것이다.
label1을 label2에 넣고 각 프로퍼티에 대해 retain을 해주면서 레퍼런스 카운트를 증가시키고, 각각 다 쓰면 프로퍼티들을 release 해준다.
프로퍼티들이 둘 다 Heap에 저장되어 있어서 2번씩 다 해줘야 한다..
다시한번 상기시켜 주지만, Label 은 Struct이다. 이럴꺼면 왜 사용했나 싶기도 하다..
실제로, Struct안에 이렇게 레퍼런스가 있는 경우, 레퍼런스 수에 비레하여 레퍼런스 카운팅 오버헤드를 지불하게 되며, 둘 이상의 레퍼런스가 있는 경우, Class보다 레퍼런스 카운팅 오버헤드가 더 많이 유지된다.
(이럴꺼면 그냥 Class로 만드는게 낫지 않음?)

이런 상황이 되는 것이다.
다른 예제도 보자.
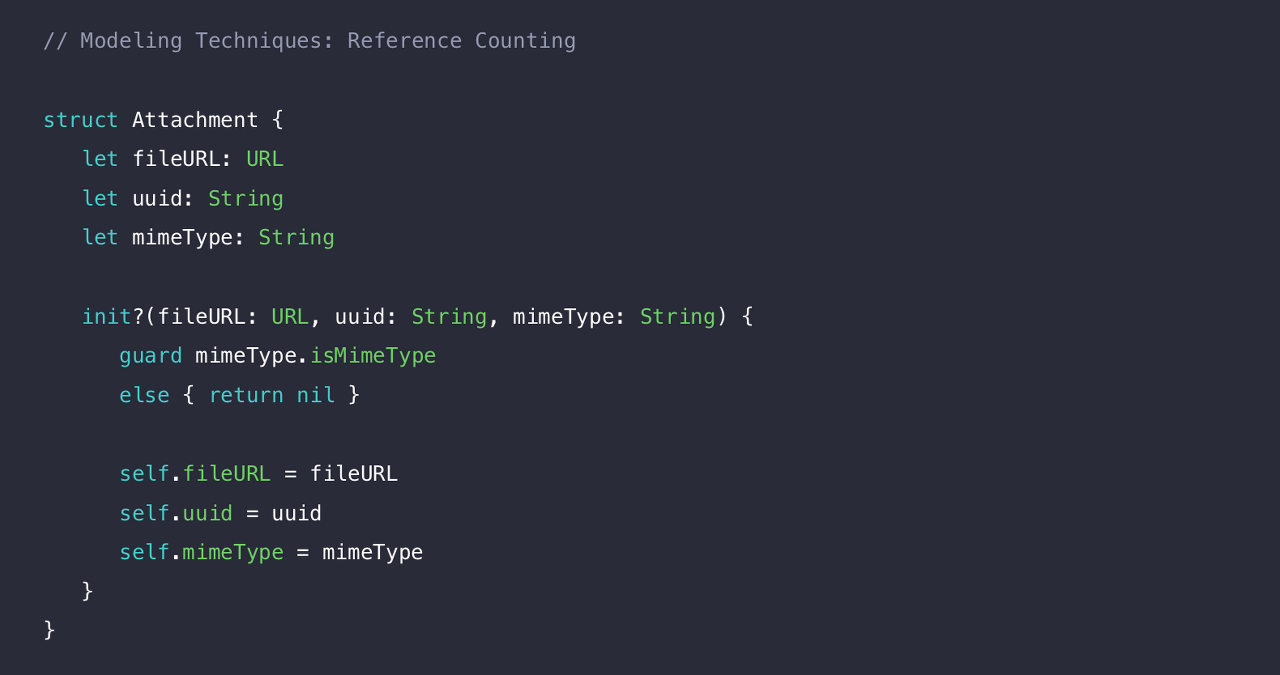
메시지 첨부기능을 추상화한 Attachment 라는 Struct를 만들었다.
fileURL은 첨부파일의 경로를 의미하고, uuid는 서로 다른 클라이언트에서 첨부파일을 인식할 수 있도록 임의로 생성된 식별자, 그리고 mineType은 첨부파일이 JPG/PNG/GIF 인지 등을 저장하는 프로퍼티이다.
이니셜라이저는 지원하지 않는 형식이면 nil을 반환하는 실패가능한 이니셜라이저 이다. 우리가 위에서 봤듯, 지금 Attachment는 Struct이지만 String, URL도 Heap에 저장될 녀석들이다.
