학습주제
사용자 권한 설정 (Snowflake Role)
보안 기능
학습내용

레드쉬프트에서 일부러 GROUP을 사용함. ROLE을 사용하지않음
이번에 ROLE을 사용해서 비교해보려함
레드쉬프트는 상대적 오래된 기술.
대표적으로 스노우플레이크는 사용자 그룹 지원 X
AWS 레거시 호환문제 때문에 못없앰
GRUOP , ROLE 흡사
ROLE은 계승 구조를 지원. 베이스가 되는 role 만들면 계승해나가면서 추가하면 됨.
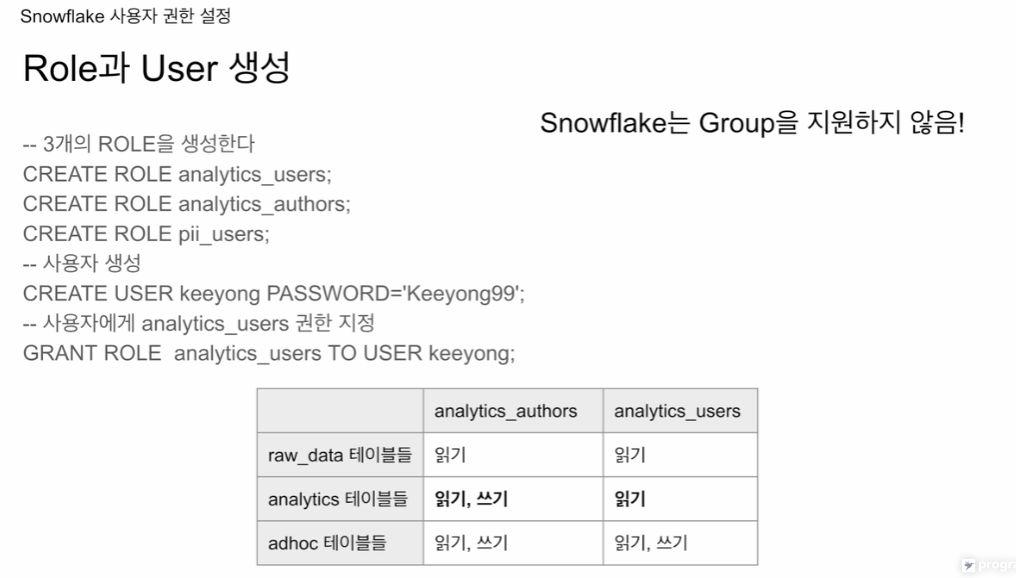
세개의 role을 생성
-- 3개의 ROLE을 생성한다
CREATE ROLE analytics_users;
CREATE ROLE analytics_authors;
CREATE ROLE pii_users;
-- 사용자 생성
CREATE USER keeyong PASSWORD='Keeyong99';
-- 사용자에게 analytics_users 권한 지정
GRANT ROLE analytics_users TO USER keeyong;역할을 유저에게 부여 GRANT
기용이 ROLE을 계승하게 됨
두개의 role에 대해 3개의 엑세스 권한을 다음과 같이 부여
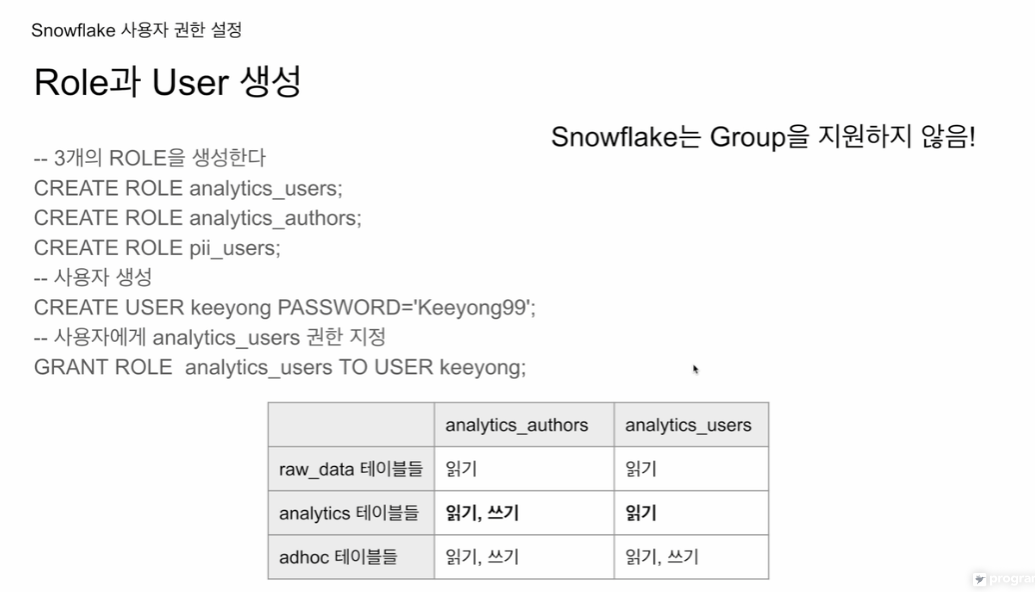
analytics 테이블에 대한 권한이 조금 다름
authors는 분석가들이라 analytics에 대한 읽기, 쓰기
users는 사용하는 사람들 analytics에 대한 읽기만
레드쉬프트에선 각 그룹별로 세팅을 반복으로 해줬음
베이스가 되는 users에 권한을 주고, authors가 계승. analytics에 대한 권한을 바꿔줌.
베이스라인을 만들 때는 GROUP이나 ROLE이나 같지만
이후는 할 일이 확 줄어들음.

