Selection Problem
- 입력 : 리스트에 n개의 수와 1과 n 사이의 자연수 k가 주어진다
- 출력 : k번째로 작은 수 를 찾아 리턴한다
- 목적 : 비교횟수를 되도록 줄인다
상한과 하한
-
상한(upper bound) : 어떠한 값 x가 있고 집합 A의 모든 원소보다 크거나 같을 때, x를 상계라고 한다. 그리고 이러한 상계들의 집합에서 최소원소를 상한이라고 한다.
알고리즘에서 수행시간의 상한은 최악의 경우에서 문제를 수행하는데 걸리는 시간을 의미.
즉, 항상 해당 시간 이하로 답을 찾을 수 있다는 것을 내포. 우리가 말하는 점근적 표기법에서 표기법이 상한을 나타내는데 사용**된다.
-
하한(lower bound) : 어떠한 값 x가 있고 집합 A의 모든 원소보다 작거나 같을 때, x를 상계라고 한다. 그리고 이러한 하계들의 집합에서 최대원소를 하한이라고 한다.
알고리즘에서 수행시간의 하한은 최선의 경우에서 문제를 수행하는데 걸리는 시간을 의미.
즉, 답을 찾기 위해선 해당 시간이 필수적이라는 것을 내포. 점근적 표기법에서 로 하한을 나타낸다.
상한과 하한 값이 같을 때, 로 표시하고, 이는 알고리즘이 필요한 만큼만을 비교한다는 뜻이다. **이러한 알고리즘은 최적 알고리즘**이라고 부른다.
가장 큰 수 찾기 (k =n)
가장 단순한 selection 문제
def select(A):
current_max = A[0]
for i in range(1, len(A)):
if current_max < A[i]:
current_max = A[i]
return current_max- 최악의 비교 횟수 : 번 ⇒ 상한**
- 상한의 비교 횟수보다 더 적게 비교해서 최대 값을 찾을 수 있는가? ⇒ 없다. 번이 필요한 경우가 존재! ⇒ 하한
- 상한 == 하한 → 최적 알고리즘!
가장 작은 수와 가장 큰 수 찾기 (k = 1, k = n)
1. 알고리즘1
- 가장 작은 수를 번의 비교로 찾기
- 가장 작은 수를 제외하고, 나머지 (n - 1)개 중 다시 번의 비교로 가장 큰 수 찾기
→ 두 수를 찾기 위한 최대 비교 횟수 ⇒ 번 ⇒ 상한
위의 횟수보다 더 적게 비교 가능할까?
가장 작은 수를 찾을 때, 비교한 결과를 이용해서 가장 큰 수를 찾을 수 있지 않을까?
2. 알고리즘2
-
이 짝수라고 가정
-
가장 작은 수를 먼저 찾는 데, 토너먼트식으로 번 비교하여 찾음.
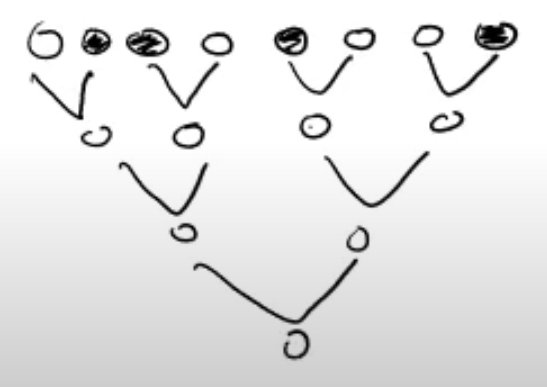
- 토너먼트의 1라운드에서 탈락한 수 에서 가장 큰 수가 존재한다!
-
1라운드에서 탈락한 수는 개
-
이 탈락한 수 중에서 가장 큰 값이 전체에서 가장 큰 값 → 이를 위해 번의 비교 필요**.
-
전체 비교 횟수 =
가장 작은 수 와 두 번째로 작은 수 찾기 (k = 1, k = 2)
위의 토너먼트 비교를 이용해서 생각해보자.
가장 작은 수를 찾았다면, 2번째로 작은 수는 어디에 있을까?
- 가장 작은 수가 토너먼트 우승자라면, 2번째로 작은 수는 반드시 제일 작은 수를 만나 경기를 벌인다.
- 그럼, 가장 작은 수를 만나 떨어진 값들 중에 있다.
- 후보의 개수 = 토너먼트 round의 수 - 1
- 만약 라고 가정하면, 후보의 개수는 개 ⇒ 이진트리의 높이와 같기 때문에
- 결국, 하한 비교 횟수 =
임의의 k번째로 작은 수 찾기 (가장 일반적인 selection 문제)
- k = 1이면 가장 작은 값 찾기와 동일
- k = n이면 가장 큰 값 찾기와 동일
- k = n // 2이면 중간 값(median) 찾는 문제
입력 : n개의 수와 함께 k가 함께 주어짐
아이디어 : 앞의 문제들 처럼 찾고 있는 수가 존재할 범위를 줄여나가기
ex) n개 중에서 k번째 작은 수가 있음 → k번째 작은 수가 있을 범위를 반으로 줄임 → 해당 범위를 다시 반으로 줄여 n / 4개 → 마지막 1개가 남을 때까지 반복 → 해당 값이 찾는 값!
