TMDB에서 영화 데이터 가져오기 🍿
오늘은 영화 데이터를 어디서 가져와야하며, 어떻게 가공하고 저장하는지에 대한 포스팅 글을 써보고자 한다.
다른 데이터들도 그렇겠지만, 영화 데이터에는 많은 필드가 집합 되어 있다.

기생충 영화를 예를 들어보자.
일단 기본적으로 출연 배우, 감독 등 출연진 정보가 필요하다. (이름, 이미지 등)
그리고 영화 포스터 이미지, 스틸컷, 예고편, 심의등급, 개봉일자 등등 많은 필드를 담고있다.
그래서 핵심은 이 데이터를 주는 곳을 적합한 API를 찾는 것이 제일 중요하다 👍
1️⃣ 영화 DB가 왜 필요 했는가?
LG U+ 유레카 최종 융합 프로젝트에서 영화 리뷰 플랫폼을 개발하게 되었다.
그래서 위처럼 정확하고 로컬라이징이 잘 되어있고 다양한 정보를 제공하는 API를 찾는 것이 최우선적이였다.
2️⃣ 영화 DB API 선택
- 그래서 어떤 API를 선택했는가?
내가 선택한 영화 DB API는 TMDB API를 선택했다.
그 이유는 다음과 같다.
- 로컬라이징이 훌륭하다. 타이틀, 출연진 정보 등 한국어 번역이 잘 되어있다.
- 영화 데이터가 굉장히 방대하다.
- 쿼리를 통해 다양한 API를 호출할 수 있는 기능을 제공한다.
- 각 국가 별 심의 등급, 날짜 별 인기 영화 순위 등
이 같은 이유로 후보로 있던 KMDB, OMDB는 제외 되었다.
3️⃣ 영화 데이터 가져오기
프로젝트 진행 시 우리는 총 4천여개의 영화 데이터를 저장하고자 했다.
단, 여기서 영화를 추출한 기준을 적용하여 어느정도 인지도가 있고, 대중성 있는 영화를 선택할 필요가 있었다.
영화 데이터 선정 기준 ✅
1990년도 부터 2024년도까지 rating이 높은 (인기가 있는) 영화로 정렬
- 각 연도 별로 100개씩 추출
인기순으로 먼저 정렬하는 쿼리로 API를 요청해서 받아온 데이터를 일단 필터링한다.
Code
@Transactional
public AdminMovieBaseAddResponse defaultMoviesAdd() {
long movieAddCount = 0;
for (int year = 1990; year >= 2024; year--) {
for (int page = 1; page <= 5; page++) {
String urlDiscover = createDiscoverUrl(year, page);
TMDBMovieSearchResponse response = webClient.get()
.uri(urlDiscover)
.header("accept", "application/json")
.retrieve()
.onStatus(HttpStatusCode::is4xxClientError, clientResponse ->
Mono.error(new RuntimeException("잘못된 TMDB API 요청입니다. 요청 URL 또는 매개변수를 확인하세요."))
)
.onStatus(HttpStatusCode::is5xxServerError, clientResponse ->
Mono.error(new RuntimeException("TMDB 요청 중 서버 오류가 발생했습니다. 잠시 후 다시 시도해주세요."))
)
.bodyToMono(TMDBMovieSearchResponse.class)
.retryWhen(Retry.backoff(2, Duration.ofSeconds(1)))
.block();
if (response == null || response.getResults().isEmpty()) {
continue;
}
List<Movie> movies = response.getResults().stream()
.map(movie -> {
try {
AdminMovieTMDBDetailResponse movieDetail = TMDBService.getMovieInfoById(movie.getId());
return createMovie(movieDetail);
} catch (MovieAlreadyExistsException e) {
System.out.println("이미 등록된 영화입니다: " + movie.getId());
return null;
} catch (Exception e) {
System.out.println("영화 저장 중 오류 발생: " + e.getMessage());
e.printStackTrace();
return null;
}
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
if (!movies.isEmpty()) {
movieRepository.saveAll(movies);
movieAddCount += movies.size();
}
try {
Thread.sleep(25);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.out.println("요청 지연 중 오류 발생: " + e.getMessage());
}
}
}
return AdminMovieBaseAddResponse.builder()
.movieAddCount(movieAddCount)
.build();
}여기서 핵심은 TMDB API는 무료로 이용 가능하나 API 요청 제한이 존재하기 때문에 Thread.sleep으로 처리하여 에러 반환을 방지하였다.
추가적으로 API 에러 발생 시 재시도 정책을 적용하였으며, 실패 시 Log 출력을 통해 에러를 확인할 수 있게 작성하였다.
