
학습주제
빅데이터 정의와 예
학습내용

어떤 데이터가 빅데이터인가?

아마존에서 데이터 사이언티스트가 직관적으로 정의
서버 한대로 처리를 못하면 - 빅데이터라고 함.
결국 다수의 서버로 처리해야함. 분산처리의 필요
판다스로 데이터 처리엔 제약 있음. 메모리 제한으로.
하둡이나 스파크 같은 빅데이터 분산처리 환경에서만 가능.
소프트웨어가 달라짐.
기존의 소프트웨어로 처리할 수 없는 규모의 데이터
프로덕션형 데이터베이스. 한대의 서버에서 돌아감.
2번째 정의는, 첫번째 정의와 유사함.
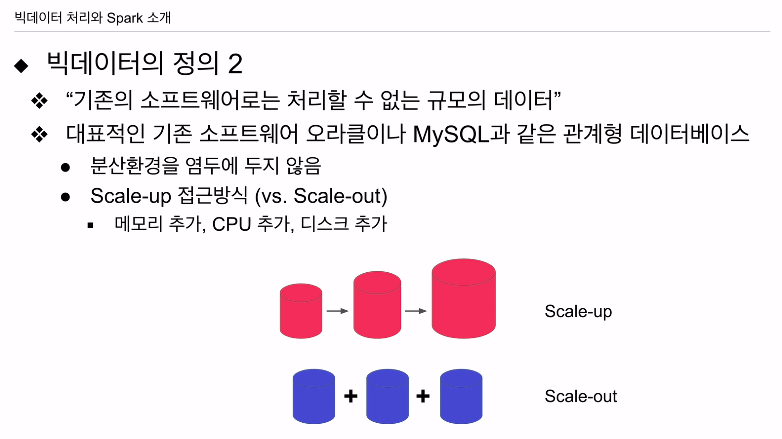
기존 소프트웨어는 처리할 수 있는 데이터의 크기를 늘리려면 스케일 업을 해야함. 계속 한대의 서버밖에 못쓰는 대신 사양을 높임. 메모리, CPU, 디스크 등을 추가함.
분산환경.
하둡, 스파크는 스케일 업도 가능하지만, 서버의 숫자를 늘리는 방식으로 (스케일 아웃) 처리를 가능케함.

컨설팅업체서 사용함
4가지로 특정할 수 있다.
V가 더 늘어날 수 있음.
4개의 V라면
Volume
Velocity
Variety: 테이블, 로그, 오디오/비디오 처럼 비구조화인지
Veracity: 데이터 품질은?
예

스마트폰의 위치정보. 어떠 앱, 행동, 기록들이 빅데이터가 될 수 있음. 계속해서 정보들이 발생하기 때문
굉장히 많은 센서들, 네트워크 장비들도 입출력 데이터가 많음.
새로운 인사이트 도출, 새로운 비즈니스 창출 가능

웹에는 수십조의 웹페이지 존재. 품질이 굉장히 다양함. 쓸데없는 내용부터 정보라 볼 수 없는 컨텐츠도 있고, 위키피디아 처럼 질좋은 데이터도 있음.
이걸 검색하기 쉽게 한건 웹 검색엔진.
크롤해서 (페이지 랭크) 인덱싱하고 제공해줌. 사용자들이 쿼리로 검색할 수 있게 해줌.
구글이 엄청난 공헌을 함. 또한 자기들만 알고 넘어가는게 아니라, 논문으로 공유함.
검색어들을 보면 사람들이 어떤 정보에 관심이 있구나, 독감이 시작됐는지 등 트렌드를 파악할 수 있음. 클릭정보를 파악하면 통계기반 정보를 추출할 수 있음.
웹이라는 거 자체가 빅데이터가 됨.
챗GPT 보면 거대언어 모델 기반으로 만들어졌는데, 훈련데이터도 웹에 있는 위키피디아 같은 고품질 데이터로 훈련시킴.
