분류 알고리즘
개요
머신러닝을 배울 때 가장 먼저 접할 수 있는 분류 알고리즘에 대해 정리해 보았습니다.
분류 알고리즘은 학습 데이터로 주어진 데이터의 피쳐와 레이블값을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 모델에 새로운 데이터가 주어졌을 때 미지의 레이블 값을 예측하는 것입니다.
분류는 다양한 머신러닝 알고리즘으로 구현할 수 있습니다.
- 베이즈 통계와 생성모델에 기반한 나이브 베이즈
- 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀
- 데이터 균일도에 따른 규칙 기반의 결정 트리
- 개별 클래스 간의 최대 분류마진을 효과적으로 찾아주는 서포트 벡터 머신
- 근접거리를 기준으로 하는 최소 근접 알고리즘
- 심층 연결 기반의 신경망
- 서로 다른 머신러닝 알고리즘을 결합한 앙상블
분류만 해도 종류가 너무나도 많죠....
이 책에서는 앙상블 방법을 집중적으로 다룹니다. 하지만 그전에 결정트리가 무엇이고 어떤 특성이 있는지 알아보도록 하겠습니다.
결정트리
머신러닝 알고리즘 중 가장 직관적으로 이해하기 쉬운 녀석입니다. 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만듭니다.
다음 그림은 결정 트리의 구조를 간략하게 나타낸 것입니다.
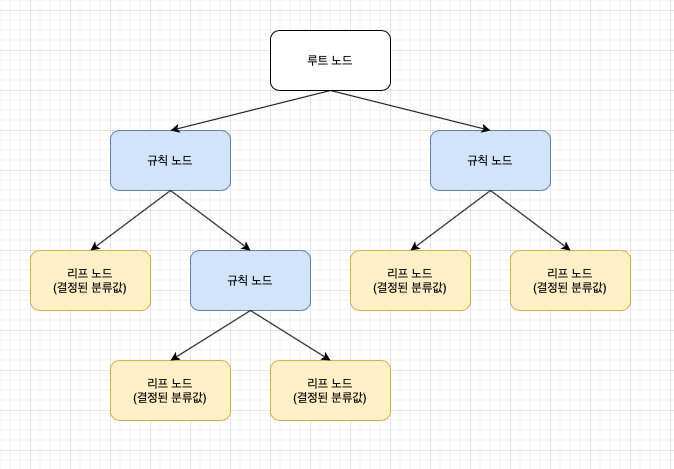
규칙을 쉽게 표현하자면 코딩할때의 그 if/else 기반으로 나타내는 것입니다. 또는 더 쉽게 스무고개로 생각하셔도 좋습니다. 스무고개에서 가장 중요한 것은 핵심 질문을 하는 것인데, 마찬가지로 결정트리에서도 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우합니다.
분류를 할때 최대한 많은 데이터가 해당 분류에 속할 수 있도록 하려면 트리는 최대한 균일한 데이터 세트를 구성할 수 있도록 분할하는 것이 필요합니다.
잠깐, 여기서 균일한 데이터란?
데이터 세트 안의 데이터 정보가 들쭉날쭉 하지 않고 쉽게 예측 가능한 데이터를 말합니다. 예를 들어 데이터 세트를 공주머니라 하고 공을 데이터라 하면, 빨간색공이 들어있는 균일한 공주머니는 별다른 정보가 없어도 빨간공이 나와야한다는 것이죠. 만약 주머니에서 공을 뽑을때마다 다른색의 공이 나온다면 균일하지 않다는 뜻입니다.
그럼 데이터가 균일한지 아닌지 어떻게 측정할까요?
정보의 균일도를 측정하는 대표적인 방법은 엔트로피를 이용한 정보 이득(Information Gain) 과 지니계수가 있습니다.
정보이득
정보이득은 엔트로피라는 개념을 기반으로 합니다. 엔트로피는 쉽게말해 주어진 데이터 집합의 혼잡도를 의미하는데 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여있으면 엔트로피는 낮습니다. 정보이득 지수는 1에서 엔트로피를 뺀 값 즉, 1 - 엔트로피 지수 입니다. 결정트리는 정보이득이 높은 속성을 기준으로 분할합니다.
지니계수
지니계수는 원래 경제학에서 불평등 지수를 나타낼때 사용하는 계수인데, 0이 가장 평등하고 1로 갈수록 불평등합니다. 결정트리는 지니계수가 낮은 속성을 기준을 분할합니다.
결정트리는 이 기준을 토대로
1. 데이터 집합의 모든 아이템이 같은 분류에 속하는지 확인이 되면
2-1.리프 노드를 만들어서 분류를 결정합니다.
2-2.만약 아닐경우 분할하는데 가장 좋은 속성과 분할기준을 찾고
3.분할하여 Branch노드를 만들고 그 노드에 대해 재귀적으로 1부터 과정을 반복합니다.
다음은 결정 트리 모델의 특징에 대해서 살펴보겠습니다.
