0.서론
업무중 데이터가 과도하게 많은 테이블을 count()하던중 분명 index컬럼으로 설정되어있었는데 해당 컬럼을 parsing 하여 사용할시에는 indexing이 되지않아 CPU과부하가 왔던 경험에서 DB에서의 index는 어떻게 적용되고 사용되는지 정확히 알아보고싶어서 포스팅하게되었습니다.
1.INDEX란 무엇인가?
DB분야에 있어서 index는 테이블의 동작속도를 높여주는 자료구조를 일컫습니다. index는 테이블에서 여러개 컬럼을 이용하여 생성할수있습니다.
보통 우리는 index를 책의 목차에 비유합니다. 책에 목차가 없다면 독자는 책에서 특정 내용을 찾고싶을때 첫페이지부터 원하는 내용이 나올때까지 계속 책을 넘기며 찾아야할것입니다. 책의 분량이적거나 원하는 내용이 책의 초반부에 있을때는 시간이 적게걸리겠지만 반대로 아주 두꺼운책이거나 책의 마지막부분에 원하는 내용이 있다면 그것을 찾기까지 오랜시간이 걸릴것입니다.
하지만 책에 목차가 존재한다면 책의 분량이 아무리 많더라도 독자는 원하는 내용이 몇 페이지에 있는지 바로 알 수 있습니다. 이처럼 목차는 검색에 소요되는 시간을 비약적으로 줄여줍니다.
CREATE INDEX [인덱스명] ON [테이블명](컬럼1, 컬럼2, 컬럼3.......)
이렇게 인덱스를 만들수있다.
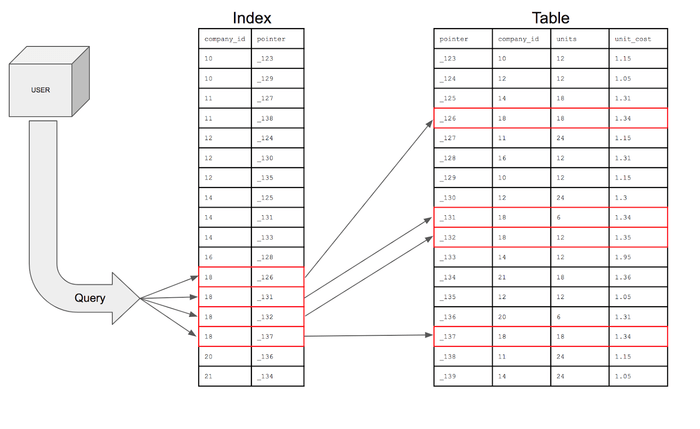
index는 데이터의 주소값을 저장하는 별도의 특별한 자료 구조이며 위의 그림의 USER테이블의 COMPANY_ID 컬럼에 대한 index가 존재한다면 SELECT * FROM USER WHERE COMPANY_ID = ?
쿼리를 수행할때 테이블을 Full Scan 하지않고 해당하는 index를 바탕으로 원하는 데이터의 위치를 빠르게 검색합니다.
약 100만건의 데이터가 존재할때 원하는 데이터를 조회하는데 걸리는 시간이 환경에 따라 검색성능이 적게는 2배에서 많게는 4배 차이가 난다고합니다.
2.INDEX 자료 구조
DB Index에 사용하는 자료 구조는 일반적으로 B-Tree가 있으며 왜 하필 B-Tree인지 탐색시간이 같거나 빠른 자료구조나 알고리즘이 있는데 그것들은 왜 사용하지않는지 알아볼텐데 그전에 B-Tree의 하위 개념인 트리(Tree) 에 대해서 먼저 알아봅시다.
2.1. 자료구조 트리(Tree)란?
Average case of Tree algorithm
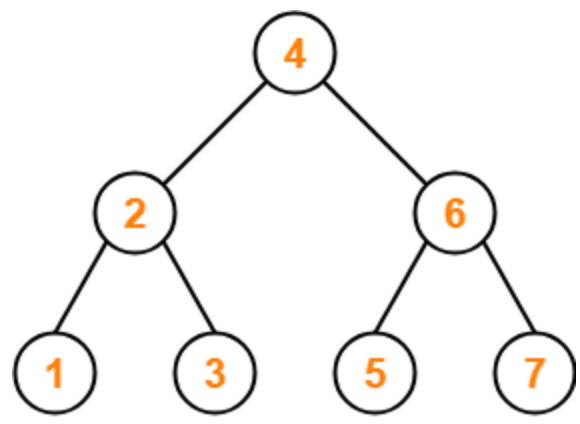
일반적은 Tree는 평균적으로 탐색에 대한 시간 복잡도로 O(logN)을 가진다.
그러나 이것은 지극히 '평균적인' 시간 복잡도이며 최악의 경우에는 이야기가 달라진다.
