학습주제
데이터 파이프라인 프로세스 알아보기
학습내용
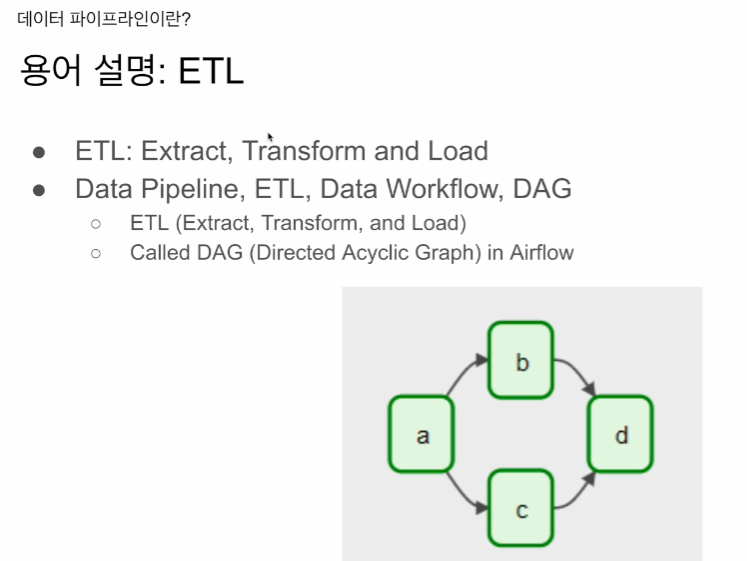
데이터 워크플로우 , DAG라고도 부름
Directed Acycle Graph
보면 파이브라인에 4개의 테스크가 있고
a 실행.
b, c 병렬 실행.
d 실행 순으로 보임
그래프로 보이고, 한방향 (dicrected)
루프가 없음 (acyclic)
루프가 없다? -> d가 끝나고 a로 돌아가진 않음.
데이터 소스가 있으면, 덤프를 받는다 Extract. API, 파일을 받고
받은 데이터를 내가 원하는 형태로 포맷을 바꿈 Transform.(그대로 가져오는 경우도 있음. 내가 원하는 것만 추출하는 경우도 있음. 포맷을 완전히 바꾸는 경우도 있음.)
내가 추출하고 정제한 데이터를 적재함 Load(데이터 웨어하우스에 테이블 형태로 저장)
데이터 웨어하우스는 보통 스케일러블한 관계형 데이터 베이스.
ETL? ELT?

ETL: 데이터 엔지니어. 누군가의 요청으로 수행.(데이터 분석가. 가져와줘. 현업 사람들의 요청)
자기가 복사해오는 데이터가 어떻게 쓰이는지 엔지니어는 잘 모름.
"Best practice"는 특정 분야에서 가장 효과적이고 성공적인 접근 방식이나 방법을 의미합니다. 이러한 방법은 해당 분야에서 많은 전문가들이 인정하고 사용하는 일종의 표준입니다. 주로 조직이나 업무 프로세스, 소프트웨어 개발 등 다양한 분야에서 사용되며, 효율성, 품질 개선, 리스크 감소 등을 목표로 합니다.
ELT: 엔지니어들이 뭔지 모르고 가져온 데이터들을 조합, 추상화, 사용하기 쉽게 요약하여 데이터를 만듦. 소스의 크기에 따라 데이터 레이크(훨씬 스케일러블)를 인풋으로 하는 경우가 꽤 있음.
dbt(Data Build Tool)는 데이터 웨어하우스 구축과 유지보수를 위한 오픈 소스 도구입니다. dbt를 연습하고 익히는 가장 좋은 방법은 실제 데이터를 사용하여 로컬 환경에서 dbt 프로젝트를 설정하고 실행해 보는 것입니다. 이를 위해 다음의 단계를 따를 수 있습니다
dbtlabs라고 SaaS 제공
dbt 사용하면 애널리틱스 엔지니어링
데이터 레이크, 웨어하우스

