
본 시리즈는 메타 코딩님의 Junit 강의를 학습한 내용을 바탕으로 정리하였습니다.
지금까지 책을 등록(create)하고 조회(select)하는 작업을 완료했다. 이제 삭제(delete)를 구현할 차례이다.
책 삭제_test
책 삭제는 비교적 간단하게 구현할 수 있었다.
BookRepositoryTest.java
@Test
public void 책삭제_test() {
// given
Long id = 1L;
// when
bookRepository.deleteById(id);
// then
assertFalse(bookRepository.findById(id).isPresent());
}Repository의 값이 delete되는지를 검증하기 위해 assertFalse 를 사용한다. assertFalse 는 assertTrue 와는 반대로 True일 때, 에러를 발생시키는 메소드이다.
즉, bookRepository의 findById 를 통해 나온 값이 없다면 False, 있다면 True를 리턴하게 된다. 삭제를 시켰다면 값이 없을테니 False가 나와야 할 것이다.
delete 구현이 끝났다. 이제 한번 테스트를 돌려보자.

잘 동작하는 것을 볼 수 있다.
그렇다면 이쯤해서 전체 통합 테스트를 한 번 돌려보자.
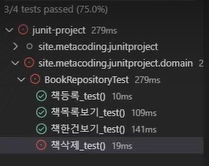
잘 되던 책 삭제 테스트에서 오류가 뜬다. 어떤 내용의 오류인지 살펴볼 필요가 있는 것 같다.
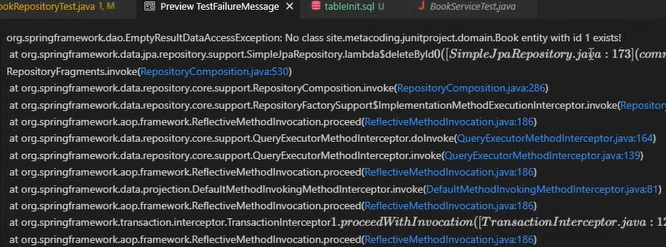
로그를 보니 우리가 만든 Book entity에 id가 1인 데이터가 없다고 나온다. 왜 이런 현상이 발생할까?
문제 발생의 원인 ⚠️
1. 순서 보장이 되지 않는다.
테스트 메서드가 다음과 같이 3개가 있다.
- 메서드 1
- 메서드 2
- 메서드 3
그렇다면 테스트를 실행할 때, 메서드1 ~ 3까지 순서대로 진행이 될까?
답은 No다. 순서에 상관없이 실행되어도 똑같이 같은 테스트 결과를 도출해내어야 좋은 로직이다.
실제로 서비스가 동작할 때, 우리는 고객들이 우리가 만든 서비스 로직대로 움직일 것이라고 예상하지 않는다. 물론 초기에 책이 없는 상태에서는 책 등록부터 하겠지만 그 이후엔 수정을 먼저 하든 삭제를 먼저 하든 고객의 마음이다.
만약 실행 순서와 상관없이 테스트를 구성하려면 어떻게 해야할까? 다음의 방법이 있다.
@Order
@Order 는 테스트의 실행 순서를 정해주는 어노테이션이다.
@Order(1)
@Test
public void 책등록_test() {
// ... (생략)
}
@Order(2)
@Test
public void 책목록보기_test() {
// ... (생략)
}이런식으로 메소드 간의 순서를 지정해줄 수 있다.
2. PK의 auto_increment 값이 초기화가 되지 않는다.
auto_increment 값이 초기화가 되지 않아 오류가 발생한다. 쉽게 얘기해서 id값이 계속해서 증가한다는 얘기인데 우리의 테스트 코드를 다시 한번 살펴보자.
