Abstract
fine-grained 수준의 few-shot 이미지 분류는 딥러닝에서 인기 있는 연구 분야이다. 주요 목표는 제한된 수의 샘플을 사용하여 더 넓은 범주 내의 하위 범주를 식별하는 것이다. fine-grained 이미지의 클래스 내 변동성이 크고 클래스 간 변동성이 낮다는 점에서 분류 성능을 저해한다. 이를 극복하기 위해, 우리는 양방향 특징 재구성에 기반한 fine-grained few-shot 이미지 분류 알고리즘을 제안한다. 이 알고리즘은 channel attention과 window-based self-attention을 결합하여 이미지의 국부적 세부 정보를 포착하는 혼합 잔차 어텐션 블록(MRA Block)을 도입한다. 또한, 이중 재구성 특징 융합(DRFF) 모듈을 설계하여 계층 간의 서로 다른 규모의 특징을 통합함으로써 클래스 간 및 클래스 내 변이에 대한 모델의 적응성을 향상시킨다. 유사도 측정을 위해 코사인 유사도 네트워크를 사용하여 정밀한 예측을 가능하게 한다. 실험 결과, 제안된 방법은 CUB-200-2011, Stanford Cars, 그리고 Stanford Dogs 데이터셋에서 각각 96.99%, 98.53%, 89.78%의 분류 정확도를 달성하였으며, 이는 fine-grained 작업에서 제안 방법의 유효성을 확인시켜 준다.
Introduction
최근 몇 년 동안, 딥러닝을 이용한 이미지 작업에서 상당한 진전이 이루어졌다. 이는 풍부한 주석이 달린 데이터를 통해 얻어진 풍부한 이미지 표현을 활용하여 분류 성능을 향상시킨 결과이다. 그러나 모든 상황에서 대규모의 학습 데이터를 확보할 수 있는 것은 아니다. 예를 들어, 멸종위기 동물 인식, 군사 무기 식별, 희귀 질병 탐지와 같은 시나리오에서는 종종 제한된 샘플 수만 존재한다. 더욱이, 이러한 시나리오에서는 클래스 내 차이가 상당히 크기 때문에 기존 딥러닝 방법은 인식 정확도에서 두드러진 한계를 보인다. 따라서 이러한 세밀한 차이를 few-shot 학습 접근법으로 해결할 필요가 있다.
fine-grained 이미지 분류는 이미지 분류의 중요한 하위 분야로, 기본 범주를 구별하는 것뿐만 아니라 하위 범주를 정밀하게 나누는 것이 요구된다. 따라서 도전 과제는 적은 수의 이미지로부터 더 다양하고 판별력 있는 특징 표현을 학습하는 데 있다.
이러한 문제를 해결하기 위해, 정밀한 분류에 기여하는 판별력 있는 국부 영역 특징을 깊이 있게 탐구하는 것이 중요하다. 예를 들어, Zhu는 다중 어텐션 메커니즘에 기반한 meta learning 방법을 세밀 인식에 적용하여, 모델이 어텐션 메커니즘을 통해 이미지 내 판별 영역에 적응적으로 집중하도록 하여 분류 정확도를 향상시켰다.
Wertheimer은 세밀 분류 문제를 잠재 공간에서의 특징 재구성 문제로 정의하여, support set과 query set의 특징을 서로 다른 방식으로 재구성함으로써 세밀 이미지 특성의 영향을 줄였다. FRN(Feature Reconstruction Network)은 prototype networks에 비해 더 세부적인 특징 영역을 학습하지만, “birds” 데이터셋에 적용했을 때, 동일한 범주 내 두 샘플 간의 의미적 정보 불일치가 여전히 나타났다. 이는 세밀 데이터셋의 클래스 내 차이가 크고 클래스 간 차이가 작아, 촬영 각도, 조명 조건 등 개별적 요인에 의해 FRN이 일관된 의미 정보를 추출하는 데 불안정성을 보이기 때문이다.
Zhang은 최적 블록 매칭 비용을 계산하여 support set과 query set 이미지 간의 유사성을 평가하는 지구 이동 거리(EMD) 기반 측정 방법을 제안했다.
Li은 BSNet(Bi-Similarity Network)이라는 알고리즘을 제안하여, 서로 다른 특징 기반의 두 유사도 측정을 학습·통합하여 보다 정확한 특징 맵을 생성하고, 판별력 있는 특징 표현을 추출함으로써 유사도 편향을 줄이고 모델의 일반화 능력을 크게 향상시켰다.
EGNN은 그래프 합성곱 네트워크 기반 few-shot 학습 방법으로, 클래스 내 유사도와 클래스 간 차이를 활용하여 edge 라벨을 반복적으로 업데이트하고 이를 통해 node 라벨을 예측한다. 이 모델은 support set과 query set의 특징을 전이적 방식으로 동시에 학습하여 분류 성능을 최적화하며, 다른 범주로의 전이에도 적합하고, 전이 후 파라미터 재학습이 필요 없다.
Tang은 deep navigator를 사용해 이미지에서 판별 영역을 생성한 후 이를 기반으로 그래프를 구성하고, message passing을 통해 집계하여 분류 결과를 얻는 PMRC 프레임워크를 제안했다.
Chang은 여러 다른 데이터셋을 공동 학습하여 데이터셋 간 부정적 전이를 줄이고 긍정적 전이를 촉진하는 박식 FGVC 모델을 제안했다.
Lyu은 계층적 개념 임베딩(hierarchical concept embedding)을 갖춘 시암 트랜스포머(Siamese transformer, STrHCE)를 제시했으며, 이는 동일한 설정을 공유하는 두 트랜스포머 서브네트워크로 구성되고, 여러 개념 수준의 계층적 의미 정보를 제공받아 세밀 이미지 임베딩을 수행한다.
Wu은 더 판별력 있는 특징을 탐구하도록 돕는 특징 자기-재구성 메커니즘을 도입했으나, 초기 특징 품질에 대한 높은 의존성으로 인해 근본적인 특징을 충분히 표현하지 못하는 문제가 남아있다.
fine-grained few-shot 분류 알고리즘은 크게 meta-learning 기반과 metric-learning 기반 방법으로 나눌 수 있다. meta-learning 기반 방법은 기존 지식과 경험을 활용해 모델이 새로운 분류 작업에 빠르게 적응하도록 한다. 예를 들어, Finn은 각 작업에 민감한 네트워크 파라미터를 찾아 이를 미세 조정함으로써 빠른 수렴을 달성하는 MAML (Model-Agnostic Meta-Learning) 방법을 제안했다. Rusu은 저차원 잠재 공간을 도입해 그 안에서 내부 루프 파라미터를 업데이트하는 LEO few-shot 학습 알고리즘을 제안했다.
반면 metric-learning 기반 방법은 특징 임베딩 최적화에 집중하여 특징 벡터의 공간적 분포를 개선한다. 이러한 방법은 샘플 간 절대적인 특징 표현보다 상대적인 관계를 강조하며, 적은 수의 샘플로도 좋은 파라미터 분포를 얻을 수 있게 한다. fine-grained few-shot 분류에서는 범주 간 차이가 미묘하므로 샘플 간 유사도를 정확하게 측정하는 것이 핵심 과제다. 그러나 많은 기존 메트릭 기반 방법들은 하나의 유사도 계산 방식에 의존하며, 이는 제한된 샘플 상황에서 유사도 계산의 편향을 초래할 수 있다. 또한 CNN은 국부적 세부 정보를 충분히 포착하거나 크기 간 특징을 융합하는 데 한계가 있어 더 판별력 있는 세밀 특징을 깊게 탐색하기 어렵다.
