학습주제
만들려는 대시보드 소개
학습내용

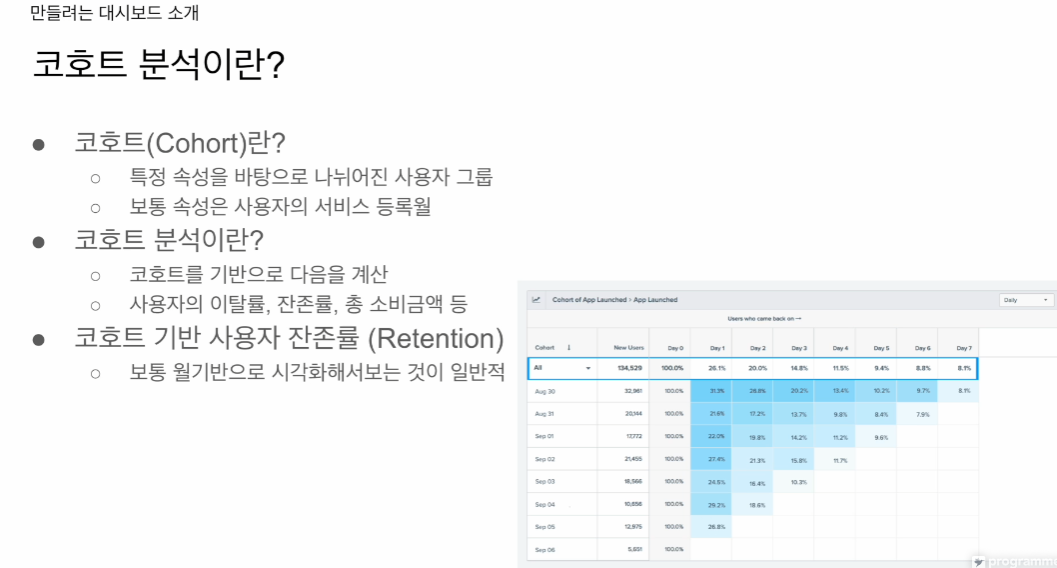
대시보드가 어떤 모양인지
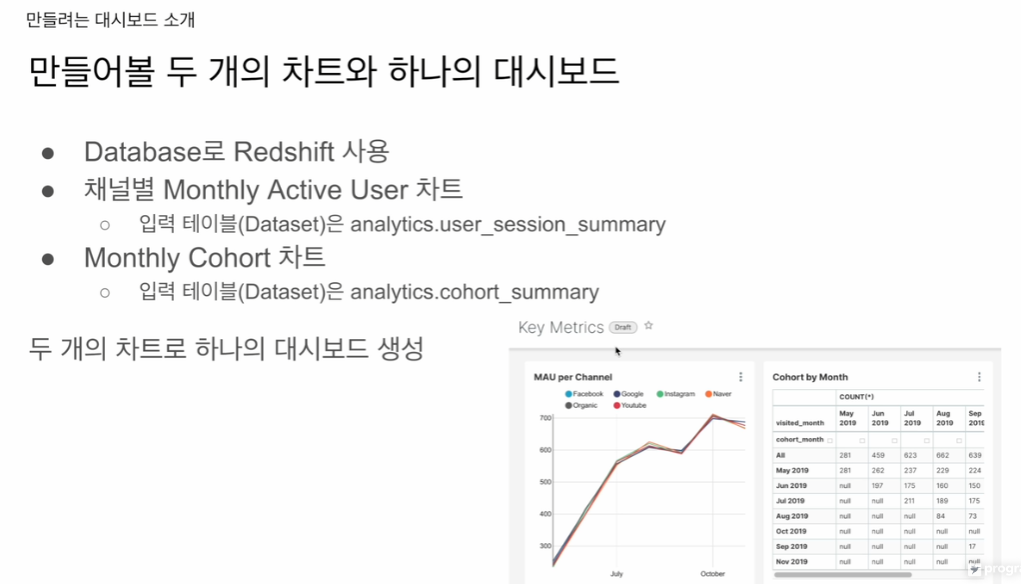
키 매트릭스
2개의 차트 mau, 코호트
Redshift 사용
- 갑자기 비용 지출되는게 궁금해서 갔더니 RDS, NAT에서 비용이 계속 빠지고 있었다. 4만 5천원 정도 빠진다는데, 이게 프리티어에서 빠지는건지 실제 비용지출인지 모르겠음.
