코딩테스트
1.코딩테스트 시작하기 (Python)

졸업 이후 코딩과 거리두기를 한 나.그동안 새로운 일을 하기도 하고, 오랫동안 원하던 것을 해내기도 하면서 시간을 보냈다.졸업할 때까지만 해도 개발과 연구에 너무 지쳐서 한동안 멀리하고 싶었는데 다른 것들을 하고 나니까 새삼 다시 개발과 연구가 하고 싶어졌다.이들과 영
2.[백준] 10818 - 최소 최대
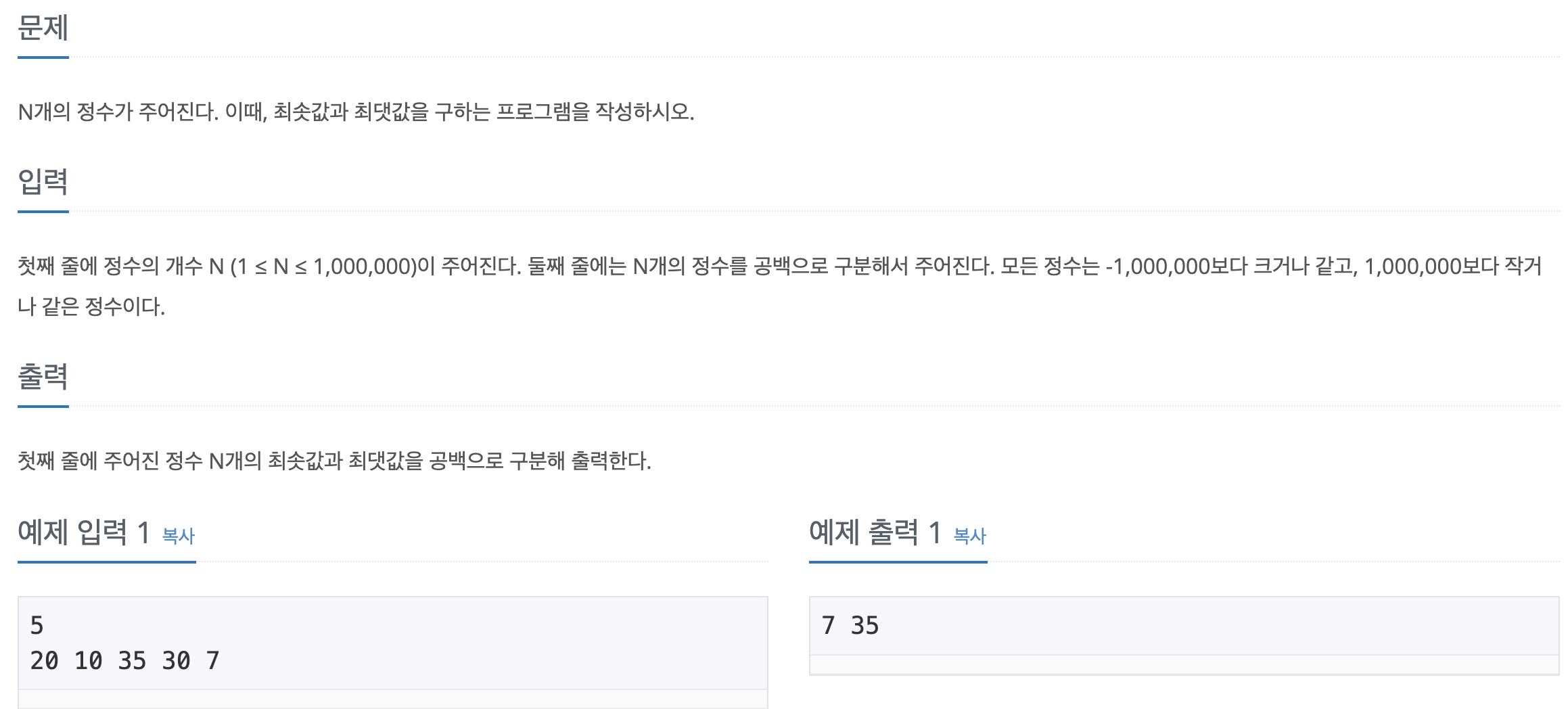
문제 바로 가기n개의 정수일 때 n을 입력받는다는 점에서 반복문으로 풀 수 있을 것 같은데,sorted를 사용하면 정수 개수 없이도 쉽게 풀 수 있다.sorted 함수는 아주 간단하게 다음과 같은 방식으로 사용하면 된다.입력을 llist로 받고 정렬 기준을 lambda
3.[백준] 2562-최댓값
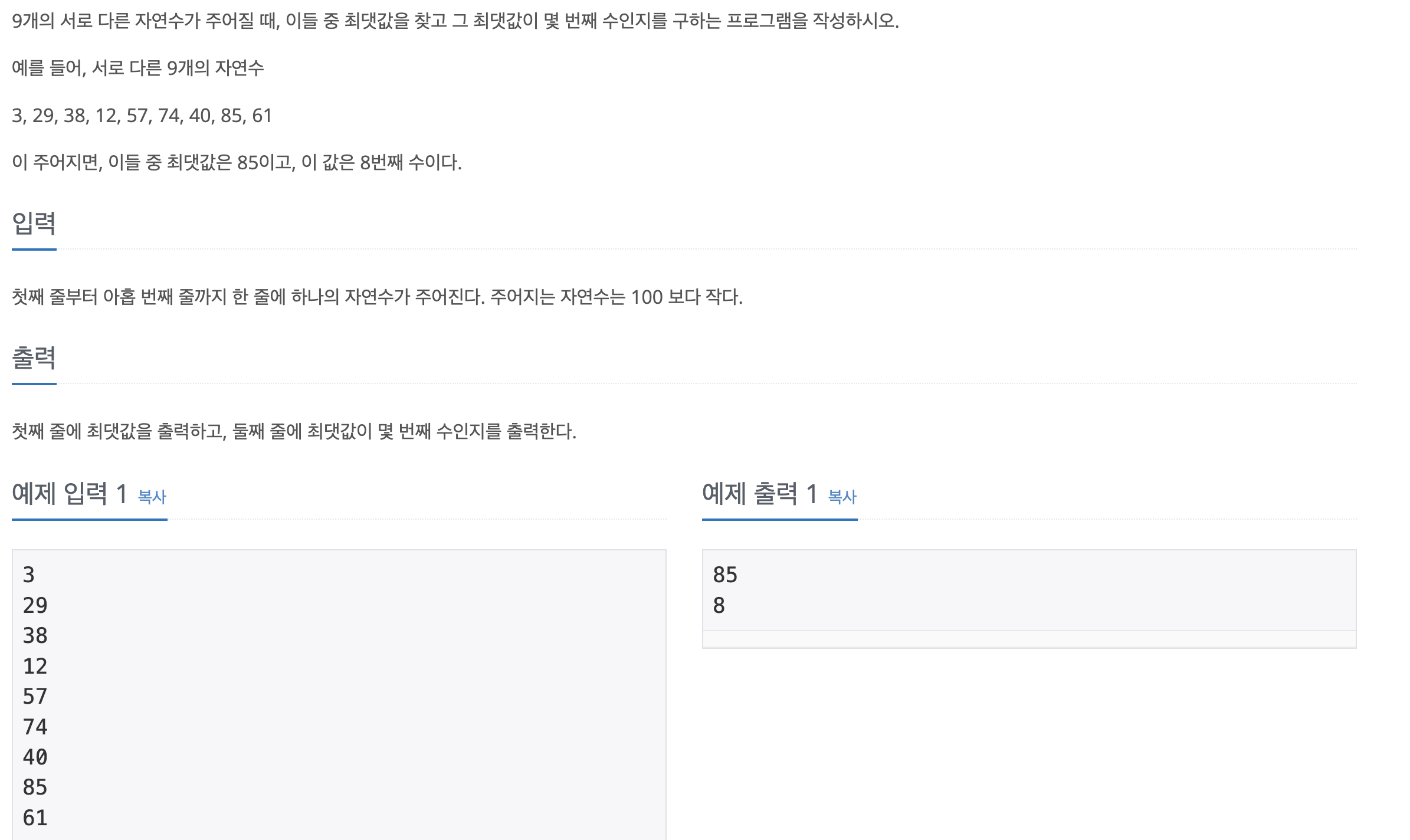
문제 바로 가기이번에는 간단하게 반복문으로 구현어이없는 것은 코드에서 제일 오래걸린 부분이 마지막 줄이란 것.. ^^ num_list.index를 num.index로 써놓고 뭐가 틀렸지? 했다.
4.[백준] 1152-단어의 개수