이러한 문제를 해결하기 위해, 본 논문에서는 특징 이중 재구성(feature dual reconstruction)에 기반한 fine-grained few-shot 이미지 분류 방법을 제시한다. 이는 metric learning을 활용해 fine-grained few-shot 이미지 분류 문제를 해결하는 접근으로, 본 논문의 주요 기여는 다음과 같다.
① MRA 블록 제안: Mixed Attention Block(MAB)과 Overlapping Cross-Attention Block(OCAB)을 설계하고, 이를 직렬로 연결하여 MRA 블록을 구성한다. channel attention과 window-based self-attention 메커니즘을 통합함으로써 윈도우 간 연결성과 정보 집약 능력을 향상시켰다. 여러 residual 메커니즘과 결합하여 주·보조 경로의 특징을 융합해 데이터 분포를 더 잘 이해하고 국부 영역 변화에 정확히 대응하도록 했다.
② DRFF 모듈 제안: support set으로 query set을 재구성하여 클래스 간 변이를 증가시키고, query set으로 support set을 재구성하여 클래스 내 변이를 줄이는 상호 재구성 전략을 도입했다. 또한 transformer encoder와 attention feature fusion model(AFFM)을 결합해 범주 간·범주 내 변이에 동적으로 적응하도록 하여 다양한 크기에서 핵심 정보를 포착하는 능력을 향상시켰다.
③ 세 가지 공개 fine-grained 데이터셋에서 심층적인 결손 분석과 평가를 수행하여 제안 방법이 높은 성능과 강건성을 보임을 검증했다.
Methods
ⓐ Algorithm Structure
본 연구에서는 fine-grained few-shot 분류 문제의 특성에 대응하여, 특징 맵의 유사도를 정확하게 측정하고 보다 판별력 있는 특징 표현을 학습하는 것을 목표로, 특징 이중 재구성(feature dual reconstruction) 기반의 세밀 이미지 분류 방법을 제안한다.
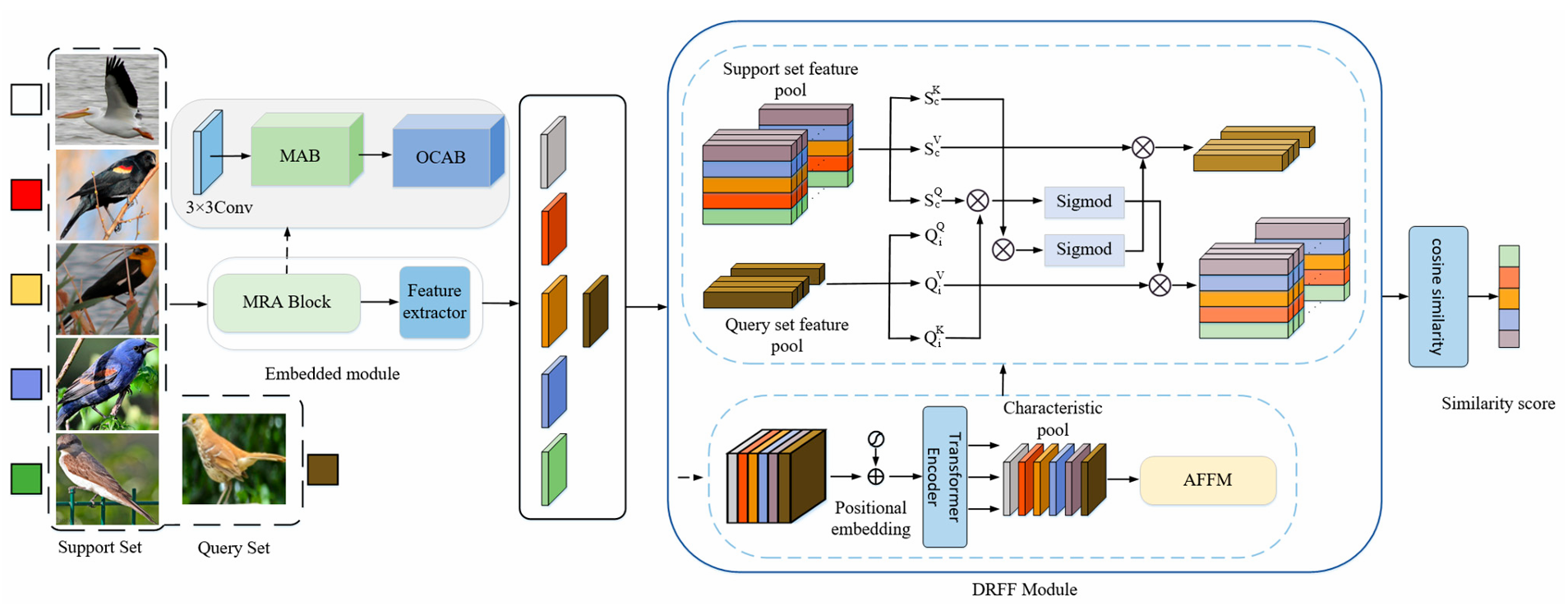
우리 모델은 네 개의 주요 모듈로 구성된다.
① Embedding Module
입력 이미지의 심층 합성곱 특징을 추출한다. MRA 블록과 특징 추출기로 이루어지며, 특징 추출기는 CNN이나 ResNet이 될 수 있다.
② Dual Reconstruction Feature Fusion(DRFF)
각 이미지의 합성곱 특징을 self-attention 메커니즘으로 재구성하고, AFFM(Attention Feature Fusion Module)으로 정제하여 더 표현력 있는 특징을 생성한다.
③ Mutual Feature Reconstruction Module
support sample과 query sample의 특징을 양방향으로 재구성한다. 기존의 단방향 재구성은 클래스 간 변이만 강화하는 반면, 양방향 재구성은 클래스 내 변이를 줄이는 추가 능력을 제공한다.
④ Cosine Similarity Measurement Module
원본 특징과 재구성된 특징 간의 거리를 계산한다. 이 두 거리의 가중합을 기반으로 query set의 샘플의 분류를 수행한다.
새로운 작업이 주어졌을 때의 처리 흐름은 다음과 같다. support set 이미지와 query set 이미지를 먼저 임베딩 모듈에 입력하여 이미지 특징을 추출한다. 임베딩 모듈 내부에서는 3×3 합성곱 층, 혼합 어텐션 블록(MAB), 겹침 교차 어텐션 블록(OCAB)이 결합되어 입력 이미지로부터 특징을 더 효과적으로 추출한다. 이후 DRFF 모듈을 통해 특징을 재구성하면서 다중 스케일 특징에 대한 모델의 인식 능력을 강화한다. 마지막으로, support set과 query set의 재구성된 특징 간 코사인 유사도를 계산하여 최종 유사도 점수를 얻는다.
❓어텐션의 다양한 변형
① self-attention
입력 특징을 선형변환해 Q, K, V를 만든 뒤, Q·K의 내적을 스케일해 Softmax로 어텐션 맵를 얻고, 그 가중치로 V를 가중합한다.
② 윈도우 기반 self-attention
특징맵을 여러 로컬 윈도우로 나눠 각 윈도우 안에서만 self-attention을 계산해 비용을 줄이면서 국소 상호작용을 잡는다.
