학습주제
트랜젝션과 SQL 고급



- 사용자별 처음과 마지막 채널 찾기
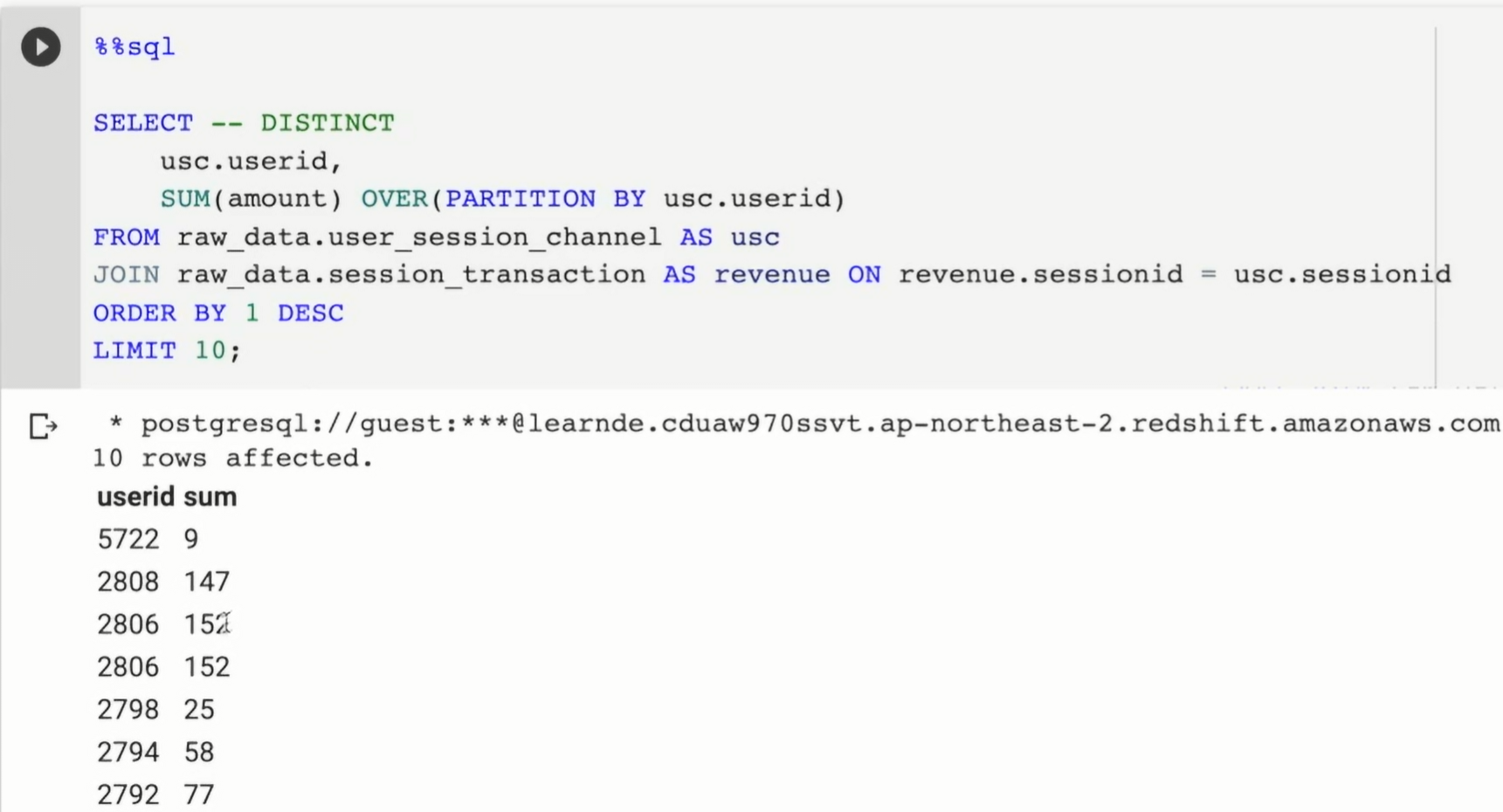
- Gross revenue가 가장 큰 사용자 ID 10개
- NPS
숙제 1 처음채널, 마지막채널

직접 노가다로 접근하는 방법에 대해 알아보았다.
-> 다수의 사용자에 대해 접근하는건 부적절. 일반화 방법이 필요.
-> 처음과 마지막 채널을 바로 접근하고 싶음.
그 후 ROW_NUMBER()을 사용하여 각 그룹별 일련번호를 부여케한다.
- PARTITION BY userId
- ORDER BY ts
중복되는 userid를 그룹핑하여, 그 안에서 일련번호를 ts의 오름차순으로 붙인다.

