학습주제
Mysql_to_Redshift DAG 데모
학습내용


풀리프레쉬 두개의 태스크
이미 만들어져 있는 대그들을 임포터해서 파라미터만 채워보는 형태
sqltos3opertor
SQL 동작하는 대부분의 DB를 데이터 소스로 해서
특정 select 문의 결과를 S3에 저장을
한번에 처리해주는 오퍼레이터.
굉장히 편리함.
관계형 데이터베이스에 대한 conn_id
관계형 DB에게 테이블 이름 또는 SELECT
s3 버킷과, s3 키 (레드쉬프트 아이디에서 -nps) 붙여서 구성해봄.
S3ToRedshiftOperator
파라미터만 잘 맞춰주면 됨.
S3 파일을 레드쉬프트 특정 테이블로
벌크 업테이트를 지원해줌.
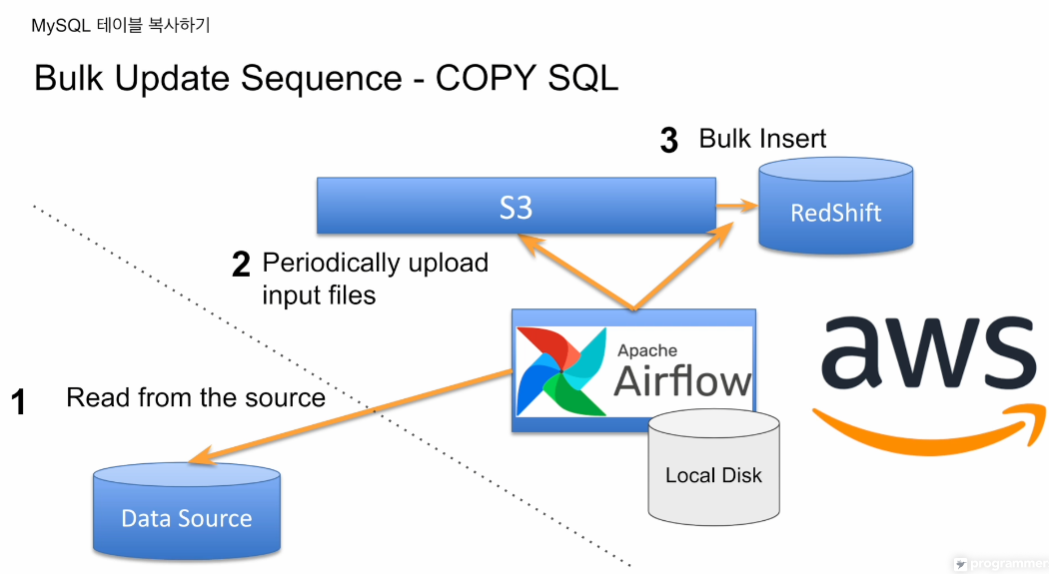
COPY SQL
에어플로우 사용 전제 하에
데이터 소스를 읽어다 파일로 저장해 S3에 로딩
이를 레드쉬프트에 타겟 테이블에 벌크 업데이트함.
에어플로우가 S3 에 대해 권한 있어야하고
레드쉬프트가 S3에 대해 권한 있어야함
https://github.com/learndataeng/learn-airflow/blob/main/dags/MySQL_to_Redshift.py
이처럼 DAG 코드가 미리 구현되어 있음.
코드를 살펴보자
풀리프레쉬 하는 대그임
오퍼레이트 두개를 임포트 하고 있음
에어플로우에서 제공하는 네이티브 오퍼레이터
먼저
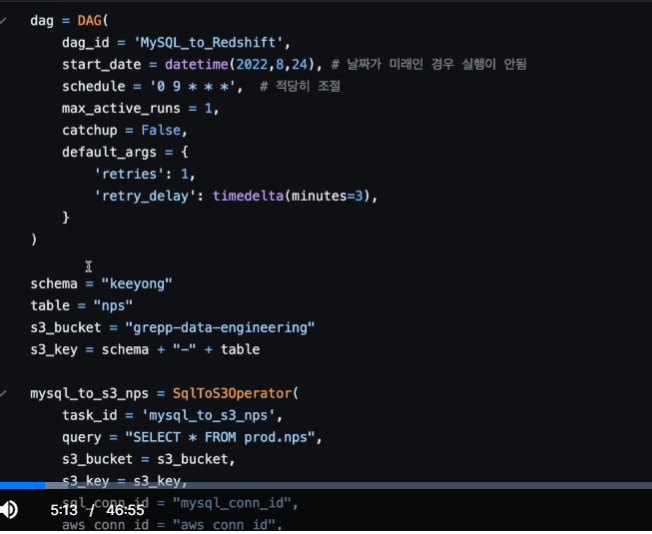
대그를 만들고
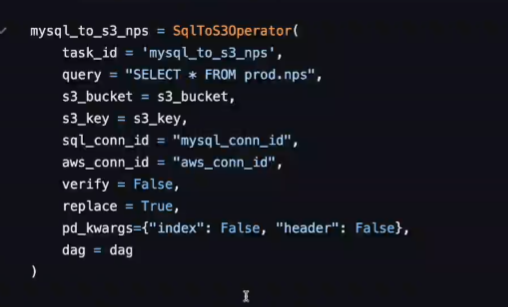
보면 파라미터만 맞춰주는 형태로 구성되어 있음
태스크 id가 정의됨.
mysql를 가리키는 conn_id가 있음 우리가 connections로 만들었던 id
어떤 테이블을 가져올 지는 query로 지정할 수 있음.
소스가 되는 데이터를 가리킴.
이걸 어디에 적재할지는 S3임. s3 버킷 파라미터를 지정해줌, 어느 패스에 로딩할지는 key로 정해짐. key가 뭐지?
키(Key): S3에서 객체를 고유하게 식별하는 데 사용되는 문자열입니다. 키는 파일의 이름 또는 파일 경로와 유사하게 생각할 수 있습니다. 키는 버킷 내에서 유일하게 유지되어야 합니다.