③ channel attention
평균 풀링(GAP)/최대 풀링(GMP)으로 채널별 요약을 만든 뒤 채널 중요도를 구해 중요한 채널을 증폭한다.
④ cross-attention
한 집합의 Q가 다른 집합의 K,V를 보며 정보를 가져온다. overlapping cross-attention은 창 경계가 겹치게 해서 윈도우 사이 정보 흐름을 늘린 변형이다.
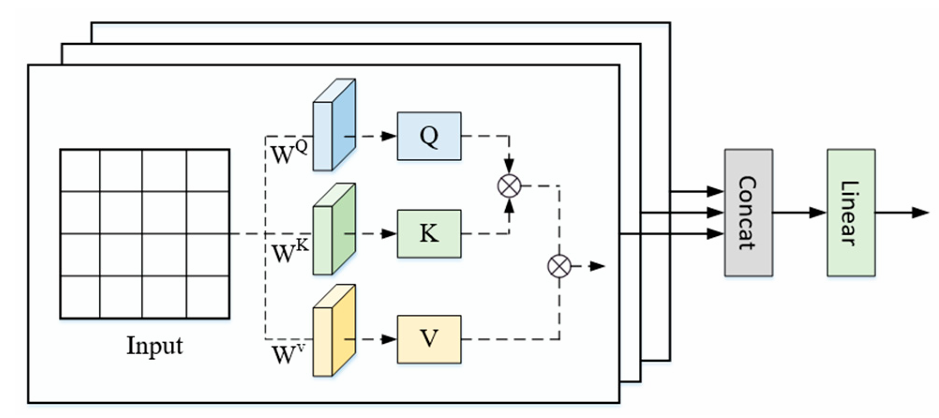
⑤ multi-head attention
multi-head은 Q,K,V를 여러 헤드로 쪼개 서로 다른 투영에서 각각 어텐션을 계산하고, 마지막에 결과를 이어붙여 합친다. 동시에 여러 관계를 잡고, 계산이 안정적이고 표현력이 커진다.
ⓑ Embedding Module
본 논문에서의 임베딩 모듈은 MRA 블록과 특징 추출기로 구성된다.
MRA 블록은 3×3 합성곱 층, MAB, OCAB로 이루어진다.
ⓑ-1 MRA Block
MRA 블록은 세밀한 특징 추출과 어텐션 메커니즘 통합을 통해 이미지 특징의 표현 능력을 향상시킨다. 이 블록의 내부 구조는 다음 세 가지 주요 구성 요소로 이루어진다.
① 3×3 합성곱 층 – 초기 특징 추출을 수행한다.
② Mixed Attention Block(MAB) – channel attention과 multi-head self-attention을 결합하여 특징의 표현력을 강화한다.
③ Overlapping Cross-Attention Block(OCAB) – 두 개의 병렬 겹침 교차 어텐션 레이어(OCA)로 구성되며, 서로 다른 영역 간의 정보 교환을 촉진한다.
이 모듈에서 channel attention은 이미지에서 중요한 채널을 식별하고, 이 채널들에 더 높은 가중치를 부여함으로써 중요한 특징에 대한 모델의 반응을 강화한다. 채널 어텐션의 구조는 다음과 같다.

multi-head self-attention은 모델이 여러 subspace에서 입력을 동시에 포착할 수 있도록 하며, 각 head가 서로 다른 특징의 중요도를 학습하여 모델의 특징 표현을 더욱 풍부하게 만든다. multi-head self-attention의 구조는 다음과 같다.
ⓑ-2 Mixed Attention Block
네트워크의 표현 능력을 향상시키기 위해, 기존 MAB 블록에 channel attention 기반의 합성곱 블록을 추가하였다. 합성곱은 MAB가 더 나은 시각 표현을 얻도록 도와줄 수 있기 때문이다.
Window-based Multi-Head Self-Attention(W-MSA) 모듈과 Channel Attention Block(CAB)을 기본 MAB 블록 내부에 직렬로 삽입하였다.
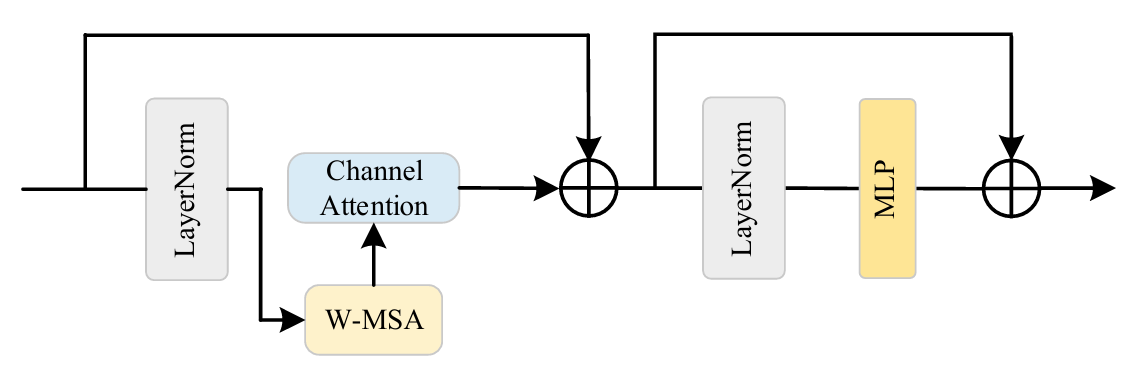
MAB의 입력 특징 X에 대한 전체 연산 과정은 다음과 같다. 이는 multi-head self-attention 모듈과 channel-attention block 간의 시각 표현 충돌을 피하기 위함이다.
① 레이어 정규화(LayerNorm)
입력 특징 X를 정규화한 결과가 XN이다.
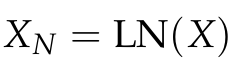
② XN은 W-MSA 모듈로 처리된다. 이 모듈은 특징 맵을 로컬 윈도우로 나눈 뒤, 각 윈도우 내에서 독립적으로 milti-head self-attention을 적용하여 국소적 의존성을 포착한다.
③ 채널 어텐션 적용
W-MSA의 출력에 채널 어텐션 블록(CAB)을 적용하여, 중요한 채널의 특징을 강조한다. 그리고 W-MSA의 원 출력과 채널 어텐션 결과를 더해 최종 MAB의 중간 출력 XM을 얻는다.
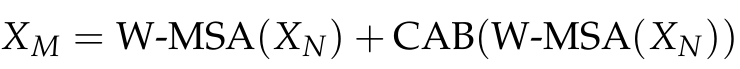
④ MLP와 잔차 연결(residual connection)
XM을 다시 정규화한 뒤, 다층 퍼셉트론(MLP)에 통과시킨다. MLP는 두 개의 완전 연결층과 GELU 활성화 함수를 포함하며, 특징을 더욱 정교하게 다듬는다. 마지막으로 MLP의 출력과 원래의 XM을 더하여 정보 흐름을 유지하고, 복잡한 특징 학습 능력을 향상시킨다.
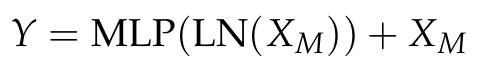
Channel Attention은 각 채널의 중요도를 계산하여 가중치를 부여한다. 먼저, 입력 특징 X에 대해 전역 평균 풀링(GAP)과 전역 최대 풀링(GMP)을 적용해 각각 전역 및 국소 특징을 추출한다. 두 결과를 학습 가능한 가중치 W1과 W2로 곱하고, 시그모이드 함수 σ로 정규화하여 어텐션 스코어를 얻는다.