Worse case of Tree algorithm
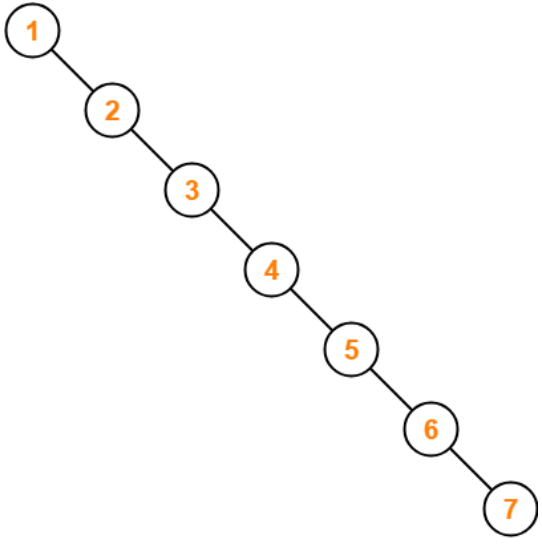
만약 트리 노드의 요소가 위처럼 한쪽 방향으로 쏠려있다면 최악의 탐색 시간은 O(N)을 가지게 된다. 이러한 경우를 방지하기 위해 우리는 밸런스 트리(Balanced Tree)를 이용할 수 있다.
💡 밸런스 트리(Balanced Tree)란?
트리의 노드가 한 방향으로 쏠리지 않도록, 노드 삽입 및 삭제 시 특정 규칙에 맞게 재 정렬되어 왼쪽과 오른쪽 자식 양쪽 수의 밸런스를 유지하는 트리이다. 항상 양쪽 자식의 밸런스를 유지하므로, 무조건 O(logN)의 시간 복잡도를 가지게 된다.
다만 재정렬되는 작업으로 인해 노드 삽입 및 삭제 시 일반적인 트리보다 성능이 떨어지게 된다.
그러므로 밸런스 트리는 삽입/삭제의 성능을 희생하고 탐색에 대한 성능을 높였다고 볼 수 있다.
대표적인 밸런스 트리는 RedBlack-Tree, B-Tree 가 있다.2.2. Hash Table
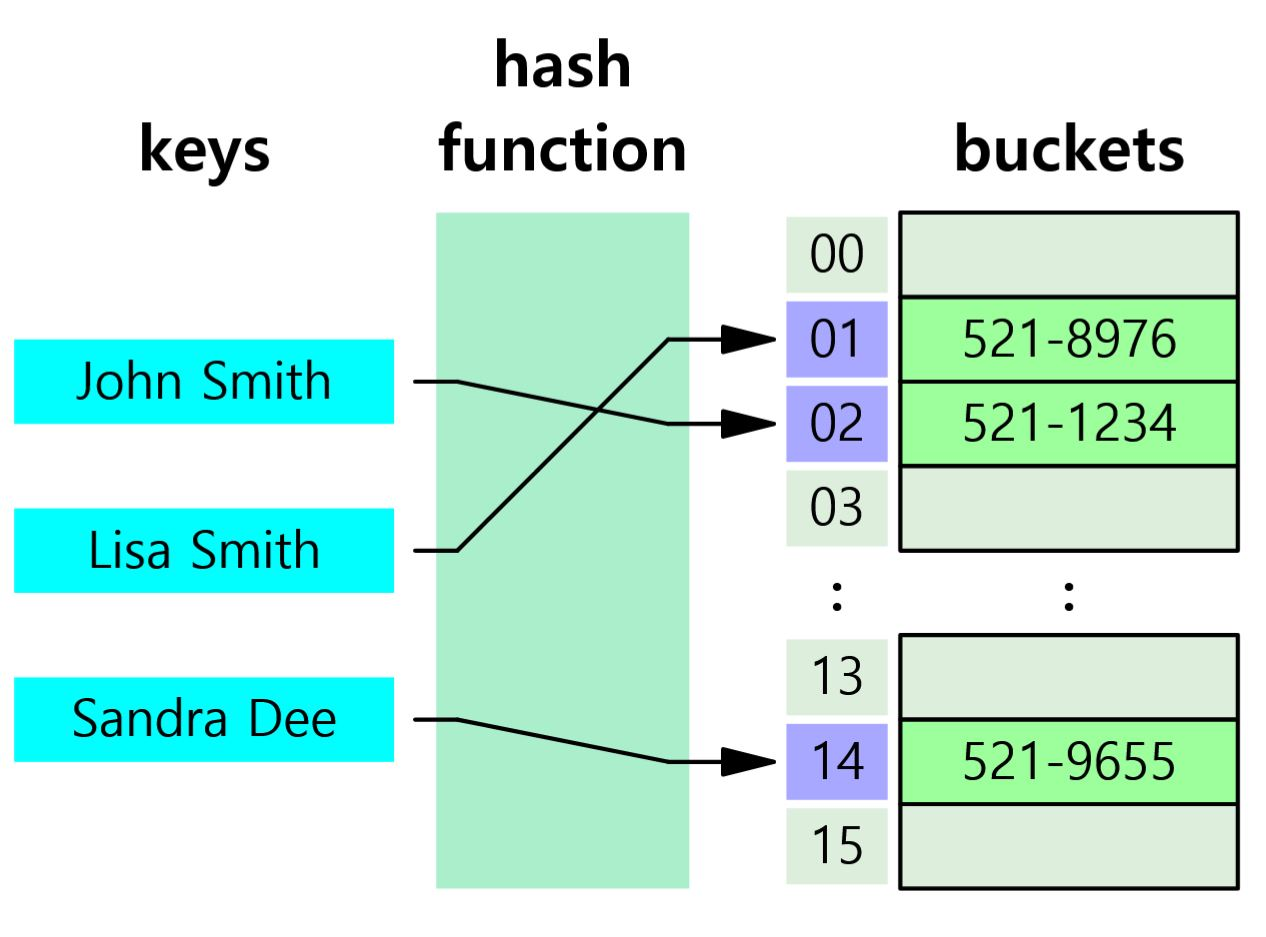
해시 테이블은 Key-Value로 이루어진 데이터를 저장하는데 특화된 자료구조입니다.