데이터 레이크
- 훨씬 스케일러블함.
- 그냥 스토리지라고 생각해도 됨.
- 로그 파일처럼 비구조화 데이터
- 원본 그대로 복제를 하는 경우가 많음.
데이터 웨어하우스
- 비구조화 X
- 보존기한이 있는, 중요한 구조화 데이터 저장, 처리까지 (SQL)
- BI 툴과 연결되어, 시각화 가능
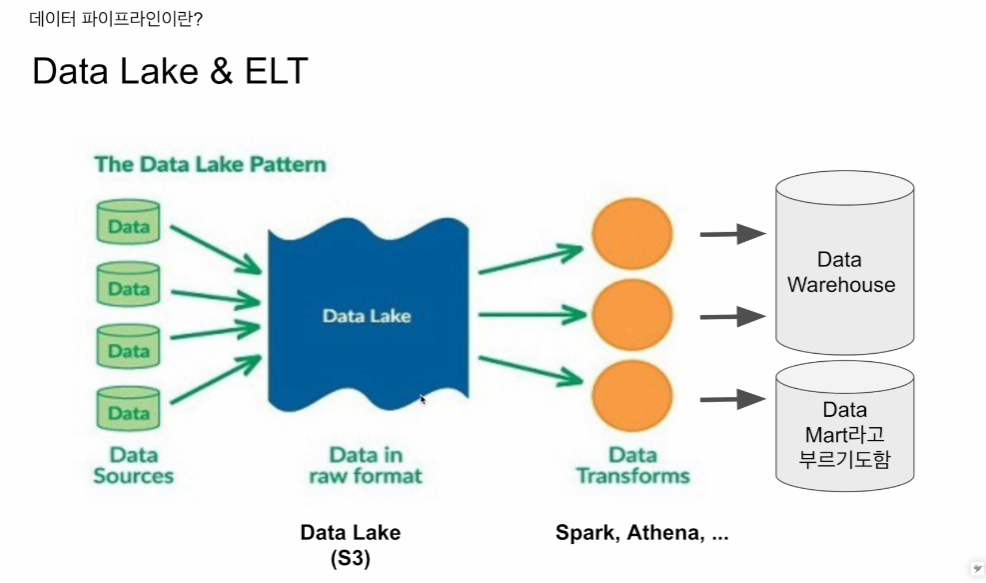
데이터 시스템이 성숙해진 회사의 다이어그램.
굉장히 많은 데이터 소스. 로그(중요하지만 굉장히 파일이 커 웨어하우스에 저장하긴 무리) 원본 형태로 S3에 저장.
트랜스폼 처리를 통해 데이터 웨어하우스에 저장
데이터 레이크 (S3) 단순 스토리지. 프로세싱 프레임워크가 연계되어 있진 않음.
이를 Spark, Athena로 정제 후 데이터 웨어하우스 저장
Athena - presto 기반 sql으로 AWS에서 SaaS. 하둡위에서 돌아가는 sql
(요약 정리해줌)
데이터 마트 - 웨어하우스인데 특정 부서, 특정 용도를 위해 만들어짐
데이터 레이크 - raw form. 프레스토, 하둡, 스파크로 정돈, 요약해서 데이터 웨어하우스 저장.
데이터 소스 -> ETL -> 데이터 레이크 -> ELT -> 데이터 웨어하우스

데이터 소스를 목적지로 복사
SQL로 이뤄지는건 ELT (이미 데이터 시스템 안에 들어와있는 경우. 데이터 소스도 데이터 웨어하우스, 데이터 레이크인 경우)
목적지가 외부 시스템이 될 수도 있음.
캐시시스템, NoSQL, S3등도 목적지가 되기도 함.
데이터 파이프라인: 데이터를 한 곳에서 한 곳으로 옮기는 것

내부: 같은 회사.
외부: 회사 밖에 있는 시스템. 페이스북 광고 정보.
API로 추출을 많이 함.
크기가 커지면 파이썬 코드로 정제를 할 수 없음. Spark같은 빅데이터 프레임워크를 많이 씀.
데이터 웨어하우스에 테이블 형태로 저장됨.

DW, DL로 읽어 다시 DW에 쓰는 ETL
좀 더 사용하기 쉬운 정제된 데이터
결국 테이블 형태로 데이터 웨어하우스, 레이크에 저장.
DBT 같은 툴을 쓰기도 함. - 분석가들이
결과의 목적지가 내부가 아닌 외부 시스템인 경우.
DW 안에서 요약 후 다른 프로덕션 데이터베이스에 쓰는 것.
유튜브에서 갑자기 뜨는 비디오가 있는 경우, 뷰 카운트, 라이브 카운트가 안뜨는 경우가 있음. 시스템의 부하가 크기 때문.
유데미에서도 인기 컨텐츠가 생기면서 사람들이 굉장히 많이 엑세스하고, 실시간 정보를 보여주려고 GROUP BY 등으로 처리해서 보여주려면 프로덕션 DB도 부하가 큼. 캐시로 처리해도 캐시가 풀리면 다시 부하가 걸림.
해결책: 이런 정보들이 실시간으로 정확할 필요가 없기 때문에, 이걸 한시간에 한번씩 계산해서 몇개의 레이팅, 몇개의 수강생, 평점인지 알아내서. MySQL에 push 하겠다. (유데미는 MySQL을 프로덕션 DB로 사용중이었음)
꼭 굳이 실시간성 정보가 아니어도 되기 때문.
데이터 웨어하우스, 레이크 정보를 정리해서 데이터 시스템 밖의 스토리지에 저장하는 예.
머신러닝 모델을 만들 때 데이터 과학자들이 인풋이 되는 피쳐를 주기적으로 계산해야될 떄가 있음. 굳이 분단위로 넣을 필요는 없음. 하루에 한번, 한시간에 한번 계산해서 넣음
데이터 파이프라인이 꼭 시스템 안에서 구현되는게 아님.