예를 들어, 만약 우리가 grepp-data-engineering 버킷 안의 keeyong-nps 데이터를 다루려면, 버킷은 grepp-data-engineering이고 키는 keeyong-nps가 되는 것입니다. 이렇게 설정함으로써 Airflow는 S3에서 정확히 어떤 데이터를 가져와야 하는지 알 수 있습니다.
이렇게 질문했더니 파일인지 폴더인지 헷갈려서 조금 더 질문해봤다.
S3에서 키(Key)는 파일의 이름 또는 파일 경로와 유사하게 생각하실 수 있습니다. 따라서 키는 특정 파일을 가리킬 수도 있고, 특정 폴더를 가리킬 수도 있습니다. 키가 파일을 가리키는 경우, 확장자를 포함하는 것이 일반적입니다.
하지만, Airflow에서 SqlToS3Operator나 S3ToRedshiftOperator를 사용할 때, 키에 확장자를 명시하지 않는 경우가 많습니다. 그 이유는 이러한 연산자들이 자동으로 확장자를 추가하기 때문입니다. 예를 들어, SqlToS3Operator는 query 결과를 CSV 파일로 S3에 저장하는데, 이 때 저장되는 파일의 확장자는 .csv입니다. 키로 "keeyong-nps"를 설정하면, 실제로 S3에 저장되는 파일의 이름은 "keeyong-nps.csv"가 됩니다.
Amazon S3에서 특정 폴더 아래에 있는 파일에 접근하려면, 키를 폴더명/파일명 형식으로 설정하시면 됩니다. 예를 들어, 'data' 폴더 아래에 'example.csv' 파일에 접근하려면, 키를 'data/example'로 설정하시면 됩니다
이번 대그에선 파일을 말하고 있고, csv 확장자는 생략되어 있다.
SqlToS3Operator
저장하려는 버킷, 키에 어떤 내용이 이미 있을 때 덮어쓸지를 결정하는 파라미터가 replace
True면 이미 있어도 덮어씀. False면 에러가 나고 끝나버림.
pd_kwargs
mysql 읽어온 정보를 업로드할 때 어떤식으로?
header를 카피할지 말지 결정
index 처음 레코드부터 일련번호가 붙음 1~5 이렇게 그 인덱스도 카피하지 마라.
기본적으로는 csv로 업로드 하게됨.
내부적으로는 pandas를 이용해 읽어오게 되어 있음 판다스에 주는 옵션들이 여기에 지정되는 거라 생각.
이렇게 되면
지정된 위치에 업로드가 됨
S3ToRedshiftOperator
태스크 아이디 부여
소스는
s3 버킷, 키로 지정이 됨.
aws_conn_id로 connection에 있는 값 사용
타켓이 되는 최종 목적지는
conn_id로 인증해서 연결 후에
schema, table로 지정이 되는 곳이 목적지자 됨.
소스데이터가 csv라고 지정 해주고
method는 replace -> 풀리프레쉬가 됨. 지금 새로 테이블을 만들게 됨.
뒤에 upsert로 지정을 하면 앞에 설명했던것처럼 Pk를 기준으로 바꾸고 새로 수정, 존재하지 않으면 새로운 레코드를 추가. INSERT UPDATE를 적절히 지원함.
INSERT, UPSERT, REPLACE
나중에 UPSERT 사용해봄
업로드 하고 >> 다음은 벌크업데이트로 태스크 순서 부여
각자 사용하는 스키마
bucket도 variable을 부여해서 사용 가능 Variable.get()
iam 유저 만들때 conn_id에 값 넣었음
이것으로 풀리프레쉬 버전 마무리
Incremental

데이터 소스쪽에서 바뀐 정보를 리턴해주는 방법이 없으면, 애초에 불가능함. 아니면 다 읽어와야함.
프로덕션 DB를 인크리멘탈하게 업데이트하고 싶으면 다음처럼
변경, 생성될 때마다 기록이 되는 타임스탬프가 있음 created와 살짝 다름(최초생성) modified는 내용이 수정됐을 때. 최초 created 때 modified도 같은 값으로 기록. 이게 지켜지면 어느 날짜 이후 바뀐것만 수정이 가능함.
테이블에서 레코드 삭제가 안된다면 위의 조건만으로 충분
만일 레코드 삭제가 가능하다면 인크리멘탈 업데이트를 할 수 없음 삭제가 된 것은 다 읽어오기 전에 모르기 때문 (왜냐면 비교 대상이 애초에 없기 때문. modified는 비교 기준이 남아있기 때문에)
어떤 레코드가 삭제되는게 가능하다고 하면 진짜로 물리적으로 테이블에서 제거되는게 아니라 deleted라는 컬럼을 만들어 놓고, 값을 True로 해놓음. True로 해놓으면 modified도 현재시간으로 바뀔 것이기 때문에 삭제, 변경 등을 modified만 보면 알 수 있음.

두가지 방법을 살펴봄
ROW_NUMBER() 사용해서 비슷하게
두번째는
레드쉬프트 오퍼레이터에서 UPSERT 방법을 사용함.
실제로 두번째 방법도 써봄.
ROW_NUMBER는 방식만 알려주고 코드로 알려주진 않음
보니까 저번 ROW_NUMBER 때 처럼 기존 테이블 날리고, 다시 정제 후에 적재하는 방식임. 에어플로우 환경에서 작업하고 -> S3 수정본 올리고 -> 레드쉬프트 적재
ROW_NUBMER() 구현절차
- 먼저 레드쉬프트 A의 내용을 temp_A로 복사
- mySQL의 A 테이블 레코드 중 modified의 날짜가 지난 일(execution_date)에 해당되는 레코드들을 따로 읽어다가 temp_A로 복사
- 아래는 mySQL에 보내는 쿼리. 결과를 파일로 저장한 후 S3에 업로드하고 COPY 수행.
- SELECT * FROM A WHERE DATE(modified) = DATE(execution_date)
- temp_A의 레코드들을 PK를 기준으로 PARTITION BY 한다음 modified 값을 기준으로 DESC 해서, seq 값이 1인(가장 최신 업데이트인) 것들만 다시 A로 복사
앞에서와 다르게 execution_date을 사용해야함. 에어플로우 대그를 사용할 때도 문제 없고, 백필도 문제 없음. 에어플로가 없던 세상에선 지금 시간을 기준으로 계산해서 입력했었음.
