HAN (ECCV 2020)
HAN: Holistic Attention Network (ECCV 2020)
Single Image Super-Resolution via a Holistic Attention Network
Holistic: 전체론의
모델 구조
Feature Extraction Step
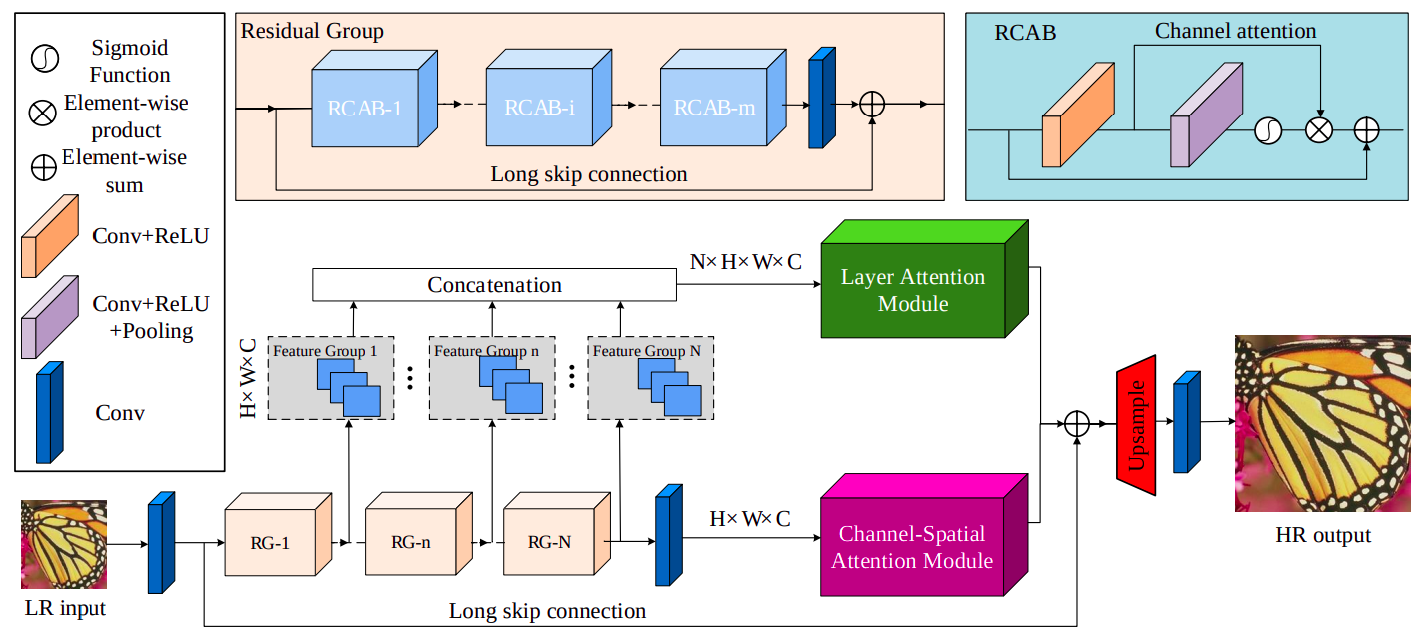
RG(Residual Group)을 쌓고 중간중간에 발생하는 feature들을 전체적으로 모아서(concatenation) layer attention module을 통해 attention을 적용시켜준다.
또한 RG를 통과하면서 나오는 feature들도 channel-spatial attention을 적용시키고 둘을 합치면서 HR과 LR의 차이값을 학습한다.
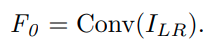
I_LR은 입력 LR 이미지
F_0은 입력 conv를 통과한 shallow feature
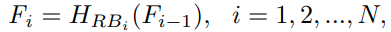
H_RB_i() 는 i번 째 RG.
F_i는 i번 째 RG를 통과한 feature.
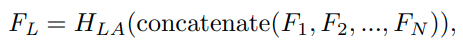
1번부터 N번까지 모든 RG를 통과한 feature를 concat한 것을 F_L이라고 한다. (즉, 각 RG들의 입출력 사이즈는 동일한듯??)
H_LA는 LAM(Layer Attention Module)을 의미
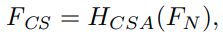
H_CSA는 CSAM(Channel-Spatial Attention Module)을 의미
Reconstruction Step
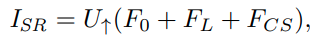
Shallow feature인 F_0과, layer attention에서 나온 feature인 F_L, CSAM을 통한 F_CS를 element sum한 것을 upsample한다.