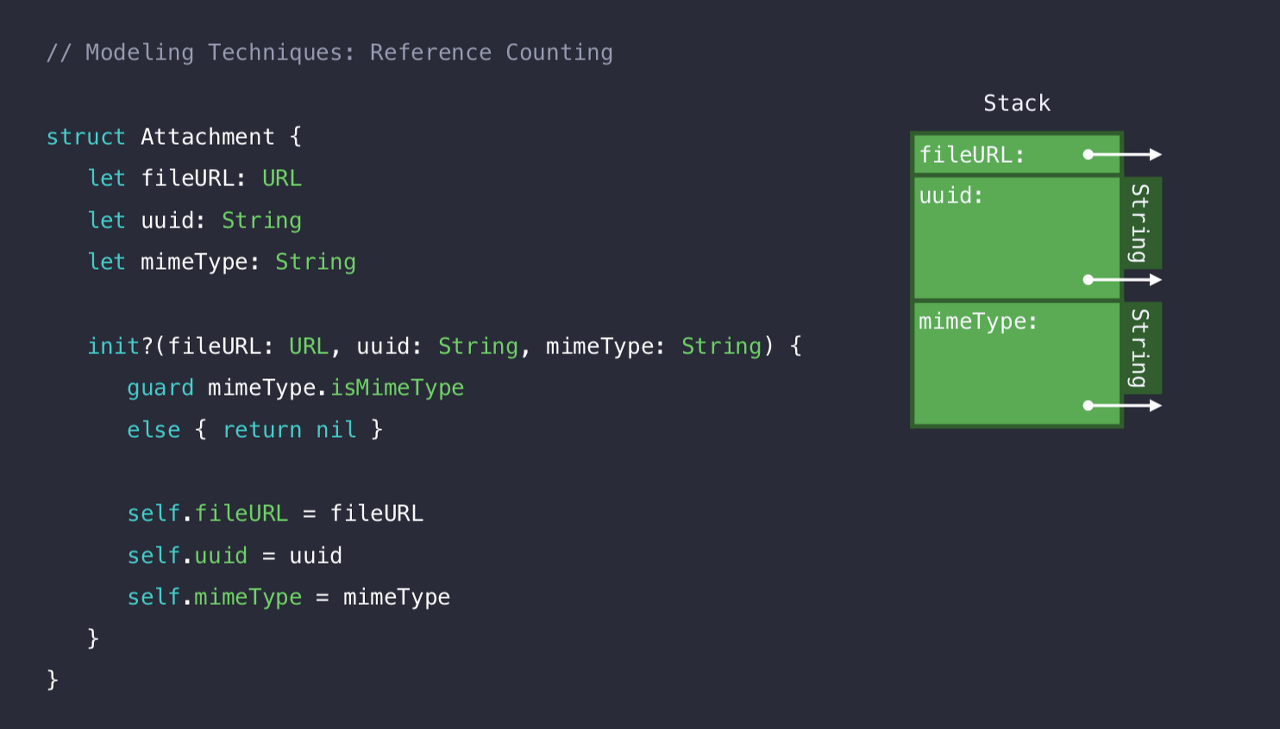
허어..아까 위에서 설명했듯 "둘 이상의 레퍼런스가 있는 경우, Class보다 레퍼런스 카운팅 오버헤드가 더 많이 유지된다" 라는 것을 그대로 실현하고 있다. (아이고 두야..)
이제 이걸 개선시켜보자.