지난번 CTE를 배웠다. WITH AS로
보면 first 테이블, last 테이블만들었다.
2개의 임시 테이블은 저렇게 만든다.
그리고 두 테이블을 JOIN하였는데 뒤에 처음보는 조건이 붙는다.
WITH first AS(
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_transaction st ON usc.sessionid=st.sessionid
), last AS(
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts DESC) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_transaction st ON usc.sessionid=st.sessionid
)
SELECT first.userid AS userid, first.channel AS first_channel, last.channel AS last_channel
FROM first
JOIN last ON first.userid = last.userid and last.seq =1
WHERE first.seq=1;userid는 중복된 값이다 last.seq =1 -> first.seq 1~끝까지 하나씩 대입하여 레코드를 생성함. 증폭됨.
우리가 원하는 것은 last.seq =1, first.seq =1 이므로, WHERE에서 언급해준다.
JOIN의 증폭을 활용함.
이번엔 INNER JOIN이라 WHERE에 언급해도 되나,
일반적으로 FROM의 조건은 WHERE에서 언급하고.
JOIN 우측테이블은 JOIN 시 언급한다.
다양한 접근법이 있다. 이번엔 아까 생성한 first와 last를 바로 JOIN문에 집어넣음

뭔가 딱 봐도 번잡하고 가독성이 떨어지는 느낌이다.
FROM 에서 네스팅을 통해 first, last 테이블을 만들고 JOIN 까지 해버림
FROM(
first JOIN last ON first.userid = last.userid and last.seq = 1
WHERE first.seq =1;
기본 구조는 비슷하나
임의의 테이블을 생성하지 않고 바로 FROM에서 처리한다는 차이가 있다.
FROM 안에서도 앨리어스를 적용할 수 있음.
개인적으로 CTE를 빌딩 블록으로 사용하는게 가독성이 좋았음

여기선 GROUP BY를 해야지만 userid가 1개만 생김. 그리고 이 1개 에서 각자 first_channel, last_channel을 집계함수 MAX로 출력함
GROUP BY 뒤엔 AGGREGATE 함수밖에 못씀.
보면 CASE WHEN으로 임의의 필드를 생성함.
- 필드는 first의 경우 Facebook을 레코드 1개 있고, 나머지는 모두 NULL
이 경우 MAX를 해주면 숫자가 아니어도 facebook을 max값으로 인식하고 리턴해주는 것 같다.
MAX(CASE WHEN rn1 = 1 THEN channel END) first_touch
일종의 편법같은 느낌. 사용자 id를 기준으로 모아버림

제일 간단한 방법
SELECT DISTINCT
A.userid,
FIRST_VALUE(A.channel) over(partition by A.userid order by B.ts rows between unbounded preceding and unbounded following) AS First_Channel,
LAST_VALUE(A.channel) over(partition by A.userid order by B.ts rows between unbounded preceding and unbounded following) AS Last_Channel
FROM raw_data.user_session_channel A
LEFT JOIN raw_data.session_timestamp B ON A.sessionid = B.sessionid;
over 안 구문은 동일하고 호출 함수명만 다름.
일련번호를 붙이는데 ts 값을 기준
rows between unbounded preceding and unbounded following 이거 처음 봄.
이렇게 뒤에 attribute를 적어줘야함.
일종의 디폴트라고 생각해주면 됨.
ordering 할 때 좀더 자세하게 선택할 수 있음.

