출처
https://www.youtube.com/watch?v=WWaPGDS7ZQs
SK Tech Summit을 보고 개인적으로 정리한 내용.
LLM에 관련된 논문이나 이론적으로 정리된 내용들은 많지만 실제 기업에서 어떻게 접근하는지가 궁금했는데 도움이 많이 되었다.
OpenSource VS Closed Source
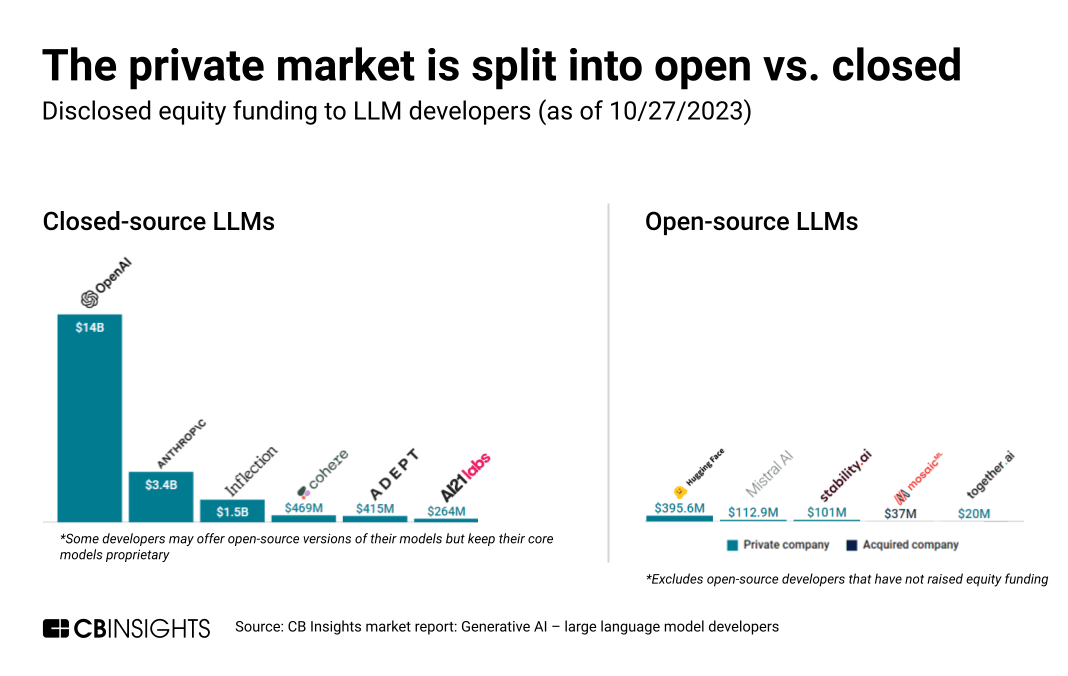
- open source
장점: 성능이 뛰어남, API 형식으로 사용하기 용이함
단점: 보안을 보장할 수 없음. API 호출 비용 - closed source
장점: 상대적으로 높은 보안성. 낮은 비용
단점: 개발 난이도 높고 전용 GPU 서버 필요
PEFT VS RAG
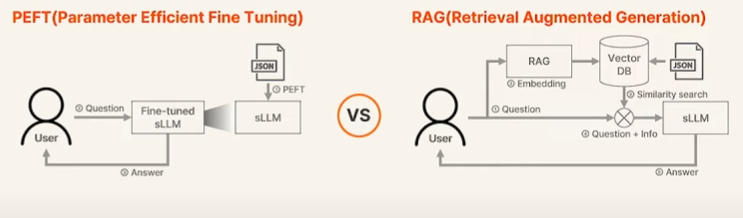
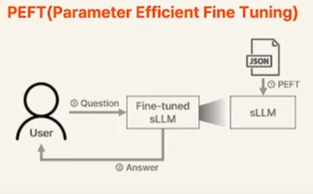
- PEFT (Parameter Efficient Fine Tuning)
일반적인 Fine Tuning 방법인데, 요즘 LLM은 너무 모델이 커져서 일부만 파라미터 튜닝하는 방법 - RAG (Retrieval Augmented Generation)
벡터 DB를 가지고 유사도 기반 검색을 이용하는 방법
PEFT
Augmentation

문장의 순서와 구조를 랜덤하게 변화시켜서 augmentation을 수행

위와 같이 똑같은 Q&A라도 다양한 형태의 데이터로 증강할 수 있다
Model

KoAlpaca, KoVicuna, KuLLM 등 한글 기반의 LLM 모델들을 사용했다고 함. 전부 Billion급 파라미터를 가지고 있는 sLLM(small Large Language Model)이다.