해시 테이블 기반의 DB index는 특정 컬럼의 값과 데이터의 위치를 Key_value로 사용합니다.
해시 티에블은 내부에 버켓이라고 하는 배열이 존재해서 해시 함수를 통해 Key를 고유한 해시 값으로 변환시키는데 이를 버켓 배열의 인덱스로 사용하며 해당 인덱스에 Value를 저장합니다.
Key 값으로 Value가 저장되어있는 위치(주소)를 바로 산출할 수 있기 때문에 해시 테이블의 평균적인 시간복잡도는 O(1)입니다. 하지마 해시 함수를 제대로 정의하지 않으면 해시 함수를 통해 산출한 해시 값이 중복되는 해시 충돌이 발생할 수 있고 너무 많은 해시 충돌이 발생하면 검색 성능이 하락해 시간복잡도가O(N)에 수렴할 수 있습니다.
하지만!! 탐색시간이 가장 빠른 해시테이블을 DB index로 사용할수 없는이유
모든 자료 구조와 그 어떤 알고리즘을 비교해도 탐색 시간이 가장 빠른 것은 바로 해시 테이블입낟. 하지만 이것은 온전히 '단 하나의 데이터를 탐색하는 시간' 일 경우에만 적용됩니다.
예를들어 1,2,3,4,5가 저장되어있는 해시 테이블에서 3이라는 데이터를 찾을때만 O(1)이라는 것입니다. (3이라는 데이터를 인풋으로 해시 함수를 통해 나온 해시 값으로 3이 저장된 메모리 공간에 접근을 할것이기 때문) 여기서 이게 무엇이 문제가될까?? 라고 생각한다면
우리는 DB에서 등호(=)만 사용하는것이 아니라 부등호(<,>)도 사용한다는것을 잊으면 안됩니다.
모든 값이 정렬되어있지 않기때문에 해시 테이블에서는 특정한 기준보다 크거나 작은 값을 찾을 수 없습니다. 굳이 찾으려면 찾을수야 있겟지만 O(1)의 시간 복잡도를 보장할 수 없고 매우 비효율적입니다.
그렇기에 기준 값보다 크거나 작은 요소들을 언제나 탐색할 수 있어야 하는 DB index로 해시 테이블은 어울리지 않는 자료구조라고 볼 수 있겠습니다.
아까 밸런스 트리를 살짝 설명하면서 트리의 종류로 B-Tree와 RedBlack-Tree가 있다고 한것을 기억하시나요? B-Tree와 같은 밸런스 트리 종류임에도 RedBlack-Tree는 DB 인덱스로 선택받지 못한 이유를 알아보기전 먼저 이 두 개가 어떻게 다른지 개념부터 보고 가시겠습니다.
2.3. RedBlack-Tree와 B-Tree의 특징 비교
RedBlack-Tree의 특징
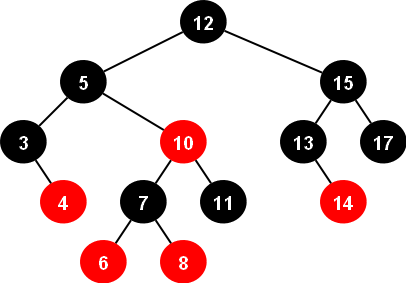
각 노드는 하나의 값만을 가진 상태로 좌,우 자식 노드의 개수를 밸런스를 맞추는데 여기서 빨간색,검은색 노드로 구분되어 있는것은 노드의 삽입/삭제 작업을 할 때마다 규칙에 맞게 재정렬을 하기 위한 수단이므로 여기서는 크게 신경 쓰지 않아도 됩니다.
(RedBlack-Tree에 대해 더 자세히 알고 싶다면 여기를 참조. 개념이 크게 어렵지는 않다.)