-
n개의 수 중에 k번째 작은 수를 찾는데 필요한 비교 횟수(상한)
-
추가 작업을 위해 사용한 비교 횟수
-
추가 작업이 번의 비교 필요하다면, 이 성립
-
이라고 가정, 점화식을 풀어보자.**
-
1. Quick Select 알고리즘
위의 아디이어를 단순하게 구현한 알고리즘
- 현재의 후보 중에서 임의로 수 하나 선택, 이를 pivot(p)라고 표기
- 후보 수를 하나씩 p와 비교하여 p보다 작은 수는 집합 A에, 같은 수는 집합 M에, 큰 수는 집합 B에 분류
- 라면 k번째로 작은 수는 A에 있다! Why? p보다 작은 수가 k개가 넘기때문
- 라면, k번째로 작은 수는 B에 있다. ⇒ B에서 번째로 작은 수**를 찾으면 됨.
- 위의 경우가 아니라면 k번째로 작은 수는 M에 있으며, 그 값은 바로 p.
def quick_select(L, k):
p = L[0]
A = [] # p보다 작은 수
M = [] # p와 같은 수
B = [] # p보다 큰 수
for i in L:
if i < p:
A.append(i)
elif i > p:
B.append(i)
else:
M.append(i)
if len(A) > k: # k번째로 작은 수가 A에 있을 경우
return quick_select(A, k)
elif len(A) + len(M) < k: # k번째로 작은 수가 B에 있을 경우
return quick_select(B, k - len(A) - len(M))
else:
return p- 수행시간
- 최상의 경우를 보장하기 위해선 pivot 선택이 중요.
- 하지만 좋은 pivot을 선택하는 것은 꽤 복잡하고 추가시간 필요
- 대신, quick_select는 평균 수행시간()으로 매우 훌륭
2. Median-of-Medians 알고리즘
quick_select의 아이디어에서 발전한 알고리즘
강제로 A와 B의 크기를 L의 이상, 이하가 되도록 한다. → pivot을 공들여 선택!
- pivot을 고르는데 비교 횟수 :
- 중간 값을 기준으로 정렬하는데 비교 횟수 :
- 묶음 당 수 :
- 한 단계 내려갈 때마다 이 되며, 총 번 재귀
- 결국, 한 단계 내려갈 때마다 번의 비교, 만약 이라면 ⇒ quick select 보다 더 효율 좋다
MoM(L, k)
-
L의 수를 5개씩 묶음 → 개의 묶음이 존재
-
각 묶음에 대해 중간값을 찾음 (6번 비교로 가능) ⇒ 총 번 비교
- 중간 값보다 작은 수 2개 - 중간 값 - 중간 값보다 큰 수 2개 순서로 정렬
-
묶음 별 중간 값들을 모아(개), 그 값의 중간 값들을 찾음 (median of group medians)
- 모인 개에 대해 다시 재귀호출(
MoM(medians, len(medians) // 2)) ⇒ - 번 호출
그 중간 값을 라고 하면,
- 모인 개에 대해 다시 재귀호출(
-
pivot = ,
quick_select(L, pivot)호출 -
만약 가 k번째 수가 아니라면 혹은 에 대해
MoM을 재귀호출( or ), 아니면 return
수행 시간
, 이므로
- 증명
,
⇒ ,
-
점화식 귀납적 증명
(단, 임을 귀납적으로 증명해보자.
-
일때, ⇒ 성립!**
-
일때 이 성립한다고 가정**
-
일 때,**
⇒
-
def find_median_five(A):
"""
4개의 값을 토너먼트 형식으로 비교하여 최댓값을 구한다. 이 값은 중앙값이 될 수 없다. (이 과정에서 3번의 비교가 필요하다.)
위에서 사용되지 않은 나머지 한 값을 1.에서의 최댓값 자리에 넣고, 4개의 값을 토너먼트 형식으로 비교하여 최댓값을 구한다.
이 값은 중앙값이 될 수 없다. (이 과정에서 2번의 비교가 필요하다.)
남은 세 숫자 중 최댓값을 구한다. 이 값이 중앙값이다. (이 과정에서 1번의 비교가 필요하다.)
총 6번의 비교가 필요하다
"""
a1, a2, b1, b2 = 0, 0, 0, 0
if A[0] > A[1]:
b1 = A[0]
a1 = A[1]
else:
b1 = A[1]
a1 = A[0]
if A[2] > A[3]:
b2 = A[2]
a2 = A[3]
else:
b2 = A[3]
a2 = A[2]
if b1 > b2:
if A[4] > a1:
b1 = A[4]
else:
b1 = a1
a1 = A[4]
else:
if A[4] > a2:
b2 = A[4]
else:
b2 = a1
a2 = A[4]
if b1 > b2:
if b2 > a1:
return b2
return a1
if b1 > a2:
return a1
return a2
def MoM(L, k):
if len(L) == 1:
return L[0]
A, B, M, medians = [], [], [], []
i = 0
while i + 4 < len(L):
medians.append(find_median_five(L[i : i + 5]))
i += 5
if i < len(L) <= i + 4:
# 4개 이하의 리스트에서 중앙값 뽑기
pass
mom = MoM(medians, len(medians) // 2)
for v in L:
if v < mom:
A.append(v)
elif v > mom:
B.append(v)
else: M.append(v)
if len(A) < k:
return MoM(A, k)
elif len(A) + len(M) < k:
return MoM(B, k - len(A) - len(M))
return mom