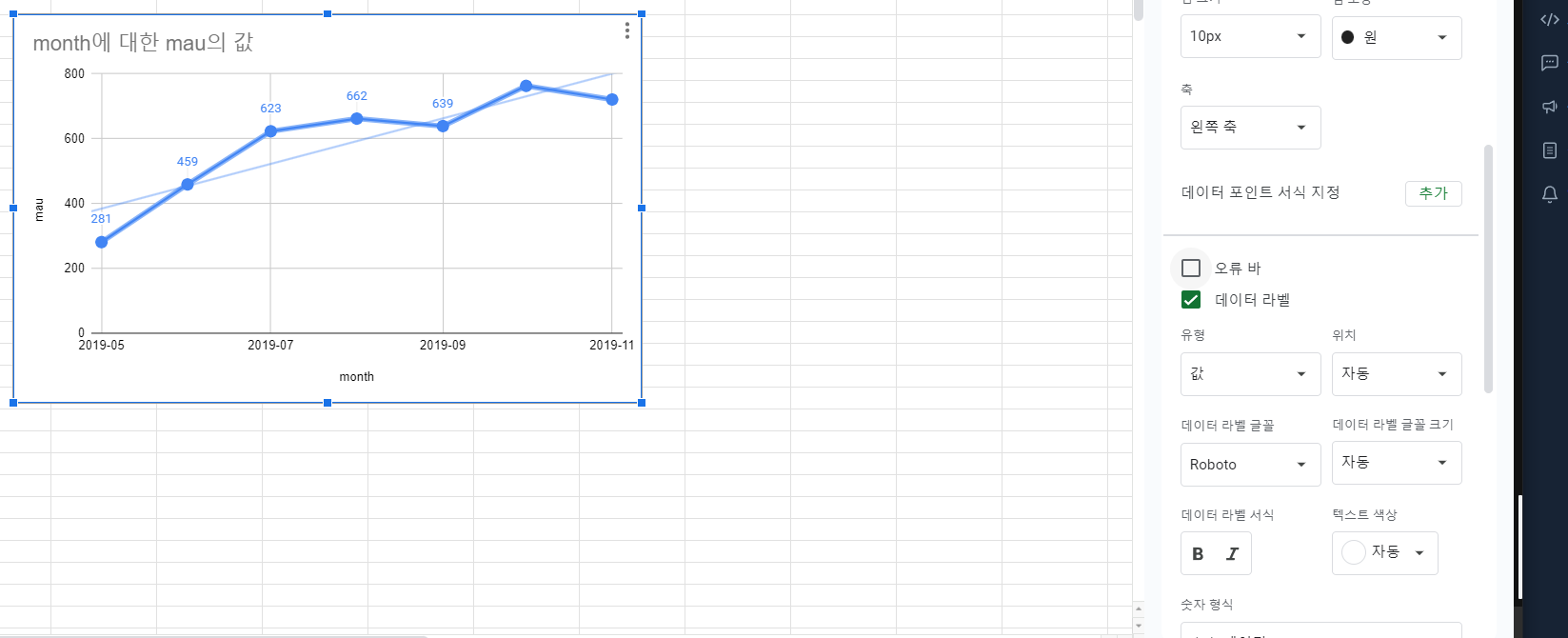
Monthly Active User 차트
월별 실제 사용자 수
Monthly Cohort 차트
테이블은 CTAS로 구성
sql은 추후 안내

CREATE TABLE analytics.user_session_summary AS
SELECT usc.*, t.ts
FROM raw_data.user_session_chaanel usc
LEFT JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionidsession 단의 완전한 정보를 갖게 만든 테이블
LEFT JOIN을 함으로써 ts의 정보 일부 누락되어도, id 누락 없음.

구글 스프레드 시트로 시각화
user_session_summary를 만들었다는 가정 하에
그 테이블을 구글 스프레드 시트 상에서 시각화
SELECT
LEFT(ts, 7) "month",
COUNT(DISTINCT userid) mau
FROM analytics.user_session_summary
GROUP BY 1
ORDER BY 1;로 테이블을 만들어 파일로 저장.