UPSERT

데이터를 실행시킬 날짜 마다 매번 그날짜의 변동 (가장 최신) 값들을 가져와서
바꿔줌.
upsert_key로 PK를 넣어주면 (다수일 경우 나열해주기)
알아서 오퍼레이터가 레코드를 비교하고 값을 바꿔줌. 새로운 값이면 그대로 적재
상당히 자동적인 느낌이다.

https://github.com/learndataeng/learn-airflow/blob/main/dags/MySQL_to_Redshift_v2.py
레드쉬프트 클러스터 생성시
https://docs.google.com/document/d/1FArSdUmDWHM9zbgEWtmYSJnxPXDX-LB7HT33AYJlWIA/edit#heading=h.9u82ph29nth9
ROLE을 만든다. 레드쉬프트 -> s3 권한 정책을 가지는.
- 보통 s3fullaccess를 부여함.
- 제약하고 싶으면 create policy해서. 특수한 버킷만 지정할 수 있음.
IAM을 만들어서
ARN을 사용함 예전에 했었음.
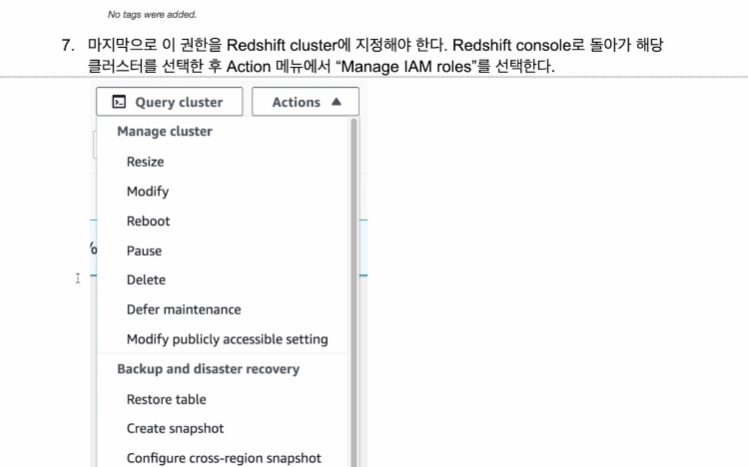
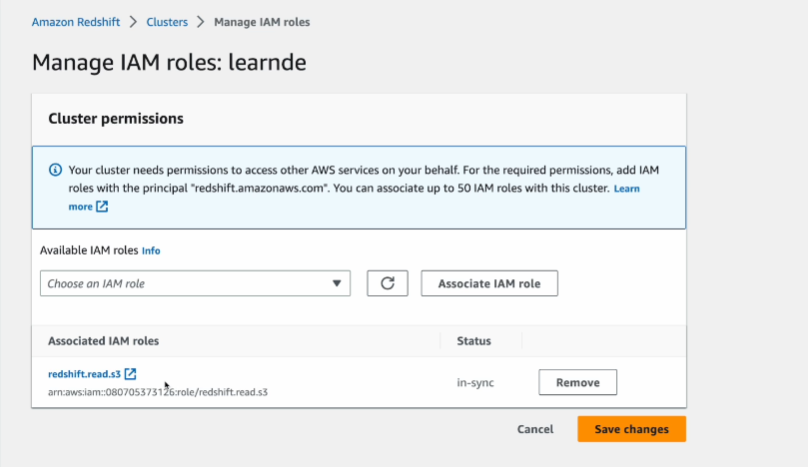
Manage IAM ROLES가 있는데
여기서 가능한 IAM role이 있는데
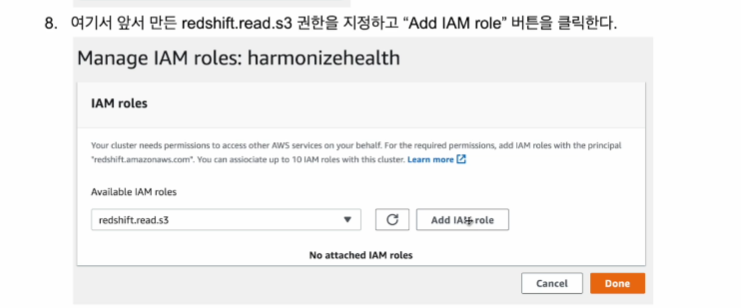
추가해주면 됨.
그럼 해당 클러스터가 권한을 갖게 된다.
다시 슬라이드로 돌아와서

이번엔 모든 레코드를 불러오는게 아니라
바뀐 날짜가 엑시큐션 데이트와 동일할 경우만 가져옴
레드쉬프트쪾은
method = "UPSERT"
upsert_keys = ["id"]
풀리프레쉬 버전과 크게 다른게 없음
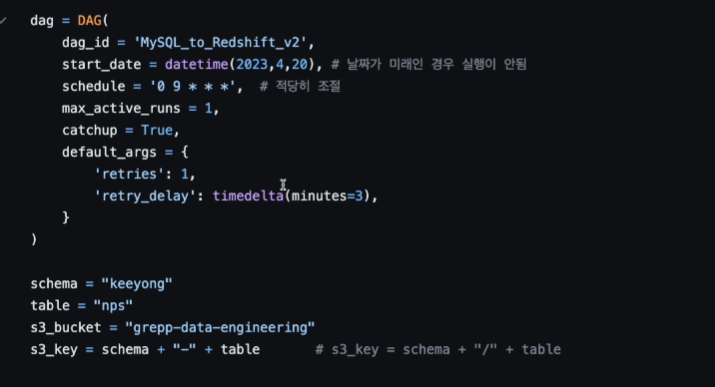
쿼리에 변화가 생겼다.
