회사일로 정신이 없다가 다시 블로그를 작성하려고 합니다.
시작은 Spark 설치 ~ Spark 기본 문법까지 설명하려고 합니다.
Spark: Apache Spark는 기계 학습과 AI 애플리케이션 운용 시 대규모 데이터를 처리하는 데 사용되는 오픈소스 통합 인터페이스
사용계기: Pandas로 평소 전처리해왔지만 이번엔 1억건이 안되는 데이터를 전처리 해야하는 상황 발생. Pandas의 read_csv로 하자, 메모리가 부족해 업로드가 안됨. (pandas는 데이터를 메모리에 띄움)
이에 빅데이터를 처리할 수 있고 SQL, Pandas 문법과 유사한 Spark를 사용하기로 함.
사용준비: JDK, Hadoop, Spark 설치
자바의 경우 공식 홈페이지에서 19 버전으로 설치하였다. 너무 최신의 경우 Spark와 연동이 안될 수 있기 때문.
localhost 연결 확인.
ssh localhost
를 쳤을 때 ssh: connect to host localhost port 22: Connection refused 에러가 뜬다면 맥북 > 설정 > 원격 로그인을 활성화 시켜줘야 함.
ssh-keygen
그 후 cd ~/.ssh 위치로 이동하면 퍼블릭키(id_rsa.pub)가 생성된 것을 확인. 생성된 퍼블릭 키를 아래와 같이 authorized_key에 추가.
cat id_rsa.pub >> authorized_keys
chmod 0600 authorized_keys
ssh localhost
위의 명령어를 쳐보면

접속이 잘 되는 것을 확인.
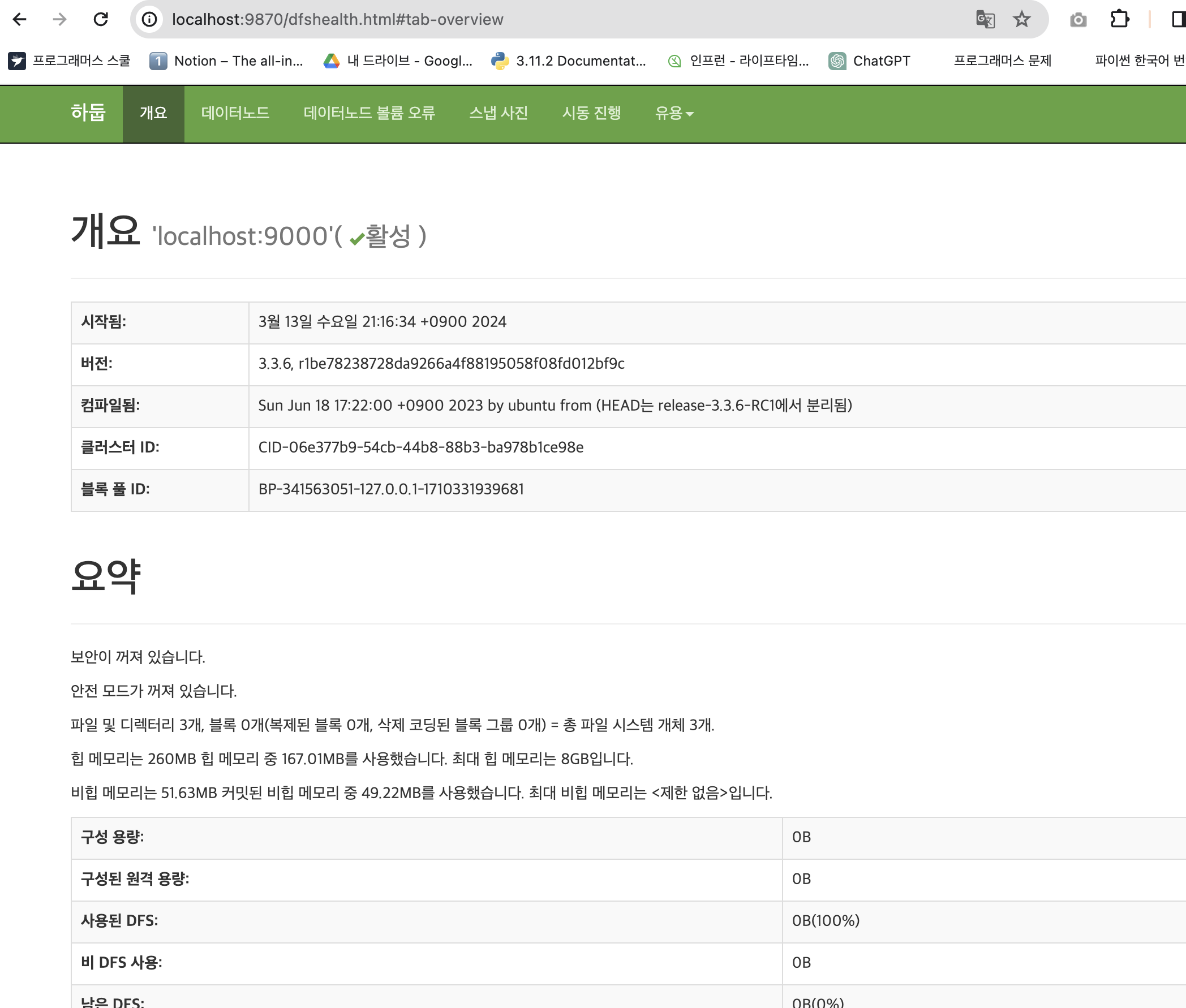
Hadoop 설치.
Hadoop: hadoop-3.3.6으로 설치
설치에 성공하면 다음과 같은 화면 뜸.
추가적으로 작성 예정.