--set up analytics_users
GRANT USAGE on shcema dev.raw_data to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.raw_data to ROLE analytics_users;
GRANT USAGE on schema dev.analytics to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.analytics to ROLE analytics_users;
GRANT ALL on schema dev.adhoc to ROLE analytics_users;
GRANT ALL on all tables in schema dev.adhoc to ROLE analytics_users;
--set up analytics_authors
GRANT ROLE analytics_users TO ROLE analytics_authors;
GRANT ALL on schema dev.analytics to ROLE analytics_authors;
GRANT ALL on all tables in schema dev.analytics to ROLE analytics_authors;레드쉬프트 문법과 동일
먼저 스키마에 대한 접근 권한 설정 (all, usage)
그 후 테이블에 대한 (어느 테이블에 접근할 것인지 포함) 접근 권한 (select, all)
변경하고자 하는 정책을 덮어씌우는 식으로

컬럼레벨 보안 제공하기도 함.
보통 개인정보
동일한 조언. 컬럼을 보안을 달리해서 관리하기 보단 빼내서 별개의 테이블로 관리하는게 좋음. 실수하기가 쉬움.
제일 좋은것 이런 정보를 데이터 시스템으로 가져오지 않는 것

위와 같이 적용됨.
정책을 만족하는 사용자만 레코드를 엑세스하게 하는게 아니라
따로 테이블로 빼주거나, 아에 쓰지 말기
오픈소스로 가면 이런 기능들은 좀 부족함. 보안, 세밀한 컨트롤