B-Tree 의 특징
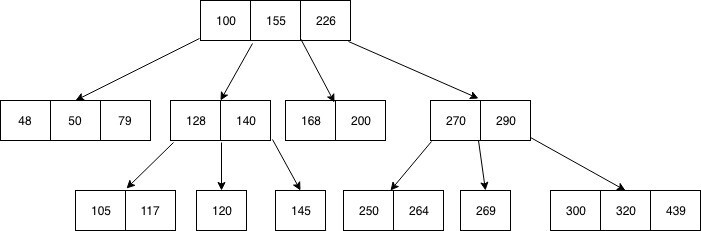
B-Tree는 위처럼 노드 하나에 여러개의 데이터가 저장될 수 있습니다. 각 노드 내 데이터들은 항상 정렬된 상태이며, 데이터와 데이터 사이의 범위를 이용하여 자식 노드를 가집니다. 그러므로 자식 노드의 개수는 (n+1)을 가집니다.
위 두개의 트리는 항상 좌,우 자식노드 개수의 밸런스를 유지하기 때문에 최아의 경우에도 무조건 탐색 시간이 O(logN)을 가지게 됩니다. 이것만 봤을때는 RedBlack-Tree도 DB index로 사용하기에 문제가 없어 보이지만 왜 DB index로 선택받지 못한 것일까요.
2.3.1.RedBlack-Tree가 DB 인덱스로 선택받지 못한 이유
두 자료구조의 가장 큰 차이점은 위의 사진들을 보면 알 수 있겠지만 '하나의 노드가 가지는 데이터 개수'입니다. RedBlack-Tree는 무조건 하나의 노드에 하나의 데이터 요소만을, B-Tree는 하나의 노드에 여러개의 데이터 요소를 저장합니다.

표시한 부분을 보면 마치 배열 처럼 정렬이 되어보이는데 실제로 배열이 맞습니다.
실제 메모리 상에 차례대로 저장이 되어있습니다. 같은 노드 공간의 데이터들끼리 굳이 자식 노드처럼 '참조 포인터' 값으로 접근할 필요가 없습니다.
이는 즉, 같은 노드상 데이터를 탐색할 때는 포인터 접근을 하는 것이 아니라 실제 메모리 디스크에서 바로 다음 인덱스의 접근을 하는 것입니다.
다시 RedBlack-Tree로 돌아가서

RedBlack-Tree는 B-Tree와 다르게 각 노드마다 무조건 하나의 데이터만 가지게 되므로 모든 데이터를 접근할 때 무조건 참조 포인터로 접근을 하게 됩니다. 따라서 B-Tree의 배열 형식의 인덱스 접근과 RedBlack-Tree의 참조 포인터 접근의 시간 차이를 알아야합니다.
둘 다 시간복잡도는 O(logN)이란 것은 변함이 없지만 이것은 '알고리즘 처리에 대한 이론적인 시간 계산 방식일 뿐' 물리적, 절대적인 시간 개념으로는 배열 접근이 훨씬 빠를 수 밖에 없습니다.
참조 포인터로 메모리에 접근한다는 것은 실제 메모리 상 순서대로 저장이 되었든 안되었든 접근하려는 주소를 연산을 통해 직접 알아내어 데이터에 접근한다는 것입니다. 주소를 알아내는데 CPU는 내부적으로 많은 연산을 수행하게 될 것입니다.
이와 반대로 배열은 데이터들이 메모리 공간에 차례대로 저장이 되어 있으므로 접근할 주소를 바로 알 수 있습니다. 그래서 메모리 주소를 알아내는데 성능에 영향이 없습니다.
물론 B-Tree도 자식 노드를 접근할 땐 참조 포인터로 접근을 하지만, 하나의 노드가 가지는 데이터 개수가 많아질수록 포인터 개수는 확연히 줄어들고, 트리 내에서 다루는 데이터가 많아질수록 이러한 차이는 더욱 커질것입니다.
비록 같은 O(logN)이지만, 포인터 접근 수의 차이로 인해 B-Tree가 RedBlack-Tree보다 탐색 시간이 더 빠를 수밖에 없습니다.
솔직히 이 둘의 성능 차이는 웬만한 데이터 개수로는 차이가 없겠지만, 글로벌하게 데이터를 다루는 수준이라면 이러한 차이가 분명 큰 영향이 생길 수 있을것입니다.
위에서 설명한 것 처럼, 같은 밸런스 트리임에도 RedBlack-Tree를 사용하지 않는 이유는 '참조 포인터 접근 수' 때문이었는데요 여기에서 더 나아가서 참조 포인터가 문제라면 그냥 참조 요소가 없는 배열을 쓰면 되지 않을까요??
충분히 요소들이 정렬 상태를 유지하고 있다면 어쩌면 배열로도 무리가 없을 것 같아 보이는데요.
하지만 배열 역시 DB index로 선택받지 못한 이유가 있습니다. 바로 아래에서 알아보겠습니다.