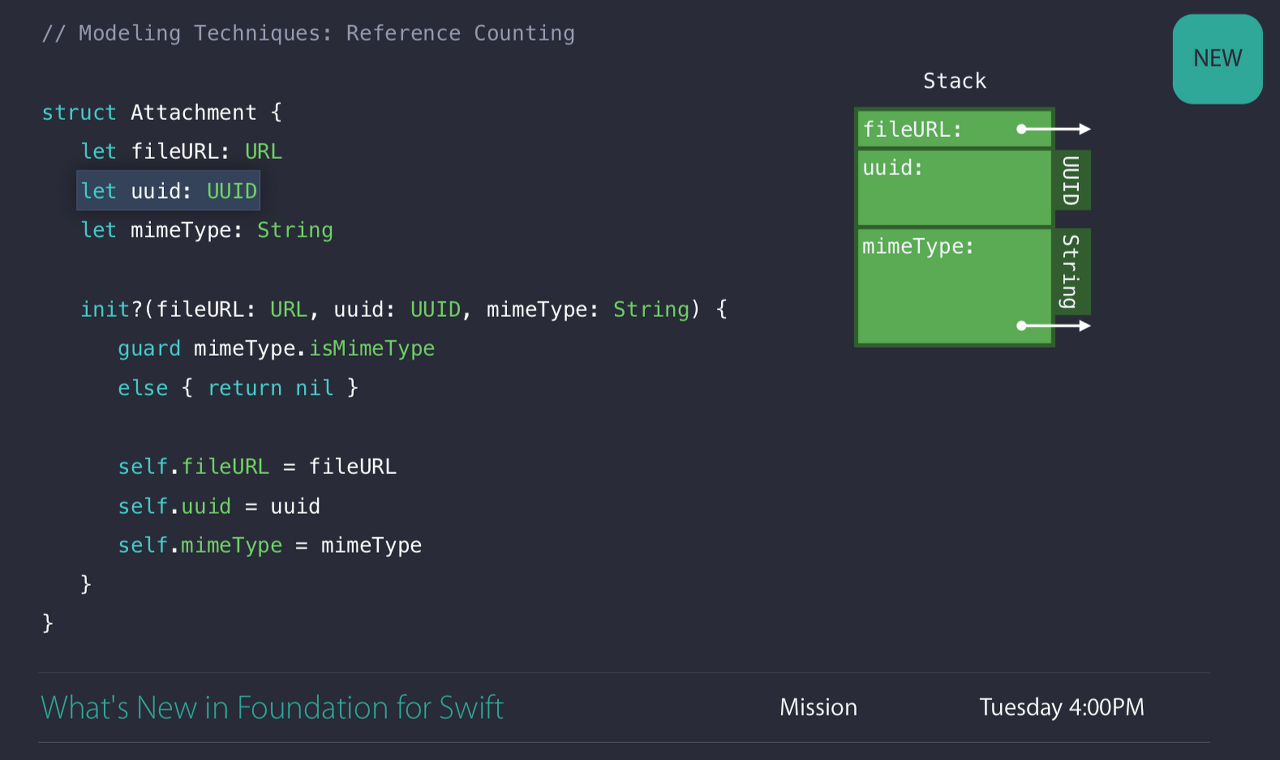
아까 Struct안에 uuid를 선언했었는데, UUID는 128비트 식별자를 Struct에 직접 저장하기 때문에 Heap에 할당할 필요가 없다.
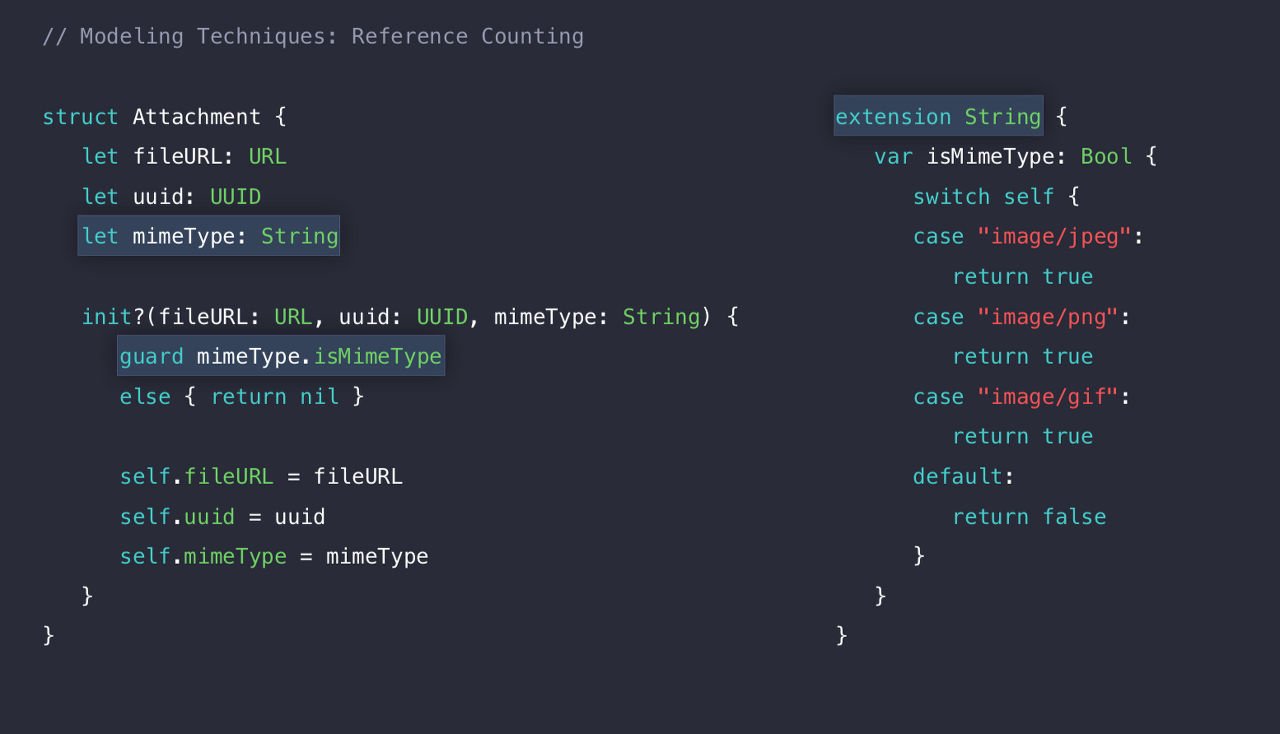
이제 mimeType을 보자.