그걸 바탕으로 시각화 수행
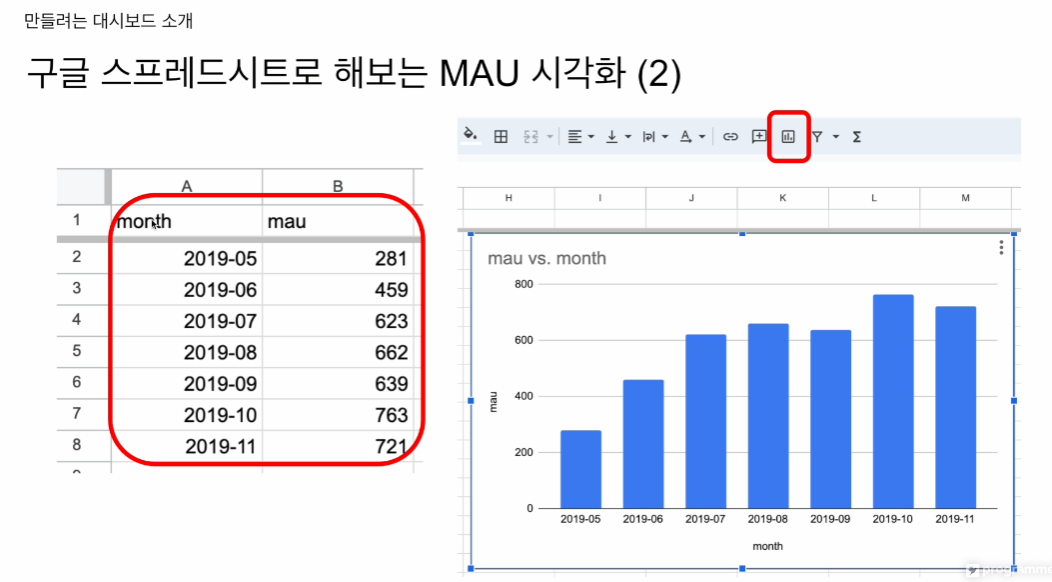
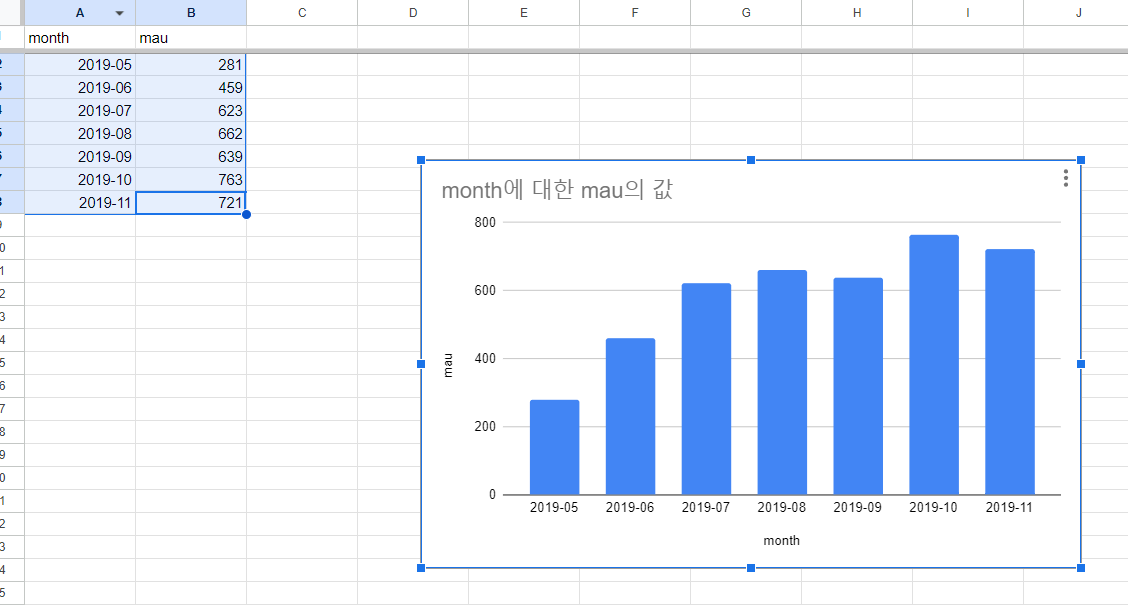
상단의 차트 아이콘을 누르면 기본으로 차트를 만들어줌.
x축이 month,
y축이 그달 들어온 유니크한 사용자 수.