영화 데이터 예외 처리 🧑🏻💻
그리고나서 각 영화 데이터를 받아온 뒤에는 별도의 가공 작업을 진행했다.
만약 필드에 존재하지 않거나 (empty, null) 인 필드의 값들은 별도로 DB에 저장하기 전에 N/A라고 별도 표기했다.
배우의 정보가 누락되어 있거나 국가코드 및 심의 등급 그리고 예고편 링크가 존재하지 않으면 전부 N/A 처리로 통일성 있게 값을 대체했다.
// 데이터 저장 코드
return ...
.youtube(video.orElse("N/A"))
//...다양한 API 병렬 처리 적용 ✅
이제 필터링과 별도의 가공도 해줘야할뿐더러, 추가적으로 각각 다양한 필드의 데이터
(배우 정보, 배우 이미지, 스틸컷 등)들은 TMDB API에 별도로 각각 요청을 해야한다.
공식 문서가 있으니 참고 하면 좋을듯 싶다.
TMDB API 공식 문서
내가 작성한 영화 데이터 생성 FLOW를 살펴보자.
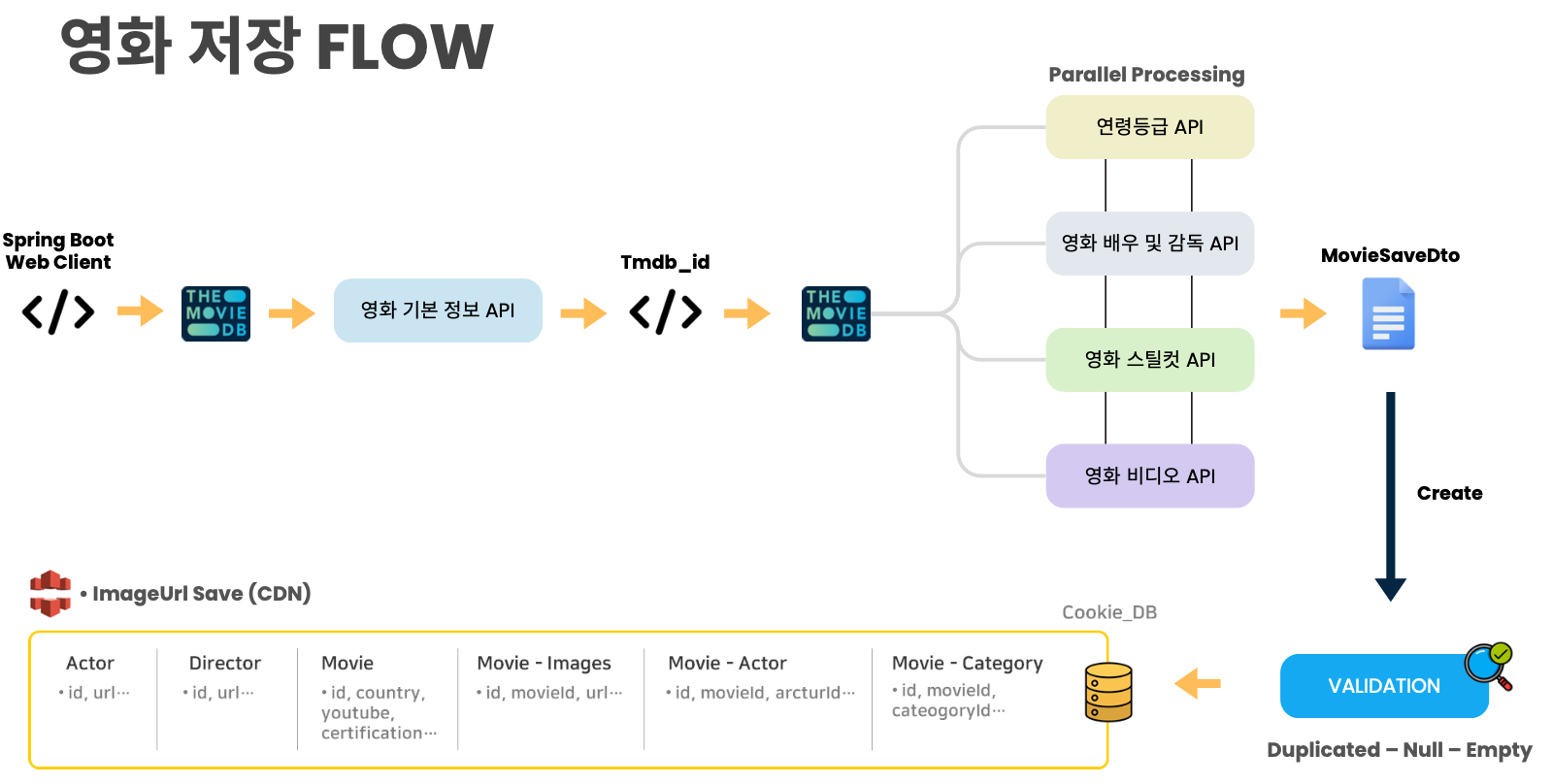
해당 FLOW 처럼 TMDB 고유 Id를 바탕으로 필요한 정보를 받으려면 위처럼 별도 API를 쏴줘야한다.