KoAlpaca는 한국어 sLLM에서 일반적으로 사용되는 Base급 모델이고, KuLLM은 이보다 정보가 적지만 벤치마크 상에서 좋은 성능을 보여줬다고 한다.
PEFT와 LoRA
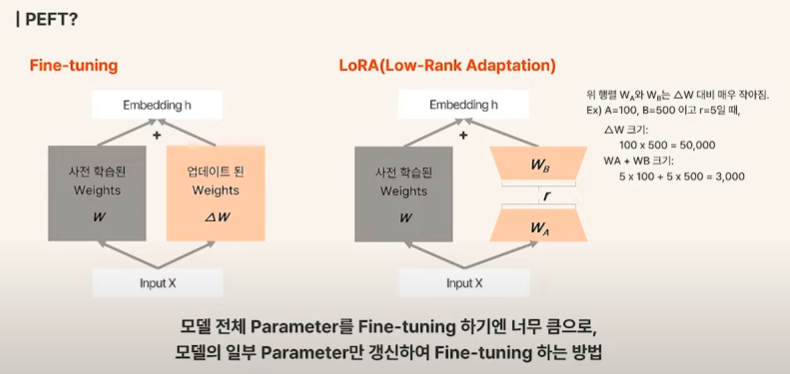
LLM은 워낙 모델이 크다보니 Fine Tuning 조차도 어려워서, 일부 파라미터만 갱신하는 방법인 PEFT를 적용한다고 한다. 이에 대한 자세한 설명은 다른 포스트에서 작성해볼 예정이다.
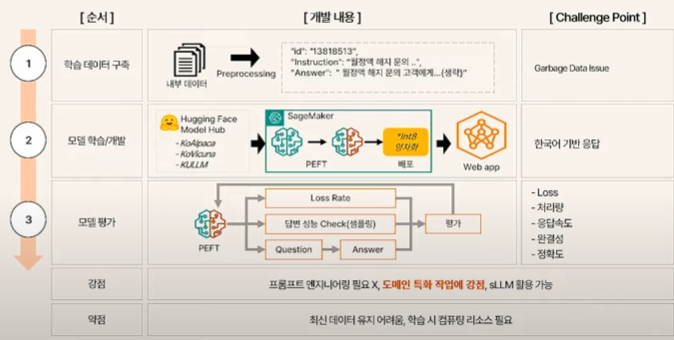
- 적절한 포맷(JSON 등)으로 전처리
- Hugging Face에서 모델과 pretrained weight를 가져온다
- AWS SageMaker를 이용하여 PEFT와 quantization 및 배포를 진행한다.
이러한 구조는 특정 도메인에 특화된 작업에는 강점을 가지지만, 최신 데이터 유지에는 좋지 않다고 한다.
RAG
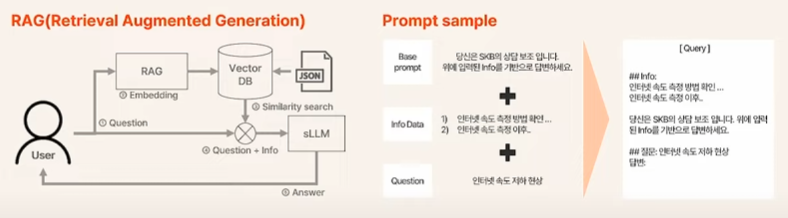
- 사전에 준비된 JSON 데이터로 VectorDB를 구축함
- 유저의 질문을 Embedding한 Vector를 가지고 VectorDB에서 Similarity Search를 하여 관련된 질문에 대한 Context Data를 가져온다.