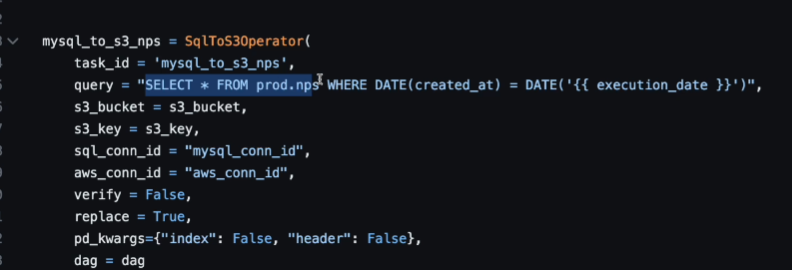
이전 쿼리는
SELECT * FROM prod.nps로 그냥 바로 다 mysql에서 가져왔었음.
이번엔
SELECT * FROM prod.nps WHERE DATE(created_at) = DATE('{{ execution date }}')
WHERE을 붙였음 {{ }} - 진저템플릿을 써서 시스템 변수를 파이썬 코드에서 쓸 수 있게 하였따. 공백 문자를 앞뒤로 주어야 함. 이러면 시스템 변수로 바꿔치기해줌. 실행 될 때, 전날 값으로 대입이 될 것이고, 백필을 할 때도 그 범위에 맞춰 값이 바뀌어 들어올 것임 - 이게 바로 에어플로우에서 대그를 인크리멘탈 업데이트를 지원하게 하는 방법임.
레드쉬프트 쪽 보면
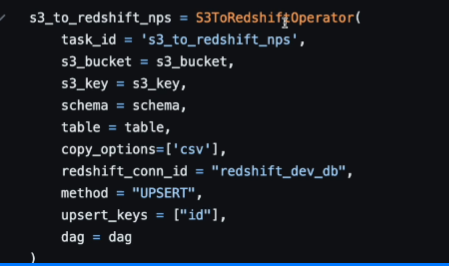
UPSERT로 방법을 변경,
upsert_keys 를 부여해서
직접 설정하지 않아도 알아서 해준다.

1. 권한설정 관련. s3 CONNECTION을 위한 IAM user
2. 레드쉬프트에 s3 엑세스 할 수 있는 권한.
3. mysql 환경이 도커에서 설치할 때 임포트 이슈있었음. 다시 보여줌
4. 두 대그를 실행시켜본다.
AWS 웹 콘솔로 로그인
IAM으로 넘어가서 전용 사용자를 만들어본다
왼쪽에 Users 선택
유저가 없다고 가정하고
add users
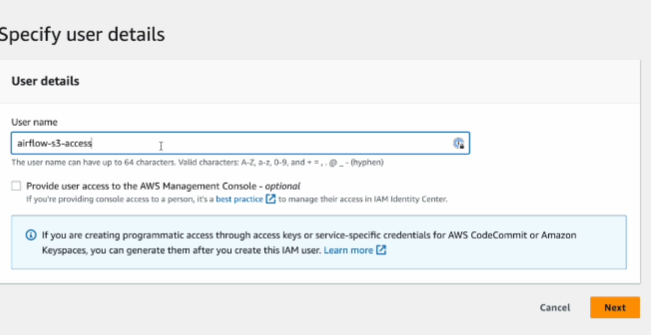
attach polices directly
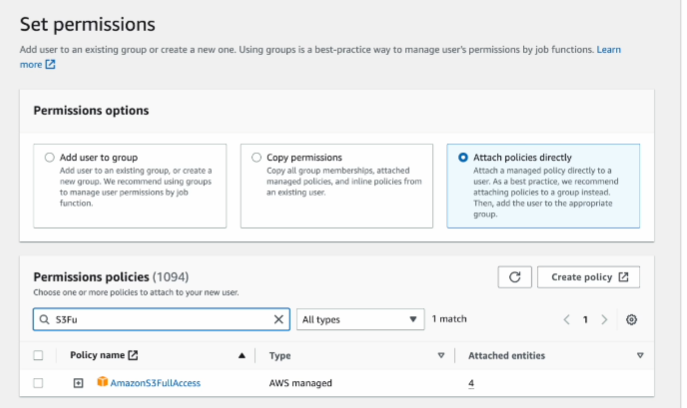
보통 fullaccess 선택해도 상관 없음
아님 create policy 눌러서
JSON 스트링 편집
특정 버킷에 대해 해당 유저가 full access 권한 가짐. - 이쪽이 더 안전함.
이렇게 만들면 유저가 하나 생성됨.
유저로 들어가서
Security credentials로 들어가서
하단에 access key를 생성함.
용도

큰 관계는 없지만
AWS 바깥에서 쓰기 선택
대충 써주고
키를 생성하면, 시크릿 키는 한번 밖에 보관의 기회가 없음. 잘 보관해야함. 잃어버리면 다시 생성하면 됨.
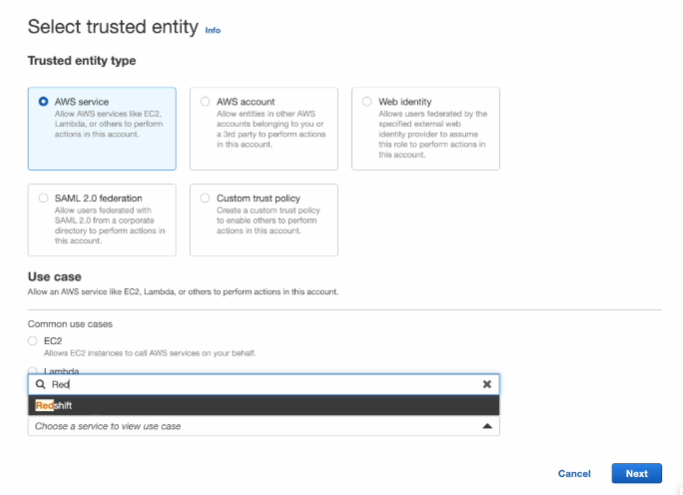
Customizable 선택
레드쉬프트 관점에서 권한을 받음
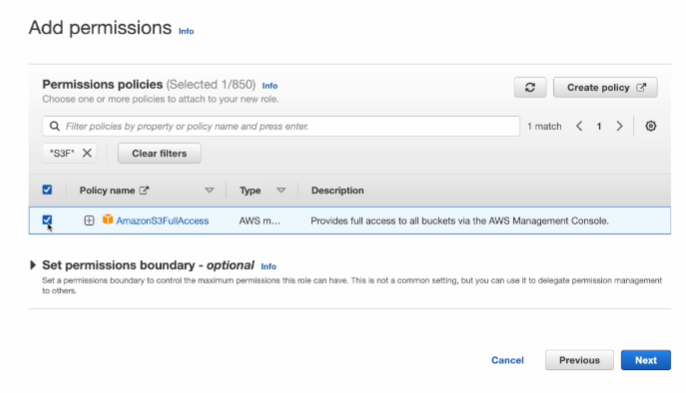
여기서도 특정 권한을 만들고 싶으면 Create policy 정책을 만들수 있음.