문제 바로가기아주 간단한 두 줄로 끝나버린 코드.처음에 split(' ')으로 했더니 틀렸다. 기본 기능을 이용하지 않으면 안되나보다.(split은 디폴트가 띄워쓰기) 그거 말곤 완전 똑같다.지피티가 추천해준대로 푸는데 너무 빨리 끝나서 다음 문제는 뛰어넘고 다음 단계
5.[백준] 9012-괄호
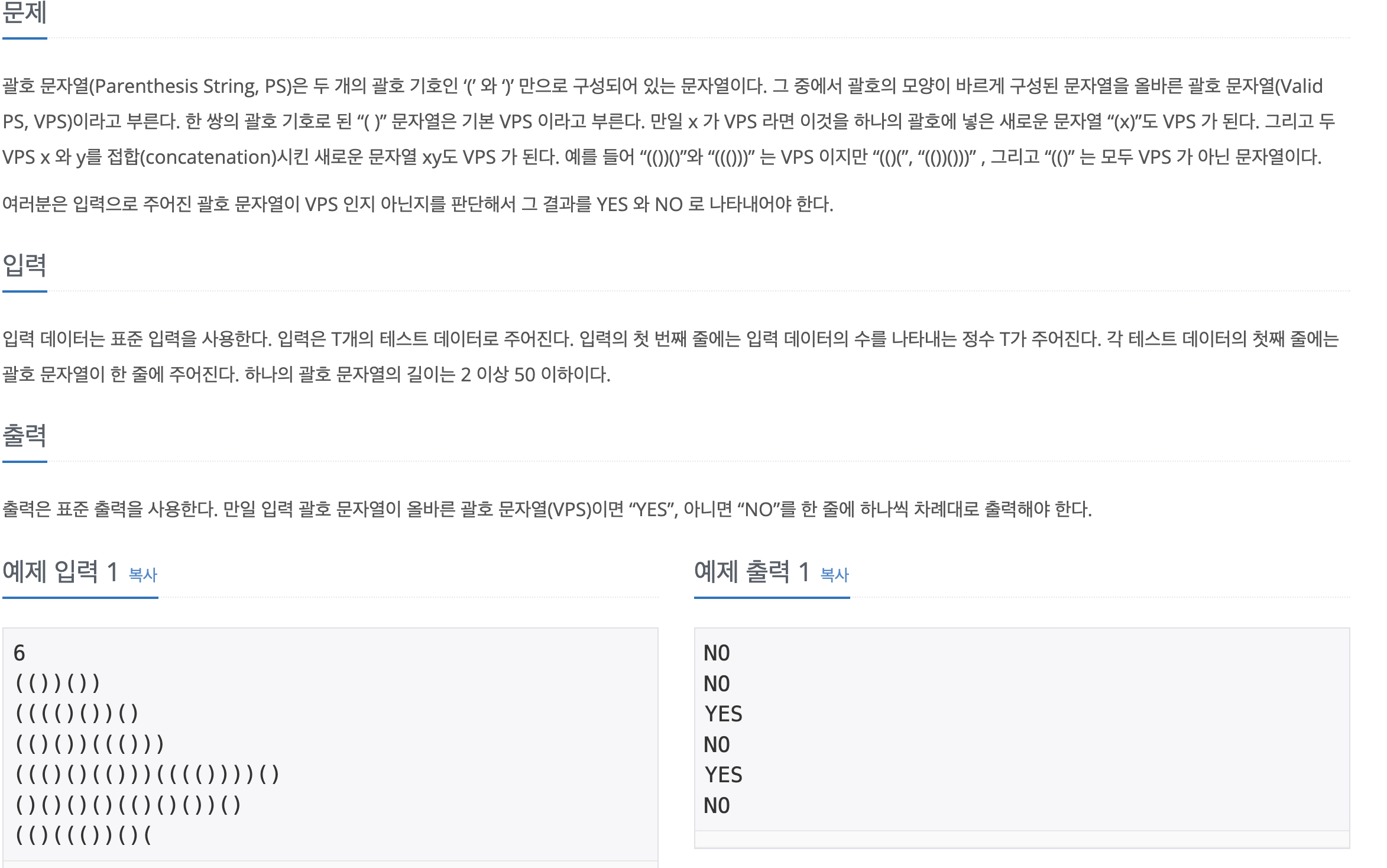
문제 바로가기처음에는 그냥 단순하게 '('의 개수랑 ')'만 맞으면 되는거 아냐?라는 생각으로 짰는데 당연히 안된다. 왜냐하면 이 경우는 )( 이런 순서의 예시를 잡을 수 없기 때문.결국 스택으로 해결했는데 마지막 else부분에서 시간이 제일 많이 걸렸다. 다른 언어에
6.[백준] 1773-폭죽

문제 바로가기문제를 읽어보면 그냥 배수 찾고 공배수 중복제거하면 끝나네~라고 생각할 수 있다. 나도 그랬음.그래서 바로 코드완료 했는데시간초과에 걸렸다. 이중포문도 충분히 자원을 많이 잡아먹는데 이건 뺄 수 없고.. 게시판에 같은 케이스가 있어서 읽어보니 not num
7.[백준] 1966-프린터큐

문제 바로가기케이스를 나눠서 분기대로 처리해주면 끝나지만 while 문장에서 반복조건을 c(숫자의 개수)만큼만 반복하라고 한 실수가 있어 시간을 잡았다.생각을 조금만 해보면.. c보다 숫자는 더 움직이는데 말이지.여러 값을 입력받을 때 map구문이 여기저기 잘 쓰이는
8.[백준] 1406-에디터

문제바로가기각 버튼에 따른 분기로 코드를 작성해주면 된다.근데 위에 코드처럼 하면 시간초과(무조건)가 뜬다.왜냐면 파이썬은 immutable한 언어여서 슬라이싱한다고 잘린 부분이 사라지는 것이 아니기 때문.게시판에서 나랑 같은 방식으로 짠 분이 질문을 올렸는데 댓글에
9.[백준] 11047-동전0

문제 바로 가기문제를 읽어보면 완전 그리디 알고리즘이다.제일 큰 수부터 반대로 몫과 나머지를 가지고 연산하면 끝.
10.[프로그래머스] 모의고사
완전탐색 문제는 그냥 냅다 푸는게 답이란 생각으로 단순무식하게 풀었다. for문으로 코드를 깔끔하게 만들어야할까? 라는 생각을 잠깐 했지만, 3개밖에 되지 않으니까 굳이 싶어서 그냥 반복했다.최대값만 추출하면 정답이 하나만 나오기 때문에 제일 어려운게 마지막에 최대값이
11.[프로그래머스] H-index

쓰다보니까 변수가 지칭하는게 자꾸 헷갈려서 혼났다. 핵심은 리스트를 거꾸로 정렬할 것 .sort(reverse=True)
12.[백준]11279-최대힙
문제바로가기제목 그대로 최대힙을 구현하는 문제인데 대부분 라이브러리를 이용하지만 나의 목표는 알고리즘 실력향상이므로 없이 짜보았다.여기서 실수했는데 못찾은 부분이 몇가지 있다. 지피티한테 물어봤다.pop함수에서 return을 heap을 했던 것.heap.pop()을 하
13.[백준] 2156-포도주시식

문제바로가기다이나믹프로그래밍 문제를 풀 때는 딱 3가지만 생각한다.초기값규칙규칙예외이렇게 코드가 해피엔딩으로 제출 끝일 줄 알았는데 계속 90%대에서 런타임에러(인덱스 에러)가 남 ㅠㅠ.결국 data값을 입력받는 부분을 참고해서 바꿔줬더니 정답이다.아마 data의 크기
14.[백준] 2798-블랙잭

문제바로가기n개중에 3개를 뽑아서 더한 합이 m을 넘지 않으면 된다.라이브러리를 이용해 간단하게 조합을 구하고 확인하여 출력하자.
15.[백준] 11724-연결요소의 개수
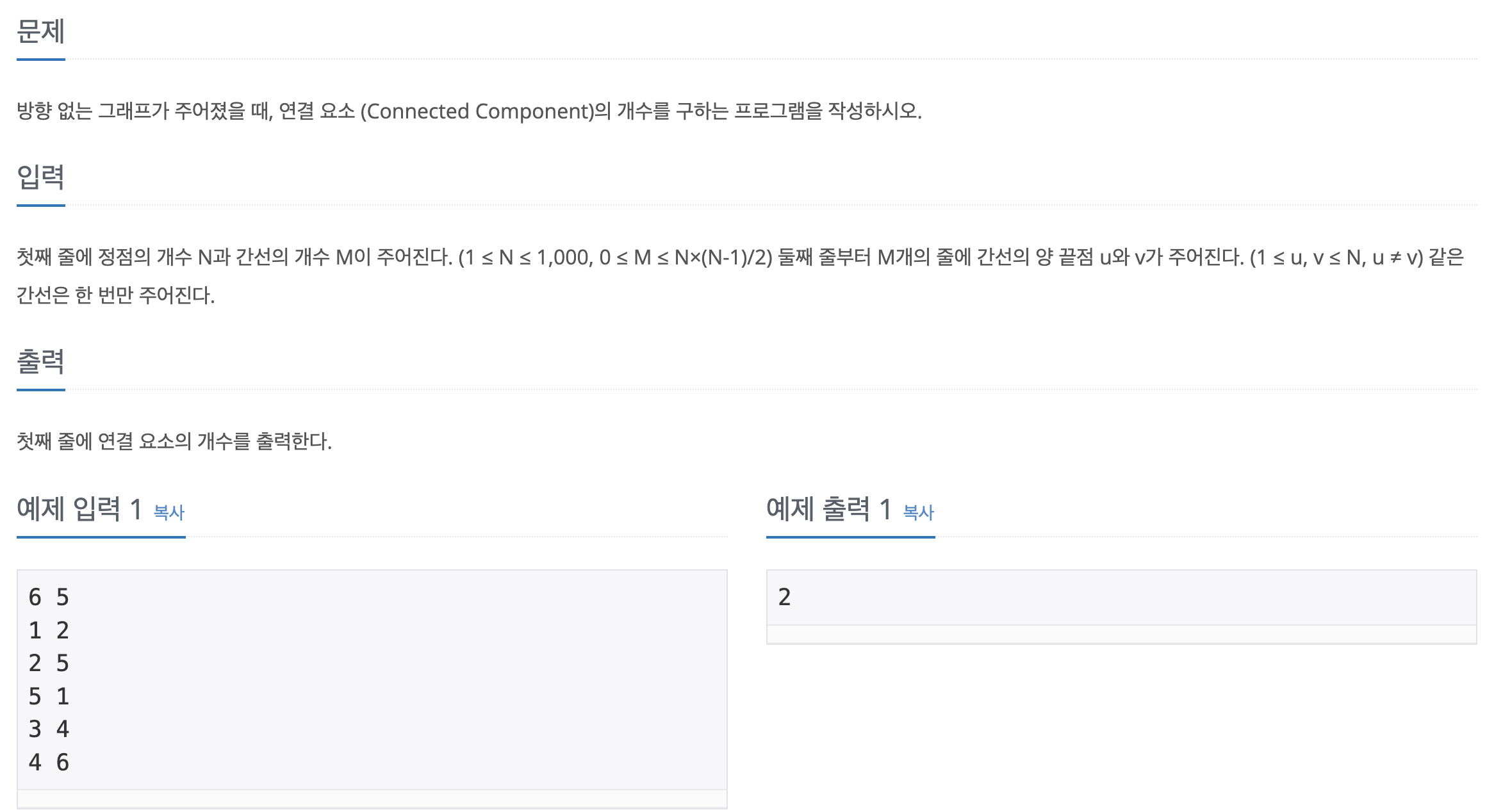
문제바로가기위 처럼 idx 기반으로 방문을 표시하는 방법도 정답이 나온다. 하지만 큰 리스트 및 filter 연산으로 메모리 초과 혹은 시간초과가 나온다. (각각 pypy3, python3으로 설정 시, 발생) 따라서 방문을 2차원 리스트의 인덱스를 일일이 검사하는 방
16.[백준] 7576-토마토

