
2.1 인덱스 구조 및 탐색
✨ 인덱스 탐색 과정은 수직적 탐색과 수평적 탐색, 단 두 단계로 이루어진다.
데이터를 찾는 두 가지 방법
- Full Scan
- 조회할 데이터가 많은 경우,
Full Scan이 효율적 - [예시] 모든 학년의 모든 반의 교실을 돌며 홍길동 학생 찾기
- Index Range Scan
- 대용량 테이블에서 소량의 데이터를 조회할 경우,
Index Rnage Scan이 효율적 - [예시] 교무실에서 학생부를 조회해 홍길동 학생이 있는 교실만 찾아가기
인덱스 튜닝의 두 가지 핵심 요소
✨ 인덱스는 큰 테이블에서 소량 데이터를 검색할 때 사용한다.
- 인덱스 스캔 효율화 튜닝
- 인덱스 스캔 과정에서 발생하는 비효율을 최소화
- 인덱스 컬럼 순서에 따라 스캔하는 데이터 양이 상이함
[예시 1] 학생부를 [이름-시력] 순으로 정렬한 경우, 소량 스캔
| 이름 | 시력 | 학년-반-번호(ROWID) |
|---|---|---|
| 강수지 | 1.5 | 4학년 3반 37번 |
| 김철수 | 0.5 | 3학년 2반 13번 |
| … | … | … |
| 이영희 | 1.5 | 6학년 4반 19번 |
| …. | … | … |
| ✅홍길동 | 1.0 | 2학년 6반 24번 |
| ✅홍길동 | 1.5 | 5학년 1반 16번 |
| ✅홍길동 | 2.0 | 1학년 5반 15번 |
[예시 2] 학생부를 [시력-이름] 순으로 정렬한 경우, 전체 스캔
| 시력 | 이름 | 학년-반-번호(ROWID) |
|---|---|---|
| 0.5 | 김철수 | 3학년 2반 13번 |
| … | … | … |
| 1.0 | ✅홍길동 | 5학년 1반 16번 |
| 1.5 | 강수지 | 4학년 3반 37번 |
| 1.5 | 이영희 | 6학년 4반 19번 |
| 1.5 | ✅홍길동 | 1학년 5반 15번 |
| 1.5 | … | … |
| 2.0 | ✅홍길동 | 2학년 6반 24번 |
- 랜덤 액세스 최소화 튜닝
- 테이블 액세스 횟수를 최소화
- 인덱스 스캔 후 테이블 레코드를 액세스할 때 랜덤 I/O 방식을 사용
- 랜덤 액세스 최소화 튜닝이 성능에 미치는 영향이 더 크다.
- 🚀 즉, SQL 튜닝은 랜덤 I/O 와의 전쟁이다.
SQL 튜닝은 랜덤 I/O와의 전쟁
- 데이터베이스의 성능이 느린 이유는 디스크 I/O 때문인데, 그 중에서도 랜덤I/O가 특히 중요하다.
- DBMS가 제공하는 많은 성능 관련 기능도 랜덤 I/O를 극복하기 위해 개발되었다.
왜 하필 랜덤 I/O일까?
- 디스크 접근 방식에서 랜덤 I/O가 성능 저하의 가장 큰 원인 중 하나이기 때문이다.
| 구분 | 설명 | 성능 차이 |
|---|---|---|
| 시퀀셜 I/O(Sequential I/O) | 연속된 블록을 디스크에서 한번에 읽음 | 빠름(디스크 헤드 이동이 거의 없음) |
| 랜덤 I/O(Random I/O) | 디스크 이곳저곳을 건너뛰며 블록을 읽음 | 느림(디스크 헤드가 계속 움직임) |
인덱스 구조
- 인덱스는 대용량 테이블에서 필요한 데이터만 빠르게 효율적으로 액세스하기 위해 사용하는 오브젝트
- 인덱스를 이용하면 일부만 읽고 멈출 수 있다 - 범위 스캔(Range Scan)이 가능하다
- ✨ 범위 스캔이 가능한 이유는 인덱스가 정렬돼 있기 때문이다. - B-Tree 구조
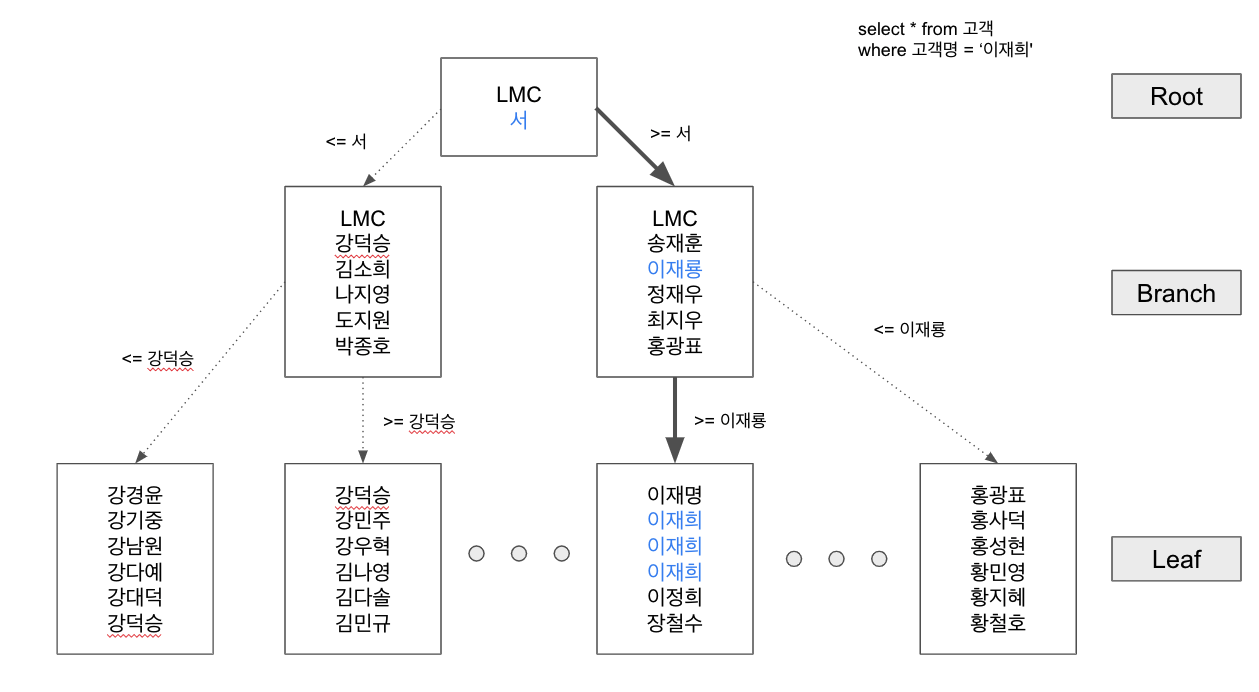
인덱스 수직적 탐색
