학습주제
간단한 ETL 만들기
학습내용
csv 파일을 받아 redshift 테이블로 로딩.

스키마가 기본적으로 만들어져 있고,
나만의 스키마 - kjw9684k로 1개 만들어져 있음.
앞으로 본인 스키마 밑에 테이블 만들 예정
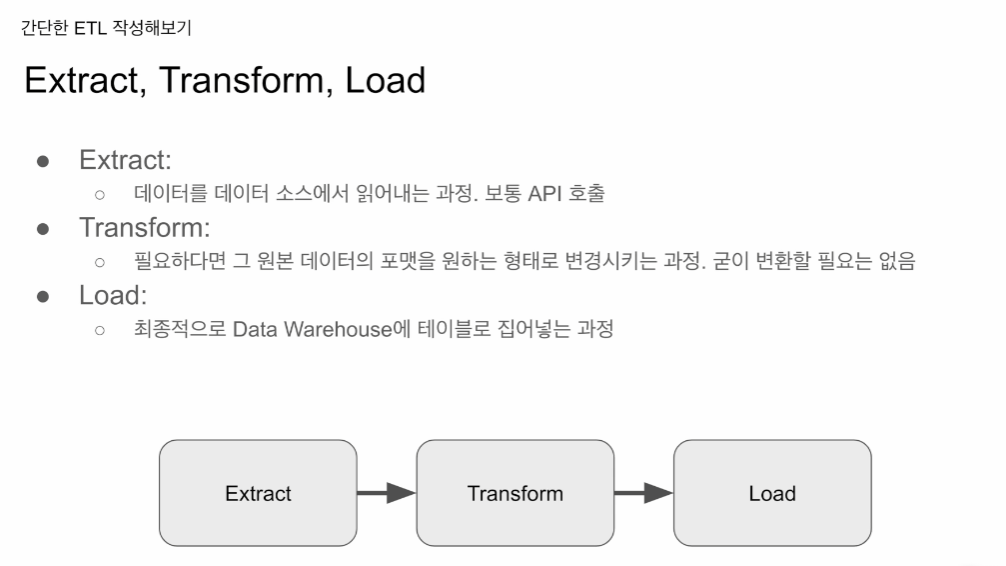
ETL : DAG
Extract: API를 호출하는 형태. 이번 강의에선 csv파일을 받아서 사용 예정. 차후에 API 사용
Transform: 포맷을 내가 원하는 형태로 변형. 생략하기도 함. 데이터가 너무 커 스파크 같은걸 쓰기도 함.
Load:
각각이 하나의 태스크가 되거나, 하나의 태스크가 될 수 있음. -> 에어플로우에서 사용하는 용어. 파이프라인을 한번에 실행하지 않고, 각각의 코드뭉치 태스크 별로 실행시킴. 조금 더 구체적인 단위로 나뉨.
순서 Extract -> Transform -> Load
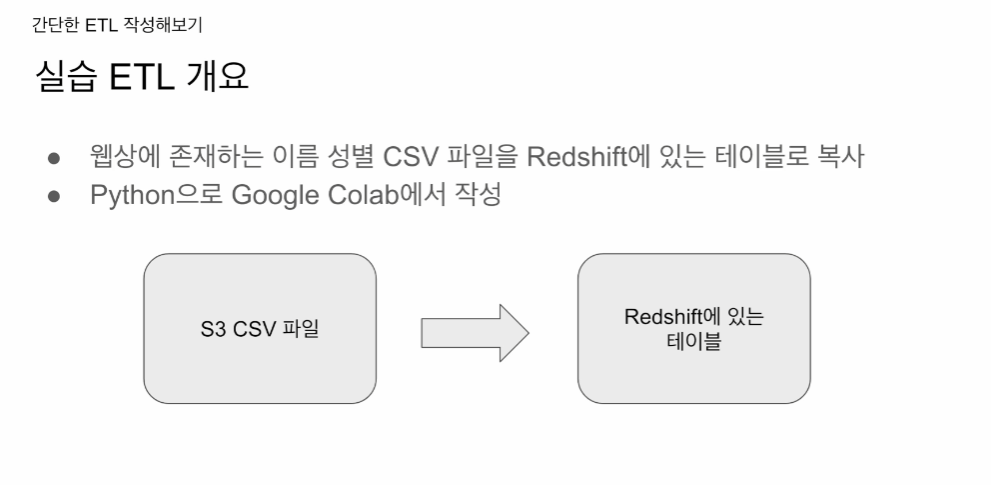
웹에서 읽어다(Extract) 읽은 파일의 내용을 테이블로 적재. Transform.
멱등성을 보장하는 것이 중요.

