인덱스 기본
💡 인덱스란?
원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 찾아보기와 유사한 개념으로, 검색 성능의 최적화를 목적으로 두고 있지만 DML 작업 효율이 저하될 수 있다는 단점이 존재
💡 B-TREE 인덱스
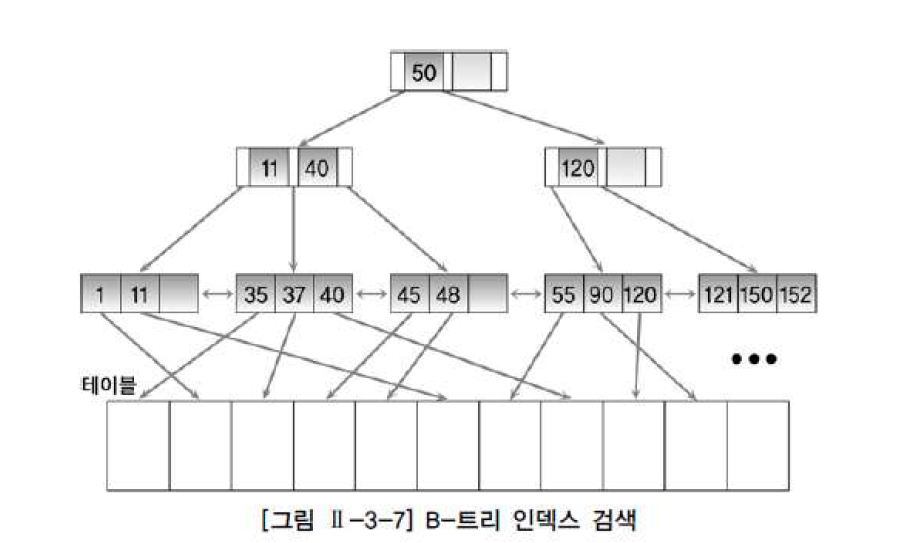
DBMS에서 사용하는 가장 일반적인 인덱스
1. 브랜치 블록의 가장 왼쪽 값이 찾고자 하는 값보다 작거나 같으면 왼쪽 포인터로 이동
2. 찾고자 하는 값이 브랜치 블록의 값 사이에 존재하면 가운데 포인터로 이동
3. 오른쪽에 있는 값보다 크면 오른쪽 포인터로 이동
💡 스캔 방법
- 전체 테이블 스캔(Full Table Scan): 테이블의 모든 데이터를 읽으며 데이터 추출, 읽은 블록의 재사용성을 낮다고 판단하여 메모리 버퍼에서 제거함
1) SQL문에 조건이 없거나
2) SQL문 조건 관련 인덱스가 없거나
3) 전체 테이블 스캔을 하도록 강제로 힌트를 지정하거나
4) 옵티마이저가 유리하다고 판단하는 경우
5) 많은 데이터를 조회할 때 - 인덱스 스캔(Index Scan): 인덱스를 구성하는 칼럼의 값을 기반으로 데이터 추출, 인덱스를 읽어 ROWID를 찾고 해당 데이터를 찾기 위해 테이블을 읽음. 일반적으로 인덱스 칼럼 순서로 정렬되어 출력됨. 적은 데이터를 조회할 때 유리함.
1) 랜덤 액세스에 의한 부하가 발생할 수 있고
2) 중복 스캔 비효율이 발생함 - 인덱스 범위 스캔(Index Range Scan): 특정 범위에 인덱스 스캔 적용
- 인덱스 역순 범위 스캔: 리프 블록의 Doubly Linked List 저장 방식을 활용하여 인덱스를 역순으로 스캔, 결과 집합이 내림차순으로 정렬됨 - 인덱스 유일 스캔(Index Unique Scan): 인덱스키가 중복되지 않을 때 단 한 건의 데이터 추출, 등호 조건으로 조회함. 검색 속도가 가장 빠름
- 인덱스 전체 스캔(Index Full Scan): 리프 블록을 모두 읽으며 데이터 추출
- 인덱스 고속 전체 스캔: 물리적으로 저장된 순서대로 인덱스 리프 블록 스캔
- 인덱스 스킵 스캔: 인덱스 선두 칼럼이 조건절에 없어도 활용함, 상위 블록에서 읽은 칼럼 값 정보를 이용해 조건에 맞는 데이터를 포함할 가능성이 있는 리프 블록만 접근
조인 수행 원리
💡 조인이란?
두 개 이상의 테이블을 하나의 집합으로 만드는 연산. SQL문에서 FROM 절에 두 개 이상의 테이블이 나열될 경우 두 테이블 사이에서 조인 수행
💡 NL 조인
프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행. 랜덤 액세스 방식으로 데이터를 읽음.
- 인덱스 구성에 크게 영향을 받지 않음.
- 결과 행의 수가 적은 테이블을 선행 테이블로 선택
1) 선행 테이블에서 조건을 만족하는 행을 찾음
2) 후행 테이블에 선행 테이블의 조인키가 존재하는지 확인함
3) 후행 테이블 인덱스에 선행 테이블의 조인키가 존재하는지 확인함
4) 인덱스에서 추출한 ROWID로 후행 테이블을 액세스함
💡 소트 머지 조인
조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행, 스캔 방식으로 데이터 읽음.
- 넓은 범위의 데이터를 처리할 때 주로 이용
- 정렬 데이터가 많을 경우 성능이 떨어질 수 있음
- 인덱스가 존재하지 않을 경우도 사용 가능
💡 해시 조인
nbsp; CPU 작업 위주로 처리, 해슁 기법 이용, NL Join의 랜덤 액세스 문제와 SMJ의 정렬 작업 부담을 해결하기 위한 대안으로 등장
- 인덱스가 존재하지 않을 경우도 사용 가능
- 결과 행의 수가 적은 테이블을 선행 테이블로 사용
