
Some Network Applications : e-mail, web, text messaging, remote login, P2P file sharing, multi-user network games, streaming stored video, voice over IP, real-time video conferencing, social networking, search ...
Principle of network applications
Important Themes overall
Control vs Messages
Centralized vs Decentralized
Stateless vs Stateful
Reliable vs Unreliable
"COMPLEXITY AT NETWORK EDGE"
- Program (application)은 end-system에서만 실행된다.
- Network-core device(router)를 위한 software를 만들 필요는 없다.
Application Structures
Client-server와 peer-to-peer(P2P) 두가지가 있다.
Client-Server architecture
client : server가 n:n, n:1, 1:n, 1:1 모두 가능하다.
Server :
- Always-on host
- Permanent IP address
- Usually as Data Center (2022년 10월에 kakako data center에 문제가 생겨 먹통이 되는 일이 있었다.)
Client :
- communicate with server
- may be intermittently connected
- may have dynamic IP address
- do not communicate directly with each other
P2P architecture
no always-on server
peer request services from other peers, provide service in return to other peers - self scalability -
Process communicating
Process : program running within a host
1. same host : inter-process communication (shared memory, pipe 등의 OS 기법)
2. diff host : Communicate via Network. send, receive.
(P2P는 server process와 client process 둘 다 가지고 있다.)
client process : initiate communication
server process : wait to be contacted
sockets - kind of interface
process는 socket을 통해 message를 보내고 받는다. socket은 문과 유사한데 sending process가 message를 넣고 OS에게 보내달라고 요청한다.
1개의 process는 1개 이상의 socket이 필요하다. 그리고 그러한 process는 identifier를 가지고 있어야 한다. Host device는 32-bit의 unique한 IP address를 가지고 있는데 하나의 host device에서는 여러개의 process가 돌아가고 있어서 IP addr만으로는 identifier라고 하기에는 부족하다. 그래서 IP + Port number로 identifier를 만든다. (HTTP의 port number는 80, mail server는 25로 정해져 있음)
Application level protocol은 다음과 같은 것들을 정의한다.
- Types of message exchanged (request, response)
- message syntax == Grammar
- message semantics == Meaning
- Rules for when and how to send & respond
Open protocols : defined in RFCs, allows for interoperability (HTTP, SMTP)
Proprietary protocols (Skype)
Application level에서 필요로하는 transport의 기능들은 4가지로 분류할 수 있다. 먼저 data가 손실없이 100% 보내진다는 걸 보증하는 data intergrity(TCP/IP가 보증한다.). Low delay를 원하는 timing, minimum amount of throughput을 필요로하는 throughput, 그리고 security이다.
TCP와 UDP
뒤에 조금 더 자세히 다루겠지만 앞으로 계속 나올 용어이기에 미리 정리 해야할 듯 하다.TCP는 reliable transport이고, flow control이 가능하다. flow control은 너무 많은 양의 data (receiver가 감당하지 못할 정도의)를 보내지 않는 것이다. 너무 많은 송신자가 한번에 송신하는 것을 control하는 congestion control이 가능하다. 대부분이 TCP를 사용한다.
UDP는 위의 기능중 아무것도 가능하지 않다. 그러나 TCP의 flow control방식이 맞지 않거나 본인만의 고유한 reliability를 만들고 싶다면 UDP를 사용하기도 한다.
둘 다 Encryption이 없어 security를 보장하지 않지만 SSL로 이를 보완한다.
Web and HTTP
Webpage는 보통 HTML file이 base다. HTML file이 HTML file이나 JPEG image, Java applet, audio file 등을 referenced object로 가지고 있는 "File"이다. URL로 주소가 지정되고 URL은 host name + path name으로 구성된다.
HTTP
Key words : HTTP, non-persistent & persistent, Cookie, Cache(Proxy server)
HTTP : HyperText Transfer Protocol의 약자이다. Web의 application layer protocol이고 client/server model이다. (P2P가 아니다.) 여기서 client는 browser, server는 Web server이다.
HTTP는 TCP를 사용한다. Server는 항상 80번 port를 열어두고 client의 연결을 기다린다. Connect된 이후에는 Browser와 Web server간의 message를 교환하는 역할을 한다. 그리고 TCP 서버를 닫는다.
HTTP는 stateless하다. 즉, 과거에 어떤 정보가 오고 갔는지 알 필요가 없다는 뜻이다.