2.4. 데이터 접근이 빠른 자료구조 '배열'이 DB 인덱스로 선택받지 못한 이유

배열은 참조 포인터라는 개념이 없고, 모든 데이터가 메모리 상 차례대로 저장되어 있어 접근이 매우 빠릅니다. 참조가 없으니 당연히 탐색 속도로만 본다면 B-Tree 보다 훨씬 빠릅니다. 뿐만아니라 해시 테이블과는 다르게 데이터들을 정렬 상태로 유지할 수 있으므로 부등호(<,>) 연산에도 문제가 없는데 하지만 배열이 B-Tree보다 빠른것은 탐색 뿐입니다.
배열 내에서 데이터 저장, 삭제가 일어나는 순간 B-Tree 보다 훨씬 비효율적인 성능이 발생합니다.
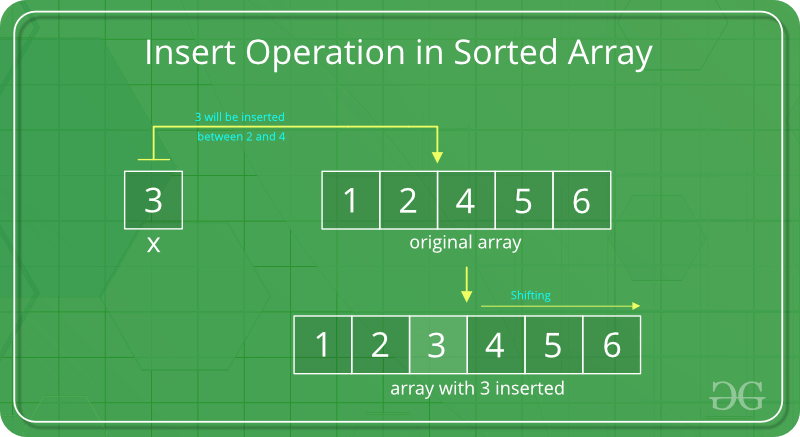
배열 자료구조를 알고있다면 위의 사진이 이해가 가실겁니다.
위 사진처럼 배열 중간에 3이라는 데이터를 삽입하게 되면, 삽입될 해당 자리를 찾은뒤 3보다 큰 데이터들은 한 칸씩 뒤로 물러나게됩니다. 이떄 한 칸씩 이동하는 과정에서 평균 시간 복잡도가 O(N)이 걸리게됩니다. 생각으로는 데이터들이 동시에 한칸씩 뿅~ 하면서 이동하면 될것같지만 실제로는 CPU 연산에 의해 맨 뒤에 데이터부터 시작해서 각 한 칸씩 뒤로 이동하는 작업을 모두 거치게 됩니다.
그나마 새롭게 삽입되는 데이터가 가장 큰 데이터라서 맨 뒤에 저장된다면 O(logN)이 걸리겠지만(탐색 시간이 있기때문에), 최악의 경우 가장 작은 데이터라면, 자리탐색시간인 O(logN)과 맨 앞에 새로운 데이터 삽입을 위해 모든 데이터를 한칸씩 뒤로 이동하는 시간O(N)으로 총 O(N+logN)의 시간이 걸리게 됩니다.
이는 삽입뿐만 아니라 삭제 시에도 동일하게 특정 데이터가 삭제되면 그 데이터가 있던 공간을 메우기 위해 뒤에서부터 한 칸씩 앞으로 이동하는 과정이 발생합니다.
데이터 수정이 일어났을떄도 퀵 정렬, 병합 정렬 등 배열 자료구조에서 재정렬을 이루어야 한다는 점도 있습니다.
2.5. 배열에서 삽입,삭제가 느리다면, 포인터 LinkedList를 사용하면 되지않을까?
LinkedList는 삽입, 삭제 시 중간의 포인터를 잠깐 끊고 추가될 요소 혹은 삭제할 요소를 처리한 다음 다시 포인터로 연결만 하면 되기 때문에 배열에서 가지고 있던 삽입,삭제 문제를 한번에 해결할 수 있습니다.
삽입, 삭제도 빠르니 LinkedList는 충분히 B-Tree를 대체할 수 있지 않을까?
하지만 LinkedList역시 B-Tree를 대체할 수 없는 이유가 있습니다.