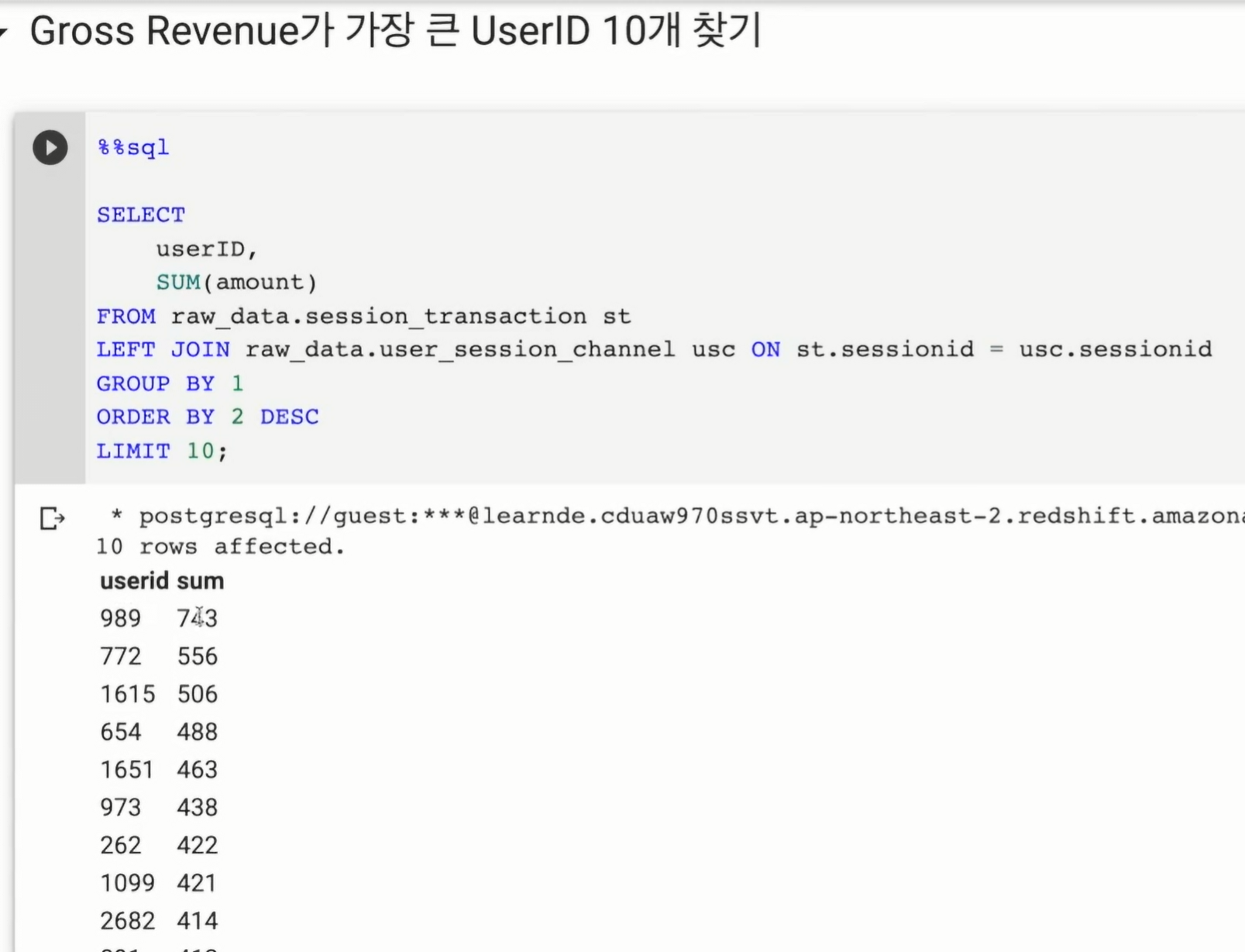
amount를 모두 합산함.
net revenue의 경우 refund 제외

내가 썼던 방법. 사실 JOIN도 필요 없는거 같음
현재는 INNER, LEFT 상관 없음 1:1로 모두 매칭됨
만일 없는 ID가 존재할 경우 LEFT 고려
LIMIT 10으로 하게되면 마지막에 동점자들이 있다면, 동점자들 중 1명만 선택됨.
-> 조금 더 개선하면, 동점인 사람까지 리턴할 수도 있음. 참고.