아까 우리는 실패 가능한 이니셜라이저를 선언했다.
따라서 그 검사를 extension을 통해 검사하게끔 코딩 해준 것 같다.
이 코드를 조금 개선 해볼까?
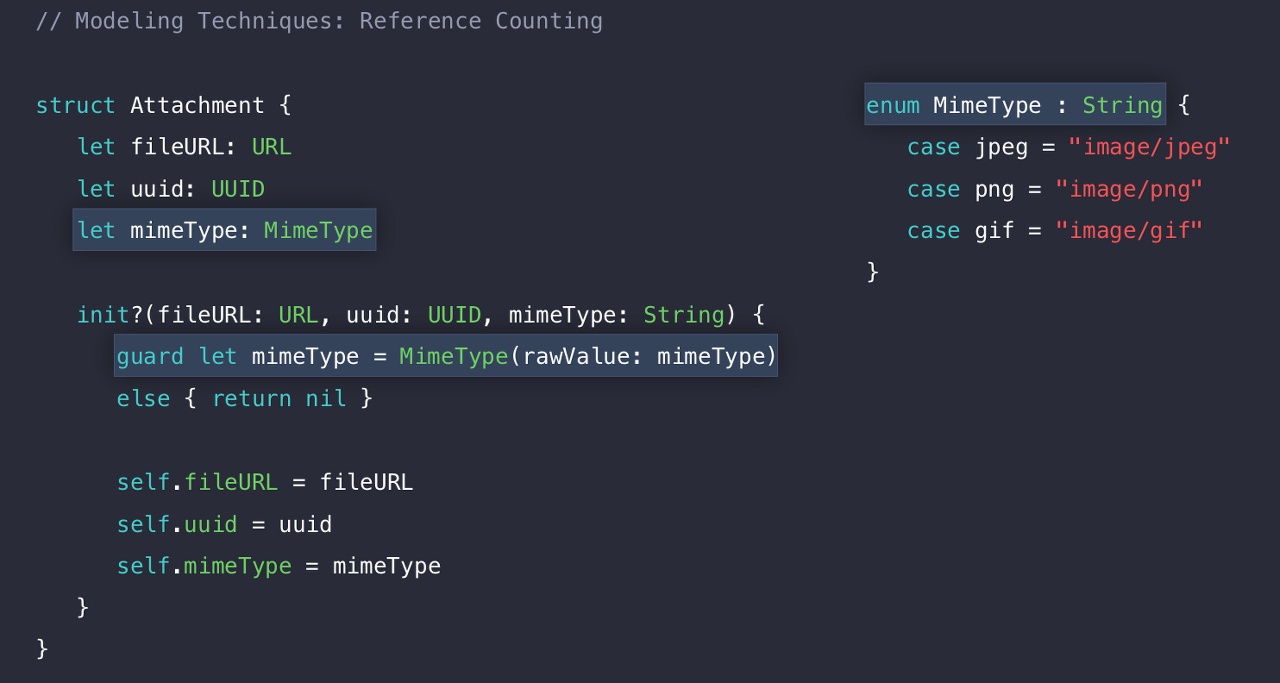
enum을 사용하여 개선하게 됐다.
enum은 값 타입이며 case들을 Heap에 저장하지 않는다. 또한 enum은 기본적으로 실패 가능한 이니셜라이저라 우리가 원하는 것을 enum을 구현할 수 있게 된다.