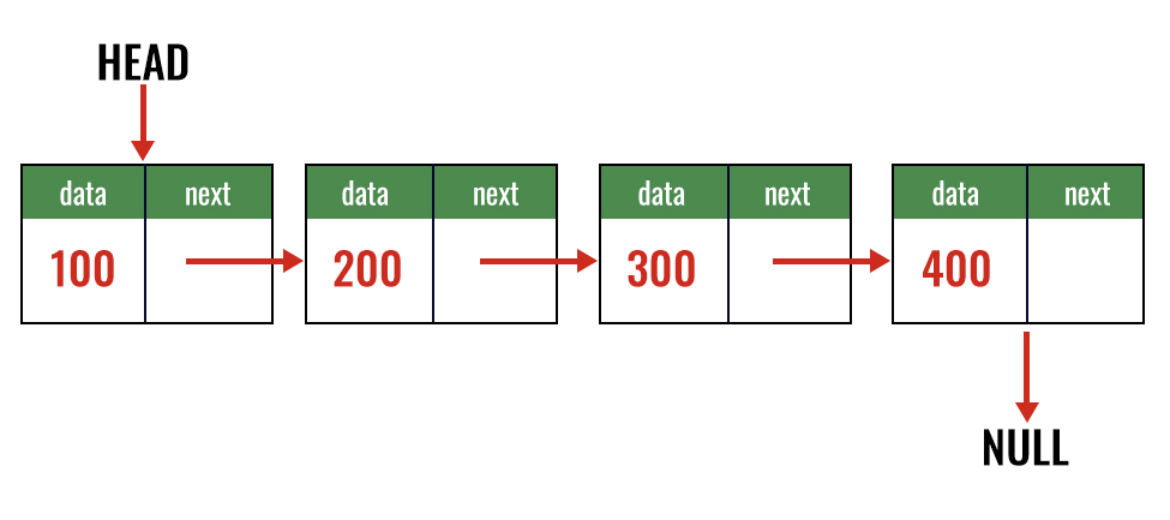
배열이 탐색에서 빠른 이유가 무엇일까?
먼저 배열은 정렬이 된 상태와 되어있지 않은 상태가 있을 것입니다. 정렬이 되어 있다면 이진탐색이 가능하며 이는 O(logN)의 시간을 보장합니다.
이와 반대로 정렬이 되어 있지 않다면 퀵소트, 머지소트 등의 알고리즘을 사용하여 빠르게 정렬시킬수 있습니다.
하지만 이 알고리즘들은 어떻게 돌아가는가?
배열의 총 길이를 미리 알아야 하고, Divided and Conquer가 일어날 때마다 해당되는 Index Number가 파악이 가능해야 하며, Index Number 파악을 위해선 기존에 파악되어있는 다른 IndexNumber 정보들을 이용해 또 다시 계산이 되어야 한다.
LinkedList에 Index Number라는 개념이 있던가?
또한 각 요소에 Index Number 정보들을 추가로 가지고 있다 해도, 그 Index Number로 해당 요소로 바로 접근을 할 수 있는가?
참조 포인터로만 이루어져 있는 LinkedList에서는 이러한 알고리즘을 적용할 수 없습니다.
탐색을 무조건 제일 앞 부분인 HEAD부터 시작해야하는 LinkedList 로서는 DB index로 사용 하기에는 매우 비효율적인 자료구조가 되는 셈입니다.
3. 마지막으로 DB INDEX 용도로 적합한 B-Tree 그리고 B+Tree?
결론적으로 DB index로 B-Tree가 가장 적합한 이유들을 정리하면 아래와 같습니다.
1. 항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없다.
2. 참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다.
3. 데이터 탐색뿐 아니라 삽입,저장,수정 에도 항상O(logN)의 시간 복잡도를 가진다.
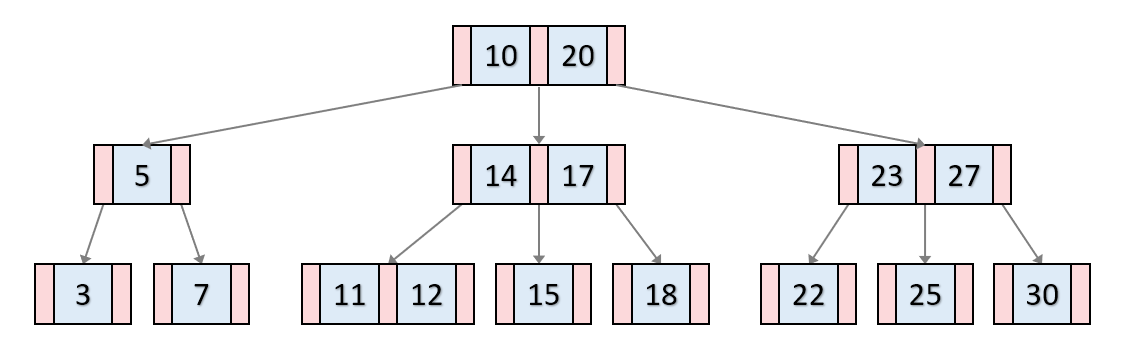
B-Tree란 자식 노드가 2개 이상인 트리를 의미하며, 이진탐색 트리처럼 각 Key의 왼쪽 자식은 항상 Key보다 작은 값을, 오른쪽 자식은 큰 값을 가집니다. B-Tree 기반의 DB index는 특정컬럼의 값(Key)에 해당하는 노드에 데이터의 위치(Value)를 저장합니다.
B-Tree 자료 구조의 상세한 내부 동작 원리는 자료구조 - 그림으로 알아보는 B-Tree
를 참조해주세요.