이렇게 적당히 역할을 생성함.
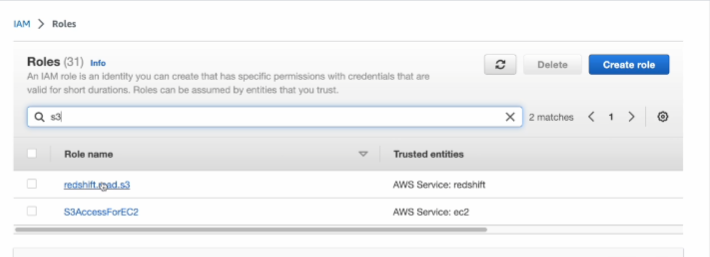
이거를 레드쉬프트 콘솔에서 적용할 예정
redshift 콘솔로 이동
클러스터로 이동
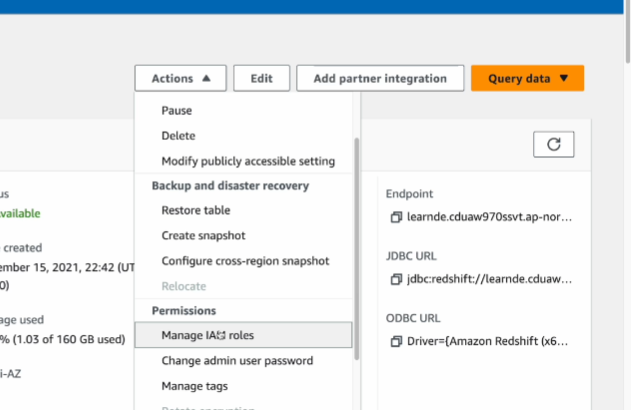
Manage IAM roles
이렇게 꼭 연동을 시켜야함.
그럼 해당 클러스터는 COPY 명령을 쓰는데 지장이 없음.
ARN도 사용해서 한번더 인식함.
도커에서의 세팅

import 에러가 날 수 있음 도커환경에서
docker ps
winpty docker exec --user root -it '컨테이너id' sh
sudo apt-get update # 클라이언트 업데이트
sudo apt-get install -y default-libmysqlclient-dev
sudo apt-get install -y gcc
sudo pip3 install --ignore-installed "apache-airflow-providers-mysql"
나도 이미 설치했었음. 노트북에서 시도할 때 하기
스케줄러에 로그인 시도해본다
--user root 없이
대그를 CLI에서 실행시켜본다
airflow dags test MySQL_to_Redshift
test라 따로 기록에 안남고 실행 날짜도 안줘도 되는거 같음
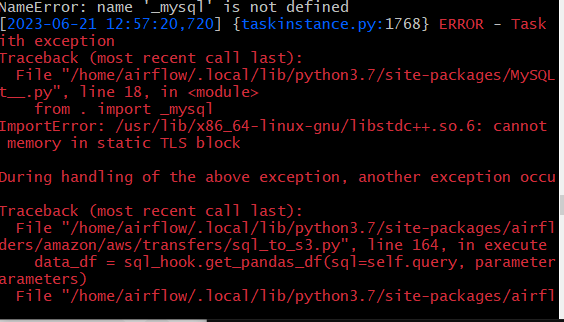
에러남.
저번에 설치했었는데??
- 도커 컨테이너를 내렸다가 다시 올리니까 생긴 이슈같음.
- 매번 도커 컨테이너 새로 올릴 때마다 실행시켜줘야 하는거 같음.
한번 컨테이너가 돌아가는 상황에서 설치시도 해보겠음.
sudo pip3 install --ignore-installed "apache-airflow-providers-mysql"
이게 새로 설치됨. 매번 컨테이너 내려가면 설치해줘야겠다
설치한 것 같음 다시 dag 돌려보자
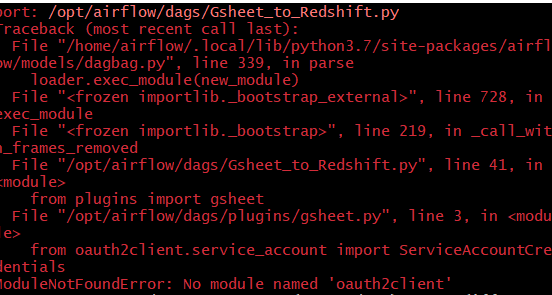
Gsheet에서 에러가 남.
gsheet 모듈이 없다고 하는데 이후 수업에서 쓰이는 거같음
일단 mysql 관련 에러는 안뜨는 것 같음
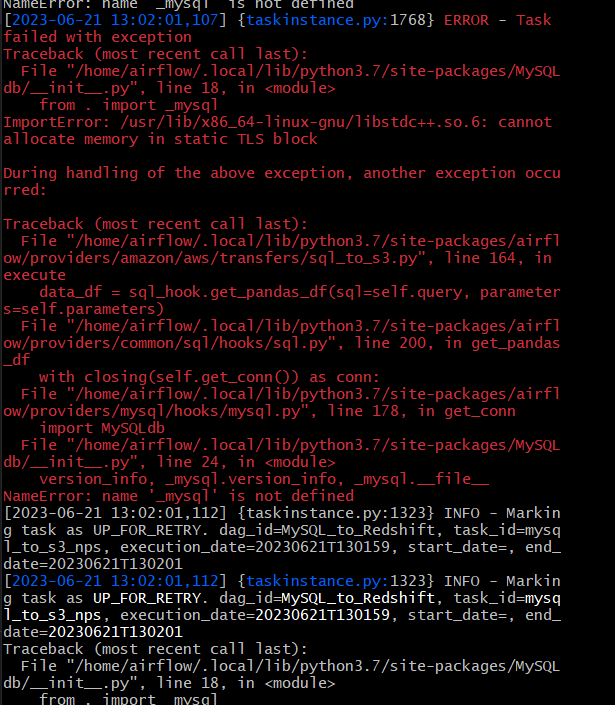
정정. 다시 뜸
GCC 메모리 이슈가 있었고 이는 mysql import에 문제가 있음
16GB 인데 현재 16GB 추가로 주문함. 최종 메모리는 32GB 예정.