문제바로가기초기에 쓴 코드는 메모리 초과가 떴다. 원인은 크게 두 가지.첫 번째는 data를 리스트로 선언한 것이고,두 번째는 i, j 리스트를 while문이 돌 때마다 생성하는 것이다.최대한 라이브러리 안쓰고 직접 구현하고 싶어서 data를 일부러 deque를 사용하
17.[백준] 2178-미로탐색
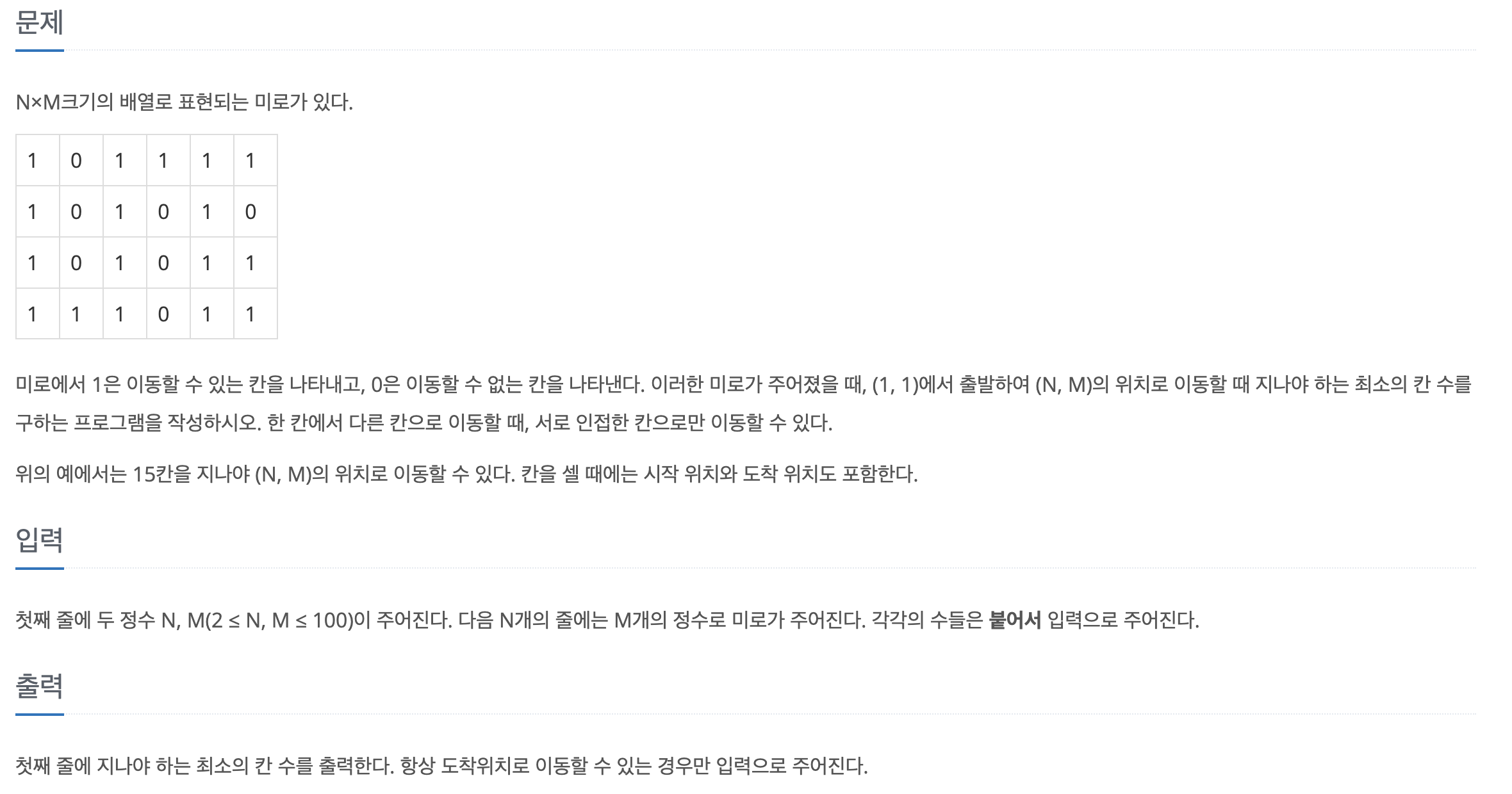
문제바로가기처음에 제대로 푼 것 같은데 왜 답이 안나오지?? 라는 생각으로 한참 헤맸는데 알고보니 시작점인 (0,0)만 넣어줘야되는데 (while문 안에 append가 되기 때문) dfs를 생각하고 무지성으로 1인 모든 값을 전부 넣어줘서 그랬다. 코딩이란.. 얼마나
18.[프로그래머스] 소수찾기

문제바로가기아주 기본적인 방식으로 문자열 -> 문자 -> 조합 -> 정수로 만들어서 정수가 소수인지 판단하는 방법으로 완성했는데 (가능한 수로 계속 나눠서 나눠지면 소수가 아님) 다른 사람들의 풀이를 보니 에라토스네스의 체 방법으로도 가능하다고 한다. 에라토스네스의 체
19.[백준] 15650-N과M(2)
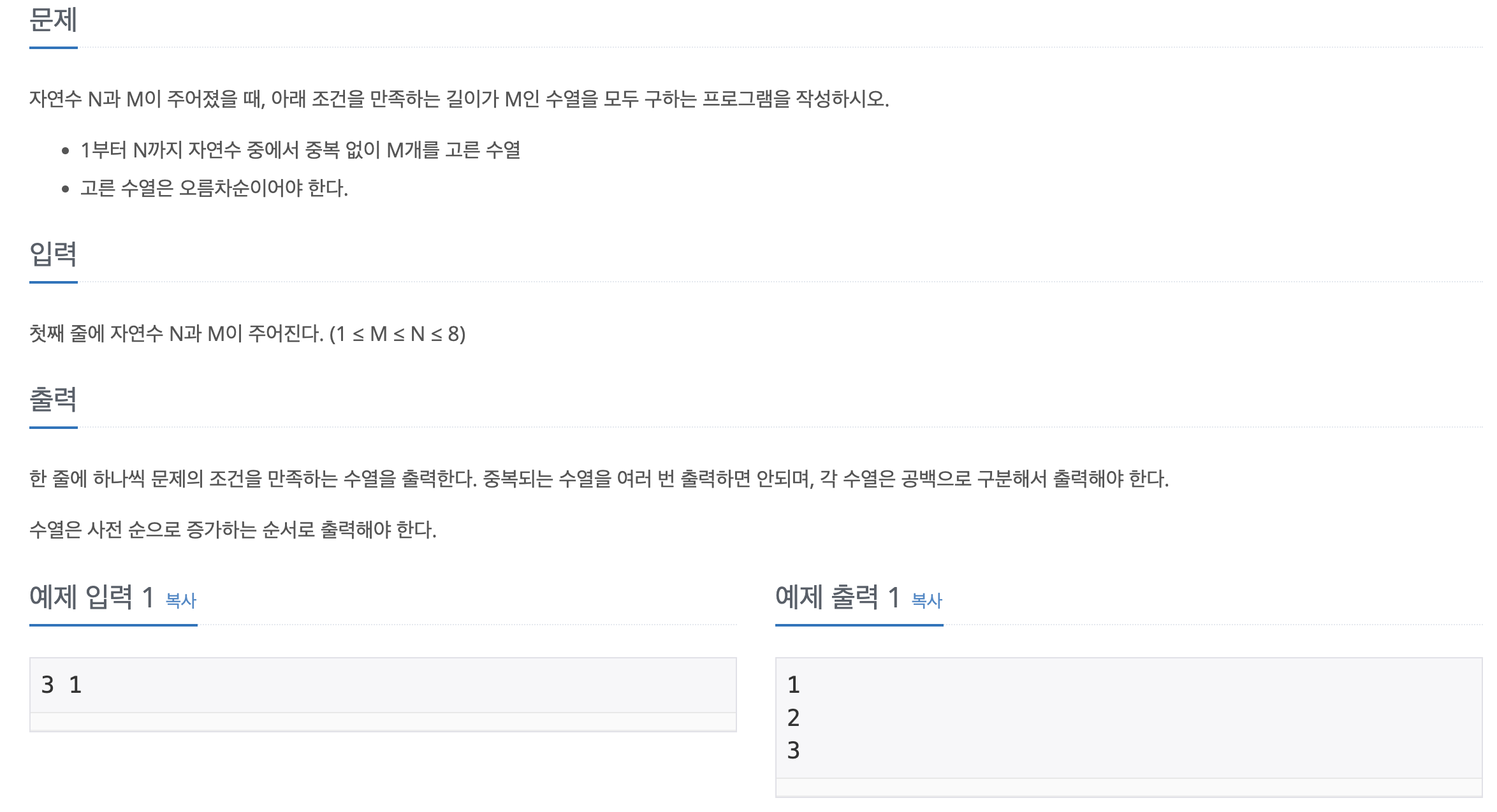
문제 바로가기일단 위 코드도 정답이다. 하지만 굉장히 비효율적인 방식으로 푼 코드이다. 기본 조합에서 중복을 제거하여 리스트에 저장하고 그 값을 오름차순으로 만들어 출력한다. 참고로 아래 코드보다 4배 더 걸린다. 당연히 메모리 초과에 걸리리라 예상했는데 맞았다고해서
20.[백준] 15651, 15652 - N과 M (3,4)
15651 문제 바로가기15652 문제 바로가기15651과 15652는 시작 값만 다르게 넣어서 해결할 수 있다.51은 순서가 상관 있고 52는 순서가 상관 없다.
21.[백준] 15654- N과 M(5)
문제바로가기앞선 문제들과 같지만 이번엔 연속된 수가 아닌 주어진 수로 조합을 해야한다. 결과를 오름차순으로 출력해야해서 입력받은 숫자들을 정렬시켜서 순서대로 진행했다.
22.[백준] 2579-계단오르기