B-Tree의 Key-Value 값들은 항상 Key를 기준으로 오름차순 정렬입니다. 이로 인해 부등호 연산(>, <)에 대해 해시 테이블보다 효율적인 데이터 탐색이 가능합니다. 또한 B-Tree는 균형 트리(Balanced Tree)로서, 최상위 루트 노드에서 리프 노드까지의 거리가 모두 동일하기 때문에 평균 시간 복잡도는 O(logN)입니다.
그러나 Index가 적용된 테이블에 데이터 갱신(INSERT, UPDATE, DELETE)이 반복되다보면, 트리의 균형이 깨지면서 성능이 악화됩니다.
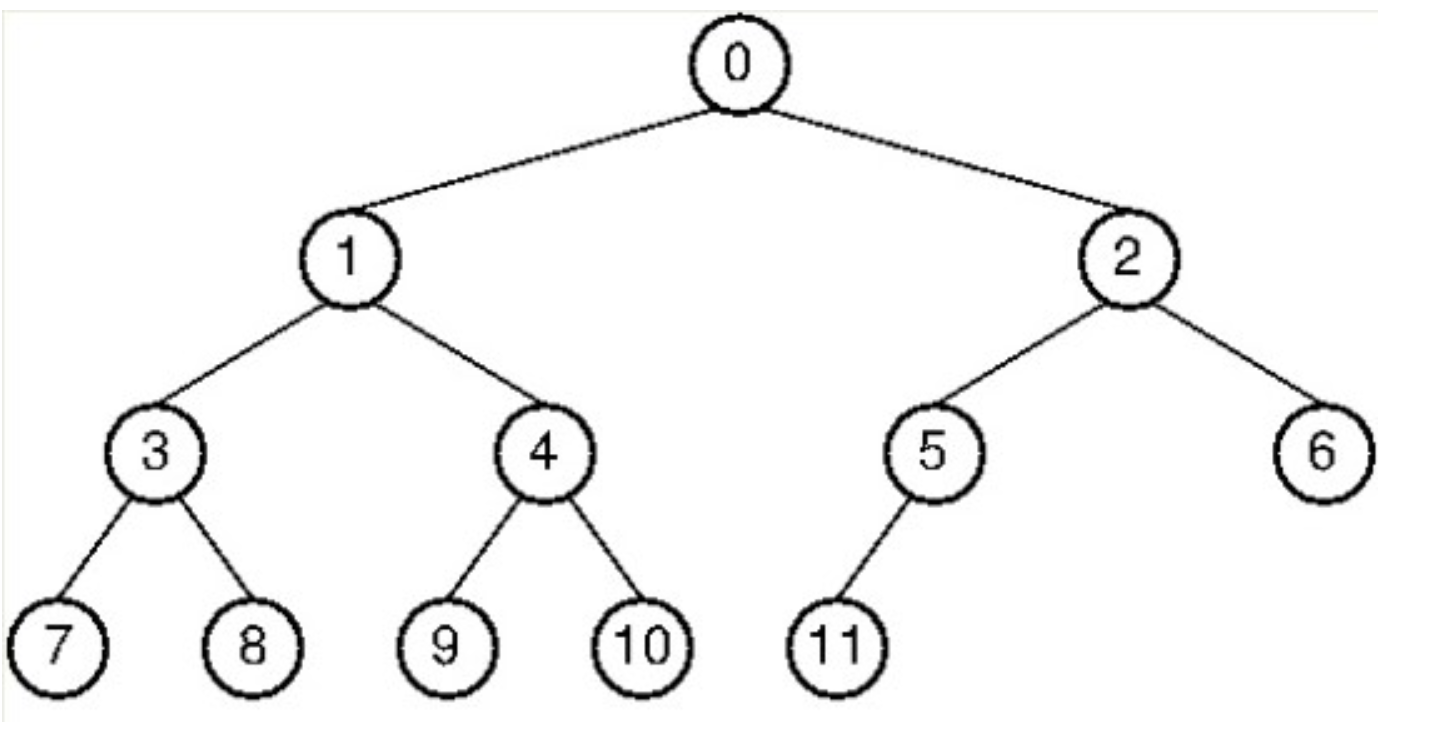
또한 DB Index 컬럼은 부등호(>, <)를 이용한 순차 검색 연산이 자주 발생합니다. B-Tree가 해시 테이블보다 부등호를 이용한 검색 연산 성능이 좋지만, 순차 검색의 경우 중위 순회를 하기 때문에 효율이 좋지 않습니다. 예시의 경우 7->3->8->1->9->4->10->0->11->5->2->6 순으로 조회하는 등 상당히 많은 노드를 확인해야 합니다.
이러한 연유로 MySQL 엔진인 InnoDB는 B-Tree를 확장 및 개선한 B+Tree를 Index의 자료 구조로 사용합니다.
