Focal loss란?
이론
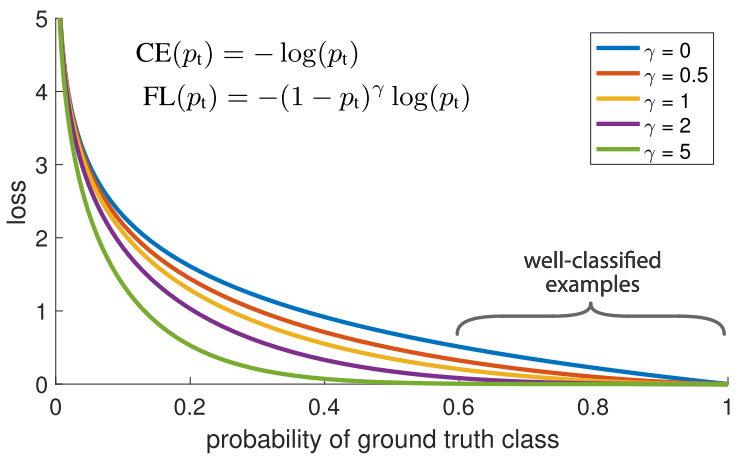
간단히 설명하면 잘 분류한 클래스에 대해서는 loss를 적게줘서 loss 갱신을 적게하고
못 분류한 클래스에 대해서는 loss를 크게줘서 loss 갱신을 크게 만든다
--> 그 차이는 gamma로 조절한다.
ex) A,B,C 클래스 중 A는 분류하기 쉽고 B,C는 분류하기 어려울 경우
epoch 100중에서 10만에 A는 99%의 정확도에 도달했다고 하자.
이럴경우 남은 90번의 epoch동안에는 B,C에 더 집중해서 loss를 계산해 전체 정확도를 높인다!
출처 - https://towardsdatascience.com/handling-imbalanced-datasets-in-deep-learning-f48407a0e758
결론
잘 찾지 못하는 클래스에 대해서 더 집중 학습을 시켜서 전체 정확도를 높인다!

jooooon