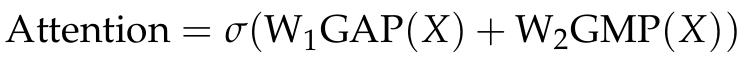
window-based self-attention 메커니즘은 로컬 윈도우 내부의 정보 상호작용뿐만 아니라, 어텐션 메커니즘을 통해 서로 다른 위치 정보에 대한 적응형 가중치를 부여함으로써 모델의 표현 능력을 더욱 향상시킨다. 입력 특징의 크기가 H×W×C일 때, 이를 여러 개의 로컬 윈도우로 분할한다. 이 연산은 self-attention 메커니즘의 범위를 로컬 윈도우로 제한하여 계산 효율성을 높이고, 계산 복잡도를 줄인다. 그 다음, 각 로컬 윈도우 내에서 self-attention을 계산한다. 각 윈도우의 특징에 대해 완전 연결층을 이용한 선형 매핑을 수행하여, 입력 특징을 원래 공간에서 새로운 공간으로 변환하고 쿼리 행렬(Q), 키 행렬(K), 값 행렬(V)를 생성한다. 이후 표준 self-attention 계산을 수행한다.
① 먼저 Q와 K의 내적을 계산한다.
② 그 결과를 Softmax로 정규화하여 어텐션 가중치 행렬을 얻는다.
③ 이 가중치 행렬을 V에 곱해 가중 합을 수행함으로써, 각 위치에 대한 새로운 특징 표현을 생성한다.
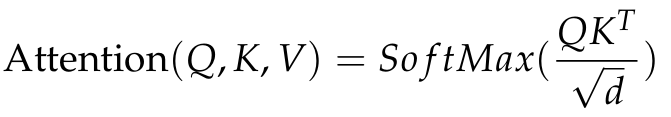
d: 쿼리와 키의 차원
(마지막에 V를 곱해야 완전한 식이 나올 거 같다)
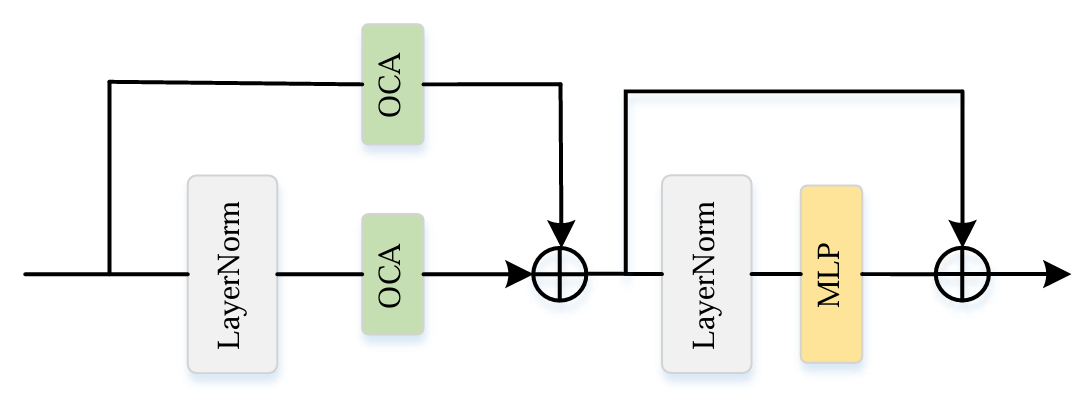
ⓑ-3 Overlapping Cross-Attention Block
윈도우 간 정보 결합을 더 잘 수행하고, 윈도우 간 상호 연결을 강화하기 위해, 본 논문에서는 OCAB을 설계하였다. 이 블록은 전역적 맥락을 이해하면서도 지역적 세부 정보를 유지할 수 있도록, 윈도우 간 직접적인 연결을 수립하여 특징 표현을 향상시킨다.
구조적으로는 표준 Swin Transformer 블록과 유사하며, 두 개의 Overlapping Cross-Attention layers(OCA)와 다층 퍼셉트론(MLP)으로 구성된다.
각 OCA 레이어는 다음과 같이 처리된다. 각 M×M 크기의 윈도우에 대해 쿼리(Q), 키(K), 값(V) 행렬을 계산한 후, Q와 K의 점곱을 계산하여 어텐션 가중치를 얻는다. 그런 다음 이 가중치를 값 행렬 V에 곱하여 가중합된 특징 표현을 생성한다. 이후 multi-head self-attention 메커니즘이 각 윈도우 내부의 특징을 집계하며, 겹침 윈도우 설계를 사용하여 영역 간 특징 통합을 달성한다. 이 설계는 모델이 전역 문맥 정보를 이해하는 동시에 국소 세부 정보를 유지하도록 돕는다.
마지막으로, 두 개의 완전 연결층과 GELU 활성화 함수로 구성된 MLP를 사용하여 집계된 특징을 추가로 처리한다. 어텐션 레이어와 MLP 앞에는 레이어 정규화가 적용되며, 각 완전 연결층 뒤에는 드롭아웃이 사용되어 과적합을 방지한다.
OCA는 더 넓은 영역에서 키와 값을 계산하기 위해 서로 다른 윈도우 크기를 사용하여 입력 특징을 분할한다. 구체적으로, 입력 XQ, XK, XV에 대해, XQ는 M×M 크기의 비겹침(non-overlapping) 윈도우로 분할되고, XK와 XV는 M0×M0 크기의 겹침(overlapping) 윈도우로 확장된다. 여기서 “윈도우로 확장”한다는 것은 인접한 윈도우 사이에 일정한 겹침 영역이 있도록 하는 전략을 채택한다는 의미다. M이 증가함에 따라 M0는 겹치게 된다. 이러한 겹침 설계는 윈도우 경계에서 정보 흐름을 가능하게 하여, 윈도우 간 정보 통합을 달성한다. M0의 계산 공식은 다음과 같다.
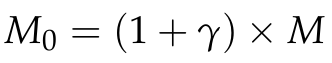
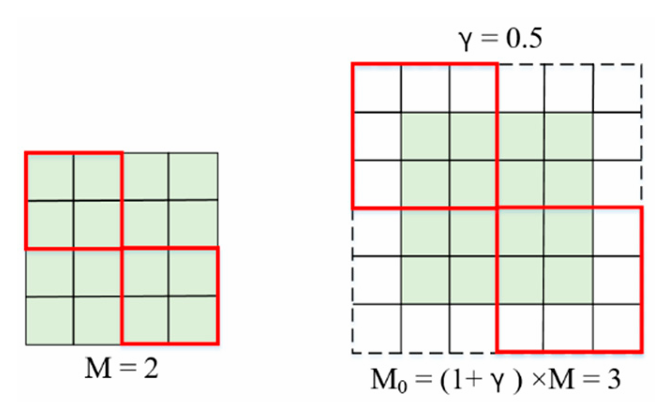
여기서 M은 표준 윈도우 분할의 슬라이딩 윈도우 크기이고, M0는 겹침 윈도우의 슬라이딩 크기이며, γ는 겹침 크기를 제어하는 상수이다. 이 설계는 서로 다른 윈도우 간의 정보를 매끄럽게 통합하도록 돕는다. 또한 각 겹침 윈도우 내에서 어텐션 메커니즘은 어텐션 스코어를 계산하고 이를 값에 적용하여 중요한 특징을 강화하고 덜 중요한 특징은 억제한다. 이러한 구성은 모델이 특징 맵 전반에 걸쳐 정보를 효율적으로 수집·전달할 수 있도록 하여, 보다 강력하고 세밀한 특징 표현을 제공한다. 아래 그림은 OCAB의 구조를 보여준다.