U_up()는 sub-pixel convolution이라고 하는데... 코드를 확인해보니 pixel shuffle과 batch normalization을 반복해서 사용한다.
Loss Function
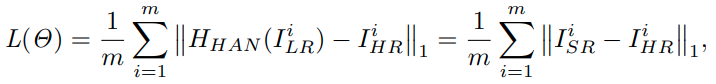
평범하게 L1 loss를 사용한다.
Layer Attention Module
서로 다른 layer 깊이에 있는 feature들의 관계에 대해서 학습하고 자동적으로 feature representation 성능을 향상시킨다.
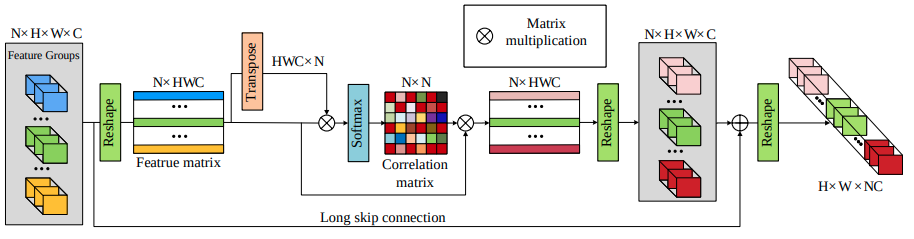
F_1 ~ F_N 까지 RG의 출력으로 나온 N개의 feature group들을 concatenate하면 NxHxWxC 크기의 tensor가 된다.
이 feature를 2차원 행렬로 reshape하여 NxHWC와 HWCxN의 행렬을 만들고, 둘을 서로 행렬곱하고 softmax 연산을 취하면 NxN크기의 feature group관의 관계를 나타내는 correlation matrix가 만들어진다.
NxN크기의 correlation matrix에 NxHWC 크기의 feature matrix를 행렬곱해서 feature attention을 수행하고, 다시 NxHxWxC 크기로 reshape 한 뒤 기존의 NxHxWxC 크기의 tensor와 weighted sum을 해주는 과정을 layer attention이라고 한다.
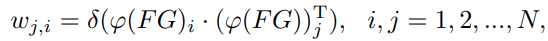
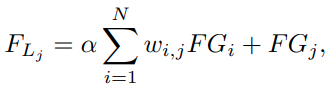
그림에는 없지만 attention value를 더해줄 때 가중치 a를 두고 가중합을 한다.
a 값은 처음에는 0으로 두어 attention을 주지 않다가, 모델에 의해 자동으로 값이 할당된다고 한다.
Channel-Spatial Attention
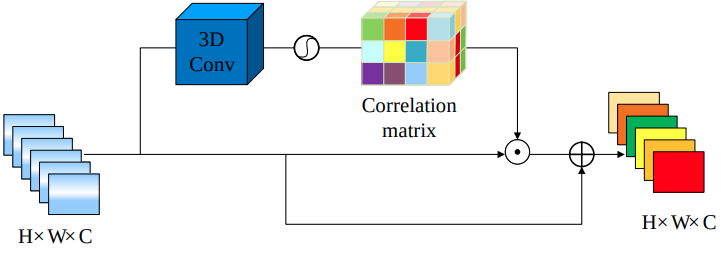
CBAM(Convolutional Block Attention Module, ECCV 2018)의 구조를 참고해서 만들었다고 한다.
최근의 channel attention 기반의 모델들은 대부분 scale information을 무시하고 channel 간의 관계에만 집중하고 있기 때문에 이런 문제를 해결하기 위해 둘을 동시에 고려하는 channel-spatial attention을 만들었다.
모든 feature group에 CSAM을 쓸 수 있었으나, 연산량 증가 때문에 마지막 layer에만 사용했다고 함.
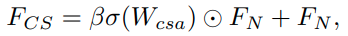
feature는 1개의 채널을 갖는 HxWxCx1 크기의 큐브라고 볼 수도 있으므로, 여기에 3D CNN을 적용하고 sigmoid를 해서 3차원 correlation matrix를 생성한다.
correlation matrix에 기존의 feature를 곱하고, 이 값을 가중치 beta로 기존의 feature와 가중합한다.
beta는 처음에는 0이었다가, epoch이 진행되면서 점점 증가한다고 한다.
3D Conv가 아니라 fully connected 였다면 Kaming He의 Non-local Neural Netowkr (CVPR 2018)과 거의 흡사하다.
Fully connected 대신에 CNN을 써서 local한 channel-spatial 관계를 보도록 하고 연산량을 줄이는 것은 ECA-Net(CVPR 2020)과 유사해 보인다.
