
1.3 데이터 저장 구조 및 I/O 메커니즘
SQL이 느린 이유
I/O 튜닝이 곧 SQL 튜닝이다!
- 디스크 I/O를 처리하기 위해 프로세스는 OS에게 시스템 콜 호출
- CPU가 OS에게 반환되며, 프로세스는 대기 상태 - 디스크 I/O 작업 완료를 대기
- 열심히 일할 프로세스가 대기하게 되니 느릴 수밖에!
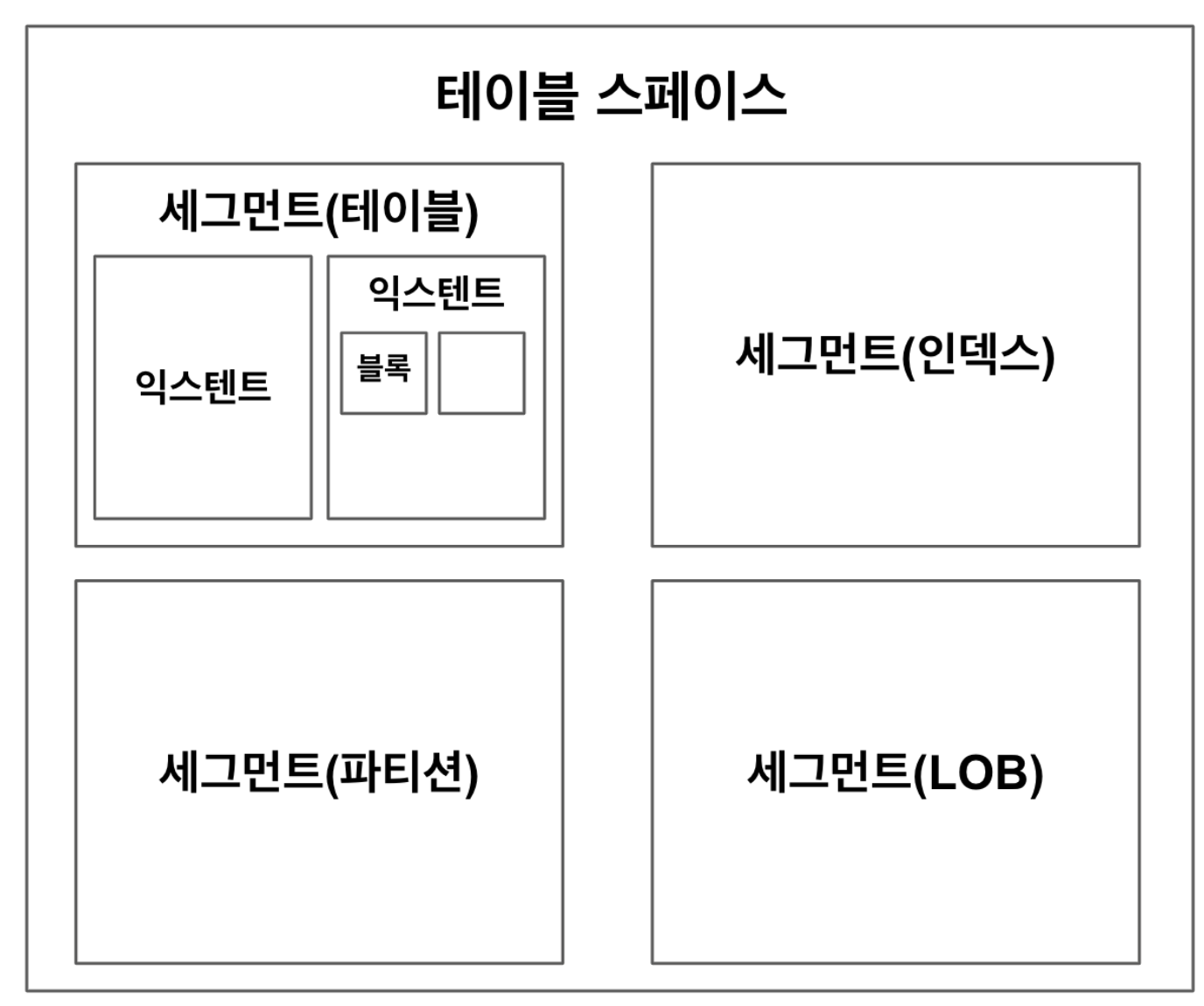
데이터베이스 저장 구조
| 이름 | 설명 |
|---|---|
| 테이블 스페이스 | 세그먼트를 담는 컨테이너. 데이터 저장을 위한 논리적 단위, 데이터를 저장하기 위해 먼저 생성되어야 함 |
| 세그먼트 | 테이블, 인덱스와 같이 데이터 저장공간이 필요한 논리적 데이터 오브젝트, 일종의 저장공간 단위, 그냥 테이블, 인덱스 = 세그먼트, 여러 개의 익스텐트로 구성, ❗ LOB 컬럼은 자신이 속한 테이블과 별도 공간에 값을 저장 |
| 데이터 파일 | 테이블 스페이스에 포함된 실제 물리적 파일 |
| 익스텐트 | 세그먼트 공간 확장 단위, ✨연속된 블록들의 집합, 하나의 테이블이 독점 → 익스텐트 내 블록들은 모두 같은 테이블, 같은 세그먼트에 속한 익스텐트들은 같은 데이터 파일에 위치하지 않을 수 있음 → 파일 경합을 줄이기 위해 여러 데이터 파일로 분산 저장 |
| 블록 | 사용자가 입력한 데이터를 실제로 저장하는 공간. 하나의 테이블이 독점 → 블록 내 레코드들은 모두 같은 테이블 |
물리적인 저장 구조
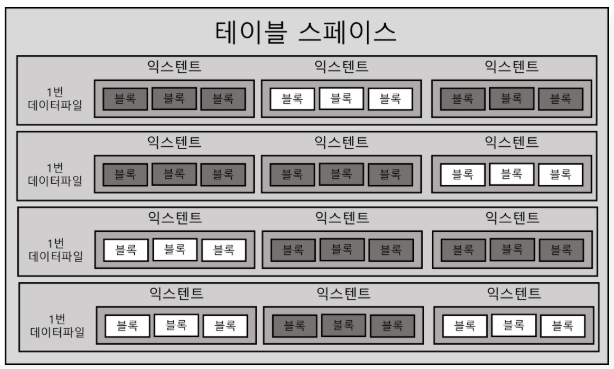