ⓒ Dual-Reconstruction Feature Fusion Module(DRFF)
DRFF은 Transformer encoder, Attention Feature Fusion Module(AFFM), mutual reconstruction module을 통합함으로써 심층적인 특징 융합과 재구성을 달성한다. 이 모듈의 설계 목적은 fine-grained 이미지 분류 작업에서 핵심 정보를 포착하는 모델의 능력을 향상시키는 데 있다.
DRFF 모듈은 먼저 전처리된 입력을 Transformer encoder에 통과시킨다. 기존 vision transformer와 달리, 우리는 이미지 패치 시퀀스를 직접 입력하지 않는다. 대신, 국소 특징 시퀀스와 그에 대응하는 공간적 위치 임베딩의 합을 계산한다. 이러한 방식은 각 위치의 특징을 고려하면서도 공간적 위치 정보를 모델에 통합할 수 있도록 해준다.
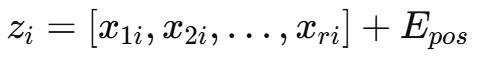
그 다음, 트랜스포머 인코더의 출력을 AFFM에 전달한다. AFFM은 표준 self-attention 연산을 기반으로 특징 융합을 수행한다. 기존의 특징 융합 기법은 주로 단순한 초기 통합 방식을 사용하여 서로 다른 계층의 특징을 결합하는데, 이는 실제로 계층 간의 진정한 의미의 특징 융합을 달성하지 못한다. 이를 해결하기 위해, 우리는 교대 통합 방식을 설계하였다. 초기 통합과 또 다른 어텐션 모듈을 결합함으로써 더 정밀한 특징 표현을 얻고, 이러한 교대 통합 방식을 특징 재구성 단계에 도입하였다.
AFFM의 독특한 점은 내부 구조에 두 개의 Multi-Scale Channel Attention Module(MS-CAM)이 포함되어 있다는 것이다. 이 모듈들은 서로 다른 스케일에서의 채널 종속성을 포착하여, 더 풍부하고 세밀한 특징 표현을 제공한다.
마지막으로, DRFF 모듈은 상호 재구성 전략을 통해 support set과 query set의 특징을 재구성한다. 이 과정은 모델의 클래스 내 변이에 대한 강인성을 높이는 동시에, 클래스 간 차이에 대한 민감도를 향상시킨다.
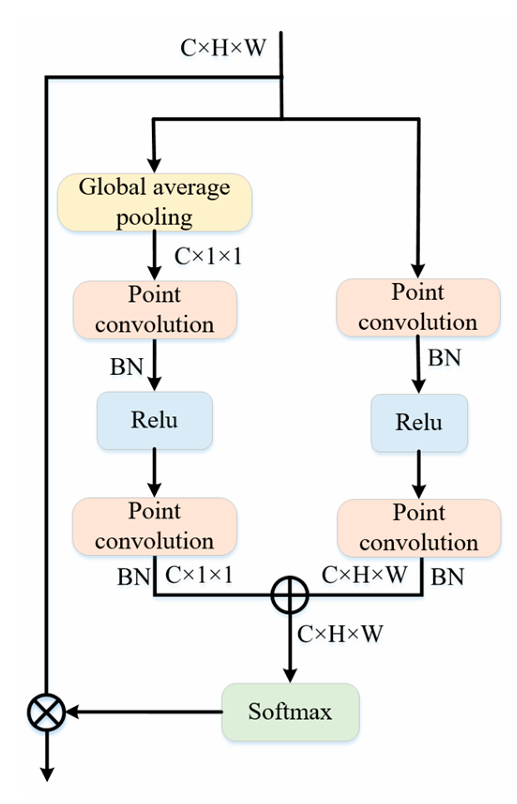
ⓒ-1 Multi-Scale Channel Attention Module(MS-CAM)
MS-CAM은 다중 스케일에서의 채널 종속성을 포착함으로써 특징 맵의 표현 능력을 향상시킨다. MS-CAM의 경량 특성을 특징 융합 과정에서 유지하기 위해, 어텐션 모듈 내부의 전역 문맥 정보와 국소 문맥 정보를 융합한다. pointwise 합성곱은 각 공간 위치에서 채널과 상호작용할 수 있으므로, 우리는 국소 채널 문맥을 집약하는 도구로 pointwise 합성곱을 선택하였고, 비선형성을 도입하기 위해 각 합성곱 층 뒤에 ReLU를 사용하였다. 학습을 안정화하기 위해 각 합성곱 층 뒤에 배치 정규화를 적용하였다.
ⓒ-2 Attention Feature Fusion Module
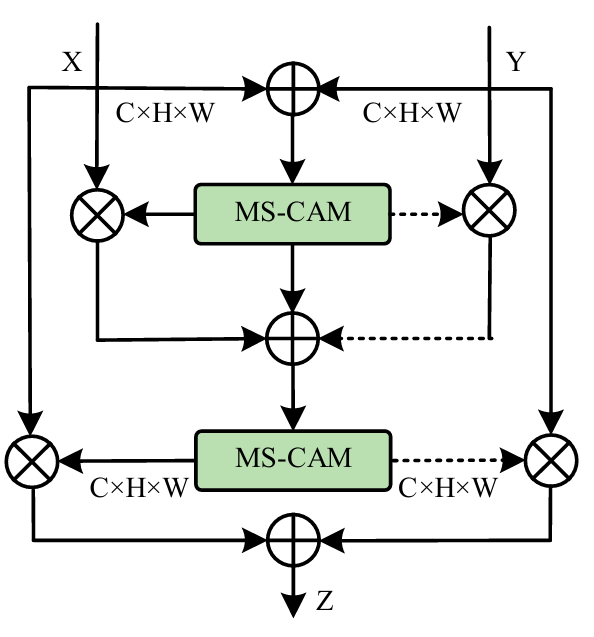
AFFM은 Inception 계층 내부의 특징 융합이나 길고 짧은 스킵 연결 계층에서 생성되는 특징의 융합 등 많은 전형적인 경우에 잘 적용된다. 기존의 어텐션 특징 융합 기법은 대개 원본 특징들을 element-wise로 더한 뒤, 그렇게 융합된 특징을 어텐션 모듈의 입력으로 사용하는 방식을 취한다. 그러나 이러한 처리는 최종적인 융합 가중치의 분포에 직접적인 영향을 미칠 수 있다.
이에 비해, 우리가 설계한 어텐션 특징 융합 모듈은 내부 구조에 두 개의 MS-CAM을 포함한다. 이 설계는 서로 다른 스케일에서의 핵심 정보를 더 효율적으로 포착하고, 가중 융합을 통해 더 표현력 있는 특징을 생성할 수 있게 한다. 보다 구체적으로, 모듈 내 각 MS-CAM은 먼저 다중 스케일 채널 종속성을 포착하여 입력 특징을 처리한다. 전역 문맥 정보는 전역 평균 풀링으로 얻고, 국소 문맥 정보는 pointwise 합성곱으로 집약한다. 각 합성곱 층 뒤에는 비선형성을 도입하기 위해 ReLU 활성화를 적용하며, 이는 높은 계산 효율을 유지하면서 더 복잡한 특징 표현을 학습하도록 하여 빠른 수렴에 기여한다. MS-CAM에서는 pointwise 합성곱 층 뒤에 ReLU를 사용하여 국소 문맥 정보를 집약하는 동안 중요한 특징 변화가 효과적으로 포착되고 증폭되도록 한다. 이어서 학습의 안정화를 위해 배치 정규화(BN)를 적용한다.