개선 정리
이렇게 되면 uuid와 mimeType이 원래 Heap 메모리 할당이 필요했지만, 둘 다 할필요가 없어지게 개선했다.
uuid는 String에서 UUID로, mimeType의 extension은 enum으로 교체하여 Heap메모리 할당 없이 구동되게 끔 변경했다.
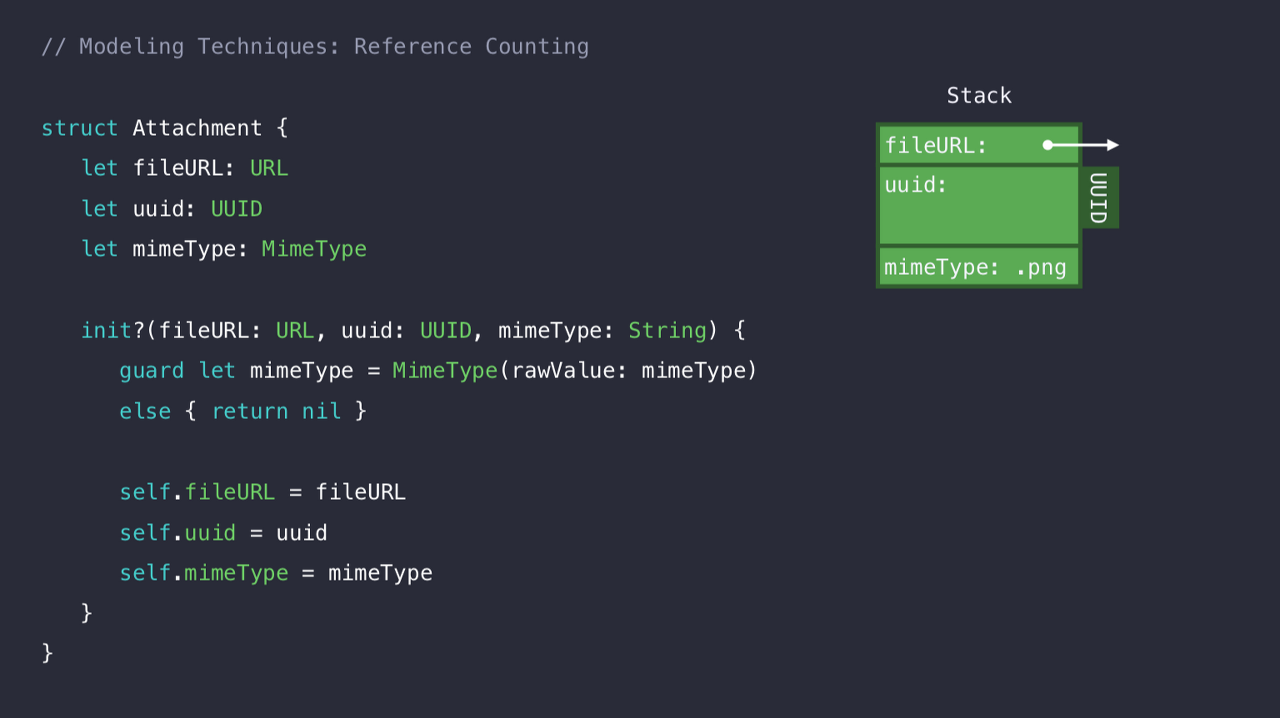
이제 fileURL 하나만 Heap 할당이 필요해졌다.
Method Dispatch
마지막 주제인 Method Dispatch로 넘어가보자.
런타임에 메서드를 호출하면, Swift는 정확한 구현을 실행해야 한다.
컴파일 타임에 어떤 구현을 실행하도록 결정할 수 있다면, 이를 static dispatch 라고 한다. 컴파일러가 실제로 어떤 구현이 실행될건지 알기 때문이다. 즉, inline과 같은 것을 포함하여 코드를 적극적으로 최적화 할 수 있게 된다.
반대로 dynamic dispatch는 컴파일러가 컴파일 타임에 어떤 구현을 실행할건지 결정할 수 없다. 런타임때만 실제로 구현된 곳으로 Jump 하게 된다.
따라서 dynamic disptach 의 비용은 static dispatch보다 훨씬 크다.

스레드 동기화 오버헤드나, 레퍼런스 카운팅 및 Heap 할당은 없었다고 해도, 이 dynamic dispatch는 컴파일러의 가시성(Visibility)을 차단하므로 최적화를 막게 된다.
예제 코드를 보자.