HTTP의 연결 방식에는 두가지가 있다. 과거에 쓰였던 non-persistent HTTP와 최신의 persistent HTTP가 있다. 둘의 차이는 하나 이상의 TCP connection(non-persistent)을 사용하는 것과 하나만의 TCP connection(persistent)을 사용하는 것에 있다. Webpage의 경우 하나의 파일이 아니라 여러개의 파일로 구성되어 있기에 multiple object를 받아야 한다. 따라서 multiple object를 하나의 TCP로 받을지, 여러개의 TCP로 받을지에 대한 논의가 필요하다.
Non-persistent HTTP는 HTTP client가 TCP connection을 initiate해서 연결한다. server와 request-response를 거친 후 server에서 HTTP connection을 닫는다. 따라서 n개의 object를 받기 위해서는 n번의 연결이 필요하다.
Round-trip time은 packet의 client -> sever -> client 왕복 시간이다. HTTP response time에서 non-persistent인 경우 2RTT + file transmission time이 된다. (1 RTT for connection, 1 RTT for request-response). object마다 2RTT가 필요하기에 시간적 문제도 있고, 너무 많은 TCP 연결은 OS에게 부담을 줄 수 있다.
Persistent HTTP 는 server에서 response후에 connection을 유지하는 것이다. 처음 connection할 때의 RTT 말고는 연결을 위한 RTT를 소비하지 않기에 시간적인 이득을 볼 수 있다.
Some response status codes in HTTP
- 200 OK
- 301 Moved Permanently
- 400 Bad Request
- 404 Not Found
- 505 HTTP Version Not Supported
Cookies
Web site들은 cookie를 사용한다. User의 ID를 만들어서 server뿐만 아니라 user에게도 저장하는 방법인데, 첫 접속 후 나중에 다시 접속할 때 user가 저장한 cookie값도 함께 보낸다. 이 경우 request-response를 한 단계 줄일 수 있는 장점이 있다. Cookie는 authorization, recommendation등에 쓰일 수 있다.
Caches (proxy server)
origin server에 갔다오지 않고도 HTTP response를 받기 위한 전략이다. 이 경우 request-response delay를 줄일 수 있으며 traffic이 복잡해 지는 것도 막을 수 있다.
proxy server를 client 근처에 두고 origin server의 data들을 저장해 놓다가, client가 request할 때 proxy server에 존재하는 data일 경우 origin server까지 가지 않고 바로 response하는 방법이다. Origin server를 main memory, proxy server를 cache라고 생각하자. Hit한 경우 좋지만, 만약 miss가 일어난 경우 proxy server가 client역할을 해서 data를 받아온다.
Conditional GET
Proxy server는 origin server의 object에 변화가 있을 때에만 update를 하면 된다. proxy server가 특정 date 이후 변경된 data가 있는지 request하고 만약 있다면 origin server에서 respond 해준다(없어도 없다고 respond는 해준다).
이렇게 data가 오는 와중에 client가 접근한다면...bad scenario이다. conditional get과는 다른 해결책으로 origin server에서 update가 있을 때 proxy server에 push하는 방법도 있다.
Electronic mail
User agent, mail servers, protocol(SMTP : Simple Mail Transfer Protocol).
User agent : mail 'reader'
Mail server :
- mail box : incoming message storage
- message queue : outgoing messages queue
- mail server 끼리는 P2P style
SMTP protocol :
TCP를 사용하고 port number는 25다. 3가지 phase로 이루어져있다.
- hand shaking (greeting)
- stransfer of messages
- closure
Persistent connection을 사용한다.
message는 7-bit ASCII
mail을 읽을 때에는 SMTP 대신 POP3, IMAP등이 사용된다.
SMTP mail message format
header : To, From, Subject
body : literal message
receiver의 mail server에 있는 data에 어떻게 retrieve 할 것인가?
-> mail access protocol
- POP(Post Office Protocol) : authorization - download
POP3 protocol [ download and keep, stateless ]
Authorization phase -> user : username, pass : password AND server response(+OK or -ERR)
Transaction phase -> list : list message numbers, retr : retrieved message by number (mail을 local에 저장), dele : delete, quit - IMAP(Internet Mail Access Protocol) : more features, including manipulation of stored messages on server [keeps all messages in one place - server]
- HTTP : gmail, Yahoo! Mail etc
HTTP & SMTP
HTTP : Pull
SMTP : PushHTTP : each object encapsulated in ints own response message
SMTP : multiple objects sent in multipart message (MIME)
DNS
Hierarchical database, TDC, name resolution
Domain Name System
IP address(32-bit) for datagrams, name(www.yonsei.ac.kr) for humans.
