
문제
https://leetcode.com/problems/group-anagrams/
풀이 1
단어에 쓰인 문자별 개수를 카운팅해서 비교하는 방식을 생각해보았다.
카운팅할때 메모리 사용을 줄이기 위해 int형이 아닌 char형을 사용하려다보니 코드가 복잡해졌다
defaultdict는 원래 잘 안쓰던애였는데 최근에 몇번 쓰다보니 또 익숙해져서 유용하게 쓰고있는것같다
배열형태로는 처음 써봤다
ord : char -> ascii
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
d = defaultdict(list)
for word in strs:
temp = ['0' for i in range(26)]
for i in word:
temp[ord(i)-ord('a')] = str(int(temp[ord(i)-ord('a')]) + 1)
d[' '.join(temp)].append(word)
return [val for val in d.values()]결과
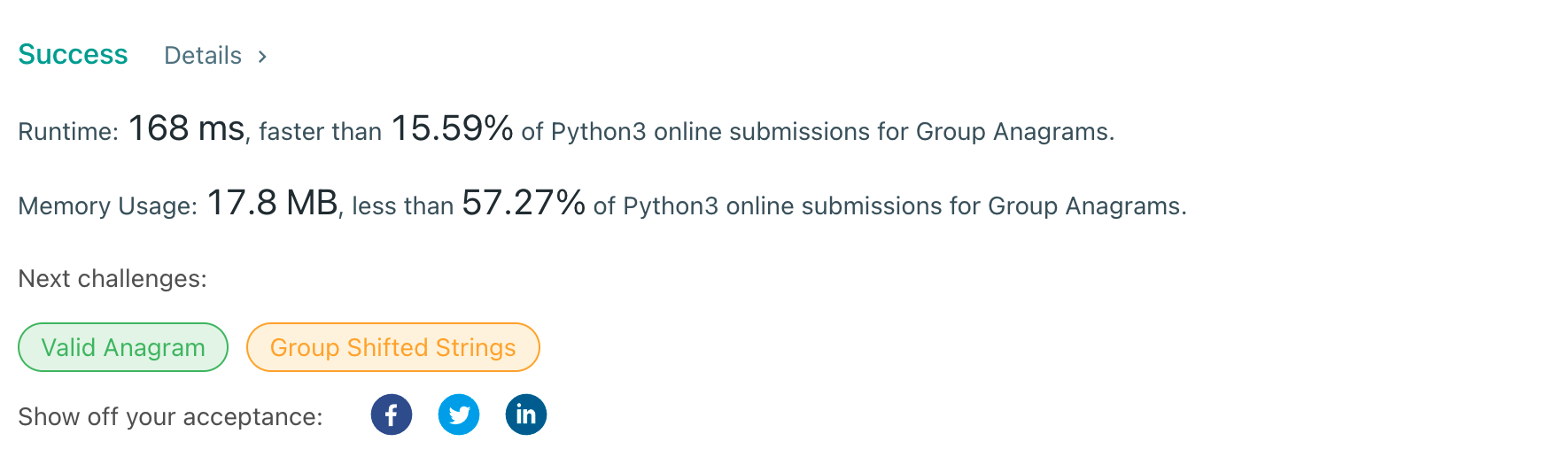
생각보다 너무 느리게 나온다 그래서 다른 풀이를 생각해봤다
풀이 2
단어마다 정렬해서 비교하는 방식을 선택했다.
사실 이게 더 오래걸리지 않을까 생각하고 1번 풀이를 했던거였는데 1번이 너무 오래걸린 관계로 일단 해봤다
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
d = defaultdict(list)
for word in strs:
d[''.join(sorted(word))].append(word)
return d.values()
결과2
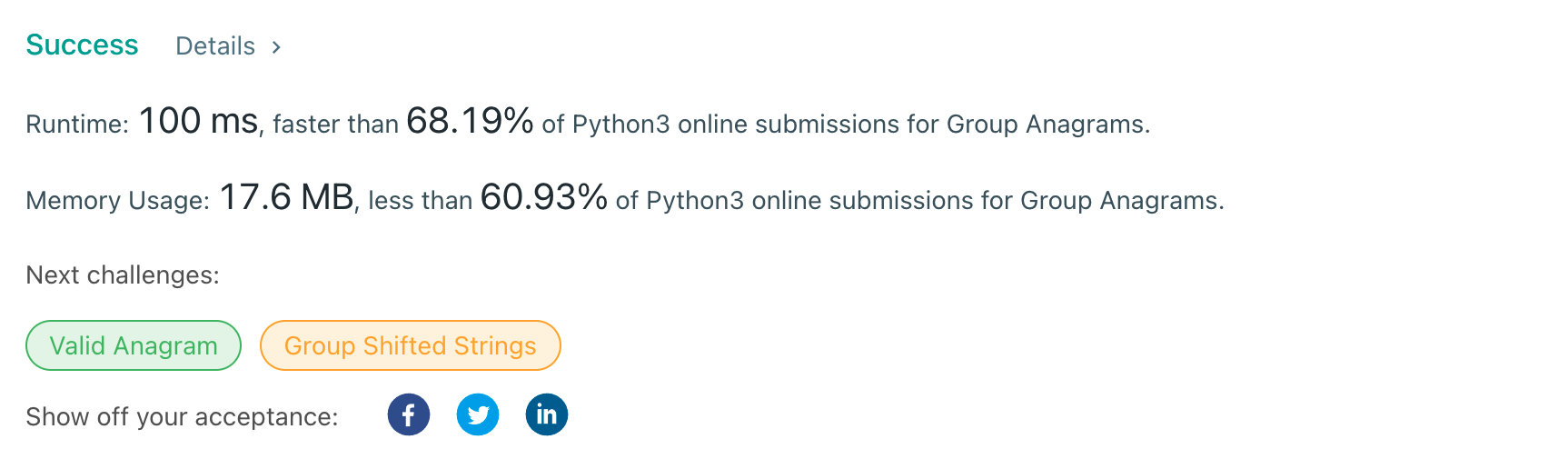

jooooon