학습주제
Redshift COPY 명령으로 테이블레 레코드 적재하기
AWS IAM Role 사용
학습내용
목표

- COPY로 레코드 적재
- CSV s3에 생성
- 레드쉬프트 s3 접근권한 생성
S3, IAM 에 대한 간단한 학습도
테이블 만들기

raw_data 스키마를 통해 아 이 테이블은 외부 소스를 ETL 통해 가져왔다는 것을 알 수 있음.
CREATE TABLE row_data.user_session_channel(
userid integer,
sessionid varchar(32) primary key,
channel varchar(32)
);
CREATE TABLE raw_data.session_timestamp(
sessionid varchar(32) primary key
ts timestamp
);
CREATE TABLE raw_data.session_transaction(
sessionid varchar(32) primary key,
refunded boolean,
amount int
);
AWS에서 S3 버킷을 만들고 거기로 업로드. csv형태. 각 테이블에 상응. 각 파일들은 링크를 받으면 됨.
접근 권한 설정

redshift 클러스터에 IAM 역할 부여
COPY명령 사용시
이 역할에 해당되는 ID, ARN을 활용하여야함
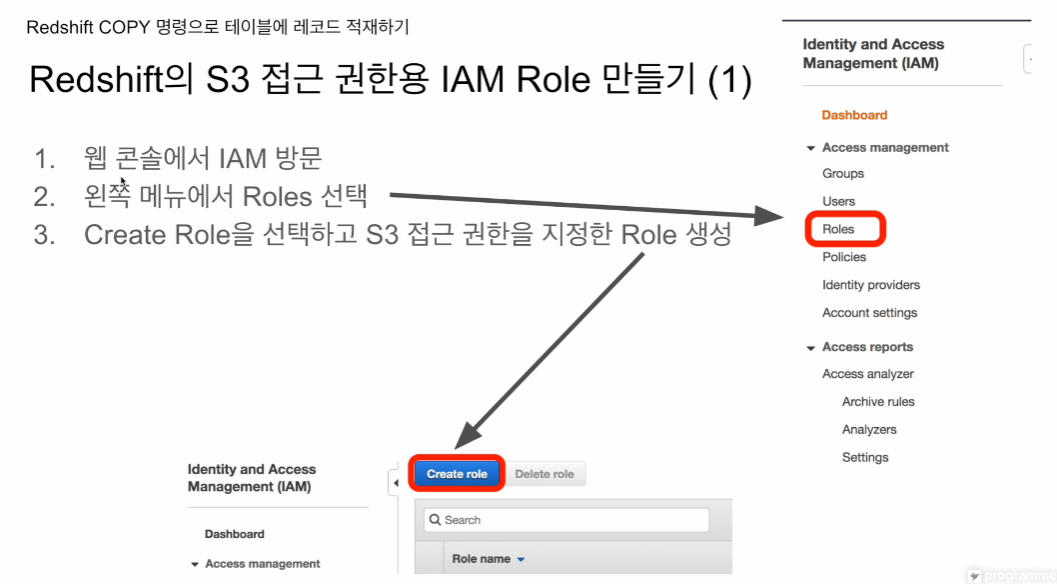
IAM - 역할 - 역할 생성
신뢰할수 있는 엔터티 유형 - AWS 서비스
다른 AWS 서비스 - redshift 선택
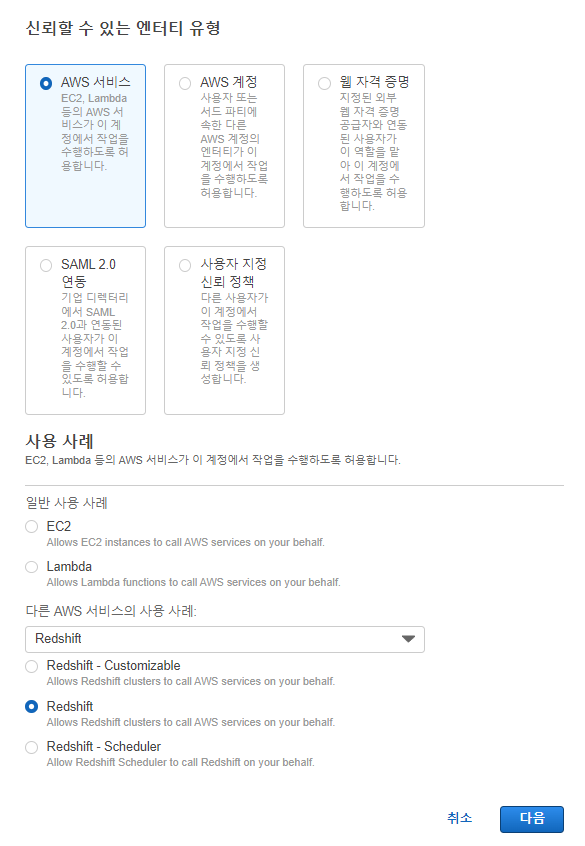
다시말해 Redshift에게 주고 싶은 권한
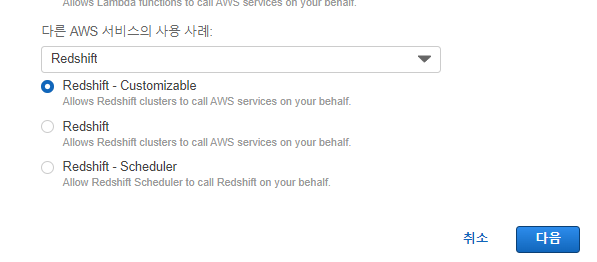
3가지 유형이 있는데 - Cutomizable 선택
다음 화면은 레드쉬프트가 어떤 권한을 가질 것인지이다
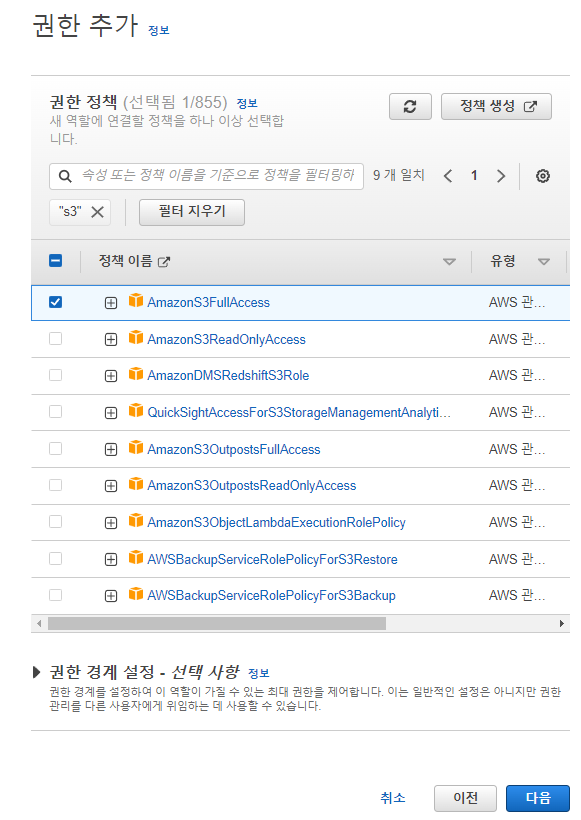
지금은 풀엑세스
만일 읽기만 지원한다면 ReadOnlyAccess를 선택
리뷰 화면에서 이름 선택
redshift.read.s3라는 역할을 생성
레드쉬프트 클러스터한테 s3한테 접근할 수 있는 권한.