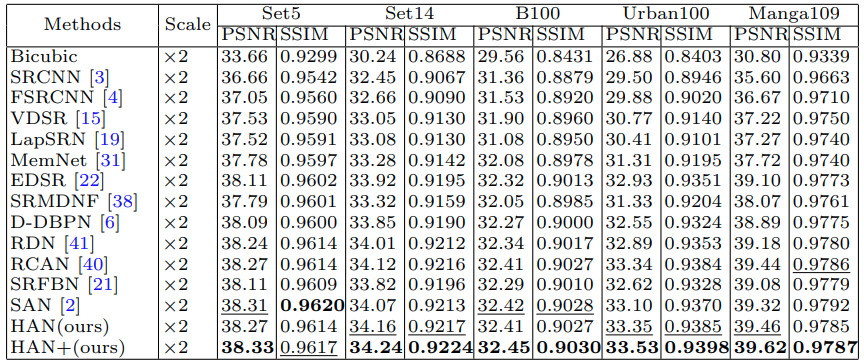
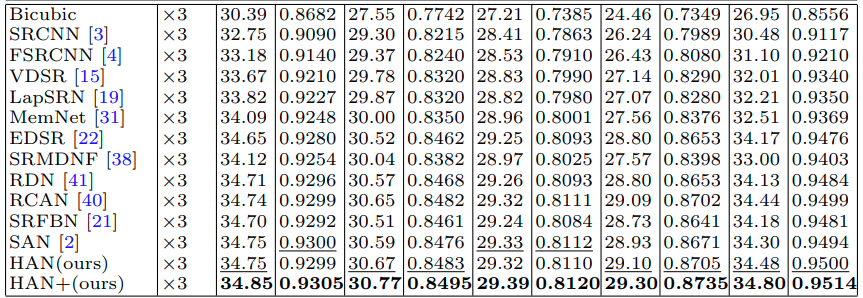
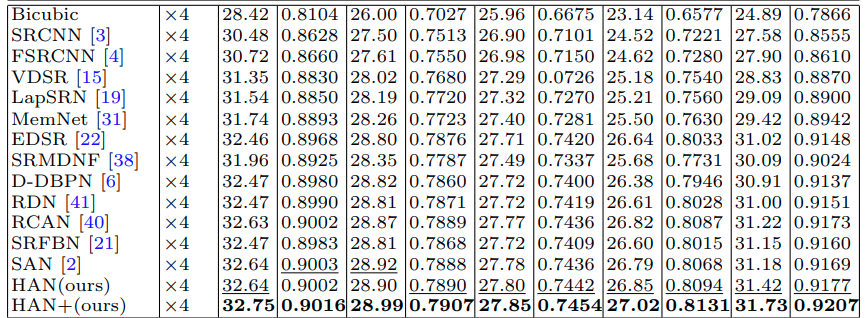
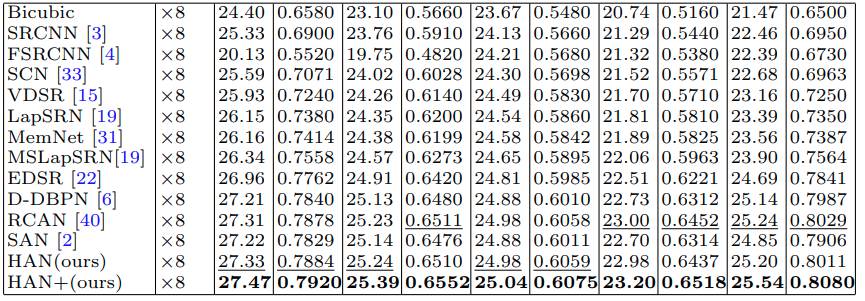
결과
HAN+는 augmentation(rotation 90 + flip) 을 적용한 self-ensemble 결과로 보인다.
개인 의견
2018년쯤부터 RCAN 이후로는 대부분 기존의 Super Resolution netowrk 구조에 SE-Net, CBAM, ECA-Net 등에서 소개된 channel attention을 SR network에 맞게 개선하여 적용하면서 모델 성능을 향상시키는 쪽으로 발전되고 있는 것으로 보인다
기존의 국소적으로 작용하던 channel attention을 모든 layer에 대해 종합적으로 작용하도록 하여 성능을 향상시켰다.
이번 논문도 RCAN을 베이스로 attention을 전체 layer에 대해서 전체적으로 작용하도록 함으로써 성능 향상을 본 것 같다.
