학습주제
최종정리
학습내용

강의 80% 에어플로우
중요한 것은 데이터 파이프라인
2가지 작용
데이터 시스템 바깥을 안으로 ETL
시스템 (작게는 DW, 크게는 DL 포함)
ELT로 안에서 또 새롭게 만들어냄
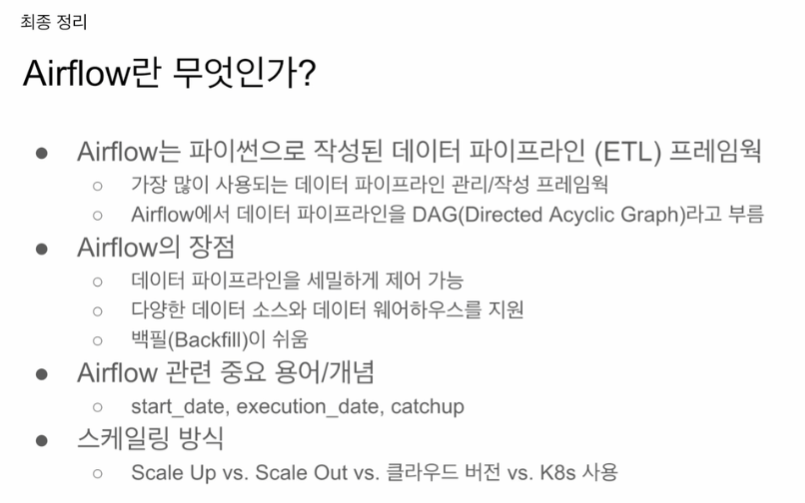
에어플로우
파이썬 오픈소스 기반 데이터 파이프라인 작성, 관리, 운용 프레임워크
에어비엔비에서 만들었음.
파이프라인을 DAG라고 함.
하나의 대그는 하나 혹은 그 이상의 태스크.
태스크는 하나 이상의 오퍼레이터 클래스의 인스턴스들
네이티브하게 제공 많이 됨.
보통 없으면 파이썬 오퍼레이터 써서 @task
장점.
파이프라인을 오랫동안 작성했던 사람이 만들었기 때문에 엔지니어가 운영관점에서 백필이 어려운 일이 있는데 해결해줌.
execution date, catchup start_date을 이해하면 쉬움.
러닝커브가 다소 있음.
굉장히 큰 커뮤니티가 있기에, 소스, 목적지(DW)를 쉽게 제어할 수 있는 오퍼레이터들을 만들어서 기여했기 때문에 코딩이 상당부분 쉬움.
MySQL-Redshift만 해도 오퍼레이터 2개 썼더니 바로 가능했었음.
이번엔 레드쉬프트만 썼지만, 빅쿼리, 스노우플레이크 등도 있음.
믿고 쓸수 있음
일부 개념들이 한번에 와닿지 않는 경우가 있음
1월 2일이 되어야 1월 1일 데이터를 실행시킬 수 있음 (start date)
execution date을 가지고 해당 날짜에 바로 접근할 수 있음. 따로 메타데이터 DB에서 관리
catchup 실행이 안된 잡들을 어떻게 할 것인가
start date - 현재 날짜까지.
기본이 True임
풀리프레쉬이면 True로 할 필요가 없음. False로 세팅
에어플로우도 스케일링 하는 방법이 있는데
대그 수 없으면 서버 하나로 세팅
대그 수가 많아지면 어떻게 하냐가 중요해짐
4가지 방식이 있음
서버의 사양을 높임 (CPU, 메모리). 어느 시점에선 한계
서버의 수를 늘림 scale out. slave node는 워커노드들 마스터는 1대.
어느방식으로 갈지 정해야함
클라우드버전으로 가면 3개 업체가 모두 에어플로우를 지원함. 회사의 상황이 좋고 정말 처리해야하는 대그 수가 많으면 클라우드 버전을 사용하는게 좋음. 쿠버네티스를 사용하게 할수도 있음.
공용 쿠버네티스 클러스터의 리소스를 가져다 쓸 수도 있음.
다음에 쿠버네티스 배울 때 이게 에어플로우와 어떻게 연동되는지 배움

베스트 프랙티스임.
파이프라인 몇개 안되면, 정보를 유지하지 않아도 됨. 사람들에게 물어봐도 되고.
파이프라인 수가 늘어나면 누가 요청한건지 알 수도 없고, 해당 데이터 파이프라인이 동작을 안하거나, 삭제해야할 때 어느사람이 요청한건지 기록이 안남으면 조사에 시간이 소모됨.
비즈니스 오너 - 해당데이터 파이프라인 요청자
데이터 리니지 - ETL을 통해서 외부에서 내부로 가져온 순간, 사람들의 ELT를 통해 조합해 새로운 데이터들을 계속 연쇄적. 계승적으로 만들어짐. 이걸 신경 안쓰면 컬럼 바꾸고, 이름바꾸고 해버림. 이걸 사용할 이어질 파이프라인들이 다 깨져버림. 뒷단에서 어떻게 사용할지 흐름을 파악하고 있어야 함.
데이터에 대한 데이터 - 메타데이터를 관리하고 검색하기 쉽게 만들어야 함. - 데이터 카탈로그
데이터 디스커버리 툴이 생김.
파이프라인 수가 늘어날수록 품질관리 어려움.
품질을 어떻게 체크할 것인가? 어떤 입력이 정상인지, 새로만들어낸 데이터가 기대하는 품질을 갖고 있는지. 코드를 짤때 유닛테스트로 체크하는 것처럼. 파이프라인도 입력과 출력단에 품질체크가 필요함.
다양한 툴들이 있음 - 고도화 세션때 배울 예정.
풀리프레쉬를 하는 것하면 문제가 생긴것도 싱크해줌.
인크리멘탈 업데이트를 해야한다면 꼭 execution date 사용
주기적으로 청소작업을 해줘야 함. 데이터를 요청하는 일도 비슷하게 필요가 끝나면 잊어버림. 혹시라도 나중에 필요하지 않을까 해서 말을 안하는 경우가 있음.

오퍼레이터 중
A 끝나면 B 트리거해주는,
상황에 따라 조건, 분기 task 결정해주는 오퍼레이터 있음
스프레드시트, 슬랙 연동
클라우드 환경
도커가 점점 더 많이 쓰임
태스크가 실행되는 환경도 쿠버네티스로 꾸며서 도커로 실행
현재까진 크기가 크지 않았음
판다스로 처리 가능해졌음
너무 커지면 스파크로 처리해야함.
빅데이터 프로세싱이 갖고 있는 문제점. 데이터를 다수의 서버로 분산해야함. 불균등이 생기면 이슈 발생. 하둡, 스파크건 어떻게 데이터를 균등하게 분산할 것인가 임.
전부 주기적으로 배치 프로세싱으로 처리
리얼타임으로 계속 처리. 연속적인 처리에 대해 배워봄
카프카 중심. 키네시스도 조금
후기
아.. 정말 시행착오를 너무 많이 겪은 챕터이다. 윈도우 환경이라 그런지, 모르겠지만 수업 외적인 에러가 정말 많이나서 정말 많이 해멨던거 같다. 동시에 뭐랄까 수업을 듣는게 조금 부담스러운 순간도 왔었던거 같다. 수업 자체가 어렵다기 보단 이로인해 또 발생할 수많은 오류들을 어떻게 해결해 나가야하나.. 결과적으로 어떻게든 해결하고 이렇게 글을 쓸수 있어서 좋다.