역할 생성
역할을 클러스터에 지정
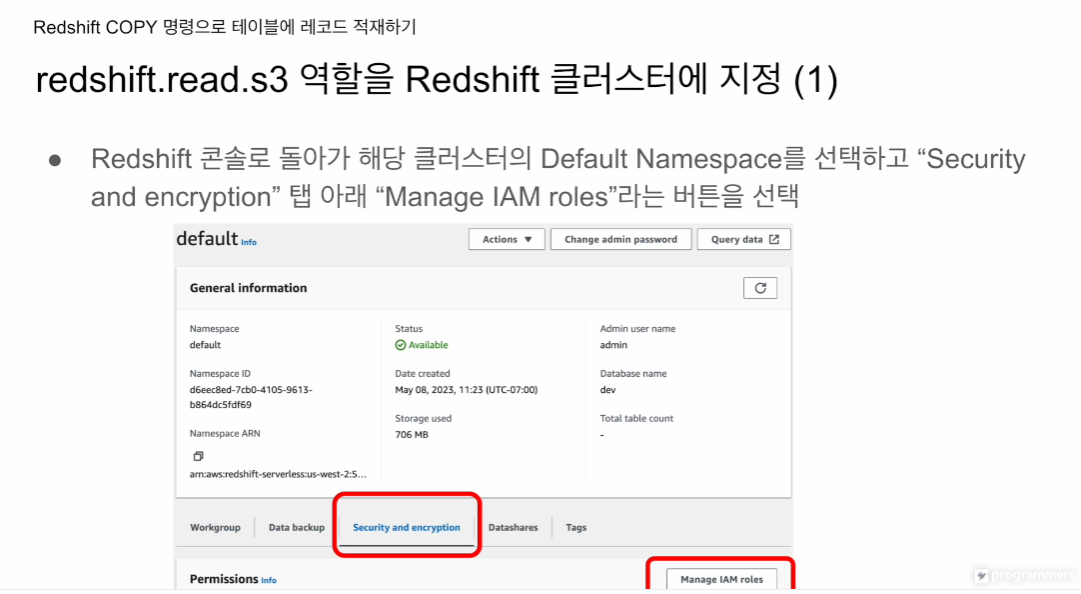
레드쉬프트 콘솔로 돌아가 지정하려는 클러스터를 선택
네임스페이스 - Default 선택
보안 및 암호화 - IAM 역할 관리 선택
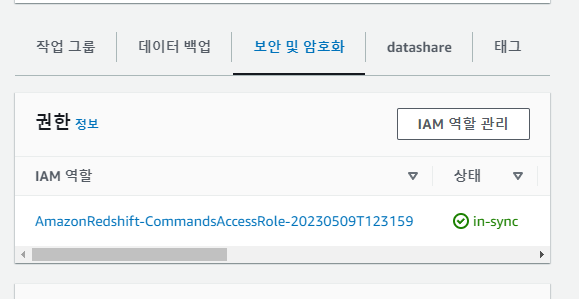
IAM 역할 연결에서
전에 만든 역할 클릭
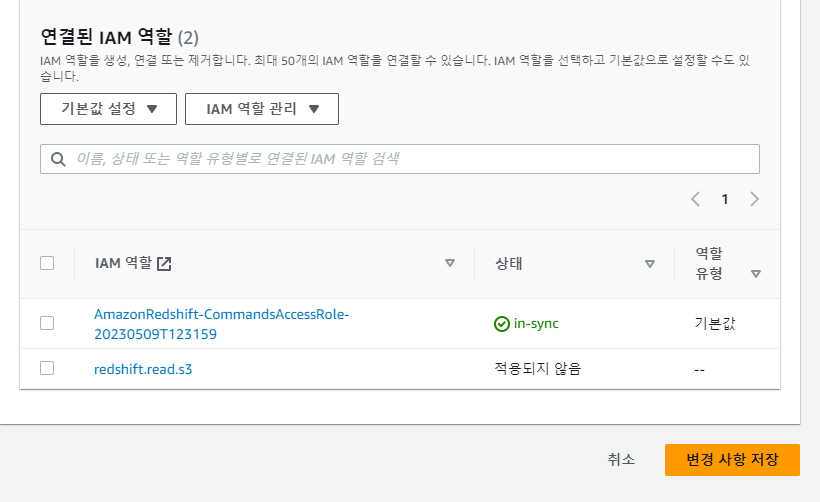
추가된거 확인 후 변경사항 저장
이제 이 클러스트는 같은 어카운트에 있는 S3에 접근을 자유자재로 할 수 있음

레퍼런스 참조
https://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html

COPY 복사받을 테이블
FROM s3주소 파일이름.scv
credential ARN
delimiter ',' 쉼표로 구분
dateformat 'auto' -- 날짜는 알아서
timeformat 'auto' -- 시간도 알아서
IGNOREHEADER 1 첫번째 헤더 무시
removequotes 문자열 "" 제거
ARN은 IAM 들어가서 역할 클릭하면 카피할 수 있게 되어있음
ARN - 머신이 이해할 수 있는 ID
에러가 났을 경우

각 에러가 발생한 시간을 기준으로 내림차순으로 해서 보면 됨.