Goal : Host name <-> IP address
host alising : 하나의 컴퓨터가 여러개의 logical name(Domain).
load distribution : 하나의 Domain에 여러개의 IP -> 서버에 가해지는 부담을 줄인다.
mail server의 ip주소도 DNS가 알려준다.
Distributed database
Application-layer protocol
hosts, name servers communicate to resolve names.
How it works :
Distributed, Hierarchical database
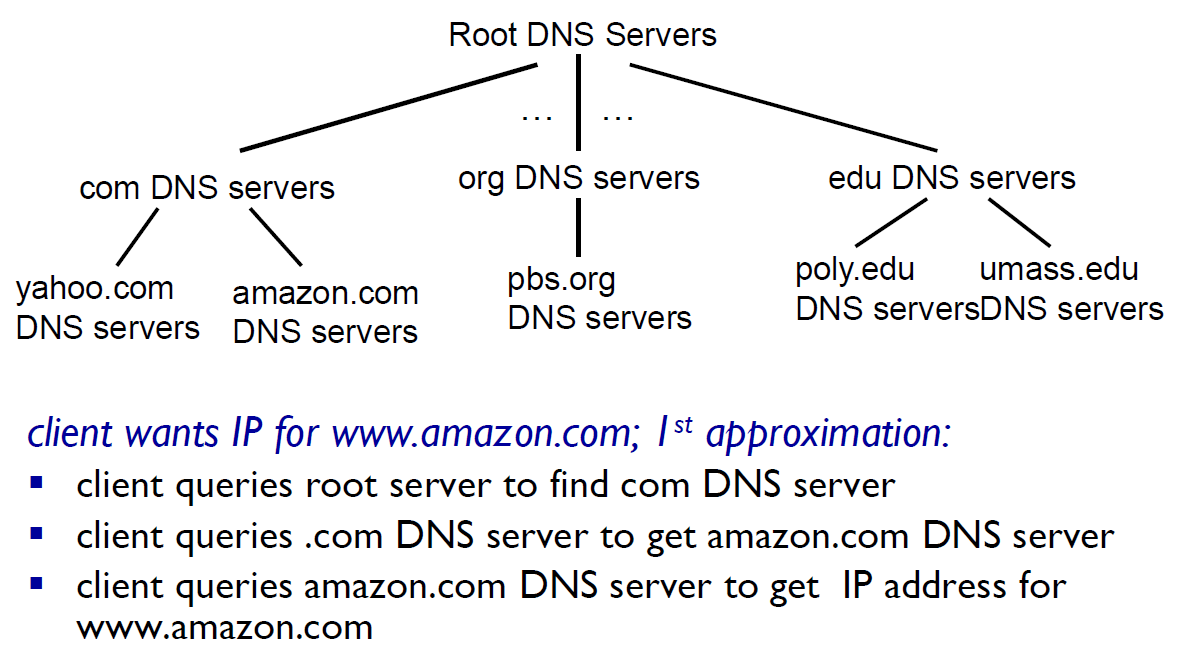
이러한 root server가 전 세계에 13개 복제되어 있다. (map보면 거의다 미국이나 유럽이다.)
Top-Level Domain servers : .com, .org, .kr~~
Authoritative DNS servers : yonsei.ac, naver ...
End user는 root에 직접 접근할 수 없다. Local DNS name server에 접근해서 활용. Local DNS server는 proxy server처럼 작동한다.
PROTOCOL :
name resolution에는 두가지 방법이 있다. Iterated query와 recursive query. Iterated query는 부서 전화 연결 생각하면 될듯 하다. 114에 전화 -> 회사 대표 번호 연결 -> 회사 부서 연결 ("I don't know this name, but ask this server"). Recursive query는 찾을때까지 알아서 recursive하게 간다. 114에 전화 -> 114가 회사 대표 번호로 전화해서 물어본다 -> 회사 대표번호가 회사 부서에 물어본다 -> pop pop pop
이러한 mapping 과정이 time consume이 클 수 밖에. 그래서 cahch로 저장한다. 모든 caching과 마찬가지로 out-of-date problem 발생할 수 있다.