object: 스노우플레이크 객체. 올거니제이션, 데이터베이스, 스키마, 테이블
tag: 객체에 태그를 달아줌. 시스템 자체 태크, 유저 정의 태그. 오브젝트에 지정함으로써 관리하기 쉽게함. 사용하기가 좀 번거로움. 가장 중요한 태그는. 민감, 개인정보 여부. 태깅의 가장 주된 목적. 이를 위해 data classification
data classification: 스노우플레이크가 자체적으로 분류해줌. 어디 컬럼 이건 식별자, 준식별자 등 자동 태킹을 해줌.
Tag based Masking Policies: 태그에 따라 엑세스 권한을 달리가짐
Access History 사용자별로 언제 시스템에 로그인, 어떤 테이블 select, join 했는지 컬럼 기준으로 기록. 나중에 감사하기 위함. 보안 관계 이슈 발생했을 때 조사.
object dependencies: 데이터 리니지. 이미 만들어진 테이블로 ELT. 새로운테이블에 기존 테이블의 보안걸린 컬럼이라는게 전파가 안되면 문제가 생김. 원본 테이블이 갖고있는 속성들이 JOIN 해서 새로운 테이블을 만들 때 속성이 따라가야함.
특정 컬럼에 걸린 접근 권한 -> 새로운 테이블 만들때도 그대로 따라가야함.
계승 관계를 명확히 알 수 있으면 원본 테이블의 컬럼 이름을 바꾸거나, 타입을 바꿀 때 더 조심할 수 있음. 이걸 부주의하면, 다른 사람들이 JOIN할 때 모르고 할 수 있음.
데이터 거버넌스

데이터가 중요해지면서, 정말 데이터 품질이 믿고 사용할 수 있는지, 개인정보가 과도하게 노출되어 법률 이슈가 있는지.
데이터 품질 보장, 개인정보 보호 법규 준수 목적을 위해 여기저기 프로세스를 만듦
- 데이터 기반 결정에서 일관성
- 데이터를 이용한 가치 만들기
- 데이터 사일로, 데이터 독점 없어야함 - 데이터 관련 법규 준수
데이터 사용자들이 그 뒤에 사용자들이 쓸지 예상을 안하고 만지는 경우가 많음
데이터 웨어하우스 단에서 거버넌스가 많이 구현되는 중
스탠다드 레벨에선 사용 불가 -> 엔터프라이즈에서 사용가능
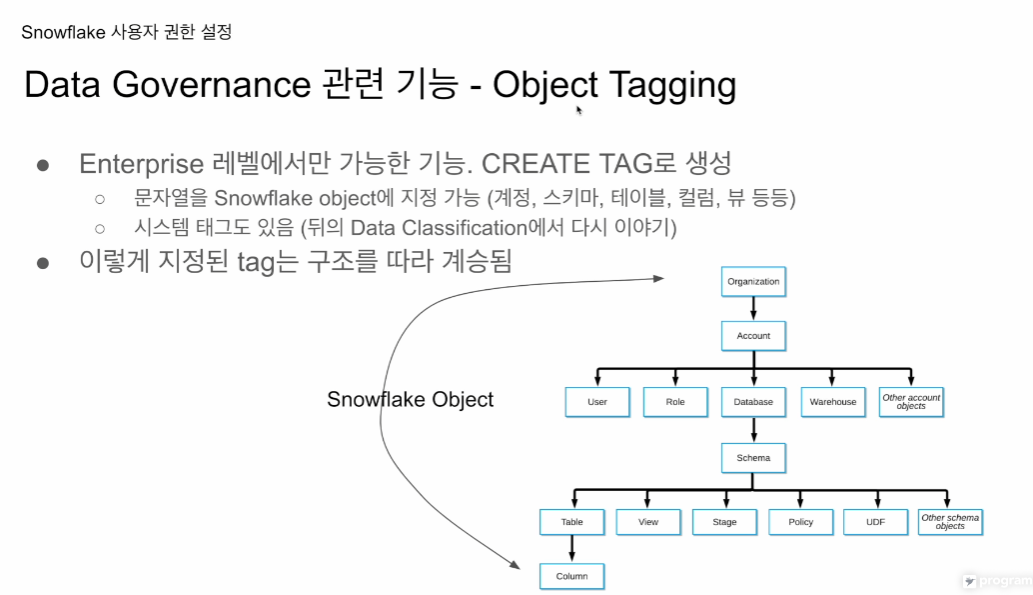
다 오브젝트임.
기존 태그도 있고, 유저 정의 태그도 있음
어떤 특정 데이터베이스에 태그 달면 하위 오브젝트에 계승됨.
태깅 이유 - 메타 데이터 생성. 개인정보과 관련된 데이터가 무엇인지. 민감정보가 무엇인지.