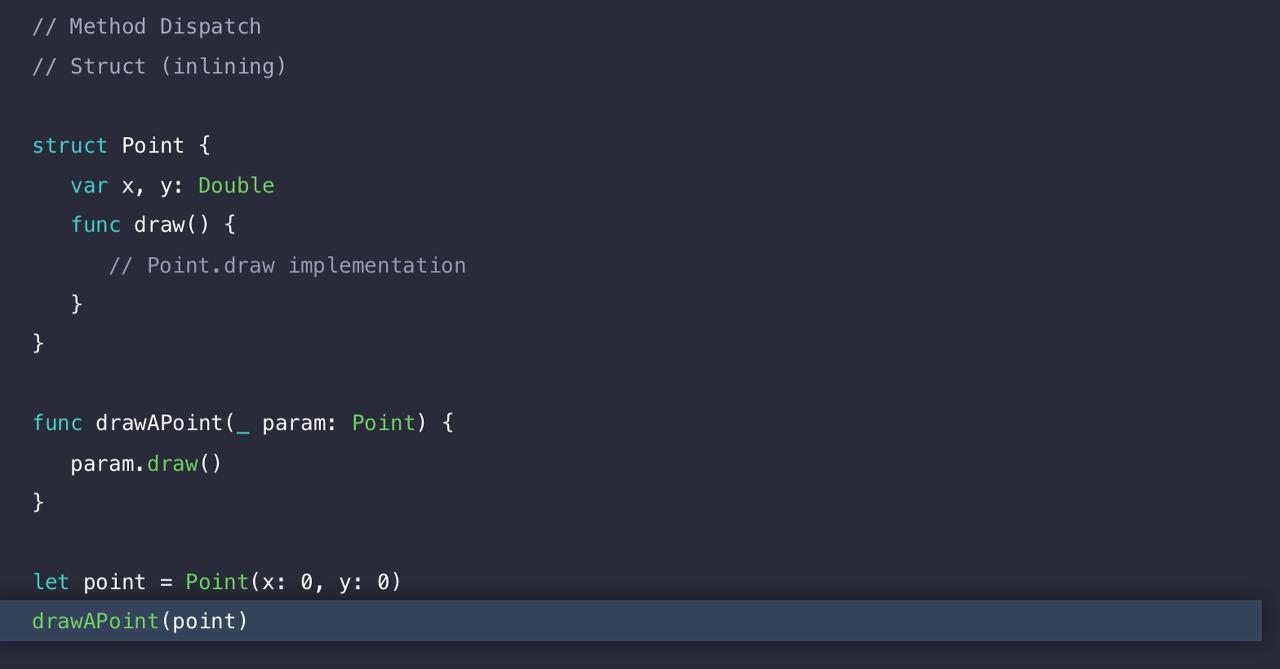
Point가 Struct로 구현되어 있다. 그리고 Point인스턴스를 만들고, drawAPoint 함수를 호출하고, 그 함수 안에서 Point Struct안에 구현되어 있는 draw()라는 메서드를 호출한다.
drawPoint와 draw 메서드 둘 다 static dispatch 되므로 최적화를 수행할 수 있게 된다. 이유는 컴파일러가 정확히 어떤 구현이 실행될 것인지를 정확하게 알고 있기 때문이다.
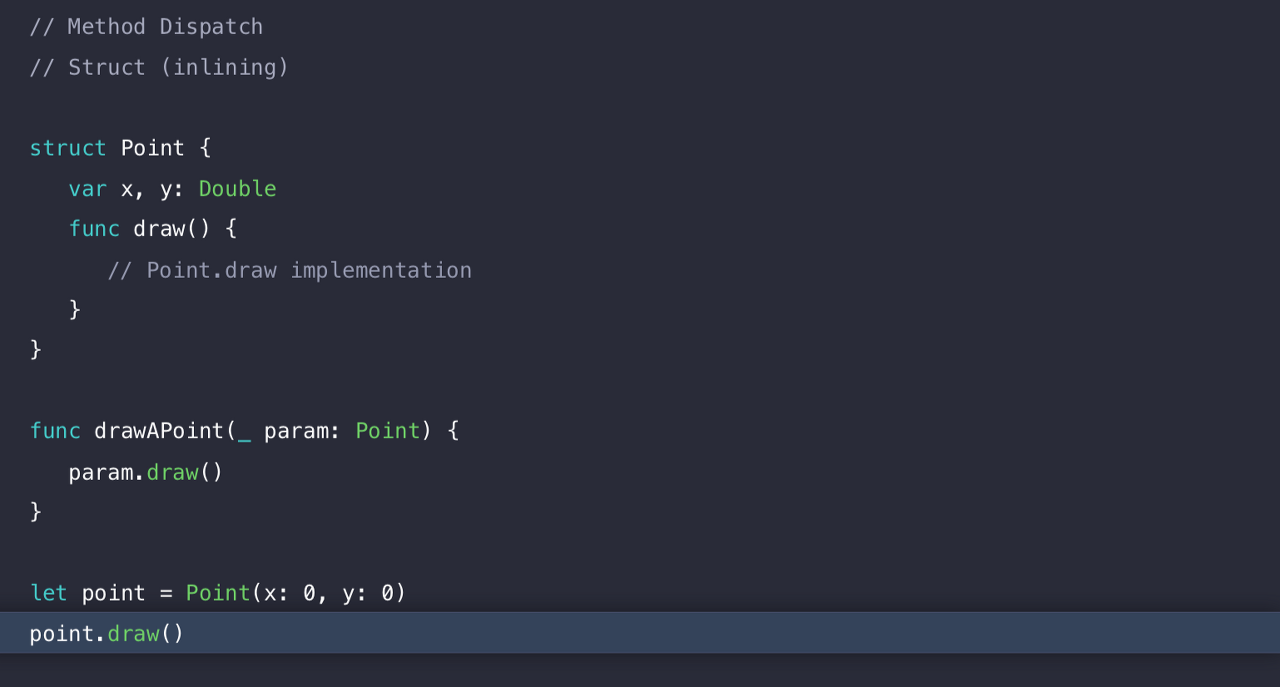
