Deep Residual Learning for Image Recognition
paper_review

1. Introduction
왜 deeper layer의 성능이 shallow layer 보다 좋지 않았다.
overfitting 때문일까? -> 그것도 아니더라.
3.1. Residual Learning


실험을 해봤더니, H(x)가 x가 되는 것 보다 f(x)가 0이 되는게 더 쉽다.
Residual == F(x)
변화량(Residual)만 학습해도 되도록 해보자
3.2. Identity Mapping by Shortcuts
몇 개의 스택 레이어마다 잔여 학습을 채택
Building block의 수식은 아래와 같다.
: input vector
: output vector
-> 학습됨을 보여줌
2 layers =>
에서 시그마가 ReLU 임
bias는 단순화를 위해 생략
는 shortcut으로 연결도 되고 element-wise로도 더할 수 있다.
shortcut 연결은 추가 매개변수나 계산 복잡성이 없다
x와 F의 차원이 같다
차원이 같지 않다면 linear projection 를 수행할 수 있다.
residual function은 유연하다
2개 혹은 3개 레이어를 가진 것을 소개하지만 더 많은 레이어도 가능하다
레이어가 1개인 경우에는 거의 linear layer랑 비슷하다 (우리가 공부할 필요없다)
위의 표기는 FC layer에 맞춘 것이지만 CNN에서도 적용 가능하다
이해가 부족한 부분
- The element-wise addition is performed on two feature maps, channel by channel.
=> 원소의 곱(https://ayoteralab.tistory.com/57)
3.3. Network Architectures
Plain Networks.
이 플레인 베이스라인은 VGG net에서 영감을 얻었다. conv layer는 3*3 필터를 가지고 2가지 규칙을 따른다.
- 동일한 아웃풋 피쳐 맵 사이즈에 따라 레이어는 동일한 수의 필터를 가짐
- 피쳐 맵 사이즈가 절반이 되면, 레이어당 시간 복잡도를 보존하기 위해 필터가 두배가 된다.
stride가 2인 conv 레이어로 다운샘플링한다.
global pooling layer 와 FC layer로 플레인 네트워크를 마무리한다.
총 레이어 : 34
이건 VGG net보다 이 모델이 더 적은 필터와 복잡도가 작다는 점에서 주목할 만한 가치가 있다.
Residual Networks.
플레인 베이스라인에 shortcut 연결을 삽입한 것이다. 이 연결은 플레인 네트워크를 counterpart residual version으로 만든다. 차원이 증가하면 2가지 옵션이 있다.
- 제로 패딩으로 차원을 올린다
- 에서 shortcut이 차원 맞추는데 사용된다
3.4. Implementation
이미지에서 랜덤하게 crop하던지 접어서 224*224를 준비.
- with the per-pixel mean subtracted [21]
conv와 activation 사이에 BN 추가
256사이즈의 미니 배치와 SGD사용
learning rate는 0.1로 시작해서 에러가 생길 때마다 1/10배
weight decay는 0.0001, 모멘텀은 0.9으로 사용
- weight decay가 뭘까? -> loss function의 하이퍼파라미터
4. Experiments
4.1. ImageNet Classification
top-1 and top-5 error rates로 평가 받았다
Plain Networks.
18 레이어와 34 레이어의 플레인 넷을 평가
더 깊은 34 레이어 플레인 넷이 valid error에서 18 레이어보다 더 높게 나왔다.
(higher validation error 는 valid 에러가 높게 나와서 valid test 결과가 worse하다는 뜻)
train/valid error를 비교해봤다. degradation problem - 34 레이어 플레인 넷에서 train 에러가 더 높게 나옴. BN 때문에 forward, backward 시그널은 사라지지 않는다.
deep plain net 은 트레이닝 에러가 줄도록 기하급수적으로 수렴률을 가질 것으로 추측
Residual Networks.
모든 shorcut을 위해 identity mapping 사용하고 차원을 올리기 위해 제로 패딩 사용. 플레인과 비교했을 때, 이것은 따른 파라미터가 필요하지 않다.
첫번째, 34 레이어 ResNet은 적은 트레이닝 에러를 보이고 valid data로 일반화 할 수 있다.
두번째, 플레인과 비교했을 때 residual은 성공적으로 트레이닝 에러를 줄였다. 이런 비교는 극도로 깊은 시스템에서 residual의 효율성을 증명했다.
마지막으로, 18 레이어 ResNet은 빠르게 수렴한다. 또 그렇게 깊지 않은 net일 때, SGD는 플레인 넷에서 여전히 좋은 해결책이다.
Deeper Bottleneck Architectures.
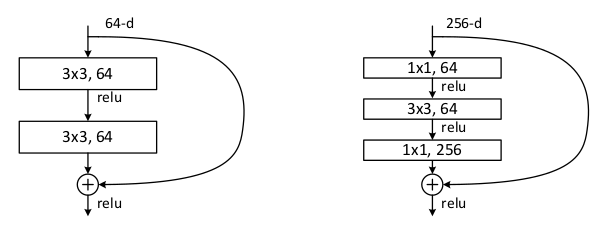
layer 는 늘어나지만 depth를 줄이는 방법인 bottleneck에서도 ResNet의 identity shortcut은 효과적이다.
스터디 간단 정리
- F(x)가 0이 돼도 'x'가 살아남으니, 즉 H(x) =x, Identity Mapping이 되니까 gradient vanishing이 없어서 학습이 잘된다.
- degradation(뎁스, 모델과 모델사이)과 vanishing(레이어 안에서) 차이
- page 6 -> (A)zero padding은 residual 학습을 하지 않은 것이고 (B), (C) 는 학습한 residual 이기 때문에 성능이 better하다



맘에 전혀 들지 않지만.... 내일 다시 수정하자.(4/5/월)
-> 수정 완료(4/6/화)