사람이 일일히 메뉴얼하기 어려운 점을 보완. 일종의 반자동화
Analyze: 그 테이블 내에 데이터를 보고 컬럼별로 민감정보 있는지 자동 분류.
Review: 위의 분류결과를 보고, 최종 리뷰
Apply: 그럼 최종 시스템 태그
프라이버시 카테고리
- 아이덴티파이어 : 개인정보. 식별자
- 콰지 아이덴티파이어 : 이것들이 합쳐지면 개인을 식별가능. 준식별자
- 센서티브 : 연봉
시멘틱 카테고리 - 위의 카테고리들을 좀 더 자세히 알려줌.
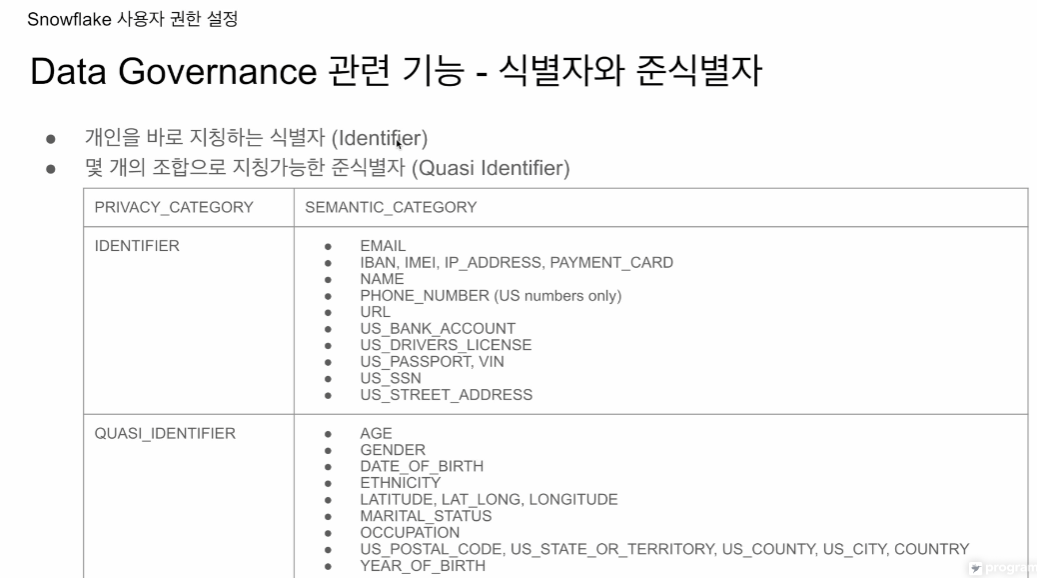
식별자
준식별자
시멘틱 카테고리가 좀더 세부적인걸 알 수 있음
-
아이덴티파이어 한 개인을 지칭(특정)할 수 있음
-
콰지 아이덴티파이어
미국 중심으로 식별이 동작함

태그를 바탕으로 엑세스 권한을 지정해줌

기록을 남김으로써, 누가 개인정보에 접근했는지 감사 추적을 제공
다른 클라우드 데이터 웨어하우스도 제공

시스템 무결성 유지 목적
가장 유용한 기능 - 별 생각없이 만드는 데이터에 이름을 바꾸거나, 컬럼을 삭제. 데이터 시스템이 복잡해지면, 내가 만든 데이터를 누가 수정하는지 알 길이 없음. 뒷단의 테이블이 연달아서 에러가 남.
연관관계를 다 파악해서 의존도가 있는 테이블의 이름, 컬럼을 변경할 경우 일종의 경고메세지를 날려줌.