그래서 이렇게 drawAPoint호출을 draw로 대체할 수 있게 된다.
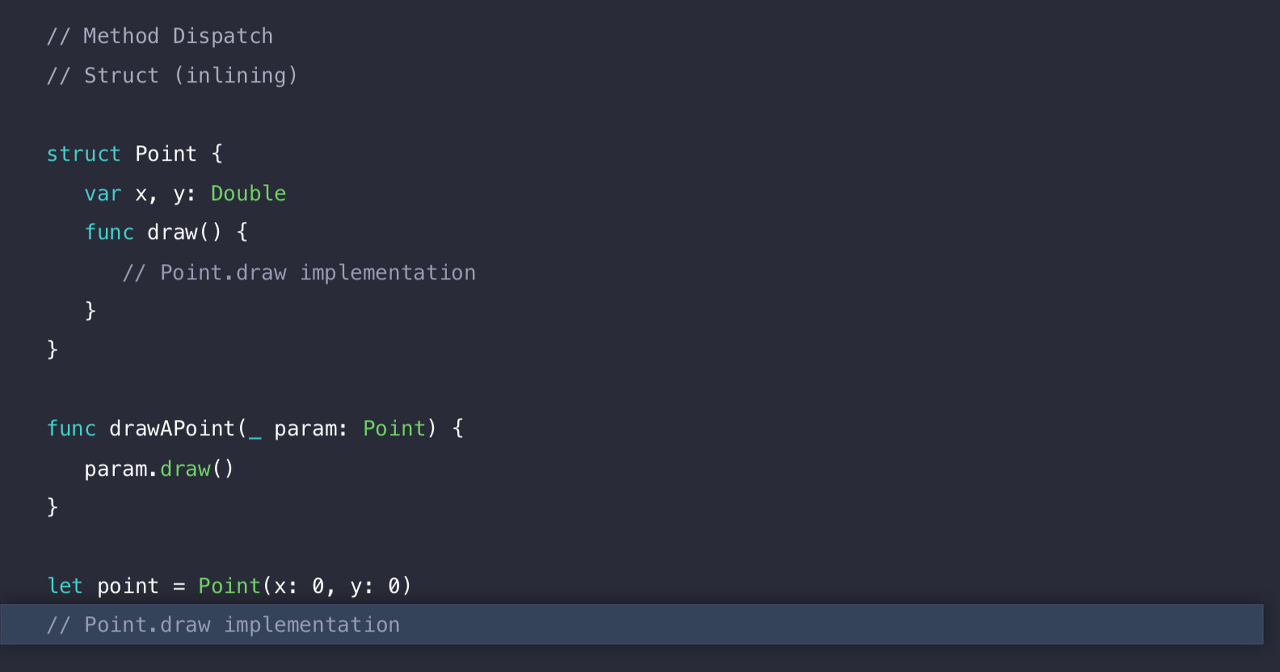
아얘 호출을 하지 않아도 draw() 의 구현을 바로 실행할 수도 있게 된다.
static dispatch가 dynamic dispatch 보다 빠른 이유는,
single dynamic disptach에 비해 single static dispatch와 비교해서 큰 차이는 없지만, static dispatch의 체인은 컴파일러가 전체 체인을 통해 가시성을 갖게 된다.
