강아지의 비문인식 역시 사람의 얼굴을 인식하는 FR에 기반한 프로세스이기 때문에,
업무에 대한 더 깊은 이해를 위해 FR 과정에 대해서 공부하는 시간을 가져보았다.
대략적인 흐름 파악을 위해 survey 논문을 보면서 FR이 어떤 흐름으로 발전해왔는지 파악하고, 최근 경향? 요런걸 파악하는 시간을 가지려고 한다.
선택한 논문은 Deep Face Recognition: A Survey 이다
검색을 하면서 이것저것 보다보니 시각자료도 많고 적당한 깊이로 읽을 수 있을것 같아서 선택하게 되었다.
Race Recognition Process
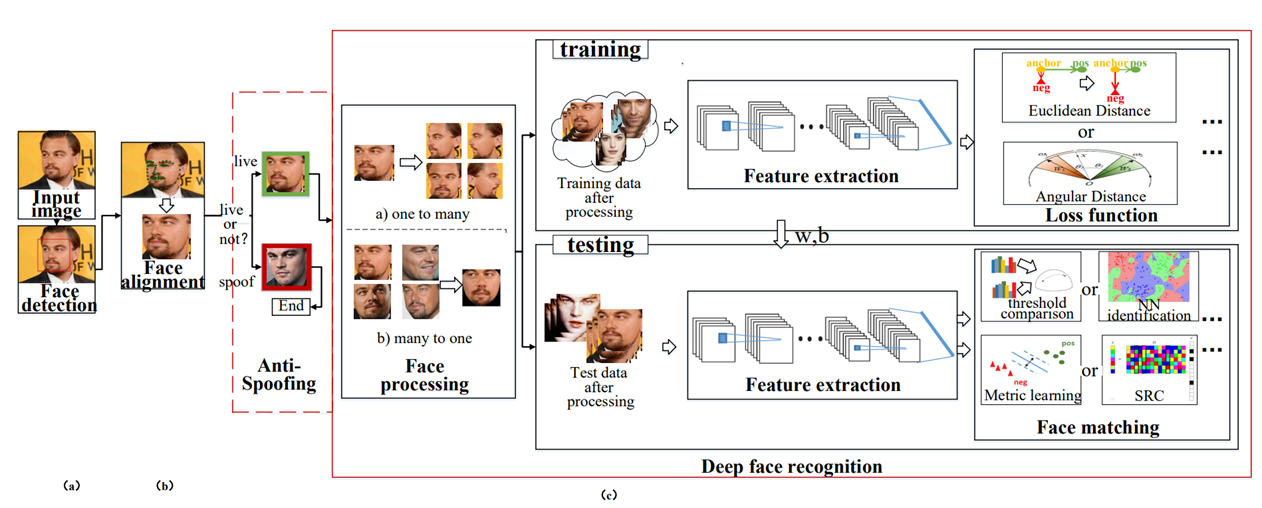
얼굴인식의 전반적인 프로세스이다. 세분화 해보면 1. detection, 2. Anti Spoofing, 3. Face process, 4. featrue extraction, 5. Mathcing 요정도로 분류할 수 있지 않을까 싶다.
1. Face detection
입력된 영상에서 얼굴의 위치를 찾는 과정이다. 입, 눈썹, 코, 턱 등의 특징들을 찾아 얼굴의 위치를 검출하고 해당 위치로 align해주는 과정이다. 이 부분도 정확한 위치탐색을 하게되면 훨씬 복잡한 과정이 있지만, 현재 다루는 내용이 detection이 아니라 recognition이므로 간단하게 요런 과정이구나 정도로 이해하고 넘어갔다. recognition에서는 3d를 활용하는 너무 정교한 alignment까지는 시행하지 않는다고 한다.
2. Anti-Spoofing
뭐하는건지 그림과 설명만 보고 이해가 안되서 따로 찾아봤던 부분이다. spoofing - 직역하면 속이다 즉, Anti-spoofing은 속임수를 방지한다 정도로 번역기 가능할 것 같다.
얼굴에서의 속임수라는게 무엇일까? 찾아보았는데 실제 얼굴이 아닌 가면이나 이미지, 합성 등을 통해 한 속임수를 지칭한다.