목적지에 테이블을 만들어두기.
CREATE TABLE kjw9684k.name_gender(
name varchar(32) primary key,
gender varchar(8)
);두개의 필드를 갖고 있음.
name varchar 타입
gender varchar
name이 PK로 이론적으로 지정. 유일한 값이 있어야 함. DW는 기본적으로 PK uniqueness를 보장하지 않음. 다수 존재할 수 있음. 어떻게 지켜주느냐는 엔지니어의 일. 멱등성 보장 요소.

csv 파일을 받아보면 두개의 컬럼으로 구성되어 있는 걸을 볼 수 있음.
F, Unisex, M
궁극적으로 멱등성을 보장하고 싶다가 이번 실습의 목표.
코드에 문제가 있는데 이걸 고치는게 숙제
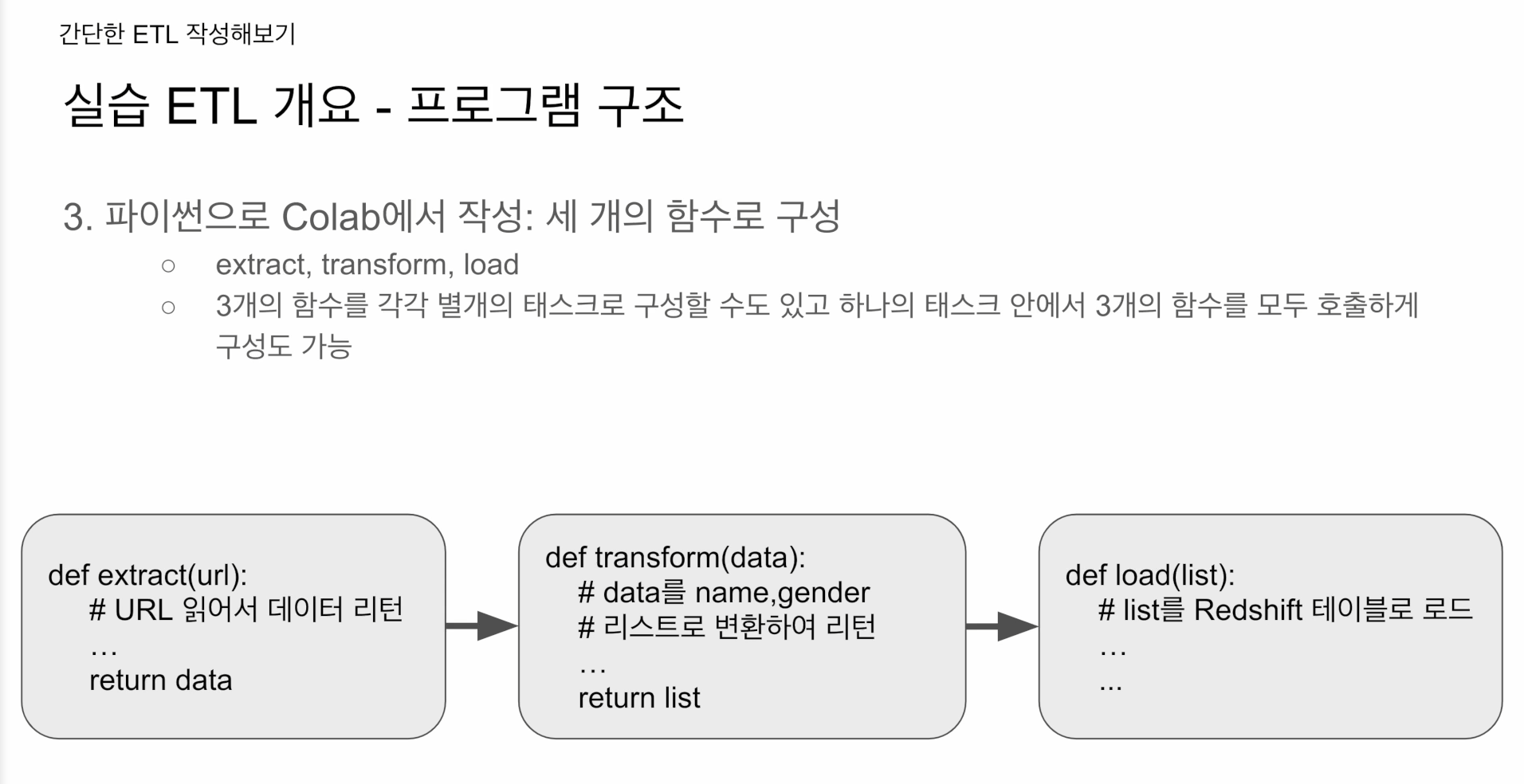
구글 콜랩 위에서 구성
별개의 테스크로 구성, 하나로 묶은 테스크도 가능
구글 콜랩 무료버전으로 사용
%load_ext sql을 쓰면 %%sql을 사용 가능
모듈은
SQLAlchemy를 사용함.
구글 콜랩이 사용하는 SQLAlchemy 버전이 충돌 이슈가 있어 이전 버전으로 다운그레이드 함.
제공받은 아이디와 패스워드 사용하여 접속