- 유저의 질문 + Context Data를 sLLM에 입력하여 최종적인 Answer를 받는다.
즉, 질문과 함께 사전지식을 같이 전달하여 특정 도메인에서도 잘 동작하도록 만드는 것이다.
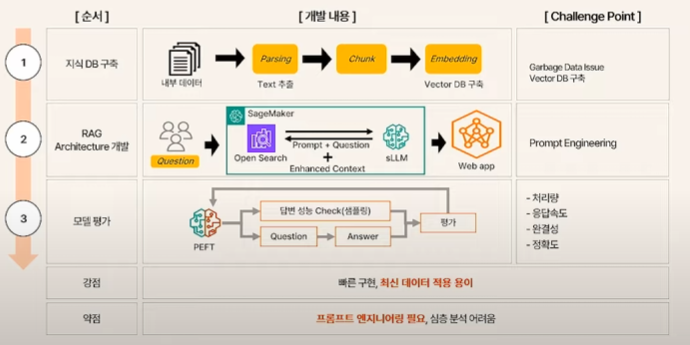
RAG를 적용한 구조는 다음과 같다.
1. 내부 데이터를 파싱하여 Vector DB를 구축한다.
2. AWS Sagemaker 내에서 OpenSearch를 이용해 위에서 설명한 RAG 기반 방식을 구현한다.
더 구현이 빠르고, 최신 데이터 적용에도 용이하다고 한다.
PEFT VS RAG
여기까지 정리했을때 느낀점은, 만약에 둘 중 하나만을 선택해야 한다고 하면
빠르게 PoC 및 구현해야 하는 스타트업에서는 RAG
더 높은 성능을 끌어내고 싶은 대기업에서는 PEFT
가 적절하지 않을까라고 생각하였으나, SK에서는 PEFT, RAG를 둘 다 hybrid하여 사용했다고 한다.
결과 분석
Base Model과 Data 준비
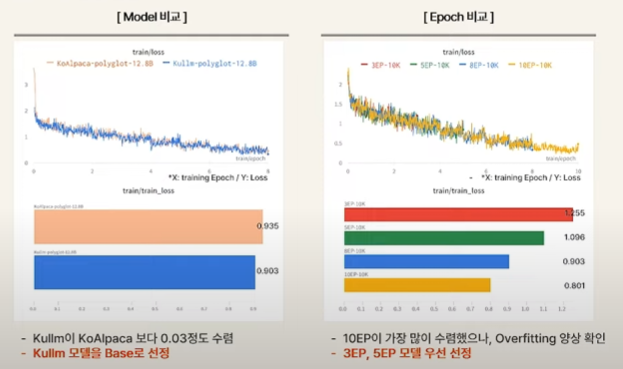
Base model로는 Kullm으로 3ep, 5ep 정도 학습된 모델을 선정했다.
LLM 경험이 많지 않은 나로서는 3epoch, 5epoch 정도라는 단위가 작다고 느꼈는데... 일반적으로는 비젼이 자연어보다 데이터 크기가 훨씬 큰데도, L(Large)LM이다 보니 모델과 데이터가 커서 그런 것 같다. 10 epoch 정도에서도 overfitting이 발생했다고 한다.