다른 컴퓨터 16GB 이식한 상태임.
컴퓨터를 껐다 켰으므로 다시 설치
보니까 나머지는 설치됐고
sudo pip3 install --ignore-installed "apache-airflow-providers-mysql"
이것만 설치해주면 되는 것 같다.
설치가 끝나면 일반 유저로 로그인해서
다시 dags를 돌려보자
같은 메모리 이슈 발생.
wsl config에 저번에 프로세서, 워커의 수를 2개로 한정했던게 그대로 남아있었음.
지우고 돌려보기로 한다.
그리고 할당 메모리를 16GB로 확장시켜본다.
실패함. 다른시도
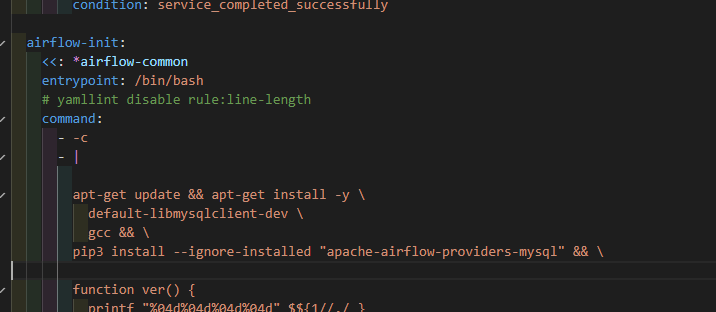
docker compose yml에 init에서 모든 컨테이너에서 필요한 패키지를 설치하도록 하게 하였음.
pandas가 먼저 임포트 되는 경우 오류가 난다고 해서
compose.yml에서 pandas를 빼고 별도로 임포트 시도해볼 예정
일단 pandas 뺐는데 다른데 오류 안남
mysql은 계속 안되는 중
sudo apt-get install libstdc++6 -> 최신임

Operatort 보니까
판다스와, 넘파이를 임포트하는것 같아서
환경설정에서 빼고 다시 해봄
실패함.
근데 희안하게
UI 로그를 보면 재시도 후 성공했다고 한다.
그리고 s3-Redshift에서 실패했다고 함.
결과적으로
다른 과정은 다 동작하나,
mySQL에서 값을 읽어오는 과정이 실패하는 중임.
그 원인으로 라이브러리의 충돌이 의심되어 노트북에서 다시 시도해봄
실패함.
도커파일을 만들어서 모든 컨테이너에 설치 시도함.
도커파일의 경우, OS 환경 패키지, 파이썬 패키지 등을 설치할 수 있음 도한 airflow.cfg 파일도 생성시켜주는 것 같음.
이렇게 함으로써 docker_compose.yml과 분리해서 작업 가능함.
일단 정상적으로 패키지 설치 완료 후
환경설정 설치로 넘어간 듯 함. (yml)
웹 UI 실행도 확인하였음.
일단 실행 돌려본다
오 일단 해결된거 같음.
모든 컨테이너에 같은 패키지를 설치하니 해결되었음.
그러나 다른 문제 발생함. Redshift 적재 관련인듯함.
에어플로우 작업이 실행 중에 있습니다.
작업 명: MySQL_to_Redshift
작업 실행 일시: 2023-06-21T17:33:18.376619+00:00
작업 순서는 다음과 같습니다:
'mysql_to_s3_nps' 작업이 성공적으로 실행되었습니다.
SQL로부터 데이터를 받아옴
데이터를 임시 파일에 작성
S3에 데이터 업로드
그 다음, 's3_to_redshift_nps' 작업이 실행됩니다.
그러나 이 과정에서 에러가 발생하였습니다.
에러 메시지: 'relation "kjw9684k.nps" does not exist'
원인: 'kjw9684k.nps'라는 테이블이 존재하지 않아서 발생한 에러로 보입니다.
작업 상태: 현재 's3_to_redshift_nps' 작업은 재시도 상태(UP_FOR_RETRY)입니다.
오 kjw968k.nps로 테이블 하나 만들어본다.
-> 그런데 스키마 구조를 내가 모르는데?
mysql 워크벤치에 연결에서 raw_data를 직접 확인한 뒤 생성한다.
def get_Redshift_connection():
# autocommit is False by default
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
return hook.get_conn().cursor()
@task
def etl(schema, table):
cur = get_Redshift_connection()
drop_recreate_sql = f"""DROP TABLE IF EXISTS {schema}.{table};
CREATE TABLE {schema}.{table} (
id int,
created_at timestamp,
score int
);
"""
logging.info(drop_recreate_sql)
try:
cur.execute(drop_recreate_sql)
cur.execute("Commit;")
except Exception as e:
cur.execute("Rollback;")
raise
별도로 테이블을 새롭게 생성하는 대그를 만들어
1회 수행시켜본다.