문제바로가기계단의 합 최댓값 구하기 문제stairs 부분은 stairs = \[int(input()) for \_ in range(n)]으로 한 줄로 써도 됨! (파이써닉하게)
23.[프로그래머스] 등굣길
문제바로가기dp 문제이다.제일 오래걸린 것은 puddles = \[\[j, i] for i, j in puddles]이다. puddles가 n,m이 아니라 m,n 순서로 되어 있어서 위치를 바꿔줘야한다. 하필 테스트 케이스가 2,2라서 더 알아차리기 힘들었다. 결국
24.[백준, 프로그래머스] 1932, 정수삼각형
백준 문제바로가기프로그래머스 문제바로가기맨 처음엔 greedy하게 풀었는데 반례를 발견했다. 그래서 결국 dp연습겸 dp로 최종코드를 완성했다. 핵심은 아래서부터 더해서 올라올 것. 계속 위에서부터 더하는 코드를 짰는데 무조건 반례가 생긴다.프로그래머스는 다른 풀이도
25.[백준] 1010-다리놓기

문제바로가기결국 문제에서 요구하는 것은 mCn의 값이다. (조합구하기)원래는 백트레킹 연습하던 게 생각나서 그걸로 코드를 완성했는데 당연하게도 메모리 초과가 났다. 백트레킹은 딱봐도 O(n^2)임. 뿐만아니라 리스트도 계속 생성/호출하고 메모리 초과가 날 것 같았다.
26.[백준] 9465-스티커
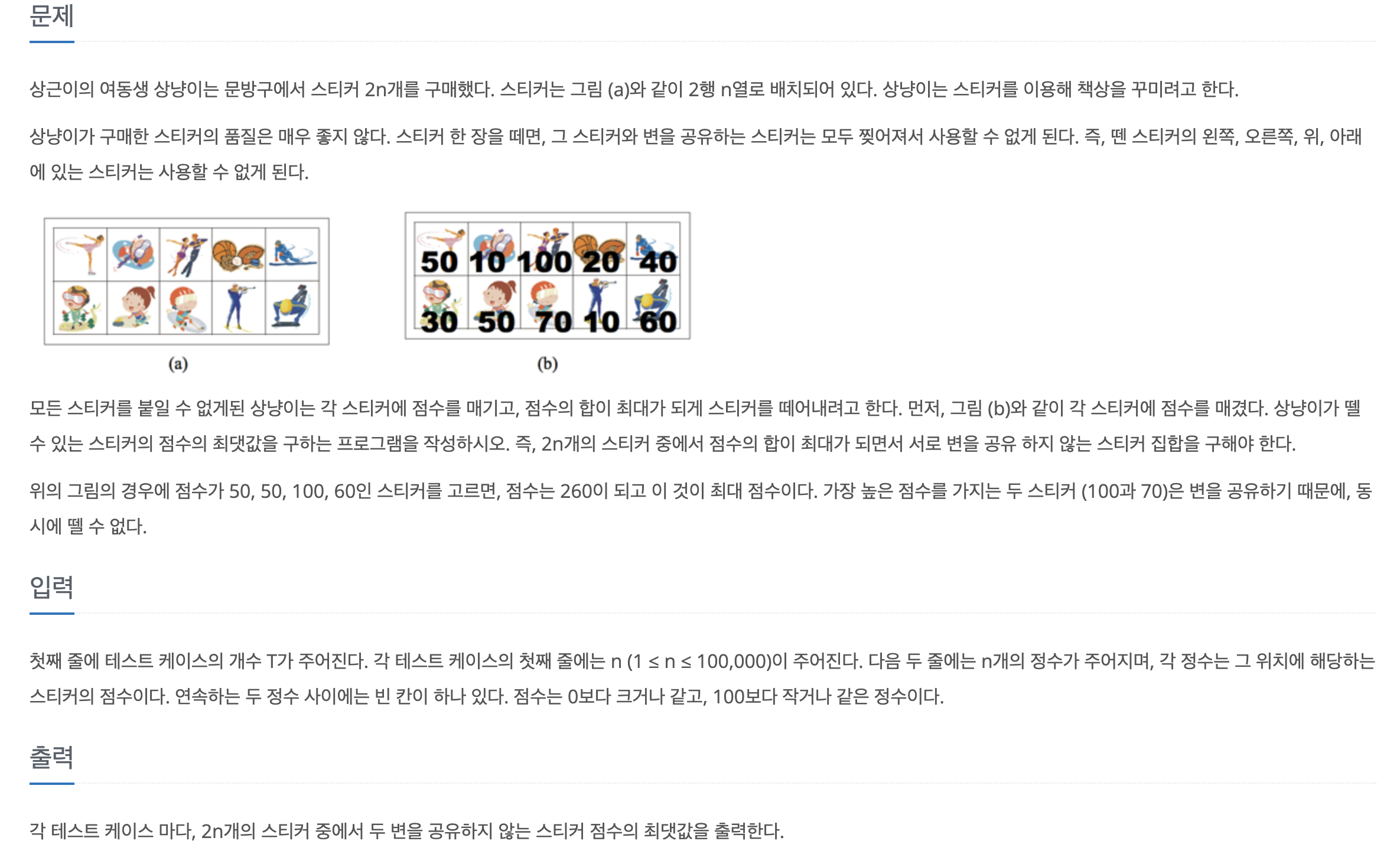
문제바로가기 처음에는 matrix는 2행으로 했는데 dp를 1행으로 해서 반례가 계속 생겼다. 지피티한테 물어서 dp 1행으로는 완벽히 문제를 커버할 수 없단 걸 알게되고 결국 수정했다.
27.[백준] 9461-파도반수열