이를 통해 시간이 지나며 사용자가 더 들어오는지 여부를 확인 할 수 있음.
이렇게 방문한 사람 중 누가 처음, 재방문한 사용자인지가 더 의미있음
돈을 쓴 사용자의 변화, 재방문한 사용자의 트렌드.
그냥 mau를 보는 것보다 의미 있음
코호트?
같은 속성을 갖는 사용자들을 이야기함
성별, 연령대, 보통 흔히 코호트 분석의 속성으로는 처음 서비스 방문한 날, 월을 기준으로 봄
2022년 1월에 처음 서비스 사용한 사람들과 2월에 사용한 사람들이 어떻게 다른지.
누가 재방문을 많이 하는지, 누가 더 돈을 많이 쓰는지
시간이 자나며 어떤 형태로 재방문, 돈을, 1년 후에 몇퍼센트나 우리 서비스를 쓰는지.
얼마나 남는지, 재방문 하는지, 코호트 그룹에서 나온 총 매출금액
가장 의미 있는 분석
코호트 기반 사용자 잔존률
월별로 몇명이나 가 아닌 시간대별로,
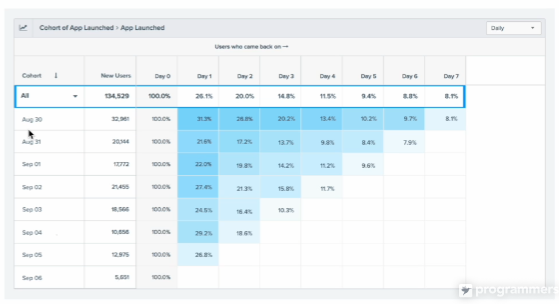
8월 30일 그 다음날, 두번째날 또방문, 세번째 또방문 점점 줄어드는게 보임.
보통 월단위로함
8월 방문한 사람이 32,000명 9월달엔 몇퍼센트나 방문, 10월달엔 몇퍼센트나 방문
좋은 서비스는 3~4번째 달부턴 안줄고 그대로 감. 오히려 조금씩 늘어남.
mau만 봐선 별 의미가 없음.
재방문 하는 사람이 늘거나, 어느 시점에서 줄지 않아야함.

서머리 테이블을 하나 만들어본다
CREATE TABLE analytics.cohort_summary as
SELECT cohort_month, visited_month, cohort.userid
FROM (
SELECT userid, date_frunc('month', MIN(ts)) cohort_month
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
GROUP BY 1
) cohort
JOIN (
SELECT DISTINCT userid, data_trunc('month', ts) visited_month
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
) visit ON cohort.cohort_month <= visit.visited_month and cohort.userid = visit.userid;
SELECT 문에서 date_frunc('month', MIN(ts))와 같은 표현이 사용되면, 결과는 순차적으로 나옵니다. 예를 들어, 테이블에 여러 개의 날짜가 있고, 각 날짜에 해당하는 월 값을 찾으려면 이 함수를 사용하여 최솟값을 찾고, 그 다음으로 작은 값을 찾아가며 순차적으로 월 값을 반환합니다. 결과적으로 SELECT 문의 결과는 월 값이 작은 순서대로 정렬되어 나올 것입니다.
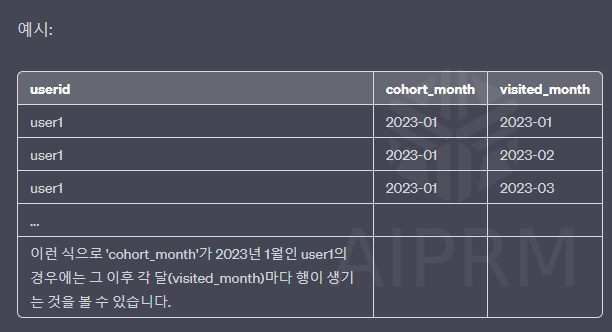
사용자 id별로 처음 방문한 달이 언제이고, 그 후 어느달에 방문했는지 기록하는 것.