그럼 카피 명령 중에 어떤 필드에서 에러가 났는지 알수있음
해당 테이블의 필드 타입과 , csv 타입이 앉맞거나, 길이가 충분치 않거나 등등 있음
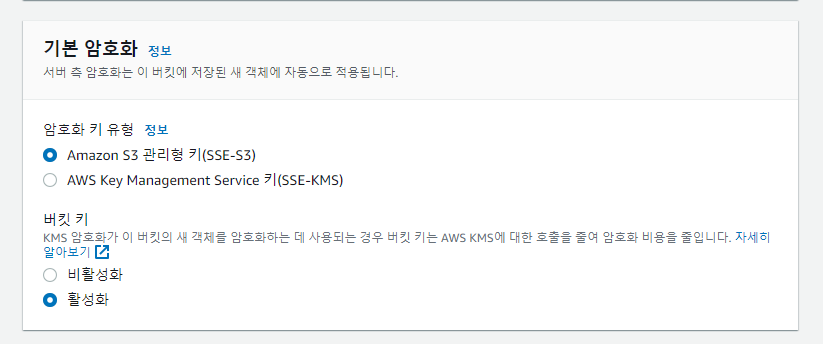
S3 생성시,
기본 암호화 이거 어떻게 해야할지 모르겠음
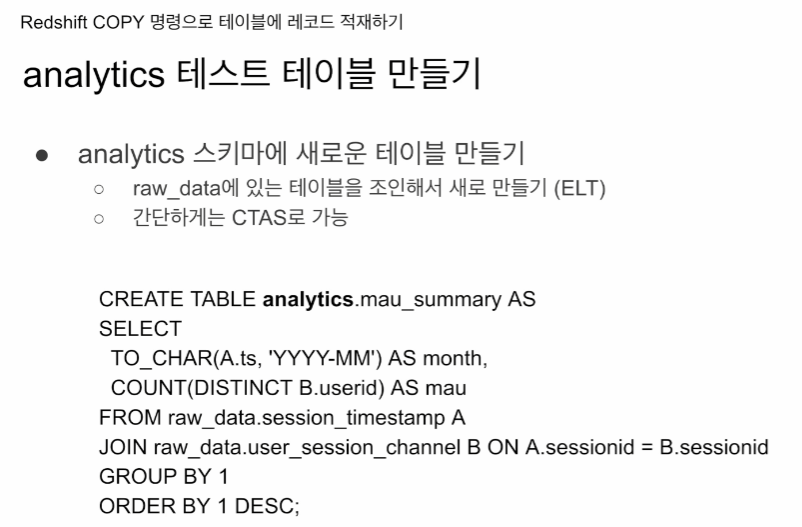
raw_data에 존재하는 테이블을 조인해서 새로 만들기 (ELT)
CTAS로 구현
CREATE TABLE analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;