Seq2Seq, Attention, Transformer 아키텍처 개요
Seq2Seq (Sequence-to-Sequence)
- 인코더-디코더 구조를 갖춘 RNN 기반 번역 모델
- 주로 기계 번역, 대화 생성 등에 사용
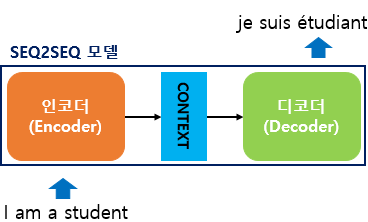
구성 요소
- Encoder: 입력 시퀀스를 읽고 고정된 컨텍스트 벡터로 요약
- Decoder: 컨텍스트 벡터를 바탕으로 출력 시퀀스를 생성
문제점
- 입력 시퀀스를 하나의 벡터에 압축해야 해서 정보 손실 발생
- 긴 문장의 경우 기울기 소실 문제로 학습 어려움 발생
기울기 소실: 역전파 시 가중치 업데이트가 깊은 층까지 전달되지 않는 현상
Attention Mechanism
기본 아이디어
- 출력 단어 예측 시, 입력 전체를 다시 참고하자!
- 예측할 단어와 관련된 입력 부분에 집중(Attention)
수식 정의
Attention(Q, K, V) = softmax(QKᵀ / √dₖ) * V- Q (Query): 디코더의 현재 시점 은닉 상태
- K (Key): 인코더의 모든 은닉 상태
- V (Value): 인코더의 모든 은닉 상태
작동 방식
- Query와 각 Key 간의 유사도를 계산
- Softmax로 확률 분포화
- 각 Value에 가중치를 곱해 context 벡터 생성
- 이 context 벡터를 기반으로 단어 생성
Transformer: 어텐션 기반의 혁신적 구조
- 2017년 논문 “Attention is All You Need”에서 처음 제안
- RNN 없이 어텐션만으로 문장을 처리
- 빠르고 병렬처리에 유리함
주요 구조
| 구성 요소 | 역할 |
|---|---|
| Self-Attention | 문장 내 단어들 간 관계 파악 |
| Multi-Head Attention | 다양한 시각에서 어텐션 수행 |
| Position-wise Feed Forward | 각 토큰에 독립적 FFNN 적용 |
| Positional Encoding | 순서 정보 부여 |
| Layer Norm & Residual | 학습 안정성 및 정보 보존 |
Transformer의 Attention 구성
Self-Attention
- Q = K = V = 입력 시퀀스의 모든 단어 벡터
- 입력 단어들 사이의 내부 관계를 파악
Multi-Head Attention
- 여러 개의 어텐션을 병렬로 수행 후 합침
- 다양한 관계를 한 번에 학습 가능
Transformer 전체 구조 요약
인코더
- Embedding + Positional Encoding
- Multi-Head Attention
- Feed Forward
- Residual + Layer Norm
디코더
- 위 구조 + 인코더-디코더 어텐션 포함
- 출력 마스킹 (Look-ahead Masking)으로 미래 정보 차단
비교 요약
| 모델 | 시퀀스 처리 | 어텐션 사용 | 병렬화 | 장점 |
|---|---|---|---|---|
| Seq2Seq (RNN) | 순차적 | ❌ | ❌ | 구조 간단 |
| Seq2Seq + Attention | 순차적 + 선택적 집중 | ✅ | ❌ | 긴 문장에 강함 |
| Transformer | 전체 병렬 처리 | ✅ (Self + Encoder-Decoder) | ✅ | 속도, 성능 우수 |