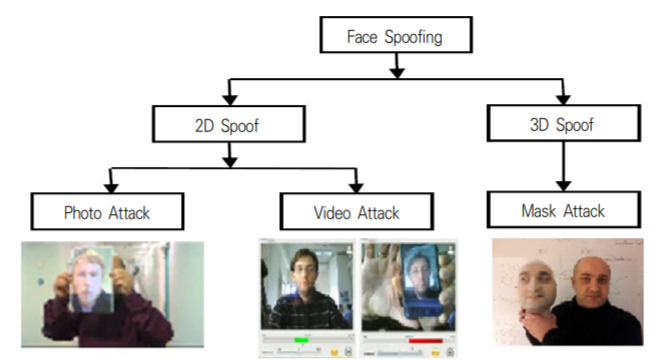
** 이미지 출처: A Comparative Study on Face Spoofing Attacks, ICCCA, 2017
만약 얼굴 인식을 통해 열리는 금고가 있다고 생각해보자.
가장 단순하게 생각하면, 도둑이 금고 주인의 사진을 인쇄해 얼굴 인식기에 보여줬더니 금고가 열리는 일은 일어나면 안될 것이다.
조금 더 복잡한 케이스로 들어가면 얼굴 영상이나, 영상 합성등을 통해 주인의 얼굴을 사칭 할 수도 있고, 3d형태로 주인의 얼굴모형을 만들어 가면을 통해 주인을 사칭 할 수도 있다.
이런 속임수 행위를 Spoofing이라고 규정하고, 이런 속임수 여부를 방지하고자 하는것이 Anti-Spoofing의 과정이다. 더 깊게 들어가면 이 또한 하나의 깊은 연구 분야 이므로 이정도로만 이해하고 넘어갔다.
3. FaceProcessing
합성이나 속임수가 아닌, 정상적인 얼굴이라고 판단이 될 경우에는 얼굴에 대한 전처리 과정을 진행한다.
전처리 과정이 왜 필요할까?

** 이미지 출처 : 구글 이미지 검색
모든 환경이 동일한 상태에서 매번 이미지 촬영이 이루어진다면, 당연히 이런 과정은 필요 없을것이다. 하지만 현실세계에서는 얼굴인식을 힘들게하는 다양한 문제점들이 존재한다.
논문에 소개된 대표적인 4가지 케이스를 정리해보았다.
Pose
뭐라고 번역해야 할지 모르겠어서 일단 자세라고 직역해보았지만 사실 사진이 찍히는 그런 각도? 를 지칭한다고 이해하는것이 자연스러울것 같다. 그냥 포즈라는 표현이 제일 자연스러운것 같기도하고..
사진이 찍히는 포즈에 따라서 보여지는 이미지가 달라지게 된다. 정면이냐 측면이냐 각도에 따라 동일한 사람이어도 다른 형태의 데이터로 표현 될 수 있기에 인식에 어려움을 겪는다.
Expression
위에서 제시한 pose의 문제점을 해결해 같은각도에서 같은포즈로 사진을 찍었다고 가정하자.
그래도 사람이 짓는 표정에 따라서 얼굴의 형태는 달라질 수 있고, 이는 얼굴인식의 난이도를 높인다.
Occlusion
뭐라고 번역해야할지 참 어려웠던 단어이다. 사전에 검색을 해보면 의학용어도 폐색이라고 나오던데 서치를 하다보니 FaceRecognition쪽에서는 자주 사용하는 표현인것 같다.
썬글라스나 마스크, 스카프 등으로 얼굴이 가려지는 그런 현상을 표현한다.
Illumination
조명에 따라서 얼굴의 일부분이 어둡게 나오거나 그림자가 지는 문제가 발생 할 수 있다. 절반만 인식되는 이미지형태로 비교를 하게되면 올바른 인식 결과가 나오긴 힘들 것이다.
이런 점들을 해결하기 위해 Processing의 과정을 거친다.
그럼 이 문제점들을 어떤식으로 해결하나?
물론 이 또한 깊이 들어가면 각각 문제들이 하나의 연구주제로 깊은 영역이 되기에 간략하게 통상적인 개념만 적어보겠다
one to many
하나의 입력 이미지로부터 여러 포즈의 이미지를 만들어내는 agumentation 과정이다
하나의 얼굴로 찍힐 수 있는 다양한 형태의 이미지들을 학습 데이터로 만들어 함께 학습시킴으로써 여러 변화에 robust한 모델을 만들어 낼 수 있게 된다.
many to one
반대로 여러개의 이미지를 정규화시켜서 하나로 만들어주는 과정이다.
여러개를 하나로 압축하는건가? 라는 생각이 들어서 헷갈렸던 부분인데, 압축한다기 보다는 모든 사진들을 nomalization해서 input으로 넣는다고 이해하면 될 것 같다.