그래서 동기적으로 처리하는 것 보다는 병렬적으로 처리하여 각 API를 동시에 요청해서 받아오는 작업이 필수였다.
배우 API 받고, 감독 API 받고... 이러면 대량의 영화 데이터를 저장 할 때 반드시 병목현상이 발생할 것을 예방하기 위함이다.
@Transactional(readOnly = true)
public AdminMovieTMDBDetailResponse convertMovieData(Long movieId) {
String movieInfoUrl = createMovieDetailUrl(movieId);
String creditsUrl = createMovieAboutUrl(movieId, "credits");
String imagesUrl = createMovieImagesUrl(movieId);
String videoUrl = createMovieAboutUrl(movieId, "videos");
String certificationUrl = createMovieCertificationUrl(movieId);
CompletableFuture<TMDBMovieDetailResponse> detailFuture =
CompletableFuture.supplyAsync(() -> getMovieDetail(movieInfoUrl));
CompletableFuture<List<TMDBCasts>> actorsFuture =
CompletableFuture.supplyAsync(() -> getMovieActors(creditsUrl));
CompletableFuture<Optional<TMDBCasts>> directorFuture =
CompletableFuture.supplyAsync(() -> getMovieDirector(creditsUrl));
CompletableFuture<List<String>> imagesFuture =
CompletableFuture.supplyAsync(() -> getMovieImages(imagesUrl));
CompletableFuture<Optional<String>> videoFuture =
CompletableFuture.supplyAsync(() -> getMovieVideos(videoUrl));
CompletableFuture<String> certificationFuture =
CompletableFuture.supplyAsync(() -> getCertification(certificationUrl));
CompletableFuture.allOf(detailFuture, actorsFuture, directorFuture, imagesFuture, videoFuture, certificationFuture).join();
TMDBMovieDetailResponse detail = detailFuture.join();
List<TMDBCasts> actors = actorsFuture.join();
Optional<TMDBCasts> director = directorFuture.join();
List<String> images = imagesFuture.join();
Optional<String> video = videoFuture.join();
String certification = certificationFuture.join();
// 반환하기 위한 return 코드..위 코드처럼 CompletableFuture를 사용하여 비동기 처리를하고, 결과를 기다렸다가 한 번에 값을 return하는 형태로 코드를 작성하였다.
4️⃣ 영화 데이터 DB에 저장하기
영화 데이터를 필터링하고 가공하고 필요한 데이터로 준비를 다 마치면
비로소 우리 DB에 저장할 수 있는 정상적인 영화 Data로 거듭나게 된다.
아래 코드를 통해 이제 우리 DB에 정상적으로 영화 데이터가 저장된다.
각 image를 담고있는 url은 AWS Cloud Front를 사용하여 CDN을 적용하였다.
@Transactional
public Movie createMovie(AdminMovieTMDBDetailResponse movie) {
Optional<Movie> findMovie = movieRepository.findMovieByTMDBMovieId(movie.getMovieId());
if (findMovie.isPresent()) {
throw new MovieAlreadyExistsException("이미 해당 영화 정보가 있습니다");
}
Director directorData = createDirector(movie);
Country countryData = createCountry(movie);
Movie movieData = createMovieData(movie, directorData, countryData);
movieRepository.save(movieData);
List<MovieImage> movieImageDates = createMovieImages(movie, movieData);
movieImageRepository.saveAll(movieImageDates);
List<Actor> actorDates = createActors(movie);
List<MovieActor> movieActors = createMovieActors(movieData, actorDates);
movieActorRepository.saveAll(movieActors);
List<Category> categories = createCategories(movie);
List<MovieCategory> movieCategoryDates = createMovieCategories(movieData, categories);
movieCategoryRepository.saveAll(movieCategoryDates);
return movieData;
}

그러면 이제 정상적으로 movie Table에 각 정보가 정상적으로 잘 저장된다.
movie뿐만 아니라, 배우, 감독, 배우 - 영화, 감독 - 영화 등등 각 엔티티에 맞게 데이터를 알맞게 저장하는 것을 완료했다.