모든 사용자에 대해 방문한 달마다 레코드가 생기고 하나의 cohort_month임
방문 달 수 만큼 레코드가 생김 (1개 사용자마다)

현재 작업을 구글 콜랩에서 작성 중

DATEDIFF는 redshift에서 지원하지 않음.
userid가 중복되는 것도 지금 허용하고 있음
-> 원본 테이블이 DISTINCT 이슈가 없다고 함
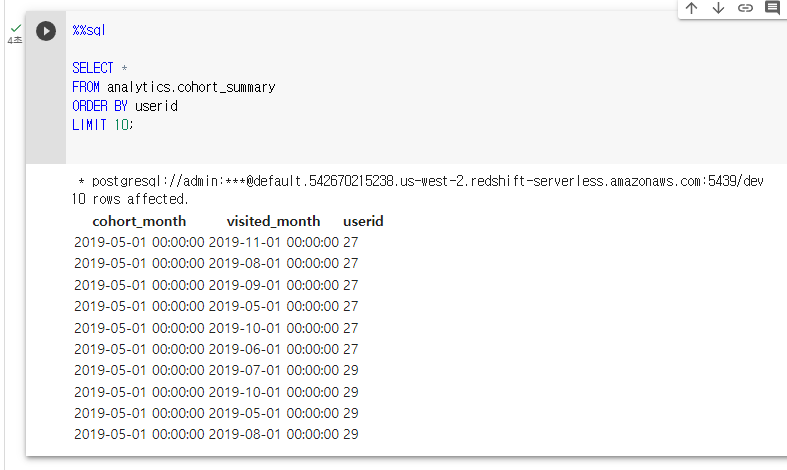
음.. 뭐지 저 각기 레코드를 별개의 레코드로 구분 하는 것 같다.

이걸 어디서 명령어를 쓰는지 아직 모름

DATEDIFF(month, cohort_month, visited_month) month
파라미터 첫번째에 day, hour, year 등을 넣음