- 인덱스 스캔 시작지점을 찾는 과정
- 즉, 정렬된 인덱스 레코드 중 조건을 만족하는 첫 번째 레코드를 찾는 과정
- 루트와 브랜치 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 가진다.
- 수직적 탐색 과정에서 찾고자 하는 값보다 크거나 같은 값을 만나면,
바로 직전 레코드가 가리키는 하위 블록으로 이동한다.
인덱스 수평적 탐색
- 데이터를 찾는 과정
- 수직적 탐색을 통해 스캔 시작점을 찾았으면,
찾고자 하는 데이터가 더 안나타날 때까지 인덱스 리프 블록을 수평적으로 스캔 - 인덱스 리프 블록끼리는 서로 앞뒤 블록에 대한 주소값을 가진다. - 양방향 연결 리스트 구조
인덱스를 수평적으로 탐색하는 이유
- 조건절을 만족하는 데이터를 모두 찾기 위해
ROWID를 얻기 위해
- 일반적으로 인덱스를 스캔하고 테이블을 액세스하는데, 이때
ROWID가 필요하다.
결합 인덱스 구조와 탐색
결합 인덱스의 오해와 진실
인덱스 정렬
- 인덱스 범위 스캔이 가능한 이유는 인덱스가 정렬되어있기 때문에 가능하다는데,
사용자는 인덱스를create할 뿐 별도로 정렬하지 않는다. - 어떻게 가능할까 ?
📦 product 테이블의 name 컬럼에 인덱스를 생성하면?
CREATE TABLE product (
id INT PRIMARY KEY,
name VARCHAR(100)
);
INSERT INTO product (id, name) VALUES
(1, 'banana'),
(2, 'apple'),
(3, 'mango'),
(4, 'cherry');CREATE INDEX idx_product_name ON product(name);인덱스 정렬
product.name기준으로 B*Tree 인덱스가 생성
[cherry]
/ \
[apple] [mango]
/
[banana]- 실제 Leaf 노드는 정렬된 연결 리스트 형태로 구성됨
[apple] → [banana] → [cherry] → [mango]- 각 노드는 해당 이름 값과 연결된 row의 주소(
ROWID)를 가지고 있어,
테이블에서 실제 데이터를 빠르게 찾을 수 있음 product테이블 자체는 정렬❌- 인덱스는 정렬된 상태로 별도의 저장 공간에 유지❗
범위 스캔이 가능한 이유
SELECT * FROM product WHERE name BETWEEN 'banana' AND 'mango';idx_product_name인덱스에서'banana'를 찾아 Leaf 노드로 이동- 그 다음 Leaf 노드들을 오른쪽으로 순차적으로 이동하며
'mango'까지 검색 - 각 인덱스 항목이 가리키는 row 주소(ROWID)를 따라가서 테이블에서 데이터 조회
즉, 정렬된 인덱스 덕분에 연속된 leaf 노드 탐색만으로 범위 검색이 가능해지고, 빠른 I/O를 유도
특정 컬럼을 인덱스로 생성하면?
- 테이블의 특정 컬럼을 기준으로 인덱스를 생성하면, 그 컬럼의 모든 값이 인덱스에 정렬된 상태로 포함됨
- 예를 들어
product.name컬럼의 값이 100개 라면,
100개의 값 모두가 인덱스 트리의 리프 노드에 정렬된 상태로 저장
- 예를 들어
NULL이 아닌 모든 컬럼 값을 따로 복사해 정렬된 트리구조로 저장- 중복된 컬럼 값도 모두 인덱스에 포함
- NULL 값은 인덱스에 포함❌
- 정렬은 인덱스 내부에서만 이뤄지며, 테이블은 그대로

"개발자는 해결사이자 발견자이다✨" - Michael C. Feathers