반면 dynamic disptach 체인은 매 단계마다 추론을 하지 않고 상위 레벨에서 차단된다. 컴파일러는 호출 스택 오버헤드가 없는 단일 구현처럼 static method dispatch를 축소할 수 있다.
그냥 위 그림을 얘기하는 것이다.
그럼 왜 dynamic dispatch를 사용하는 것일까?
그 이유 중 하나는 다형성과 같은 강력한 것들이 가능하다는 것이다.

Drawable 클래스를 만들고, Point와 Line이 Drawable 를 상속받도록 해줬다.

그리고 drawables 라는 배열을 만들었다. Drawable은 class이고, 배열 안에서는 이들의 대한 참조를 저장하기 때문에 모두 같은 크기일 것이다.

그리고 이것들은 실제로 Heap에 있는 것을 가리키고, Heap 에서는 위에서 말했다시피 refCount를 자체적으로 가지고 있을 것이다.

for 문을 돌면서 이 drawables 배열안의 인스턴스에 대해 draw()를 호출한다.
컴파일러가 여기서 정확히 어떤 구현을 실행해야 하는지, 즉 Line의 draw를 실행해야 하는지, Point의 draw를실행해야 하는지 이걸 컴파일러가 컴파일 타임에 어떤 구현이다라고 알수 없는 것을 직관적으로 이해할 수 있다.
그럼 컴파일러는 어떤 draw를 호출해야 하는지 어떻게 결정할까?
컴파일러는 그 class타입 정보에 대한 것을 정적 메모리에 저장하고, 실제로 draw를 호출할 때, 컴파일러가 실제로 생성하는 것은 타입 및 정적 메모리의 virtual method table이라고 하는 것을 조회한다. 그리고 실행하기 적합한 draw를 찾고 파라미터로 실제 인스턴스를 전달하게 된다.
결과적으로 우리는 class는 기본적으로 dynamic dispatch를 한다. 자체적으로 큰 차이를 만들진 않겠지만, 메서드 체인, 인라인과 같은 최적화를 막을 수 있다.
정리
하지만 모든 class가 dynamic dispatch를 사용할 필요는 없다. class를 서브클래싱하지 않으면 final로 명시하면 된다. 컴파일러는 이를 보고 static dispatch하게 될 것이다.
또한, 컴파일러가 앱에서 class를 서브클래싱 하지 않을 것이라는 것을 추론하고 입증할 수 있다면, 기회를 보고 dynamic dispatch를 대신하여 static dispatch를 하게 된다.
마무리
여러 기준에 따른 Swift의 성능을 알아보았는데, 정리 하자면


라고 한다.
우리가 오늘 알아야 할 것들은
우리가 코드를 작성할 때 마다
1. 이 인스턴스가 Stack/ Heap 중 어디에 해당할까?
2. 이 인스턴스를 전달할 때, 오버헤드를 포함하는 레퍼런스가 얼마나 많을까?
3. 이 인스턴스로 메서드를 호출하면 static/ dynamic dispatch 중 어떤걸 쓰게 될까?
우리가 dynamism을 필요하지 않는데도 비용을 지불하고 있다면, 우리의 성능은 나빠질 수 밖에 없는 것이다.
간단 요약
- Allocation (메모리 할당/해제) 관점에서 보면 딕셔너리 Key에 String을 사용하지 말고 Hashable을 통해 커스텀 객체를 만들자.
- Reference Counting (레퍼런스 카운팅) 관점에서 보면 구조체여도 레퍼런스 카운팅을 하는 경우도 있다. 이 경우에는 그냥 Class 에서 카운팅 하는 것 보다 오버헤드가 더 발생하게 되니, 예를 들어 uuid를 String에서 UUID로, extension을 enum으로 CallByValue 타입으로 개선해주는 것이 중요하다.
- Method Dispatch (메서드 디스패치) 관점에서 보면 Class에서는 컴파일 타임에 구현 목적이 보이는 static dispatch 말고 가시성이 없는 dynamic dispatch를 사용하게 된다. 그러나 굳이 사용하지 않아도 되는(서브클래싱을 하지 않는) class의 경우에 final을 사용하여 dispatch를 static dispatch로 구현되게끔 설정해주면 된다.