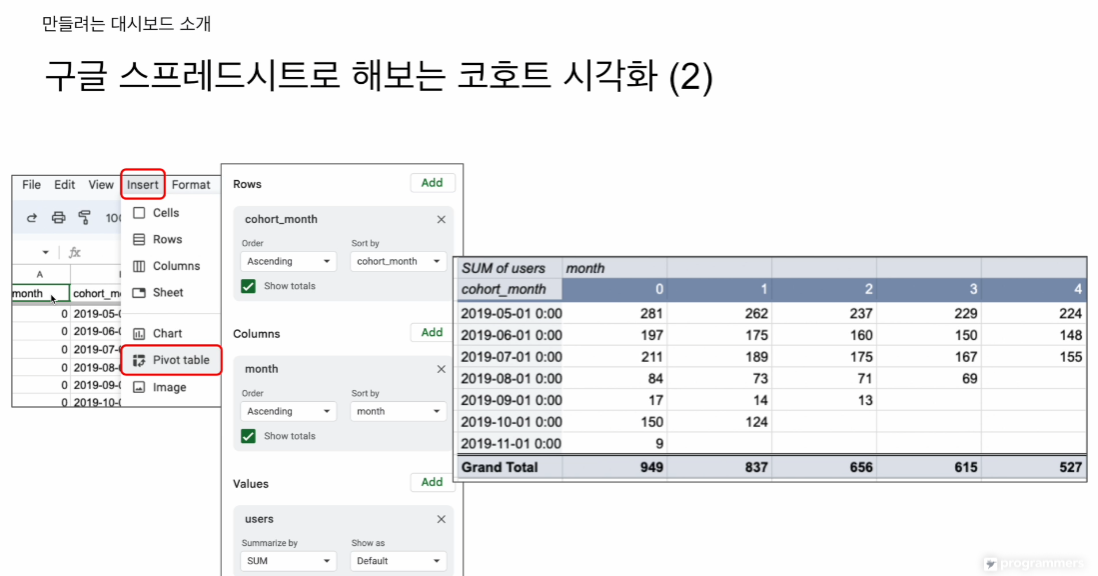
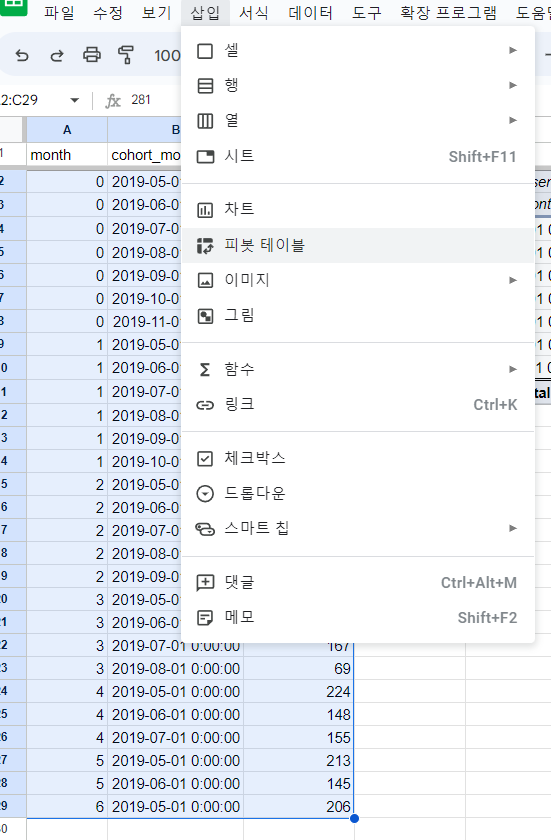
이렇게 만든 테이븦을 구글 스프레드 시트로 카피
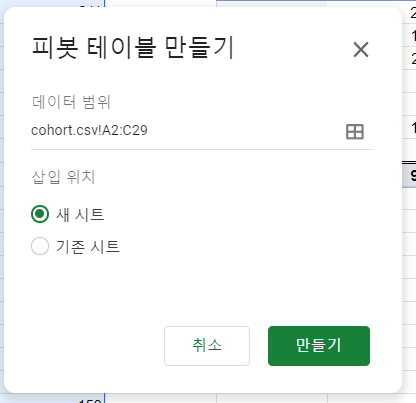
그다음 Insert - Pivot table
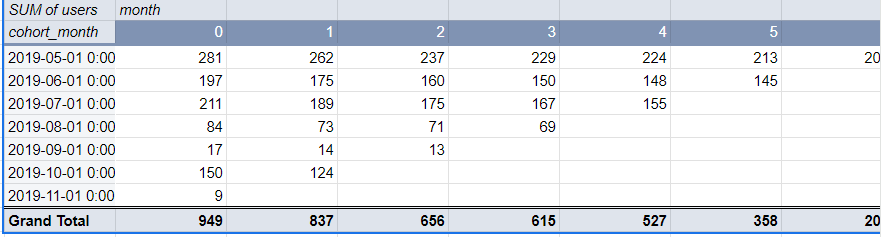
총 3개의 값
Row, column, value가 무엇인지
우측에 최종 값이 나오는 것을 확인할 수 있음
점점 줄어드는 것을 확인할 수 있다.
이걸 슈퍼셋에서 할때는 코호슽 서머리에서 바로 대시보드
중간 단계가 없을 것
실습

미리 csv가 구현되어 있음
gspread 인증만 셋업하면 스프레드시트를 파이썬으로 쓸 수 있음.