두 개의 MS-CAM을 거쳐 처리된 특징 맵들은 적응형 가중 메커니즘을 사용하여 결합된다. 이 메커니즘은 각 스케일의 특징에 중요도에 따른 가중치를 부여함으로써 다중 스케일 정보의 보다 미세하고 효과적인 융합을 가능하게 한다. 어텐션 특징 융합 모듈의 내부 구조는 다음과 같다.
Experiments
ⓐ Dataset and Experimental Setup
본 연구의 실험에는 CUB-200-2011, Stanford Cars, Stanford Dogs 데이터셋을 사용하였다. 이들 데이터셋은 fine-grained 이미지 분류에서 널리 알려진 벤치마크로, 클래스 내 변동성이 크고 클래스 간 차이가 미미하다는 특징을 갖는다. 다양한 범주와 샘플을 제공하기 때문에, 제안 방법의 유효성을 평가하기에 적합하다.
실험을 수행하기 전에, 모든 이미지 샘플을 224 × 224 픽셀로 리사이즈하여 처리 과정을 표준화하고 본 모델의 입력 요구사항에 맞추었다. 이러한 리사이즈 과정은 보간 방법을 사용해 이미지의 원래 종횡비와 내용을 유지하여 품질 저하를 최소화하였다. 이 크기를 선택한 이유는 이미지 분류 작업에서 일반적이고, 계산 복잡도를 제어하면서도 모델이 충분한 세부 정보를 포착할 수 있기 때문이다. 또한, 학습용, 검증용, 시험용 데이터셋을 2:1:1 비율로 엄격히 분할하였으며, 실험의 정확성을 보장하기 위해 이들 세트 간의 범주는 서로 겹치지 않도록 하였다.
CUB-200-2011은 200개의 범주로 이루어진 고전적인 세밀 이미지 분류 데이터셋으로, 총 11788장의 새 이미지를 포함한다. 이 데이터셋의 도전 과제는 서로 다른 조류 종 간의 미묘한 차이와 동일 종 내에서의 큰 외형적 변이성에 있다.
Stanford Cars는 196종류의 자동차에 대한 16185장의 이미지를 포함한다. 이 데이터셋은 자동차 종류가 매우 다양하며, 동일 종류의 자동차 사이에서도 외형상의 차이가 크다는 특징을 갖는다.
Stanford Dogs 데이터셋은 전 세계 120종의 개 품종에 대한 20580장의 사진으로 구성된다. 이 데이터셋은 세밀 이미지 분류를 위해 특별히 설계되었으며, 유사한 개 품종을 구별하는 복잡한 과제를 다루기 위해 처음 만들어졌다. 특히 일부 품종은 주로 색상이나 성숙도에 따른 차이가 매우 미세하기 때문에, 이 과제는 특히 어렵다.
우리는 세 가지 공개 데이터셋에서 분류 작업을 수행하였다. 모델은 SGD 옵티마이저로 학습되었으며, Nesterov 모멘텀(0.9로 설정), 가중치 감쇠 5×10−4, 초기 학습률 0.1로 1200 에폭 이상 훈련하였다. 학습의 안정성을 높이기 위해 center cropping, random horizontal flipping, color jittering 등을 포함한 일반적인 데이터 증강 기법을 적용하였다.
성능이 가장 우수한 모델은 검증 세트 결과를 기준으로 선택되었으며, 검증은 20 에폭마다 수행되었다. 테스트 시에는 제안 방법을 면밀히 평가하기 위해 10000개의 과제를 무작위로 샘플링하였다. 최종 테스트 결과는 95% 신뢰구간 내에서 평균 정확도를 계산하여 결정하였다.
ⓑ Evaluation Metrics
본 논문은 fine-grained few-shot 이미지 분류에서 C-way K-shot 문제를 다룬다. 이 시나리오에서 이미지는 먼저 support set에서 학습되고, 이후 query set에서 테스트되며, 두 집합 간에는 범주의 중복이 없다. 1-shot 학습은 few-shot 학습의 극단적인 경우를 나타내며, 5-shot은 여전히 제한적이지만 더 많은 정보를 제공하기 때문에, 우리는 5-way 1-shot과 5-way 5-shot을 주요 평가 지표로 사용하였다.
훈련, 검증, 그리고 테스트 세트를 구성할 때, query set의 각 범주는 일관되게 15장의 이미지를 포함하였다. 구체적으로, 5-way 1-shot 작업에서는 훈련 세트에서 무작위로 5장을 선택하여 support set을 구성하고, query set에는 75장의 이미지를 준비하였다. 훈련 중에는 support set에서 C개의 서로 다른 범주를 무작위로 선택하고, 각 범주에서 K개의 샘플을 추출하였다. 모델 성능을 철저히 평가하기 위해, 우리는 평균 정확도를 주요 평가 지표로 사용하였다.
ⓒ Experimental results
제안한 접근 방식의 효과성을 입증하기 위해, 우리는 이를 fine-grained few-shot 이미지 분류 알고리즘들과 정량적으로 비교하였다.