P2P applications
Keywords : distribute file comparison, tit-for-tat
No always-on server
File distribution time을 client-server architecture와 peer-to-peer architecture의 비교
File 양 F
User 수 N
upload capacity
minimum client download rate
Time to distribute F to N in client-server :
Time to distrubute F to N in peer-to-peer : client도 서버처럼 작동해서 i개의 서버가 있는 것 처럼 보인다.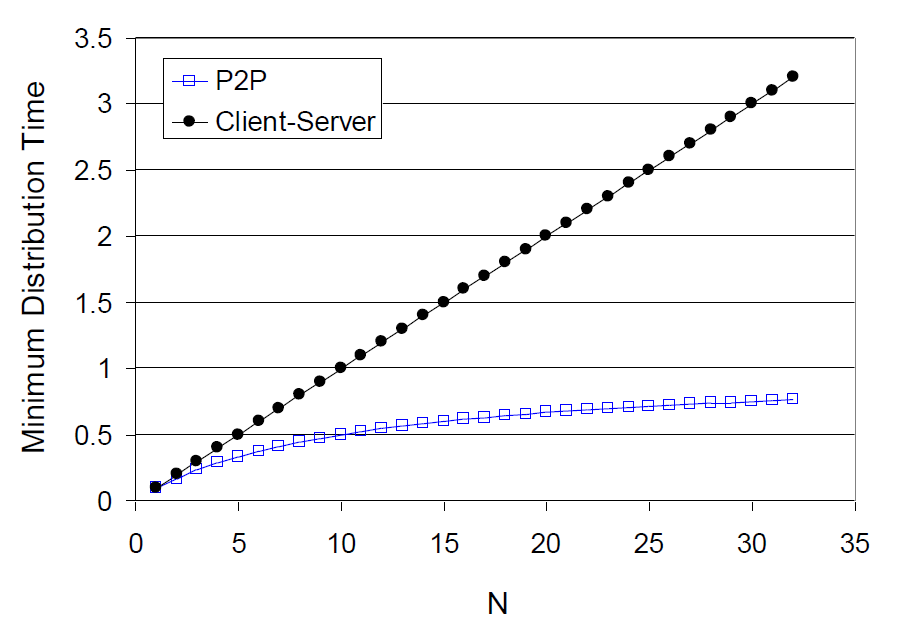
P2P file distribution example : BitTorrent
file이 256Kb chunks로 나뉘어 있고, peers가 sent/receive한다. Chunk를 교환하는 peers를 churn라고 한다.
tit-for-tat -> 토렌트를 유지하는 중요한 원리
가장 많은 chunk를 제공하준 peer top 4에게 chunk보냄.
10초마다 peer 재평가 (top 4)
30초마다 random peer에게 보낸다 (신규 가입 유저 배척을 막기 위해)
Video streaming and content distribution networks(CDN)
Challenge and Options, CDN
Video는 file이 크기에 major traffic consumer이다(Netfilx와 Youtube가 젗네 traffic의 50% 이상이다). User도 많고 video도 너무 많다. 또한 3G vs 5G의 차이도 심하다.
Solution : Distributed, Application-level infrastructure.
DASH protocol : Dynamic, Adaptive Streaming over HTTP
encode 속도에 따라서 다른 quality의 video 제공
CDN : how to stream content to hundreds of thousands of simultaneous user? (Netflix 같은 것들)
Option 1 : single, large "mega-server" - 단점이 더 많다.
Option 2 : store/serve multiple copies of videos at multiple geographically distributed sites (CDN)- Web cache와 비슷한 원리
OTT : "over the top" CDN중 하나다. (여담. Netflix의 Original Contents는 AWS에 저장되어 있다.)
Socket programming with UDP and TCP
Socket Programming? -> Application - OS(end-end-transport protocol) 연결하는 Door.
Socket type : UDP (unreliable datagram) / TCP (reliable, byte stream-oriented)
UDP
No connection between client & server
no greeting. IP dst + port # is everything.
may be lost or out-of-order
server가 죽어도 client는 알 수 없다. (connection이 없기 때문)
socket programming
client 와 server 모두 socket 생성. IP, port num, socket type(DGRAM) 필요. (server는 bind 꼭 해줘야함)
data send / receive
TCP
Client must contact server.
server가 실행중이여야 하고, socket을 만들어 놔야 한다(welcome socket 느낌).
1 client : 1 socket.
Connection을 확정한 후 data transfer 시작.
socket programming
socket 생성. server가 먼저. IP, port num, socket type(STREAM). 얘도 server는 bind 먼저 해줘야 한다
Connection request, accept and data send / receive.
시험공부 하면서 적느라 엉망이다. 나중에 다시 와서 수정할듯