GROUP BY를 안쓰고 window 함수 사용
OVER를 사용해 그룹을 지정함.
GROUP BY와 언뜻 유사해보임.
GROUP BY를 사용하면 userID 하나당 필드가 1개
SUM OVER을 사용하면
userid는 조인에서 나온 숫자만큼 동일한 수의 레코드에 대해
유저 251번이 10개의 레코드가 존재했다면. 이 SUM(amount)가 계산됨.
동일한 유저 아이디가 여러번 등장할 수 있음.
-> 이에 DISTINCT를 붙임
userid를 그룹핑 시키는 것이아니라. 그 userid마다 마다 SUM 값이 반복적으로 붙음.
-> 이러다보니 GROUP BY를 선호함. DISTINCT 때문에 퍼포먼스가 떨어짐.

두가지 방법이 있음.

FROM 에서 nesting으로 임의의 테이블을 만들어서
SELECT에서 다시 참조함.
*100일 경우 정수 나눗셈이 되어 꼭 ::float로 타입 캐스팅 해줘야함.

어차피 전체 수에서 긍정수 - 부정수의 퍼센티지를 구하는 것과 같기 때문에 별도로 필드를 만들어 긍정이면 1, 부정이면 -1을 하여 SUM 해준뒤 이 값을 바로 구함. 상당히 깔끔
SELECT LEFT(created, 7) AS month,
ROUND(SUM(CASE
WHEN score>=9 THEN 1
WHEN score<=6 THEN -1 END)::float*100/COUNT(1),2)
FROM raw_data.nps
GROUPY BY 1
ORDER BY 1;보면 라운드 안에 SUM이 있어 결국 month 별로 그룹을 모아 SUM을 집계한 모습임. 부차적인거 다 떼면.
분자를 집계함수로 계산해버림.
실습
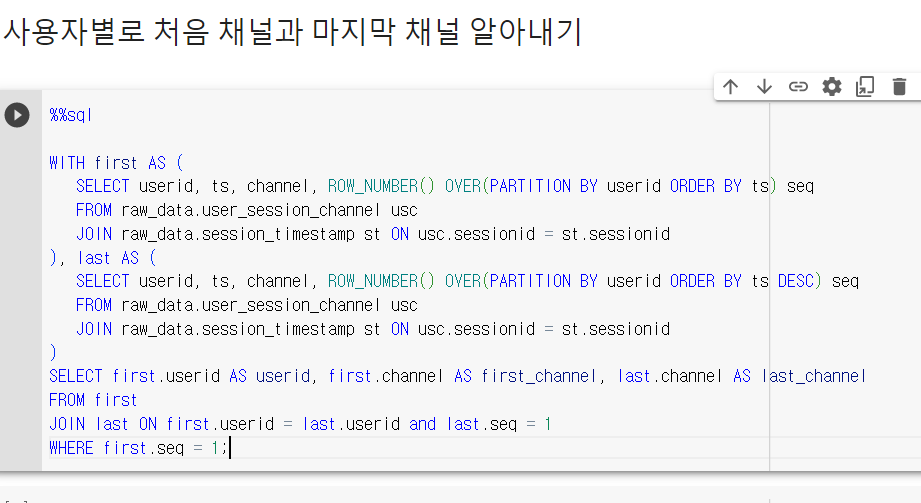
- 임의의 테이블 first, last 생성
- fist last를 JOIN 이때 우측 last.seq = 1의 조건을 달음. -> 증폭
- 다시 FROM 테이블인 WHERE에 first.seq =1 을 달아 원하는 레코드 출력
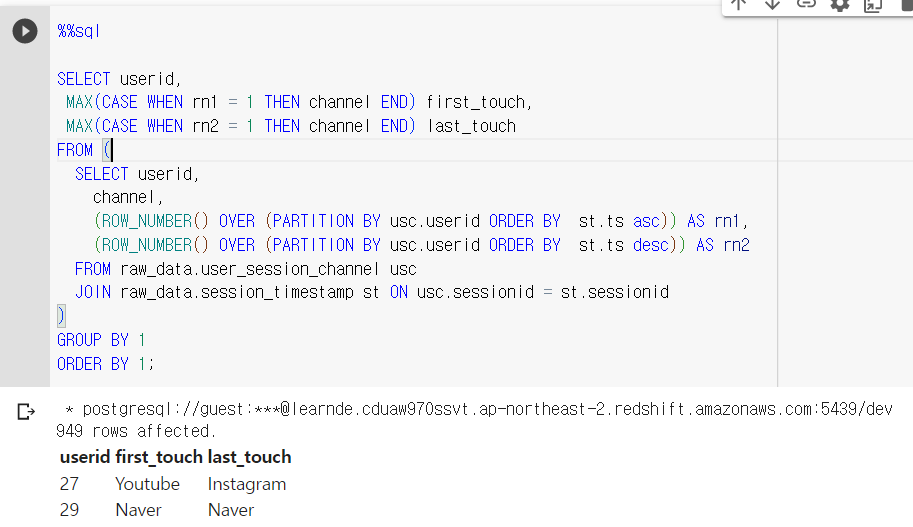
편법이긴 하나, 상당히 깔끔함.
MAX, MIN 둘다 상관 없음 NULL은 무시하고 문자열 1개만 있기 때문.