요렇게 처리를 해주면 오히려 특정 normal한 상황만 인지할 수 있는 더 성능 안좋은 모델이 되는것 아닌가? 하고 생각할 수도 있지만, test시에도 똑같은 과정으로 input값을 normalize 해줘서 집어넣게 된다. 따라서 다양한 환경적 요소들을 배제하고 이미지가 누구인지에 대해서만 집중하게 해주는 그런 과정이라고 보면 될 것 같다.
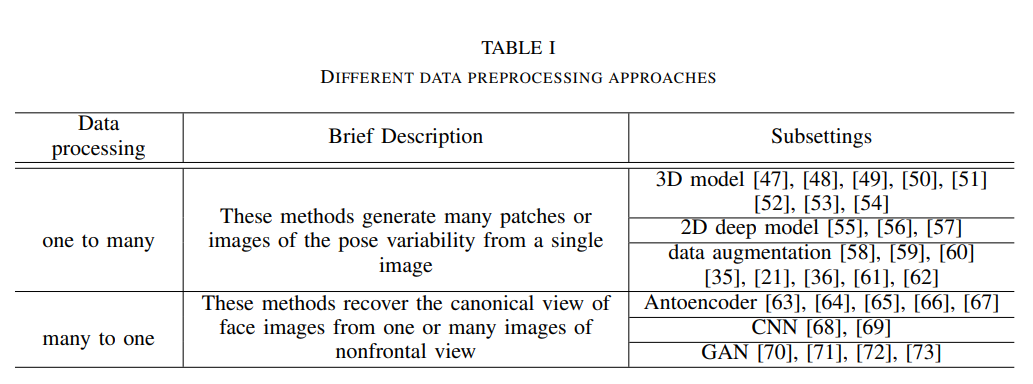
더 깊은 수준이 궁금하다면 함께 소개된 논문들을 찾아보면 좋을 것 같다.
4. feature extraction
사실 앞 과정까지는 원활한 face recognition을 전처리 과정이었고 여기서부터 진짜 인식에 대한 처리이지 않을까 싶다.
input 이미지로부터 특성을 뽑아내 숫자로 만들어주는 과정이다.
AlexNet의 등장을 시작으로 다양한 CNN 기반 네트워크들이 등장했고 현재도 지속적인 연구가 이루어지고 있는 주제이다.

이 논문에서 소개된 내용은 이정도가 있다. survey 논문 답게 개별적인 아키텍쳐들을 모두 설명하지는 않고 소개정도만 하고 넘어간다. 주요 네트워크들은 뒤에서 하나씩 정리해보겠다.
층을 구성하고, 원하는 로스함수를 구성해서 신경망을 학습 시켜 얼굴인식 모델을 만들어 낼 수 있다.
로스함수의 구성에 따라 신경망의 목표가 정해지고, 학습 방향이 결정되기 때문에 로스함수를 어떻게 구성하는지는 굉장히 중요한 요소이다.
유클리드 거리를 기반으로 하는 함수부터 시작해 각도의 관점에서 접근하는 angular 기반의 로스함수까지 다양한 방법들이 등장했다. 주요한 로스들은 뒤에서 다뤄보도록 하겠다.
5. matching
구조와 로스함수를 구성하고 데이터를 통해 학습을 진행하였다면 완성된 신경망을 얻었을 것이다.
이제 이 신경망에 인식하고자 하는 이미지를 넣어 output으로 값이 나오면, 해당 output을 통해 내가 찾는 사람이 맞는지 비교를 할 수 있다. 비교의 기준으로도 다양한 방법들을 채택 할 수 있으며, feature간의 distance를 통해 비교를 진행한다.
이 수치를 이용해 적정 threshold 값을 설정하고 특정 값 이상이면 같은 인물로 판단하고, 특정 값 이하이면 다른 인물로 판단하는 등 verification, identification 으로 활용 가능하다.
여기까지가 전반적인 FaceRecognition 의 프로세스를 간단하게 설명한 내용이다.
대략적으로 이런 프로세스로 인식이 진행되는구나 를 이해하면 내가 하는 업무가 어디에 쓰이는 건지 바라보는 눈을 넓힐 수 있을것 같다.
각각의 프로세스가 하나의 연구분야이기 때문에 전부 깊게 들어가기에는 무리가 있을것 같고, 당장 나에게 필요한건 아키텍쳐와 로스함수에 대한 안목일것 같으니, 다음번에는 CNN 모델들의 발전 흐름에 대해서 파악하고 정리해봐야겠다.