없는 테이블을 삭제하려고 하면 오류가 나기 때문에 IF EXISTS를 사용함. 존재하는 경우에만 삭제.
DROP TABLE IF EXISTS kjw9684k.name_gender;
CREATE TABLE kjw9684k.name_gender (
name varchar(32) primary key,
gender varchar(8)
);파이썬 코드에서 레드쉬프트에 SQL 명령어를 보내는 함수
psycopg2: 파이썬에서 postgres 계열 데이터베이스를 조작할 때 사용하는 모듈
redshift는 postgres와 호환됨.
import psycopg2
# Redshift connection 함수
def get_Redshift _connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = 'ID"
redshift_pass ="Pass"
port = 5439
dbname = "dev"
conn = psycopg2.connect("dbname={dbname} user={user} host={host} password={password} port={port}".format(
dbname=dbname,
user=redshift_user,
password=redshift_pass,
port=port
))
conn.set_session(autocommit=True)
return conn.cursor()ETL 함수
extract 함수는 url이 주어지면
그 url을 request.get 함수로 내용을 받아온 다음
문자열 그대로 리턴을 해줌
파싱 없이 그대로 들어가있음.
csv 파일을 읽어온다면 하나의 긴 스트링으로 리턴됨.

import requests
def extract(url):
f = request.get(url)
return (f.text)transform 함수는
csv 파일에 해당하는 긴 문자열 하나 받아서, name, gender 리스트로 리턴
strip을 부름. csv 끝에는 빈 문자열이 하나 있기에 제거하기 위해 사용. strip은 좌우 공백, \n을 제거해줌.
split 함수는 특정 기호를 기준으로 리스트로 만듦
이름, 성별 형태로 지금 리스트로 묶여있음.
이걸 최종적으로 records에 for 로 넣어줄 예정
행단으로 나눈 리스트를, 한 레코드의 문자열을 ","으로 나누어서 넣어줌. ("keeyong, M" -> [ 'keeyong', 'M' ]
리스트 in 리스트 형태로 넣음.

def transform(text):
lines = text.strip().split("\n")
records =[]
for l in lines:
(name, gender) = l.split(",")
records.append([name, gender])
return records Load함수는 transform이 리턴해준 레코드를 가지고 루프를 하나씩 돌면서 sql insert intop 함수를 스키마 아래 테이블에 하나씩 적재함.
records는 기본적으로 list in list 형식,
처음엔 sql 문을 실행시켜야하기에 get_redshift_connection 함수를 불러서 redshift와 연결하여 커서를 오브젝트로 받음.
앞서 만든 records를 for 문으로 돌면서 0번째는 이름, 1번째는 성이기에 sql 문으로 작성, cur.execute(sql)으로 실행시킨다.

def load(records):
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
# DELETE FROM을 먼저 수행 -> FULL REFRESH를 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = "INSERT INTO kjw9684k.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)함수를 하나씩 실행
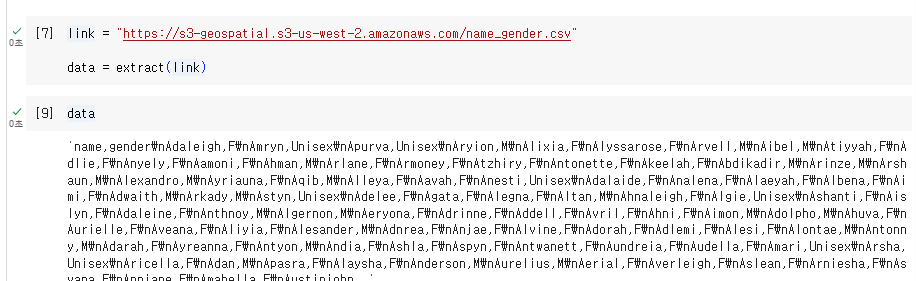
굉장히 긴 하나의 문자열
개행 문자가 중간에 보임. 이걸 중심으로 나누고,
하나의 레코드에 대해 ,를 기준으로 나눌 예정