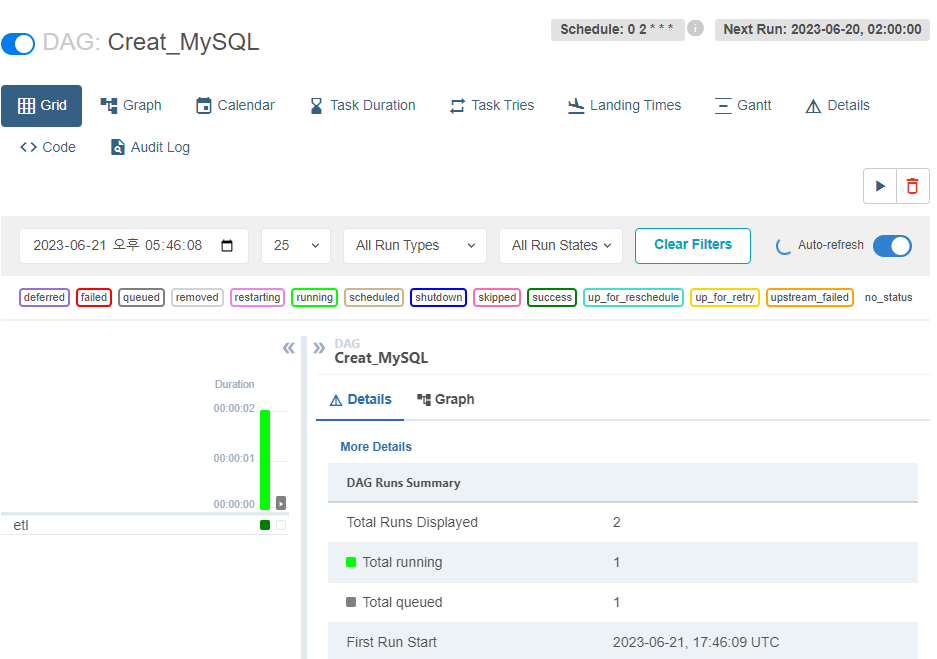
성공했음
다시 원래 MySQL_to_Redshift를 돌려본다
[2023-06-21T17:46:52.957+0000] {taskinstance.py:1350} INFO - Marking task as SUCCESS. dag_id=MySQL_to_Redshi
ft, task_id=mysql_to_s3_nps, execution_date=20230621T174648, start_date=, end_date=20230621T174652
[2023-06-21T17:46:52.972+0000] {dag.py:3691} INFO - mysql_to_s3_nps ran successfully!
[2023-06-21T17:46:52.972+0000] {dag.py:3694} INFO - *****************************************************
[2023-06-21T17:46:52.975+0000] {dag.py:3683} INFO - *****************************************************
[2023-06-21T17:46:52.976+0000] {dag.py:3687} INFO - Running task s3_to_redshift_nps
[2023-06-21 17:46:53,000] {taskinstance.py:1547} INFO - Exporting env vars: AIRFLOW_CTX_DAG_OWNER='airflow'
AIRFLOW_CTX_DAG_ID='MySQL_to_Redshift' AIRFLOW_CTX_TASK_ID='s3_to_redshift_nps' AIRFLOW_CTX_EXECUTION_DATE='
2023-06-21T17:46:48.174672+00:00' AIRFLOW_CTX_TRY_NUMBER='1' AIRFLOW_CTX_DAG_RUN_ID='manual__2023-06-21T17:4
6:48.174672+00:00'
[2023-06-21T17:46:53.000+0000] {taskinstance.py:1547} INFO - Exporting env vars: AIRFLOW_CTX_DAG_OWNER='airf
low' AIRFLOW_CTX_DAG_ID='MySQL_to_Redshift' AIRFLOW_CTX_TASK_ID='s3_to_redshift_nps' AIRFLOW_CTX_EXECUTION_D
ATE='2023-06-21T17:46:48.174672+00:00' AIRFLOW_CTX_TRY_NUMBER='1' AIRFLOW_CTX_DAG_RUN_ID='manual__2023-06-21
T17:46:48.174672+00:00'
[2023-06-21T17:46:53.002+0000] {base.py:73} INFO - Using connection ID 'aws_conn_id' for task execution.
[2023-06-21T17:46:53.004+0000] {base.py:73} INFO - Using connection ID 'aws_conn_id' for task execution.
[2023-06-21T17:46:53.004+0000] {connection_wrapper.py:334} INFO - AWS Connection (conn_id='aws_conn_id', con
n_type='aws') credentials retrieved from login and password.
[2023-06-21 17:46:53,014] {s3_to_redshift.py:164} INFO - Executing COPY command...
[2023-06-21T17:46:53.014+0000] {s3_to_redshift.py:164} INFO - Executing COPY command...
[2023-06-21T17:46:53.017+0000] {base.py:73} INFO - Using connection ID 'redshift_dev_db' for task execution.
[2023-06-21T17:46:53.069+0000] {sql.py:375} INFO - Running statement: BEGIN;, parameters: None
[2023-06-21T17:46:53.097+0000] {sql.py:375} INFO - Running statement: DELETE FROM kjw9684k.nps;, parameters:
None
[2023-06-21T17:46:53.144+0000] {sql.py:384} INFO - Rows affected: 0
[2023-06-21T17:46:53.145+0000] {sql.py:375} INFO - Running statement:
COPY kjw9684k.nps
FROM 's3://grepp-data-engineering/kjw9684k-nps'
credentials
'aws_access_key_id=AKIARFSTKIPDH3ZEJXJ5;aws_secret_access_key=CHovQnXobAkNKjGZT4lYBuRK7M
9qYlcx91tGGeuN'
csv;
, parameters: None
[2023-06-21T17:47:02.541+0000] {sql.py:375} INFO - Running statement: COMMIT, parameters: None
[2023-06-21 17:47:02,615] {s3_to_redshift.py:166} INFO - COPY command complete...
[2023-06-21T17:47:02.615+0000] {s3_to_redshift.py:166} INFO - COPY command complete...
[2023-06-21 17:47:02,619] {taskinstance.py:1350} INFO - Marking task as SUCCESS. dag_id=MySQL_to_Redshift, t
ask_id=s3_to_redshift_nps, execution_date=20230621T174648, start_date=, end_date=20230621T174702
[2023-06-21T17:47:02.619+0000] {taskinstance.py:1350} INFO - Marking task as SUCCESS. dag_id=MySQL_to_Redshi
ft, task_id=s3_to_redshift_nps, execution_date=20230621T174648, start_date=, end_date=20230621T174702
[2023-06-21T17:47:02.626+0000] {dag.py:3691} INFO - s3_to_redshift_nps ran successfully!