문제바로가기그림으로 보니까 규칙을 못찾았는데 일렬로 수를 나열해보니까 규칙이 찾아졌다.1 1 1 2 2 3 4 5 7 9 12 ... 맨 앞의 111을 제외하고서 모두 2개앞의 값 + 3개 앞의 값을 더한 값이 현재의 값이 된다.간단하게 통과했는데뭔가 파이서닉하게 작성
28.[백준] 2193-이친수
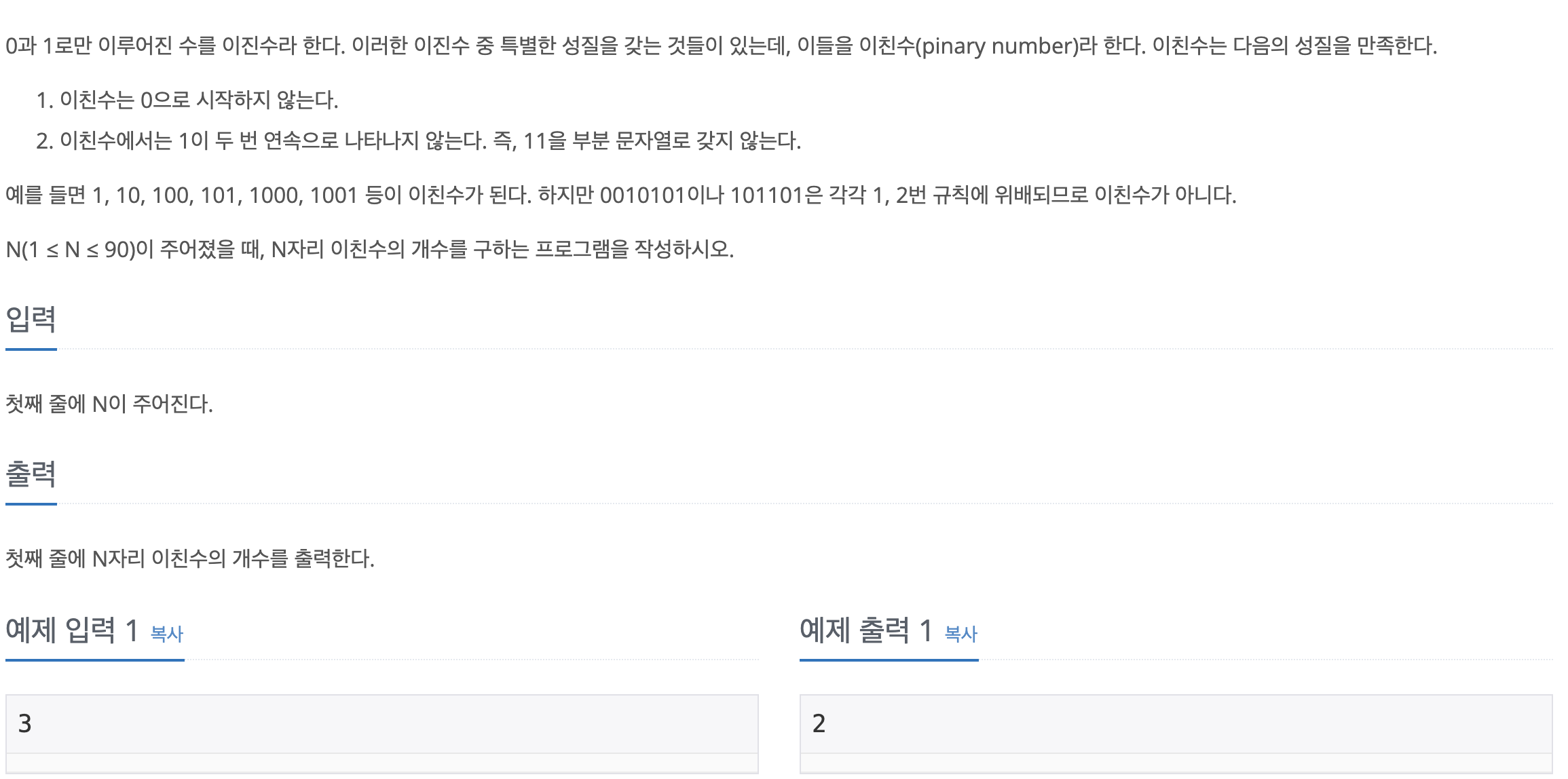
문제바로가기N까지 숫자가 증가할 때 경우의 수를 따져보자다음과 같은 규칙을 찾을 수 있다.
29.[백준]13699-점화식
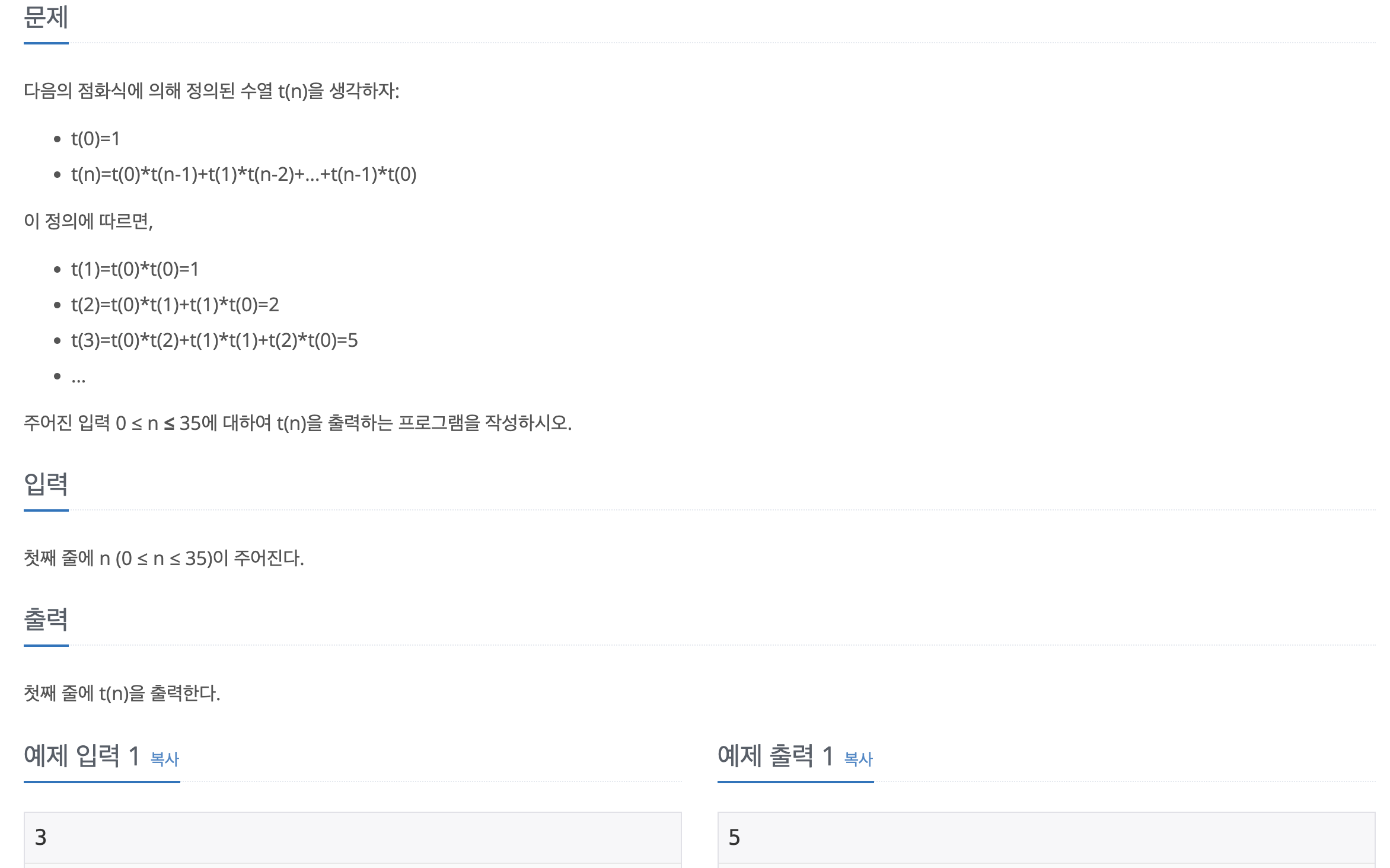
문제바로가기처음에 99%에서 런타임에러(indexerror)가 났는데 그 이유가 n이 2 이하인 경우 예외처리를 해주지 않았기 때문이다. 조금만 생각해보면 t가 n+1개인데.. 어떻게 그냥 t\[2] 라고 쓸 생각을 했지? 코딩은 역시 디테일이다.
30.[백준] 1351-무한수열
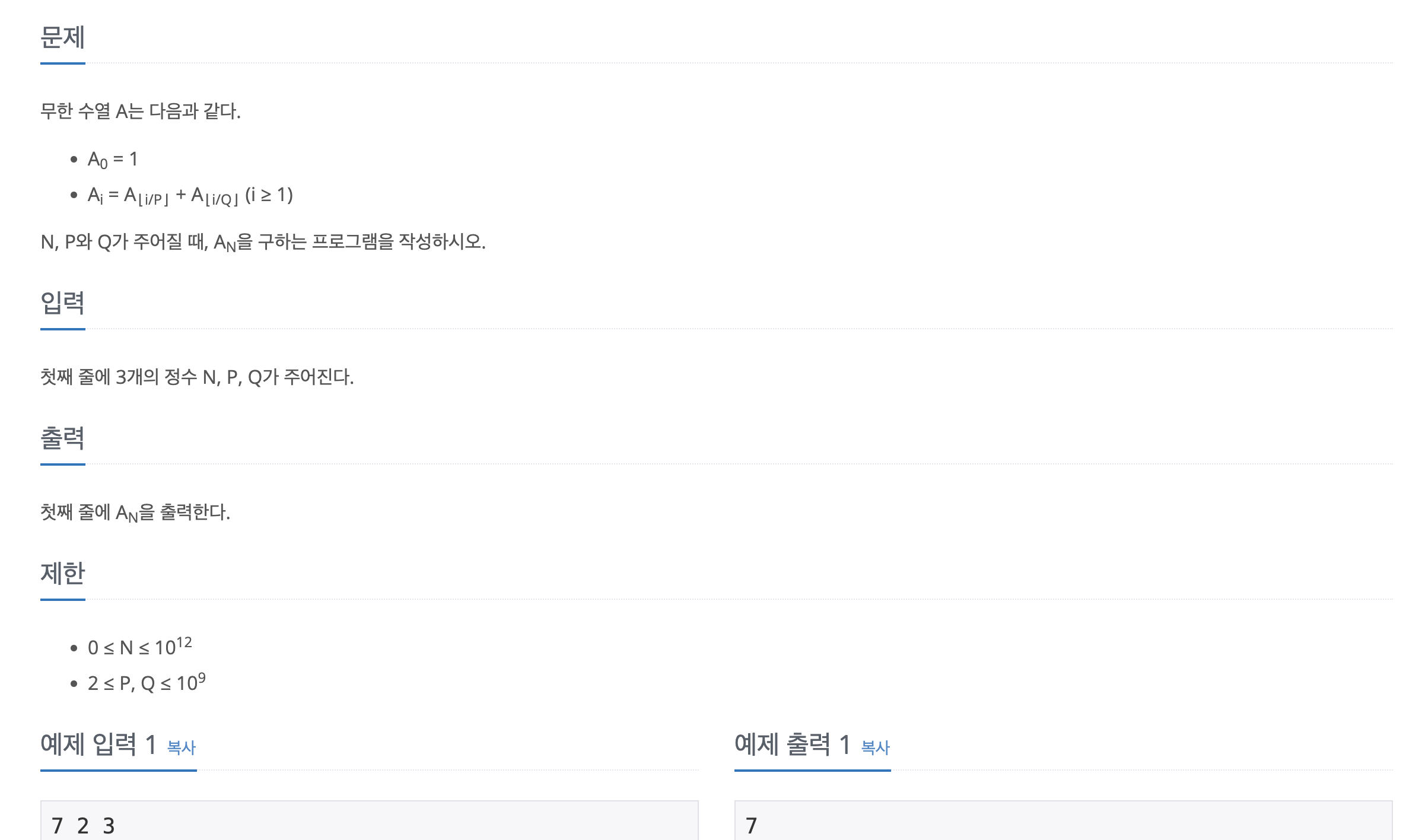
문제바로가기최종 코드를 보여주기 전에 이렇게하면 메모리초과나 시간초과남 코드를 선보이겠다.먼저 위 코드는 간단하지만 numbers를 중복해서 호출한다. N이 10^12이기 때문에 얼마나 많이 호출될지 안봐도 비디오.다음으로 위 코드는 중복호출을 막기 위해 배열에 값을
31.[백준] 27210-신을 모시는 사당

