
멤버 순서에 따른 객체 크기 변화
다음과 같이 클래스 멤버의 순서가 바뀐 두 클래스의 크기를 비교해보자.
class A{
int a;
int b;
double c;
}; // 16 byte
class B{
int a;
double c;
int b;
}; // 24 byte 더 크다!Class B의 경우 멤버가 같아도 24 byte가 나오는데 이는 메모리 룰에 의거한다.
메모리는 메모리 룰에 어긋나는 변수를 Write 하려고 할 경우
그대로 변수를 넣지 않고 대신 패딩(빈 공간)을 집어넣는다. (자연 정렬을 보장하기 위해)
메모리가 이러한 정렬 방식을 따르는 이유는
컴퓨터 하드웨어의 CPU는 데이터가 자연스럽게 정렬(naturally aligned) 될 때
(일반적으로 데이터 주소가 데이터 사이즈의 배수일 때) 메모리에 대한 읽기 및 쓰기를
가장 효율적으로 수행할 수 있어서이다.
메모리 얼라이먼트(alignment) 룰은 다음과 같다.
-
오브젝트의 멤버 변수의 주소는 변수 사이즈 배수에서 위치가 할당되어야 한다.
int 같은 경우 object 내에서 0, 4, 8 byte에 저장되어야하고
double 같은 경우 object 내에서 0, 8 ,16 byte에 저장되어야한다.
-
object의 전체 사이즈는 가장 큰 멤버 변수의 배수가 되어야 한다.
즉, 클래스에 double이 들어가면 object의 사이즈는 무조건 8의 배수가 된다.
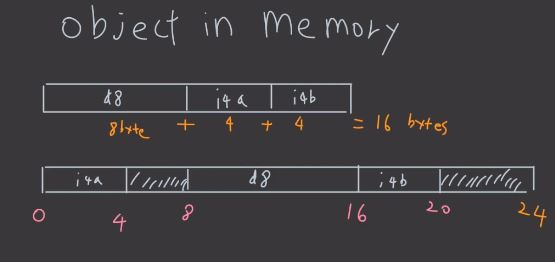
정리
결론적으로 class B의 크기가 다른 이유는 int a까지는 4byte를 점유하지만
1번 룰에 의해 double c는 8byte에서부터 저장되고
그리고 2번 룰에 의해 오브젝트의 총 크기는 8의 배수가 되어야 하기 때문이다.
즉, double c가 4byte가 아니라 8byte에서 시작되고 그 후 int b는 16byte에서 시작되지만
오브젝트의 총 크기는 8의 배수가 되어야 하니 20byte가 아닌 24byte로 설정된다.
※ 메모리 alignment 룰에 위배되지 않는 순서로 멤버 변수를 설계하여 객체 크기를 절약하자.