굉장히 중요한 기능
airflow에서 실습 예정
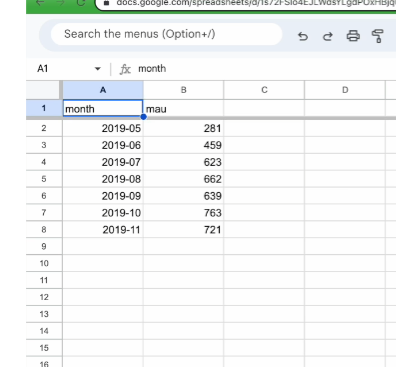
스프레드시트에서 차트 아이콘을 누르면 바로 생성됨
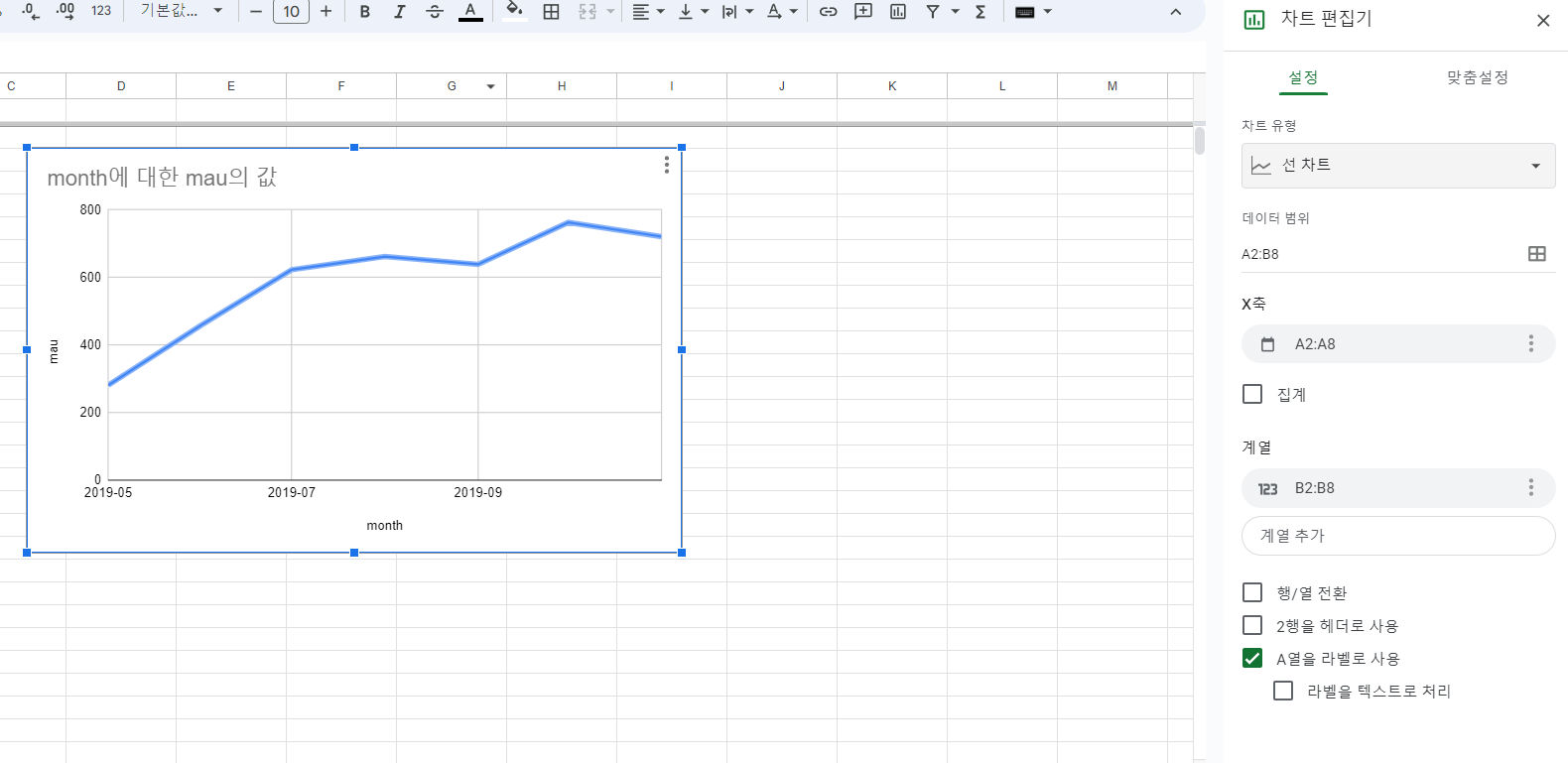
세부적으로 조정도 가능
코호트로 넘어가서
같은 시트에서 생성