문제바로가기맨 처음에 .count연산으로 풀었다가 당연하게도 시간 초과가 났다.이런 식으로 이중 포문으로 검사했다가 O(n^3) (생각해보면 당연함.)이 나오는 엄청난 결과를 얻었는데 아무리 생각해도 1의 개수랑 2의 개수 차이를 표현할 아이디어가 없어서 검색을 해봤다
32.[백준] 2167-2차원 배열의 합
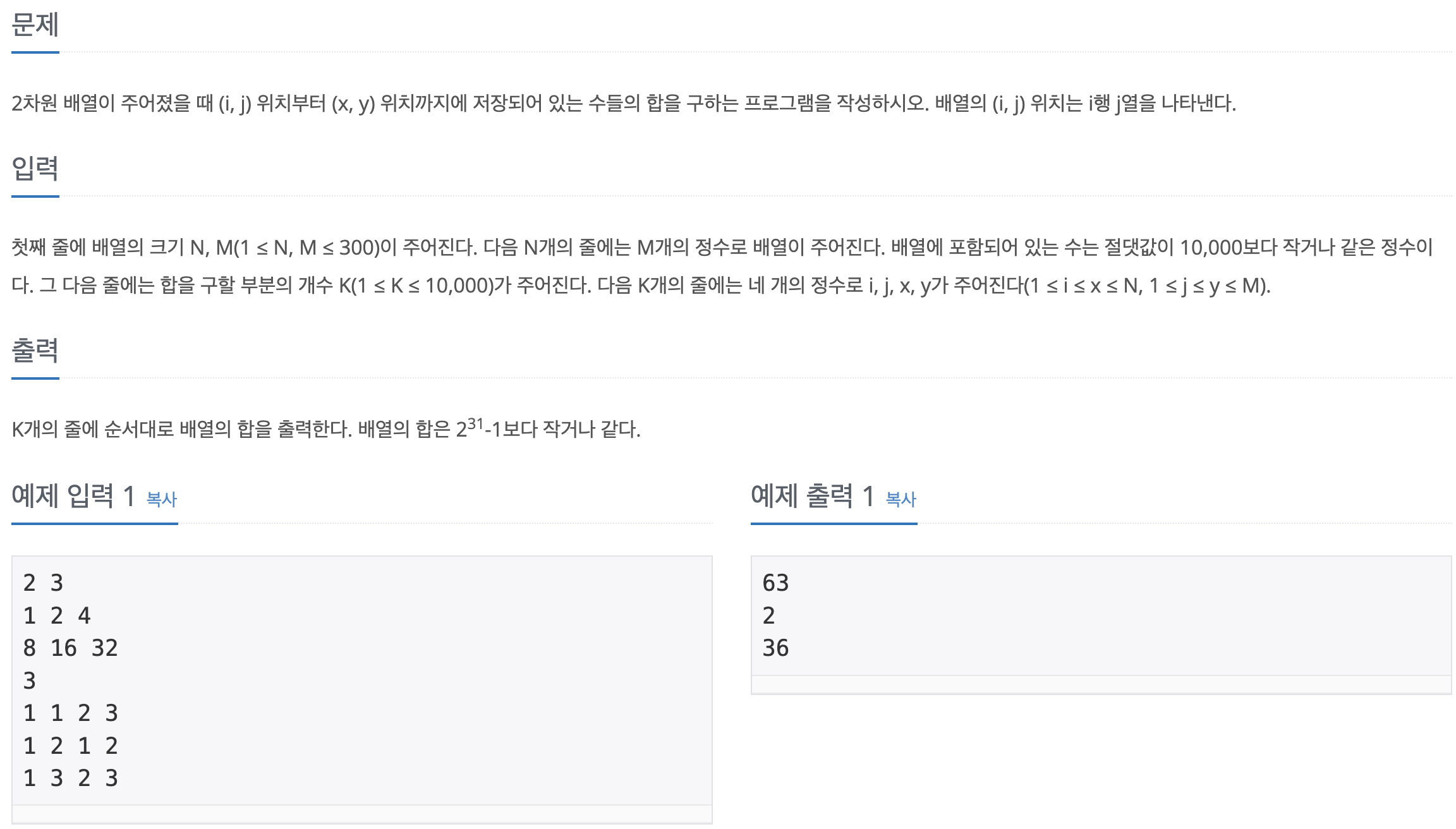
문제바로가기생각보다 문제 푸는데 오래 걸렸는데 그 이유는 문제를 잘못이해했기 때문이다. 그냥 i~x, j~y까지를 계산하면 되는데 나는 더 꼬아서 연속된 값을 찾는다고 생각했다. 예를 들어 i가 1이고 x가 3이면 2행은 전부 포함되는 것이다. 당연하게도.. 아니다!제
33.[백준] 10800-컬러볼
위 코드는 오답이다. 그럼 왜 포스팅하느냐? 결과는 정답 + 파이서닉함이라서다. 이 코드가 오답인 이유는 시간과 메모리를 고려하지 않았기 때문이다. 먼저 nums\[:i]+nums\[i+1:]에서 O(N^2)번 값의 복사가 일어나기 때문에 비효율적이다.다음으로 resu
34.[백준] 28108-시간이겹칠까?

문제바로가기처음에는 그냥 시작부터 끝까지의 수를 순회해서 값을 저장해둔다음 그 값을 출력하면 끝나는 문제라고 생각했다.하지만 해당 방식의 위 코드는 시간초과가 난다. range(i\[0], i\[1]+1)부분이 i가 클수록 (예를들어 1과 1000000이면) 부담되기
35.[백준] 15787-기차가 어둠을 헤치고

문제바로가기
36.[백준] 17497-계산기

문제바로가기0부터 N을 만드는 게 아니고N에서 0을 만드는 방식을 반대로 생각하면서 온다.마지막에 명령어 개수 출력 이후에 명령어를 출력했어야 했는데 그걸 안해서 계속 틀리고 왜 틀리지?라고 생각했었다 ㅠㅠ 아무튼 간단하게 완료
37.[백준-파이썬] 11399-ATM

문제바로가기누적합이 적으려면 앞사람의 처리시간이 적어야 한다. (그래야 뒷사람이 오래 안기다리기 때문.) 그래서 작은 순으로 정렬하고 모든 값을 합해주면 끝. 간단하게 완료.
38.[백준-파이썬] 13305-주유소

문제바로가기업로드중..위 코드는 41점짜리다. 서브테스크 문제라서 n의 크기에 제약이 있으면 점수를 절반만 준다. 위 코드가 시간 복잡도가 큰 이유는 min연산이다. min만보더라도 $O(n)$인데 이걸 for문만큼 반복하기 때문에 총 $$O(n^2)$$만큼의 복잡도를
39.[백준-파이썬] 1715-카드정렬하기