5️⃣ 영화 데이터 최신화 전략
이제 영화 데이터를 잘 정했으니 끝인가? 아니다.
자동으로 영화 데이터를 최신화해야 서비스 제공에 문제가 없어야한다고 생각했다.
Scheduler를 통해 매일 새벽 시간대에 전일 기준으로 인기순 TOP5를 저장한다.
추가적으로 주간 박스오피스 서비스를 제공하기 위해 매 주마다 작주의 인기 영화 TOP 10을 제공한다.
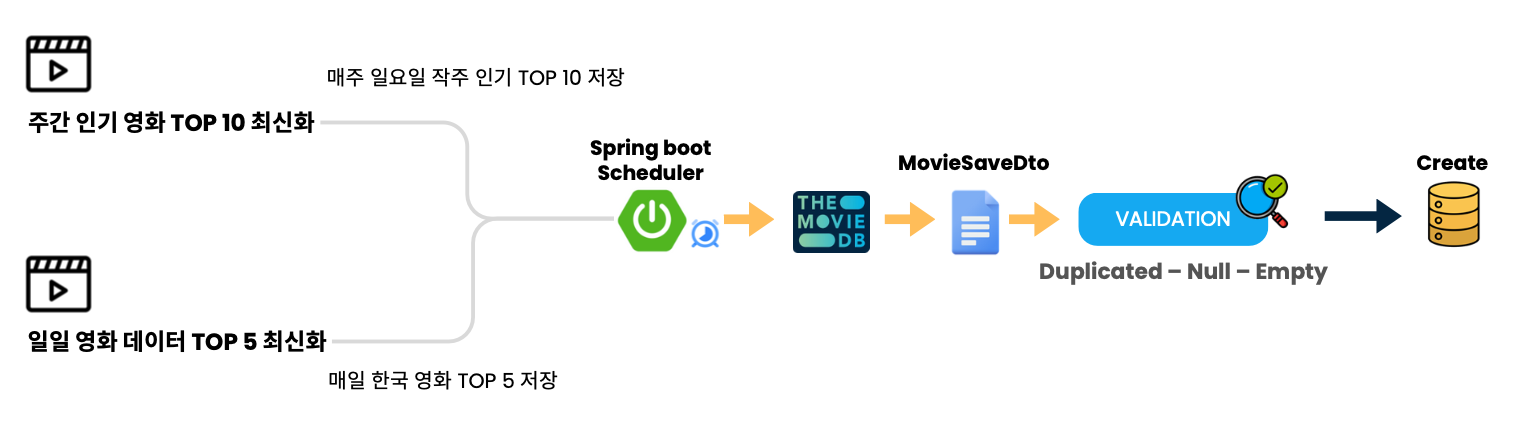
FLOW처럼 한국 영화, 외국 영화를 최신화 시켜줌으로서 서비스의 품질을 상승 시켰다.
물론, 개발 공수도 최소화 된 것은 덤이다. 🥕
// 일일 영화 최신화
@Scheduled(cron = "0 0 1 * * *")
public void createDailyMovies() {
try {
movieLatestService.createDailyMovies();
// 일일 개봉 영화 데이터 조회 및 저장 로직
log.info("일일 인기 영화 저장 및 배치 완료!");
} catch (Exception e) {
log.error("일일 인기 영화 최신화 중 오류 발생: {}", e.getMessage());
}
}
// 주간 영화 인기순위 최신화
@Scheduled(cron = "0 0 3 * * SUN")
public void updateWeeklyMovies() {
try {
movieLatestService.createMoviesWeeklyRanking();
// 주간 TOP 10 영화 데이터 조회 및 주간 박스오피스 저장 로직
log.info("주간 인기 영화 저장 및 배치 완료!");
} catch (Exception e) {
log.error("주간 인기 영화 최신화 중 오류 발생: {}", e.getMessage());
}
}
}6️⃣ 마무리 🌱
영화 데이터는 특히 너무 방대하고 다양하기 때문에 각 데이터들을 알맞은 곳에 저장하는게 매우 중요하다고 느꼈다.
특히 엔티티간의 연관관계를 구성할 때나 DB를 설계할 때 어떻게 저장하고 관리할 것인지에 대한 경험이 정말 좋았던거같다.
나중에는 이 내용과 관련하여 추후 포스팅을 할 수 있도록 하겠다 😎