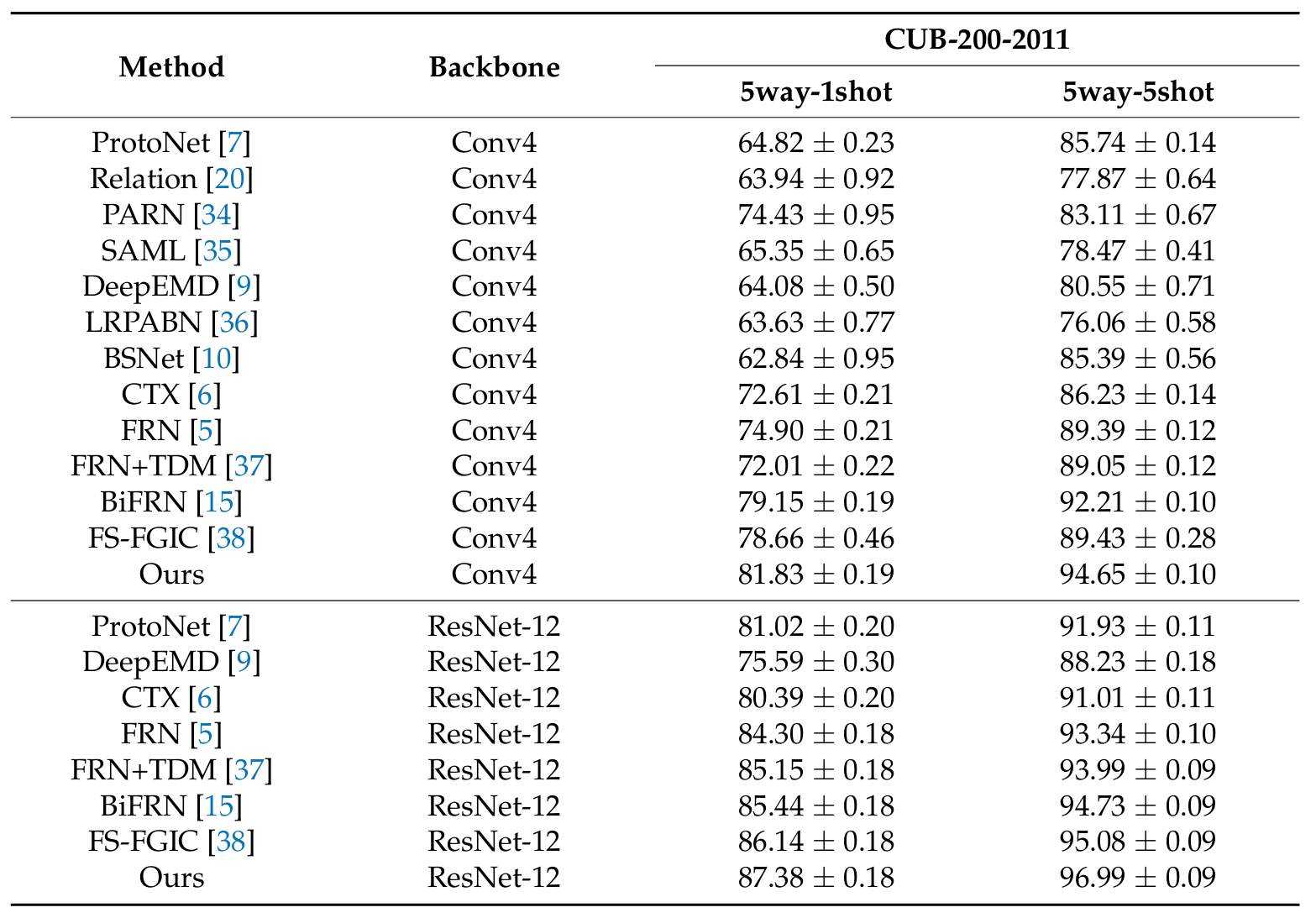
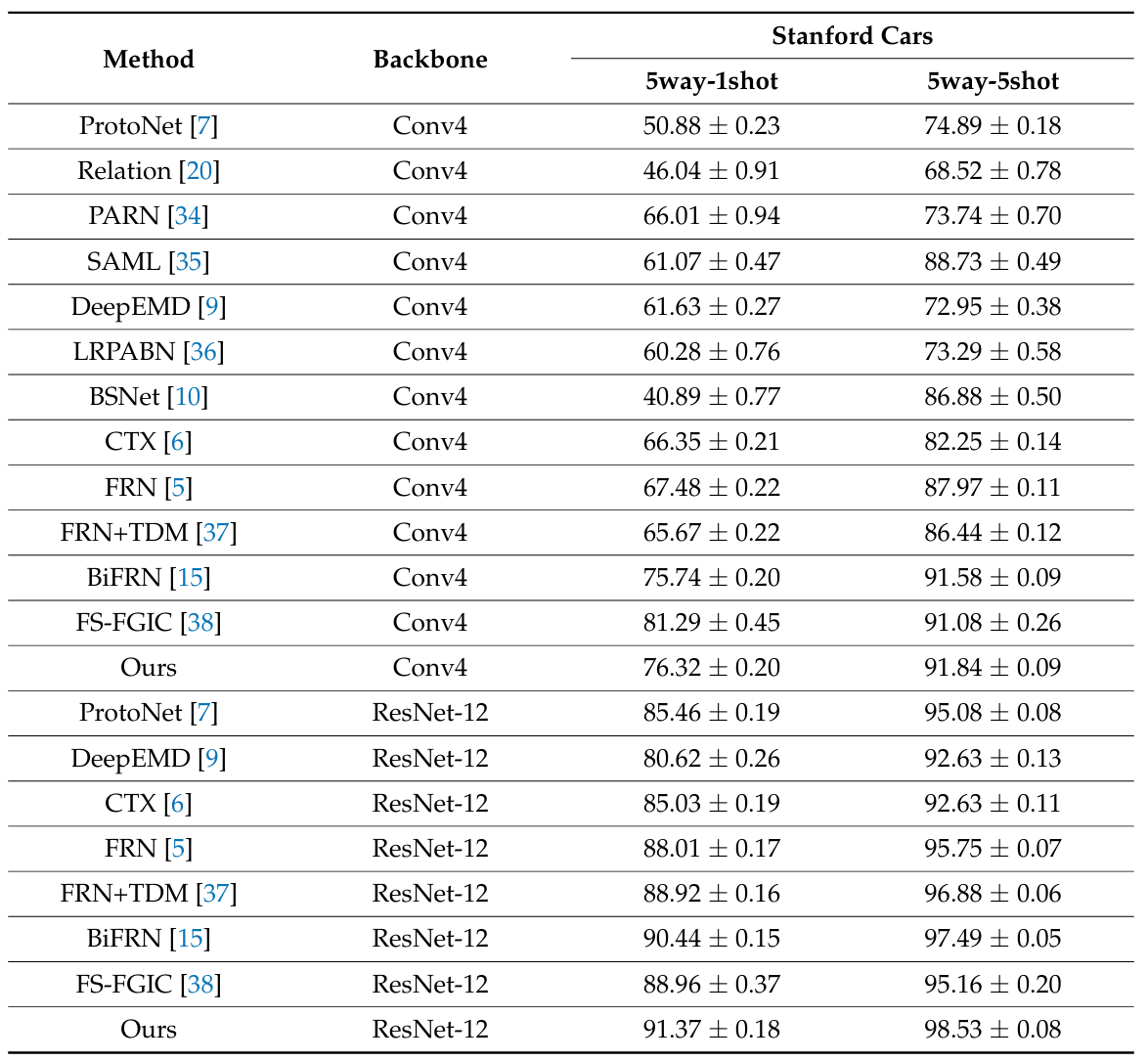
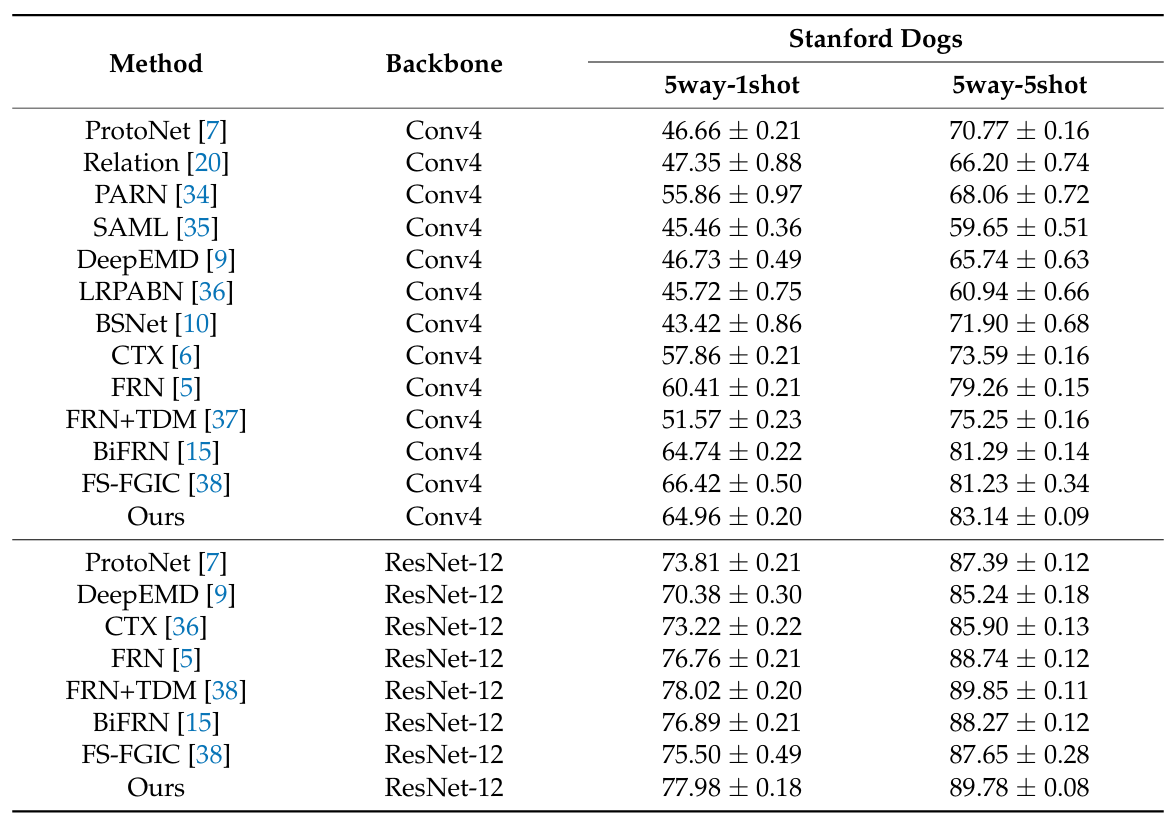
실험 결과, Matching Networks와 Prototypical Networks와 같은 전통적인 방법들은 세밀한 특징 추출에서 일정한 한계를 가지며, 종종 이미지 오분류를 유발한다.