GROUP BY 안쓰기에 DISTINCT 걸어줌. 아님 중복된 userId만큼 출력됨.
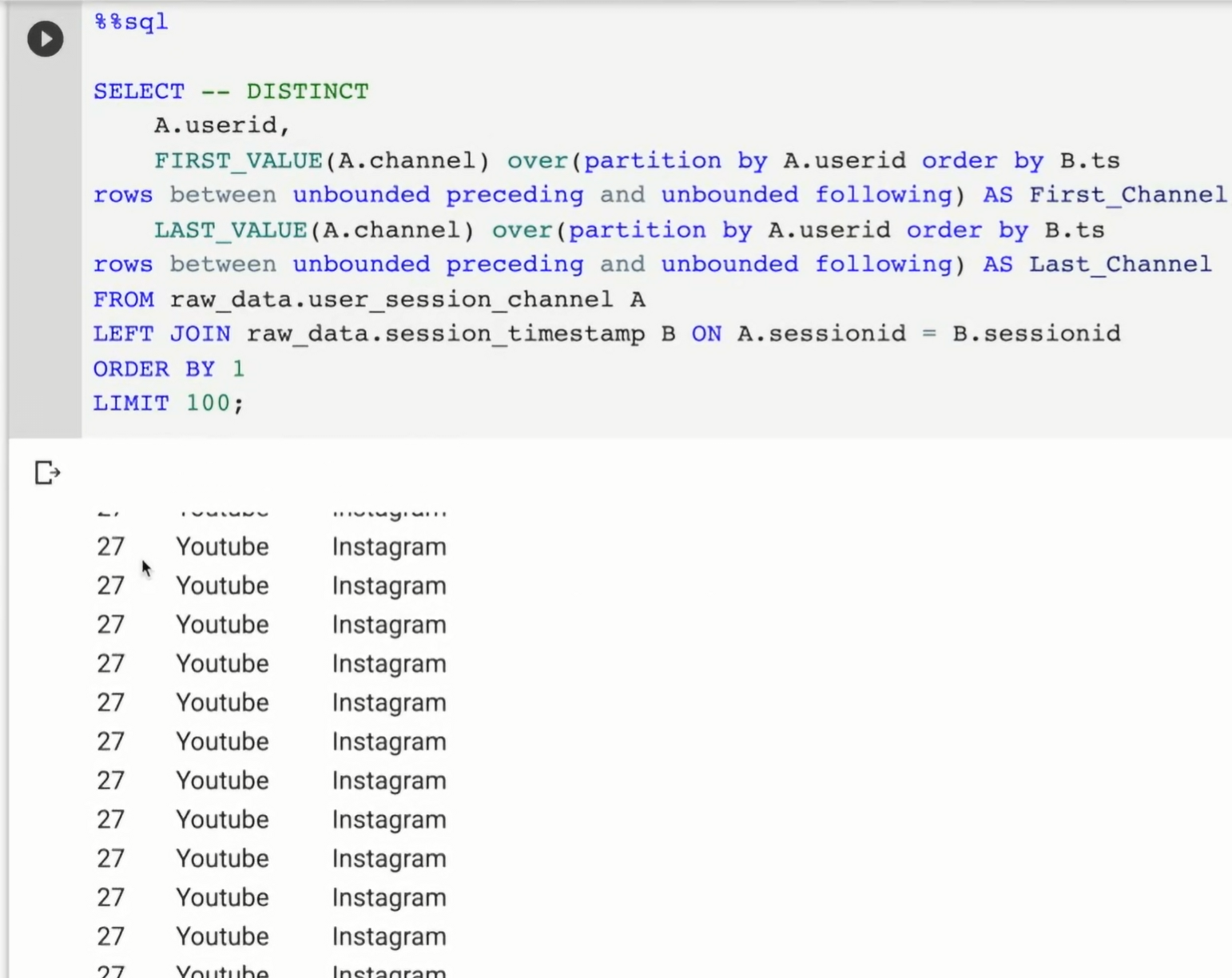
rows between unbounded preceding and unbounded following
디폴트라 생각.
DISTINCT를 안쓰고 1개의 유저만 남길 수도 있으나 쉽지 않음.

