스파르타코딩클럽(비개발자를 위한, 웹개발 종합반_3주차)
0
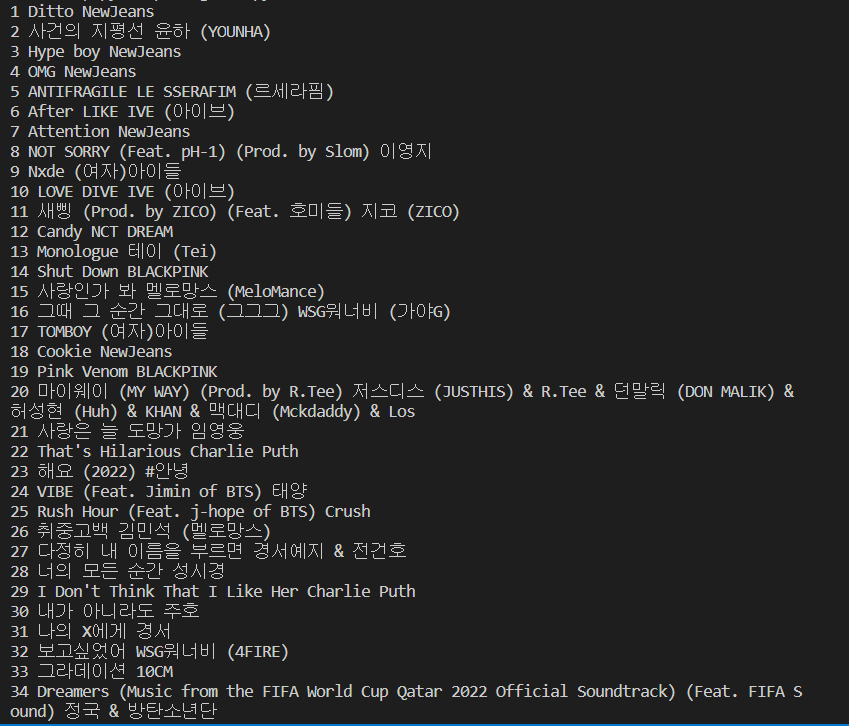
3주차(23-04-15~16)
숙제-지니뮤직의 1~50위 곡을 스크래핑 해보세요.
# 크롤링 기본코드
import requests
from bs4 import BeautifulSoup
URL = "https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#--------
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text[0:2].strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip() #.strip() 로 공백을 지울 수 있음
# doc= {
# 'rank' : rank,
# 'title' : title,
# 'artist' : artist
# }
print(rank, title, artist)일단 3주차 하면서 venv때문에 애 먹음,,, 몽고db도 해놧던게 없어서 날아가는건가싶었는데 아무리 해도 안나오던게 그냥 나중에 들어가보니 또 있고 어떻게 작동하는지 너무 어려움
가상환경 venv 설정해도 왜 안되냐,,,
숙제에서는 위치 찾는게 헷갈림
전체 tr까지 들어가고 그다음 td.number로 설정해줘야함,, .number 로 왜안되나 싶었음,,

개발일지