문제바로가기최종합이 적어지려면 작은수 두개씩을 묶어 더해나가면 된다. 이런 생각으로 처음에는 간단하게 배열을 정렬하고 작은수를 pop하면 두개를 더한 값이 다른 수보다 클테니까 이걸 push해서 반복해나가면 되겠다는 아주 단순한 생각이었는데 항상 두 수를 더한 값이 큰
40.[백준-파이썬] 2457-공주님의 정원
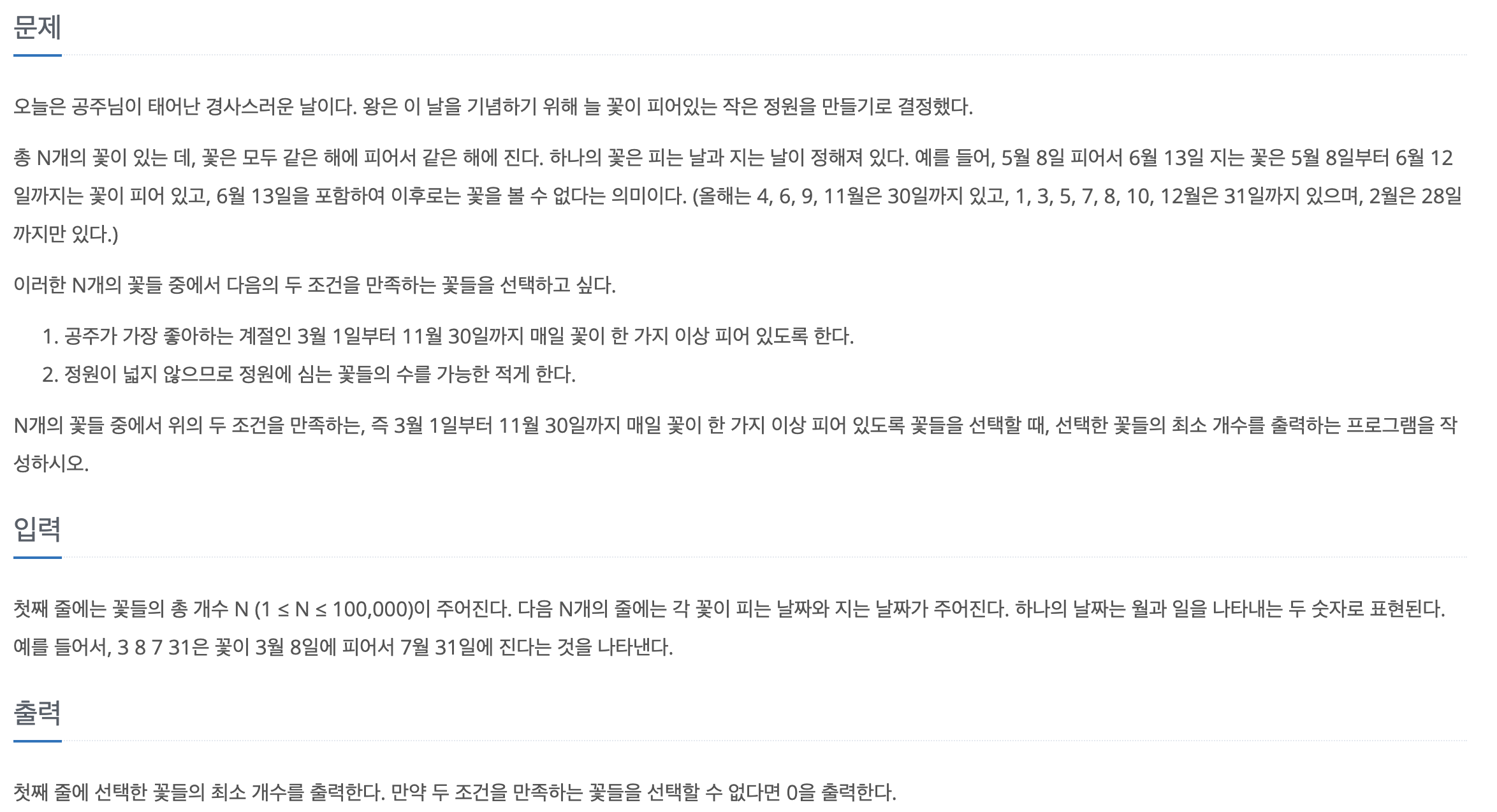
문제바로가기업로드중..이 문제의 핵심은 기준 날짜보다(초기값 3월1일) 앞서서 피는 꽃을 찾아야 하고, 그 꽃들 중에서 가장 오래 피어있는 꽃을 선택해야한다. 그리고 선택된 꽃이 지는 날이 다시 기준 날짜가 된다는 것이다. 이 아이디어만 생각하면 구현은 금방한다.마지막
41.[백준-파이썬] 1882-부분수열의 합
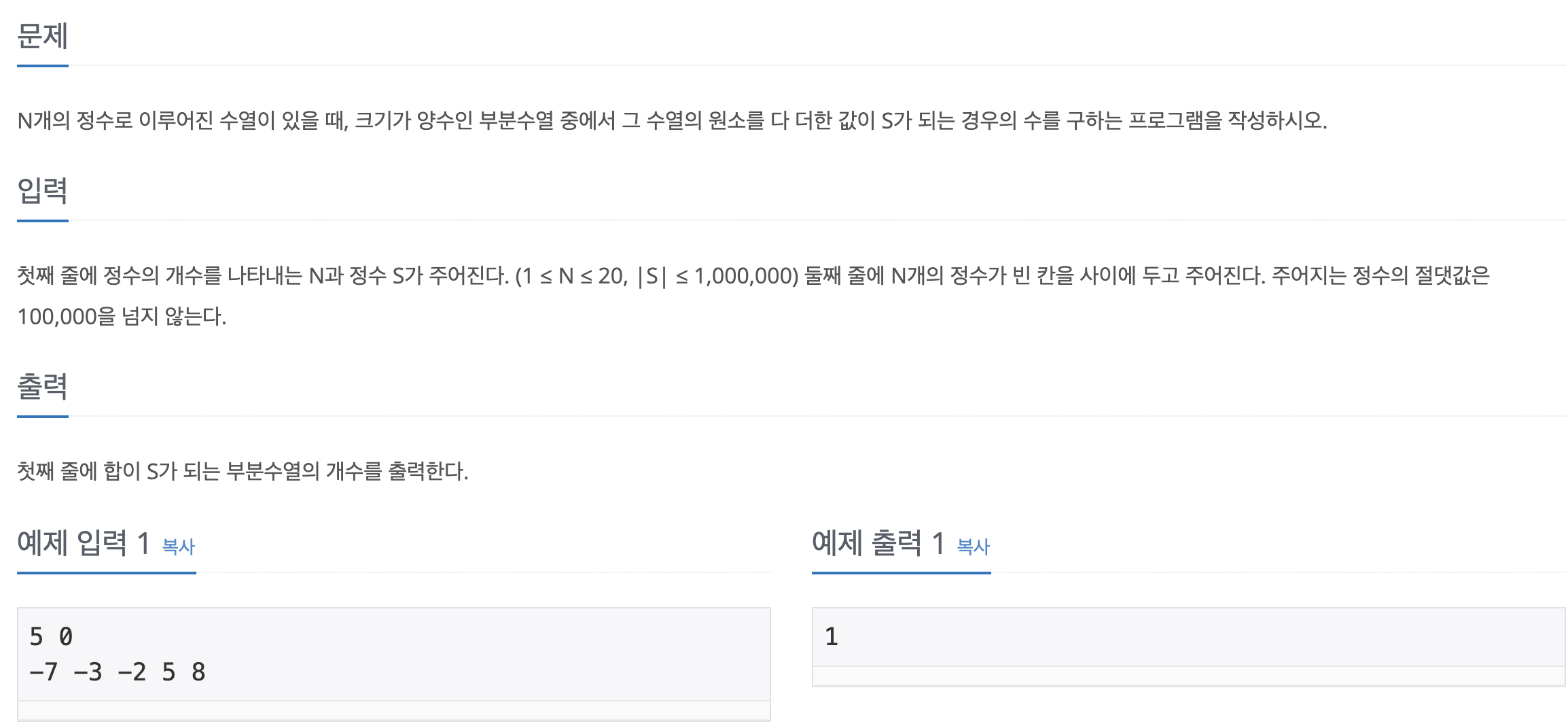
문제바로가기N과 M 문제 시리즈의 변형 같은 문제.단지 멈추는 조건이 조합의 합이 S가 될 때로 바뀐 것 뿐이다. 한가지 간과한 것은 s가 0일 때 combi가 \[]인 경우도 포함되어서 count가 올라갔었다. 그래서 추가로 combi에 무조건 값이 있어야 한다는 조
42.[백준-파이썬] 15655-N과 M(6)
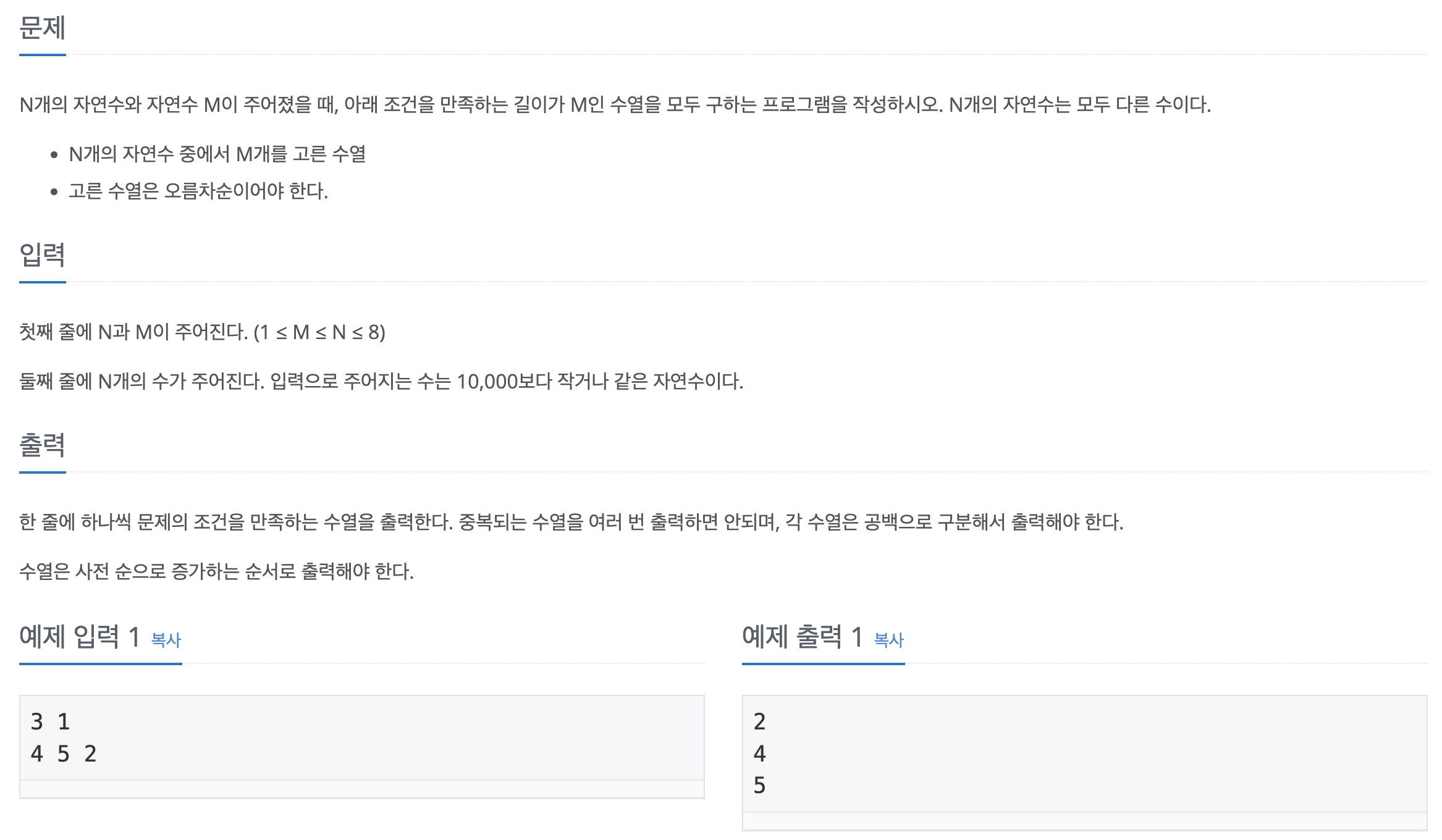
문제바로가기여기서 주의해야할 점은 print(\*nums) 부분이었다. 출력양식이 대괄호 \[] 없이 숫자만 띄어쓰기로 구분해서 출력해야함!이 문제도 역시 N과 M 시리즈를 풀었다면 쉽게 금방 풀 수 있다.