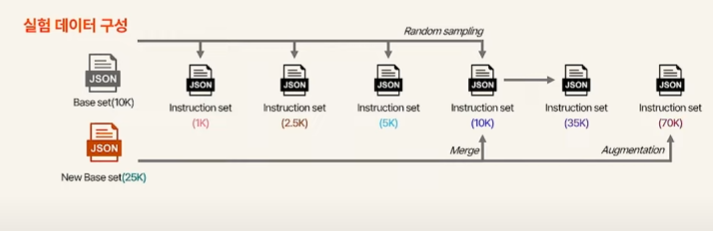
기본 10k 데이터셋에서 augmentation을 통해서 70k까지 데이터를 늘렸다고 하며, 이를 Base data로 선정
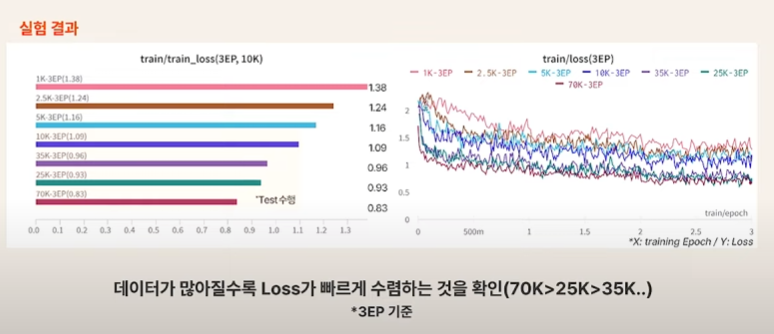
데이터가 많아질수록 loss가 빠르게 수렴한다고 한다. 보통 under fitting되는 경우가 아니라면 train loss는 epoch 올라갈수록 계속 감소하는 경향이긴 하다.
Augmentation의 영향
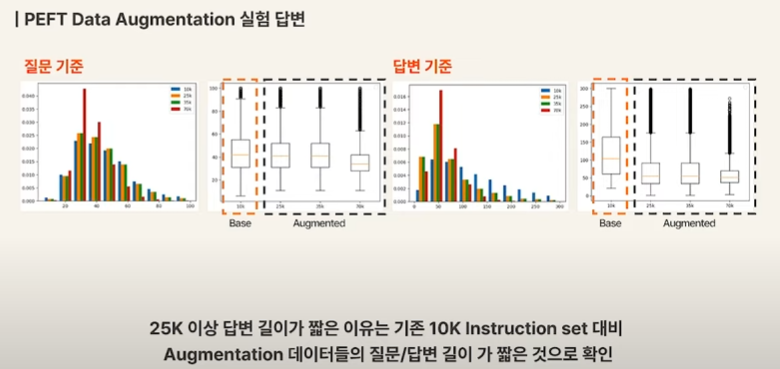
증강된 데이터는 실데이터가 아니라 생성된 데이터다보니 결과에 좋지 않은 영향을 끼칠 수도 있다. augmentation data의 질답 길이가 짧아서 추론 결과에서도 질답 길이가 짧아지는 현상이 있었다고 한다.
RAG + PEFT
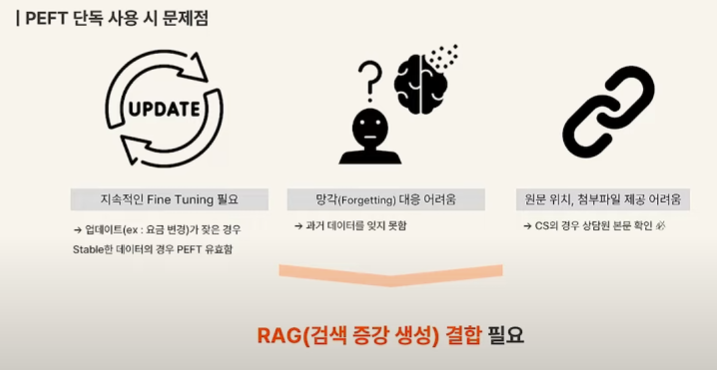

RAG와 PEFT의 장점을 둘 다 취하기 위해 둘을 결합한 아키텍쳐를 시도했다고 한다.