실험 결과, CUB-200-2011 데이터셋에서 제안한 알고리즘은 5-way 1-shot 정확도에서 1.94~11.79% 포인트 더 높은 성능을 보였으며, 5-way 5-shot 정확도에서도 2.26~8.76% 포인트의 향상을 달성하였다.
Stanford Cars 데이터셋에서는 다른 세밀 이미지 분류 모델들과 비교했을 때, 5-way 1-shot 작업에서 0.93~10.75% 포인트, 5-way 5-shot 작업에서 1.04~5.9% 포인트의 정확도 향상을 이루었다. 이러한 결과는 제안한 알고리즘이 fine-grained few-shot 이미지 분류 작업에서 뛰어난 성능을 발휘함을 충분히 입증한다.
Discussion
본 연구에서는 fine-grained few-shot 이미지 분류 작업을 위해 양방향 특징 재구성 방법을 제안하였다. 범주 간 미묘한 차이에 대한 모델의 민감도를 향상시키는 것을 확인하였다. 또한, 이 모듈들은 다양한 스케일에서의 양방향 특징 재구성을 통해 범주 간 및 범주 내 변이에 대한 모델의 적응력을 높였다. 이는 fine-grained few-shot 이미지에서 큰 범주 내 차이와 작은 범주 간 차이로 인해 네트워크가 추출한 특징 벡터의 강건성이 떨어지는 문제를 해결하는 데 중요하다.
다양한 few-shot 데이터셋에서 본 알고리즘이 유망한 결과를 보였음에도, 향후 연구에서 해결해야 할 몇 가지 한계점이 존재한다.
① 알고리즘의 성능이 사전 학습된 embedding backbone의 선택에 크게 의존한다. 이러한 사전 학습 모델은 우수한 특징 표현력 덕분에 few-shot 학습 알고리즘에 강력한 지원을 제공하지만, 이에 대한 과도한 의존성은 향후 연구에서 더 면밀히 조사할 필요가 있다.
② 모듈 내에 스킵 연결을 도입하여 모델의 정보 유지 능력을 높였음에도, 모델 복잡도가 여전히 잠재적인 성능 향상을 제한할 수 있다. 많은 few-shot 방법들은 단순한 파이프라인을 채택하면서도 데이터셋에서 좋은 성능을 내고 있으므로, 이 연구 방향을 계속 탐구할 계획이다.
또한, 학습 세트와 테스트 세트가 서로 다른 도메인일 때, 본 연구의 개선 방안을 향후 연구에서 더욱 깊이 탐구할 필요가 있다. 우리는 아직 더 효율적인 모델 설계가 발견되지 않았다고 생각하며, 어려운 샘플과 쉬운 샘플 사이의 균형 역시 충분히 연구되지 않았다고 본다. 우리는 이 연구를 지속할 것이며, 그 결과를 적시에 공유할 계획이다.
우리는 향후 연구가 보다 포괄적이고 광범위한 비교를 고려해야 한다고 제안한다. 또한, fine-grained few-shot 이미지 분류 기술의 발전은 생물다양성 모니터링과 의료 영상 분석과 같은 분야를 발전시킬 수 있다.
이러한 한계와 논의 사항은 향후 연구를 위해 남겨둔다.
Conclusions
본 연구는 범주 내 변이는 크고, 범주 간 변이는 작은 문제를 해결하기 위해 설계된 새로운 세밀 이미지 분류 알고리즘을 제안한다. 이 접근 방식은 Mixed Residual Attention(MRA) 블록과 Dual-Reconstruction Feature Fusion(DRFF) 모듈을 결합한 양방향 특징 재구성 메커니즘을 사용한다.
MRA 블록은 channel attention과 window-based self-attention을 결합하여 국부적 세부를 포착하고 특징 표현을 향상시킨다.
DRFF 모듈은 계층 간 특징 융합을 강화하고 범주 간·범주 내 변이에 모두 적응하여, 범주 간 미묘한 차이에 대한 모델의 민감도를 높인다.
세 개의 벤치마크 데이터셋에서 실험을 수행한 결과, 특히 5-way 5-shot 작업에서 본 방법은 각각 96.99%, 98.53%, 89.78%의 분류 정확도를 달성하였다. 이러한 결과는 제한된 샘플 상황에서도 제안한 방법이 세밀 분류 작업을 효과적으로 처리할 수 있음을 보여준다. 높은 정확도는 알고리즘의 강건성을 입증할 뿐 아니라, 실제 응용에서의 잠재력도 강조한다.
전반적으로, 본 연구는 세밀 이미지 분류를 위한 few-shot 학습 분야에서 중요한 진전을 이루었다. 제안한 방법은 매우 적은 예시만으로도 학습이 가능하며, 세밀한 범주를 정확하게 분류할 수 있다. 이는 생물다양성 모니터링과 같은 분야에서 중요한 응용 가치를 가진다. 향후 연구에서는 본 방법을 더 넓은 범주의 카테고리로 확장하는 가능성을 탐구하고, 컴퓨터 비전의 다른 분야에서의 적용 가능성을 조사할 예정이다.
Embedding Module
----MRA 블록
--------3x3 합성곱 층
--------Mixed Attention Block
------------channel attention
------------multi-head self-attention
--------Overlapping Cross-Attention Block
------------Overlapping Cross-Attention
------------Overlapping Cross-Attention
----feature extractor
Dual Reconstruction Featrue Fusion
----Transformer encoder
----Attention Feature Fusion Module
--------Multi-Scale Channel Attention Module
--------Multi-Scale Channel Attention Module
----Mutual Feature Reconstruction Module
Cosine Similarity Measurement Module