window를 사용한 모습.
GROUP BY를 하지 않았기 때문에 userId의 중복 발생. DISTINCT 써야함.


분자 계산을 SUM으로 처리해버림.
트랜잭션 소개와 실습

Atomic? 여러개의 sql인데 동시에 성공하던지 동시에 실패해야지 데이터의 정합성에 문제가 없는 경우.
은행 계좌이체가 좋은 예
-
인출, 입금의 두 과정으로 이뤄짐. 동시에 성공하던지, 동시에 실패해야함. 안그러면 계좌 잔액에 문제가 생김.
-
나는 인출되었다 뜨는데, 상대방은 돈이 받은 기록이 없음.
-
따라서 모두 실패로 처리해버리는 게 나음.
-
이를 Atomic. 마치 한 operation
-
조회는 Atomic 하지 않음. 1개가 실패했다고 해서 문제되지 않음.
-
이체는 잔액의 정보를 새롭게 업데이트하기 때문에 Atomic해야함.
-
Writing. INSERT, UPDATE, DELETE, DROP, CREATE, ALTER
-
BEGIN과 END 사이에 넣어주면 중간에 sql이 하나라도 실패하면, BEGIN 전으로 돌아감 -> ROLLBACK
-
트랜잭션 COMMIT True인 경우임.
-
COMMIT False인 경우도 별도로 다룰 예정.
-
BEGIN ~ END, BEGIN ~ COMMIT

모든 스테이먼트는 ;로 끝나야함.
BEGIN, END는 각각의 statement임.
sql은 프로그래밍 언어는 아니기 때문에 특정 상태에 따라 ROLLBACK 할 수 는 없음. 단순 실패만 판담. 다른 프로그래밍을 쓰면 분기를 사용할 수도 있음.
COMMIT MODE
RedShift에 있음.

True면 바로 DB에 쓰는 작업이 반영됨.
BEGIN END가 있으면, 바로 데이터에 쓰이지 않고, END, COMMIT 이 실행될 때까지 아무 문제가 없을 경우 반영.
이 작업 이후 다른 사용자는 나의 데이터 변동을 확인할 수 있음.
autocommit = False
모든 상태를 바꾸는 sql에 대해, 내가 명시적으로 COMMIT이라는 명령어를 써야지만 반영. BEGIN ~ END 시스템이 모든 쓰는 sql에 반영이 됨.
내 세션에서는 반영된 것처럼 보이나 COMMIT 호출 전에는 다른 사용자는 모름. 다른 세션에서도 마찬가지.
보통 잘 쓰진 않지만, 내가 정말 세밀하게 이러한 쓰는 sql를 조작하고 싶을 때 사용.