세그먼트에 할당된 모든 익스텐트가 같은 데이터파일에 위치하지 않을 수 있다.
아니 서로 다른 데이터파일에 위치할 가능성이 더 높다.
하나의 테이블스페이스를 여러 데이터파일로 구성하면, 파일 경합을 줄이기 위해
DBMS가 데이터를 가능한 여러 데이터파일로 분산해서 저장하기 때문이다.
- 익스텐트 내 블록은 연속된 공간에 저장되지만, 익스텐트들은 연속된 공간에 저장❌
- 왜? 파일 경합을 줄이기 위해
- 그럼 파일 경합을 줄인다는게 뭔소린데 .. ?
데이터파일 분산 저장과 파일 경합
1. 테이블 스페이스는 보통 여러 개의 데이터 파일로 구성됨
- 여러 데이터 파일로 구성하면 DB는 데이터를 굳이 한 파일에 몰아넣을 필요가 없음
2. 세그먼트가 커지면 익스텐트를 할당받음
- 처음에는 하나의 데이터파일에서 익스텐트를 할당받지만,
세그먼트가 점점 커지면 다른 데이터파일에서 익스텐트를 나눠받을 수 있고
이건 DBMS가 자동으로 처리함
3. 그런데 왜 굳이 분산해서 저장할까?
- I/O 병목을 피하기 위해 분산해서 저장 - 파일 경합
- 만약 하나의 데이터파일에만 모든 데이터를 저장하면,
해당 파일에만 디스크 I/O가 집중됨 - DBMS는 이런 파일 경합을 피하기 위해 여러 파일에 걸체 데이터를 분산 저장
- ✨ 파일 경합 최소화 전략
다시 원문을 해석해보자면,
“세그먼트에 할당된 모든 익스텐트가 같은 데이터파일에 위치하지 않을 수 있다.”
→ 익스텐트가 여러 파일에 나뉘어 저장될 수 있다
“아니, 서로 다른 파일에 저장될 가능성이 더 크다.”