BookRepositoryTest.java
@BeforeEach
public void 데이터준비() {
String title = "junit5";
String author = "메타코딩";
Book book = Book.builder()
.title(title)
.author(author)
.build();
bookRepository.save(book);
}
@Test
public void 책목록보기_test() {
// given
String title = "junit5";
String author = "메타코딩";
// when
List<Book> booksPS = bookRepository.findAll();
// then
assertEquals(title, booksPS.get(0).getTitle());
assertEquals(author, booksPS.get(0).getAuthor());
}우리가 짠 테스트 코드는 beforeEach 에 의해 다음과 같이 한 세트처럼 동작한다.
데이터 준비()+책등록_test()데이터 준비()+책목록보기_test()데이터 준비()+책삭제_test()
그리고 매 테스트 메서드가 실행이 종료되면 Junit의 @Transactional 에 의해 데이터가 초기화된다. 이 때, 완전히 테이블이 초기화가 되어야하는데 레코드가 생성될 때마다 자동으로 증가하는 primary key(id) 값만 초기화가 되지 않는 것이다.
즉, 쉽게 말해 id가 1인 데이터를 삽입 후, 삭제하고 다시 값을 삽입한다면 id가 1이 되어야 하는데 2가 되는 상황이 발생하고 있는 것이다.
해결 방법 ✅
1. Table의 id를 다시 1로 리셋하는 SQL 쿼리 날림
@DataJpaTest
public class BookRepositoryTest {
@Autowired
private EntityManager em; // Entity를 관리하는 역할
@BeforeEach
public void db_init() {
bookRepository.deleteAll();
em
.createNativeQuery('ALTER TABLE book ALTER COLUMN id RESTART with 1')
.executeUpdate();
}
}
EntityManager란?
: Entity를 관리하는 역할을 수행하는 클래스. 전에 언급한대로@DataJpaTest어노테이션을 사용하면 DB와 관련된 컴포넌트들을 사용할 수 있으며@Autowired를 통해 가져오기만 하면 된다.
이렇게 하면 매 테스트를 수행하기 전에 ALTER 문을 이용해 id 를 1로 restart할 수 있게 해준다.
이 방법을 수행해도 상관은 없지만 단점이 하나 존재하는데 매 테스트를 수행할 때마다 동작하게 되므로 앱 자체가 무거워지고 느려지는 요인 중 하나가 된다. (물론 눈에 띄게 느려지지는 않겠지만..)
따라서 두 번째 방식을 사용하는 것도 좋다.
2. 테이블을 초기화하는 SQL 쿼리문 작성 후 실행
main java 폴더에 resources 하위 db 폴더에 tableIni.sql 이라는 sql문을 따로 관리하는 파일을 하나 만든다.
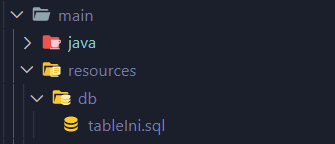
그리고 tableIni.sql 에 다음과 같이 sql문을 작성하자.
tableIni.sql
drop table if exists Book;
create table Book (
id bigint generated by default as identity,
author varchar(20) not null,
title varchar(50) not null,
primary key (id)
)
이 sql문 또한 테이블을 drop하고 새 table을 만들어주는 sql쿼리이다. 즉, 테이블을 완전히 초기화 시켜 새로운 테이블로 만든다는 이야기이다.
이제 id 값을 찾아서 작업을 수행하는 메서드(책목록 조회, 수정, 삭제) 마다 @Sql("classpath:db/tableIni.sql") 를 붙여주면 해당 경로의 sql 쿼리문을 실행하게되고 쿼리문에 의해 테이블을 자동으로 초기화시키고 테스트를 수행할 수 있게 된다.
BookRepositoryTest.java
@Sql("classpath:db/tableIni.sql")
@Test
public void 책한건보기_test() {
// ...(생략)
}
@Sql("classpath:db/tableIni.sql")
@Test
public void 책수정_test() {
// ...(생략)
}
@Sql("classpath:db/tableIni.sql")
@Test
public void 책삭제_test() {
// ...(생략)
}이제 전체 테스트를 돌려보면 다음과 같이 모두 성공하는 것을 볼 수 있다.