[2023-06-21T17:47:02.626+0000] {dag.py:3694} INFO - *****************************************************
[2023-06-21T17:47:02.629+0000] {dagrun.py:616} INFO - Marking run <DagRun MySQL_to_Redshift @ 2023-06-21T17:
46:48.174672+00:00: manual__2023-06-21T17:46:48.174672+00:00, state:running, queued_at: None. externally tri
ggered: False> successful
[2023-06-21T17:47:02.630+0000] {dagrun.py:682} INFO - DagRun Finished: dag_id=MySQL_to_Redshift, execution_d
ate=2023-06-21T17:46:48.174672+00:00, run_id=manual__2023-06-21T17:46:48.174672+00:00, run_start_date=2023-0
6-21 17:46:48.174672+00:00, run_end_date=2023-06-21 17:47:02.630656+00:00, run_duration=14.455984, state=suc
cess, external_trigger=False, run_type=manual, data_interval_start=2023-06-21T17:46:48.174672+00:00, data_in
terval_end=2023-06-22T09:00:00+00:00, dag_hash=None로그이다.
정상적으로 다 돌아갔다.
한 5시간 넘게 고생한거 같다.
내가 뭐랄까 도커를 몰라도 너무 모르는 것 같다.
멘토님 말씀대로 나중에 시간 날때마다 에어플로우 코드도 많이 파보는게 좋을 듯 하다.
노트북 작업 환경도 연동하는게 좋을 듯함.
FROM apache/airflow:2.5.1
# 명령어들을 root 사용자로 실행
USER root
# OS 업데이트 및 필요한 패키지 설치
RUN apt-get update
RUN apt-get install -y default-libmysqlclient-dev gcc
# 명령어들을 airflow 사용자로 실행
USER airflow
RUN pip install --ignore-installed "apache-airflow-providers-mysql"
RUN pip install urllib3==1.26.5
RUN pip install requests==2.26.0
# 필요한 Python 패키지 설치
RUN pip install yfinance
# Airflow 설정 파일 복사
COPY airflow.cfg /opt/airflow/airflow.cfg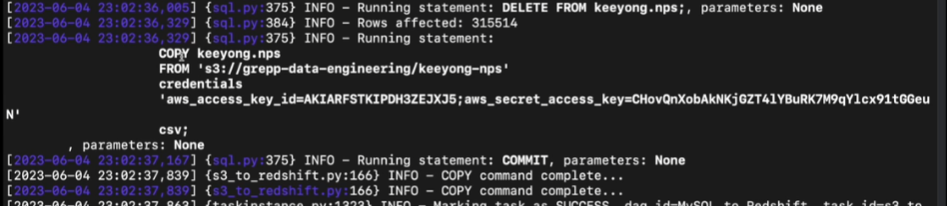
COPY 커맨드를 써서 해당 스키마 밑에 벌크 업데이트 시켜준다.
보면 알아서 arn 값도 집어넣어주는 것을 볼 수 있음
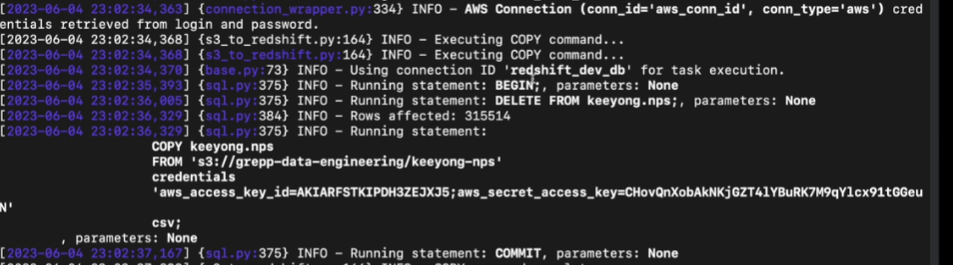
보면 위에 BEGIN;으로 트랜잭션 열고
뒤에 DELETE 해줌
두번째 버전도 돌려본다.
airflow dags test MySQL_to_Redshift_v2 2023-01-27
이제부터는 뒤에 주는 날짜가 중요해짐.
execution date로 들어가서
이 date에 해당하는 날짜에 변경된 레코드들을 읽어다가 적재해서 읽어옴
mysql에서 정확히 1월 27일 데이터만 읽어오는지는 로그가 남지 않아 알기가 힘듦
s3-redshift
로그를 보면
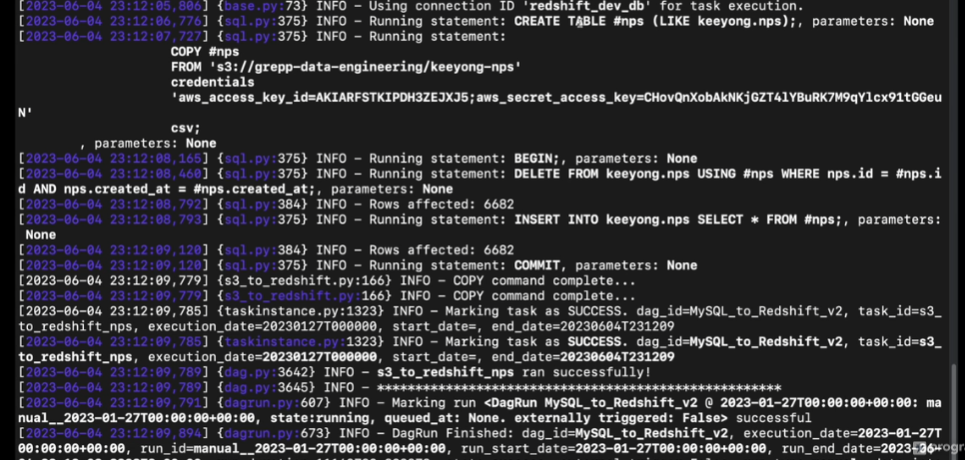
임시테이블을 만들어다가
샵nps는 임시테이블임
27일 바뀐 데이터만 들어오고
원본 데이터에서 이전 내용 삭제하고
원본 데이터에서 바뀐 내용 삽입
풀리프레쉬와 인크리멘탈 만들어놓음
v2 대그를 백필을 할 때 어떻게 할지
CLI, UI 버전을 본다