→ DB가 자동으로 분산을 선호하기 때문
“하나의 테이블스페이스를 여러 데이터파일로 구성하면, 파일 경합을 줄이기 위해 분산 저장”
→ 실제로 이게 Oracle의 동작 방식
→ DB가 I/O 병목 피하려고 알아서 분산 저장
물리적인 저장 구조에서 세그먼트가 안보인다?
- 세그먼트가 실제 물리적으로 저장될 때는, 해당 데이터를 담는 저장소가 데이터파일
- 즉, 세그먼트는 테이블 같은 논리적 객체고
실제로 디스크에 데이터를 저장할 때는 데이터 파일이라는 물리적 파일에 기록
DBA(Data Block Address)
- 모든 데이터 블럭은 고유한 주소값(디스크의 어떤 데이터 파일의 몇 번째 블록인지)을
가지는데, 이 고유한 주소값이 DBA - 데이터를 읽고 쓰는 단위가 블록이므로, 데이터 조회 시 DBA 확인 필요
- 인덱스로 레코드를 읽는 경우
ROWID가 필요 ROWID=DBA+ 로우 번호` - 어떤 블록의 몇번째 레코드?ROWID를 분해하면 DBA 추출 가능
- 테이블 스캔을 하는 경우 익스텐트 맵을 이용(테이블 세그먼트 헤더에 저장)
- 익스텐트 맵은 익스텐트 번호와 해당 익스텐트 내 첫번째 블록 DBA를 가짐
- 익스텐트는 연속된 블록 집합이므로 거기서부터 읽으면 됨
데이터를 읽고 쓰는 단위와 블록 단위 I/O
- 데이터를 읽고 쓰는 단위는 블록, 레코드 하나만 읽고 싶어도 블록 전체를 읽어야함
- 테이블, 인덱스 모두 블록단위로 읽고 씀
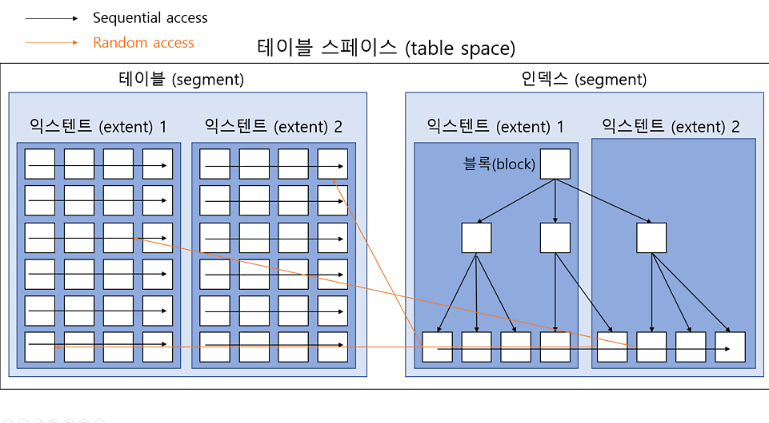
시퀀셜 액세스와 랜덤 액세스
- 테이블과 인덱스 블록을 액세스 하는 방식
- 시퀀셜 액세스 : 논리적 or 물리적으로 연결된 순서대로 액세스
- 랜덤 액세스 : 순서대로 액세스❌, 레코드 하나를 읽기 위해 한 블록씩 액세스
여기서 생각해볼점 - 테이블과 인덱스의 시퀀셜 액세스
- 인덱스의 경우
B-Tree구조를 따르고, 이 구조의 경우
인덱스 리프 블록은 서로 논리적으로 연결되어 있음(앞뒤 주소값을 가짐)
따라서 시퀀셜 액세스 가능 - 그런데 테이블 블록은 논리적 연결❌, 그런데 어떻게 시퀀셜 액세스가 가능할까?
익스텐트 맵을 사용해 시퀀셜 액세스 가능- 익스텐트 맵은 해당 익스텐트 내의 첫번째 데이터 블록의 주소값을 가짐(DBA)
- 그리고 익스텐트는 연속된 블록의 집합
- 그럼 익스텐트 맵에서 얻은 DBA를 시작으로 순서대로 읽으면 됨 - Table Full Scan

"개발자는 해결사이자 발견자이다✨" - Michael C. Feathers