이렇게 리스트 인 리스트 형식
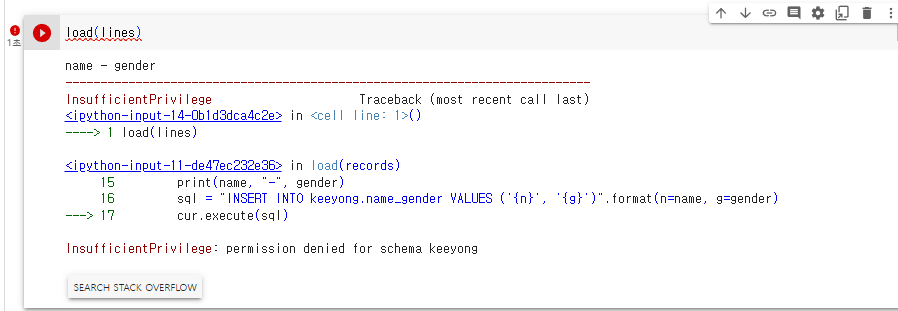
로드가 실패함.
스키마 이름을 바꿔주지 않음 keeyong에서 kjw9684k로 바꾼다

성공함.
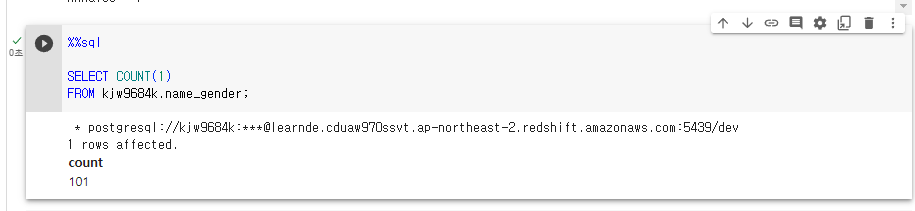
테이블에 101개의 레코드가 정상적으로 들어감.
마지막으로 성별로 그 수를 구해본다
SELECT gender, COUNT(1) count
FROM kjw9684k.name_gender
GROUP BY gender;
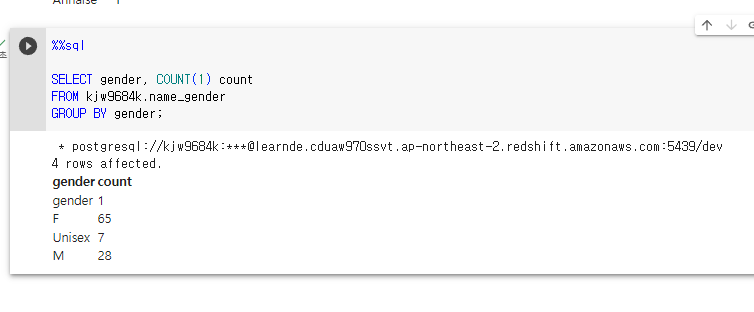
보면 gender 이 1로 잡혀있다. 이건 버그인데 나중에 숙제 설명때 알려줄 예정.
첫번째 행을 지우지 않음
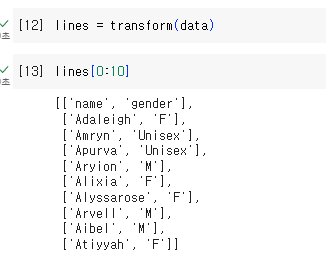
name - gender
헤더가 레코드로 들어감
멱등성이 깨지고 있음.
extract, transform, load를 재실행
ETL을 한번을 실행하는 100번을 실행하든 DW 내용과 소스의 내용이 동일해야함.
그러나 DELETE가 없어 중복이 한번씩 들어가게 됨
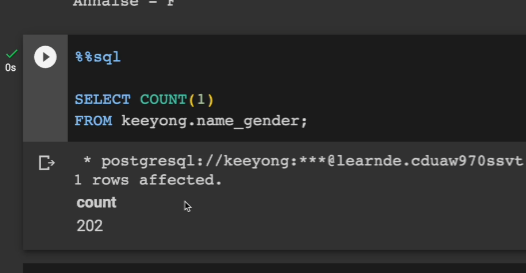
헤더도 불필요하게 두번 들어감
숙제.
load부분을 수정하여
중복하여 실행해도, 소스, DW 목적지 테이블과 내용이 같아야함.
풀리프레쉬로 접근
DELETE FROM 쓰고.
만들 delete는 성공했는데 INSERT INTO가 에러가 나면, 데이터의 정합성이 깨짐. 소스와 목적지 테이블 불일치.
트랜잭션 사용.
중요한 데이터 작업들을 하나의 atomic 오퍼레이션화.
중간에 하나라도 실패하면 실행 이전의 상태로 돌아감.
TRUNCATE 써보자.
def load(records):
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
cur.execute("BEGIN;")
try:
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
cur.execute("DELETE FROM kjw9684k.name_gender;")
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = "INSERT INTO kjw9684k.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)
cur.execute("COMMIT;") # 트랜젝션 커밋
except:
cur.execute("ROLLBACK;") # 에러가 발생하면 롤백
raise # 에러를 상위로 전파