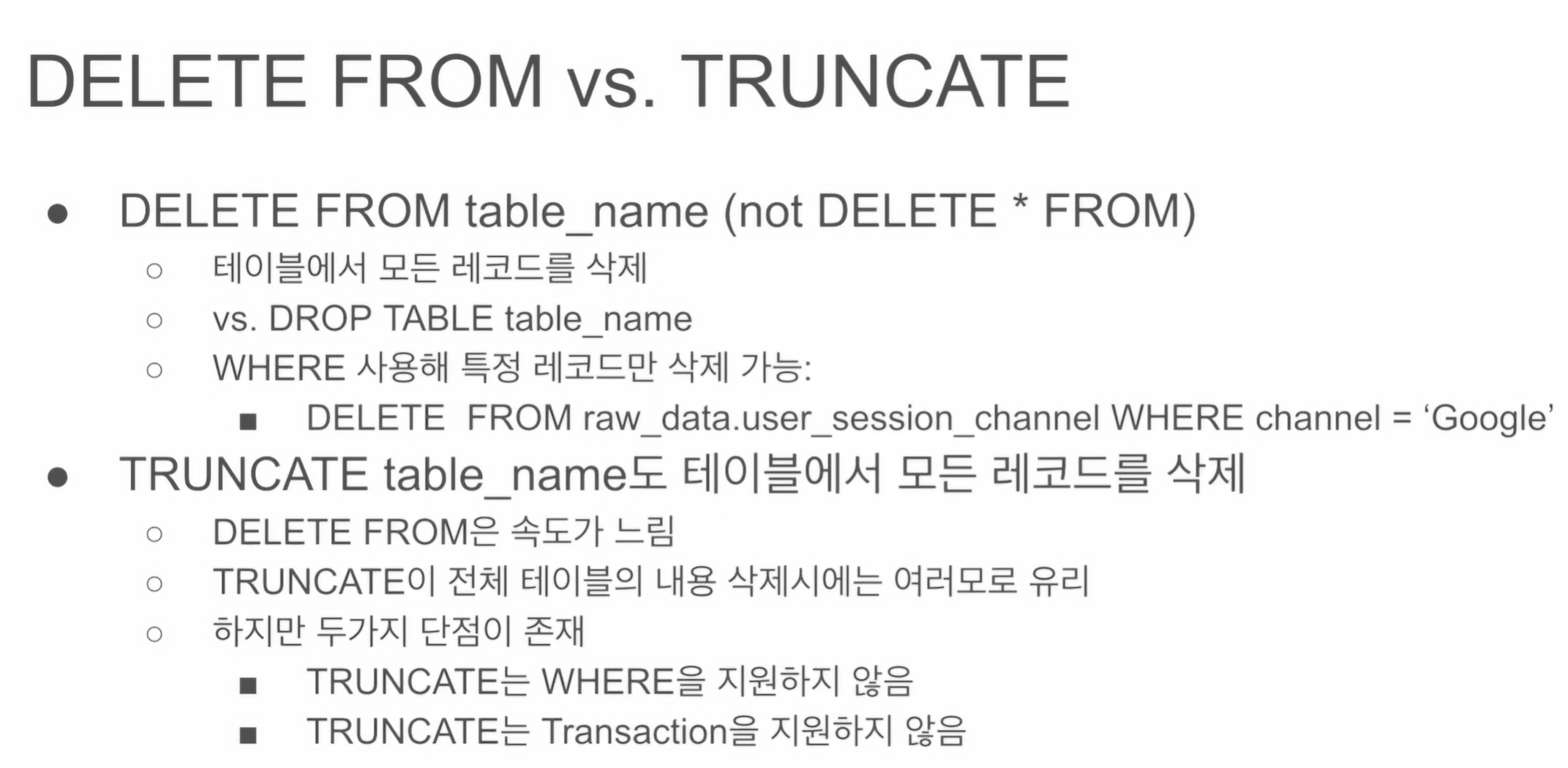
두 예약어의 차이점.
DELETE는 테이블 냄김. 레코드 별로 조건 설정
- DELETE는 트랜잭션 안에서 사용 가능. 롤백 가능
TRUNCATE 테이블 단위로 테이블 값 전체를 날림. - TRUNCATE는 WHERE 지원하지 않음
- TRUNCATE은 Transaction을 지원하지 않음. 롤백이 안됨.
BEGIN ~ END에서 써도 롤백이 안됨.
TRUNCATE은 정말 확실하게 테이블을 날릴 경우에만 사용.