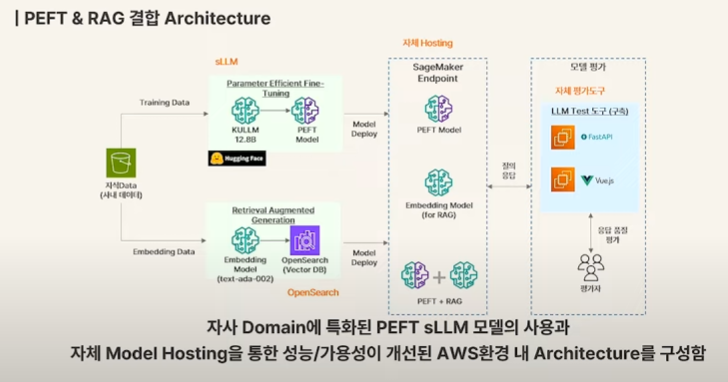
사내 데이터 기반으로 두 방식에 대해 model 구축하여 deploy하고 이를 fastAPI, Vue.JS 로 평가자가 쓸 수 있게 툴을 만든 듯 하다.
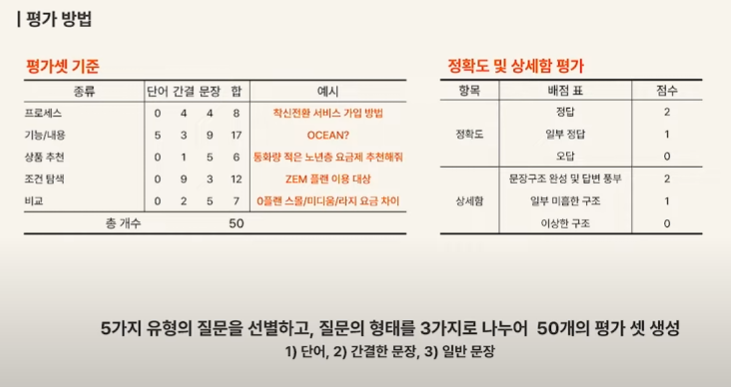
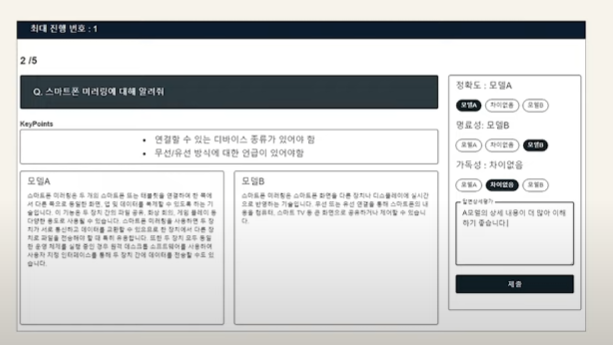
만들어진 상담 봇에 대한 평가는 이를 실제로 사용한 평가자들의 설문 방식으로 진행
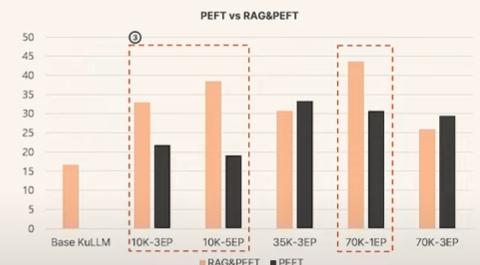

결과는 PEFT 모델을 단독으로 쓰는 것보다는 PEFT모델을 RAG에 결합한 방식이 더 좋다고 한다.
정리
위 내용을 참고하여 LLM기반 서비스를 실제로 구현한다고 했을때 순차적으로 어떻게 구성하는 것이 좋을지 정리해보았다.
-
RAG
OpenSearch와 VectorDB 등을 이용하여 RAG 환경을 구축한다.
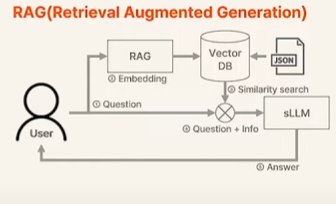
-
PEFT
Llama 등의 오픈소스 모델과 현재 가지고 있는 도메인 데이터를 기반으로 PEFT 적용하여 파인튜닝한 모델을 만든다. 이 모델을 위에서 구축한 RAG 환경에 deploy 한다.
-
Augmentation
필요에 따라 데이터 증강으로 추가 데이터 셋을 만들어서 학습한다. -
Serving
이렇게 만들어진 아키텍쳐를 SageMaker, Triton 등 이용하여 모델 서빙