43.[백준-파이썬] 2606-바이러스
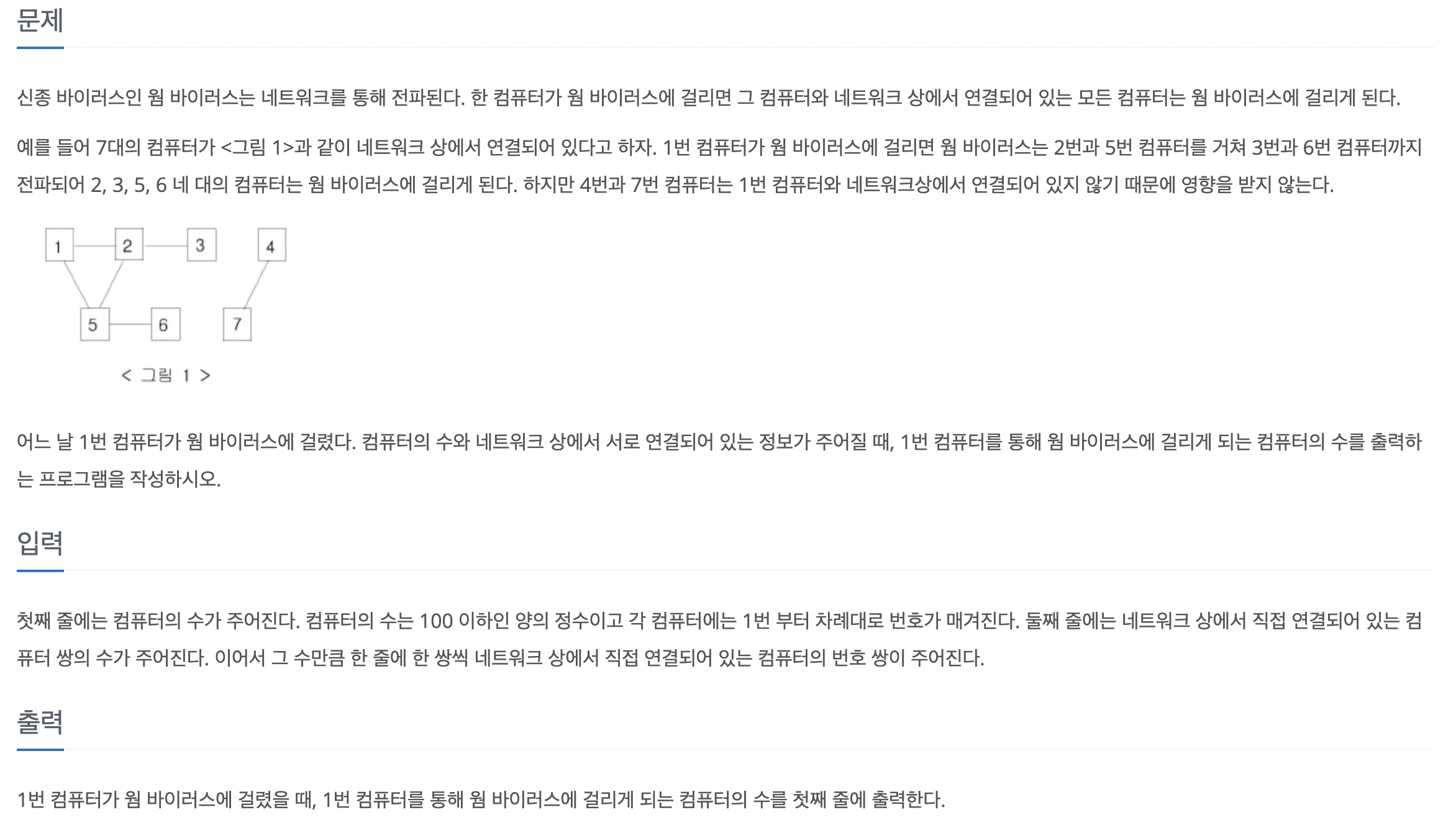
문제바로가기1번 컴퓨터에 연결된 모든 컴퓨터의 개수를 세는 문제로 bfs나 dfs를 구현하는 문제이다. 나는 평소에 dfs로 문제풀이를 많이 하기 때문에 이번엔 bfs로 코드를 짜보았다.마지막에 count-1을 해주는 이유는 1번 컴퓨터도 개수 집계가 되기 때문이다.
44.[백준-파이썬] 10026-적록색맹
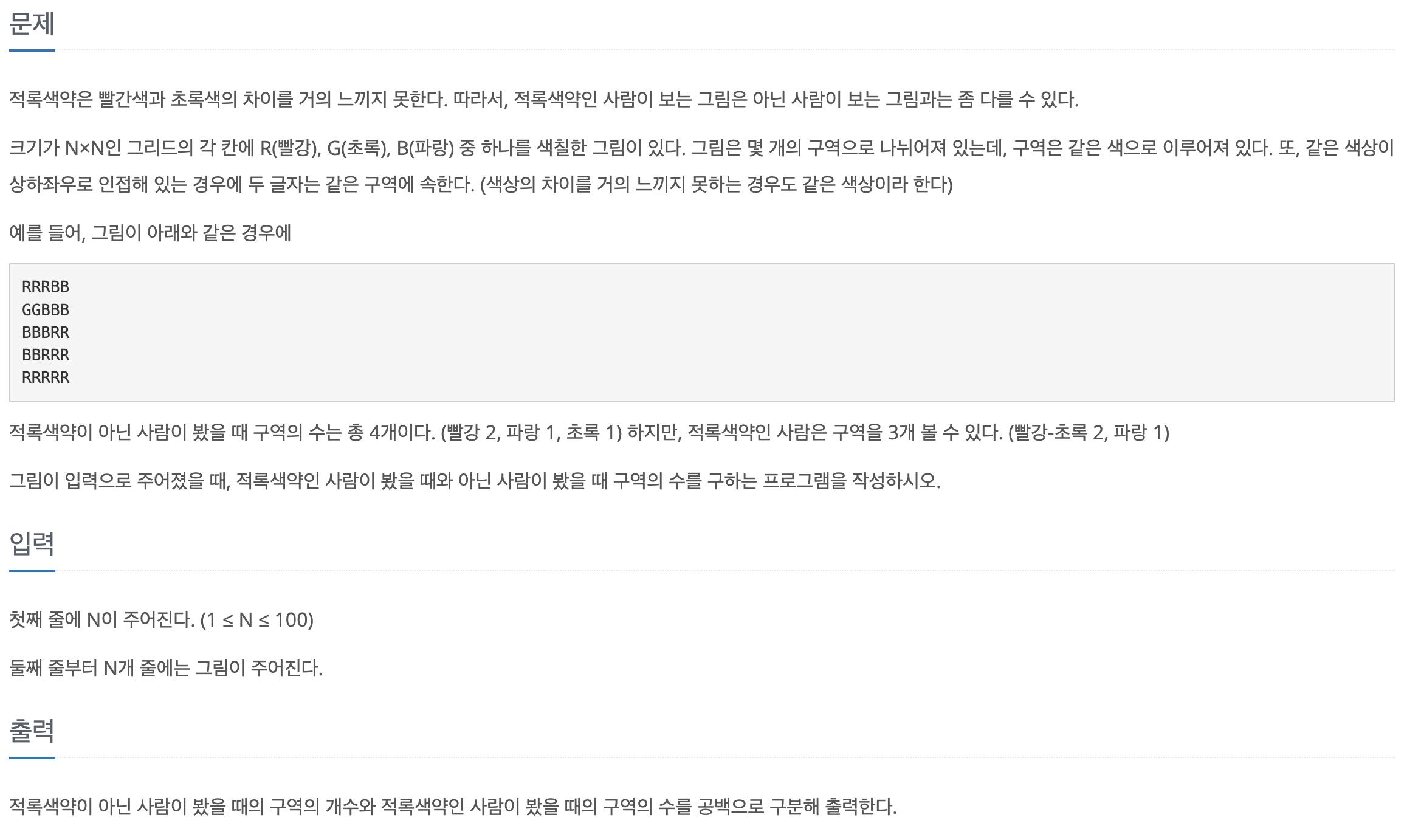
문제바로가기2178과 2160을 섞은 문제다.핵심은 사방의 (좌우상하) 값을 보고 같은 지 비교해야 하는 것이다. 처음에 이중포문 없이 구현하겠다고 last_r, last_c를 선언하여 끝나는 지점의 인덱스를 저장하고 한칸 이동하여 다시 search를 했더니 예제의 G
45.[백준-파이썬] 1753-최단경로

문제바로가기완벽히 다엑스트라 구현 문제이다. 처음에 구현한 코드는 잘 돌아가지만, 인접리스트로 구현했기 때문에 메모리 초과를 피할 수 없었다. 왜냐하면 v가 커질수록 더 많은 메모리가 필요한데 최대 v는 20000이므로 10^8을 수용할 수 있는 메모리가 필요하다. 굉
46.[백준-파이썬] 1149-RGB거리
문제바로가기i번째 위치에 있을 때, 각각 R G B을 선택했을 때의 최소값을 계산하면 모든 경우의 수를 확인할 수 있다. 이후 마지막 row의 최소값이 정답이 된다.