3.1. B+Tree
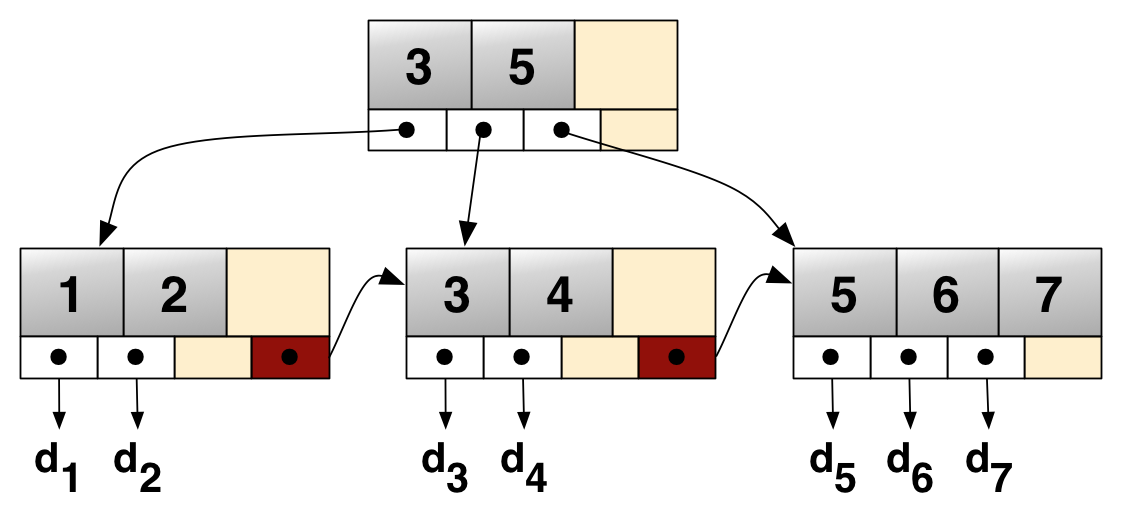
B+Tree는 B-Tree를 확장 및 개선한 자료 구조로서, 말단의 리프 노드에만 데이터의 위치(Value)를 관리합니다. 중간 브랜치 노드에 Value가 없어서 B-Tree보다 메모리를 덜 차지하는 만큼, 노드의 메모리에 더 많은 Key를 저장할 수 있습니다. 아울러 하나의 노드에 더 많은 Key를 저장하는 만큼 트리의 높이가 더 낮아집니다.
또한 말단의 리프 노드들끼리는 LinkedList 구조로 서로를 참조하고 있습니다. 따라서 부등호(>, <)를 이용한 순차 검색 연산을 하는 경우, 많은 노드를 방문해야 하는 B-Tree에 비해 B+Tree는 말단 리프 노드를 저장한 LinkedList를 한 번만 탐색하는 등 속도 이점이 있습니다.
4.고려 사항
이제 index를 사용하면 조회 성능이 우수해진다는 것을 알았습니다. 하지만 무턱대고 아무컬럼에나 index를 적용하는 것은 오히려 성능이 저하되는 역효과가 발생할 수 있습니다.
index는 항상 최신 상태로 정렬되기 위해, 데이터 갱신(INSERT, UPDATE, DELETE)작업에 대해 추가적인 연산이 발생합니다.
- INSERT : 새로운 데이터에 대한 인덱스가 추가됨.
- DELETE : 삭제하는 데이터의 인덱스를 제거함.
- UPDATE : 기존의 인덱스를 제거하고, 갱신된 데이터에 대해 인덱스 추가
앞서 살펴 본 INDEX 트리 자료 구조는 값이 추가 혹은 삭제될 때마다, 트리 균형을 위해 트리 구조의 재분배 및 합병 등 복잡한 연산이 수반되고 균형이 깨질수도 있기때문에 데이터 갱신보다는 조회에 주로 사용되는 컬럼에 INDEX를 생성하는것이 유리하다.
4.1. INDEX 대상 컬럼 선정
일반적으로 Cardinality가 높은 컬럼을 우선적으로 인덱싱하는 것이 검색 성능에 유리합니다. Cardinality란 특정 데이터 집합의 유니크(Unique)한 값의 개수를 의미합니다.
남-여 등 2가지 값만 존재하는 성별 컬럼은 중복도가 높으며 카디널리티가 낮습니다.
개인마다 고유한 값이 존재하는 주민번호 컬럼은 중복도가 낮으며 카디널리티가 높습니다.
Cardinality 높은 컬럼의 경우, Index를 통해 데이터를 더 많이 필터링할 수 있기 때문입니다.
이상으로 DB INDEX에 대해서 알아보았는데 자료 구조에도 비슷한점이 많지만 약간의 특징이 달라짐으로 인해서 용도의 적합성이 구분이 되어버릴 정도로 그 요소 하나하나가 매우 중요한것을 느낄수 있었습니다. 언제나 디테일이 중요한것 같습니다. 그 작은 요소들을 놓치지않도록 최대한 신중하게 선택하도록 하겠습니다.
Reference
DB Index 입문
자료구조 그림으로 알아보는 B-Tree
데이터베이스 인덱스는 왜 'B-Tree'를 선택하였는가
RedBlack-Tree
