https://colab.research.google.com/drive/1Bjq5l544fnqpc71few0Sms3SMBJ2kAgJ#scrollTo=eIF5oQkLSo4-
스파크 세션도 만들어졌고
프로그래밍 준비가 되었다.
앞에서 파이썬 리스트를 RDD로 페레렐라이즈
RDD 결과를 컬렉트함수로 파이썬으로 가져와본다.
RDD를 스파크 상에 데이터 프레임으로 어떻게 바꾸는지 - 실제 메소드 확인
name_list_json = [ '{"name": "keeyong"}', '{"name": "benjamin"}', '{"name": "claire"}' ]
3개의 스트링 엘레멘트들이 들어가 있음. JSON처럼 보이지만, 싱글 스트링임.
루프를 돌면서 한번씩 찍어본다

스트링이 출력됨.
이걸 RDD로 만들어서 스파크 클러스터로 업로드해본다.
스파크가 갖고 있는 오브젝트 중에 스파크 컨텍스트가 있는데, 이를 이용해서 RDD관계된 작업을 할 수 있음. 페러렐라이즈 함수를 부르면서, 3개의 스트링으로 된 파이썬 리스트를 넘기면, 이때 RDD가 만들어짐.
정확히는 스파크 레이즈 엑시큐션? 이시점에선 사실 아무일도 하지 않음
그러나 쓰기 읽기 그런 실제 데이터가 계산되는 작업을 시키면, 그때서야 미뤄논 작업을 함.
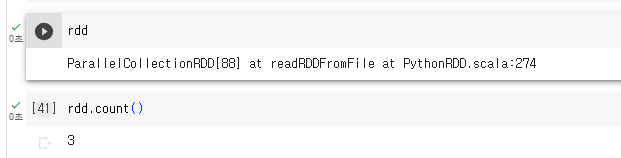
이제서야 파이썬리스트가 스파크 클러스터로 올라가는 작업이 실행됨.
3개의 레코드 있다고 리턴
그다음은 람다함수를 써서
람다함수를 쓰기 편하게 되어 있음.
방금 우리가 봤던 스트링들이 JSON 형태도 있으나, 그냥 스트링으로 존재했는데, 람다함수를 써서 스트링들을 JSON 스트럭쳐로(딕셔너리) rdd로 만드는 것임. immutable 오브젝트라 기존 rdd를 바꿀순 없고, 새로운 rdd를 만들 때 람다 함수를 써서, 스트럭쳐 형태로 파싱하는 것임.

parsed_rdd = rdd.map(lambda el: json.loads(el))
RDD의 map 함수는 RDD에 포함된 각 요소에 주어진 함수를 적용한 결과로 구성된 새로운 RDD를 반환합니다.
이 코드에서는 map 함수에 lambda el:json.loads(el) 이라는 람다 함수를 인자로 주었습니다. 이 람다 함수는 입력된 각 요소 el에 대해 json.loads(el)를 실행합니다. json.loads() 함수는 JSON 형태의 문자열을 Python의 데이터 구조(사전, 리스트, 문자열, 숫자 등)로 변환합니다.
따라서 이 코드는 rdd에 포함된 각 요소가 JSON 형태의 문자열이라고 가정하고, 이들을 Python의 데이터 구조로 변환하는 작업을 수행합니다. 이렇게 변환된 결과는 parsed_rdd라는 새로운 RDD에 저장됩니다. 이후 parsed_rdd를 사용하여 추가적인 데이터 처리 작업을 수행할 수 있습니다.
얘도 찍어보면 별거 없음.
드라이버 쪽에 있는게 아니라, 스파크 클러스터에 있음. 자세한 정보를 알 수는 없음.
collect 메소드를 통해 파이썬 쪽으로 가져와 본다

각각이 스트링이었는데, 람다 함수를 써서, JSON 구조를, 딕셔너리형태로 바꿨었음.
더 나아가, rdd에서 json 스트링을 파싱을 하고 거기서 name 키의 value를 읽어오게 한다.
parsed_name_rdd = rdd.map(lambda el:json.loads(el)["name"])
lambda는 인자를 받아서. 변형값을 리턴.
map은 인자를 주고, 새로운 값을 묶어줌.
이에 벨류로만 구성된 rdd가 생성될 것임
collect로 스파크 클러스터에 존재하는 데이터를 파이썬 쪽으로 불러옴 name에 해당되는 값들이 리스트로 들어옴.
파이썬 리스트를 데이터 프레임으로 변환해본다.
스트링 타입의 리스트였음. 판다스나, rdd를 스파크 데이터프레임으로 변경하고 싶으면 createDataFrame함수를 쓰면 됨. 두번째 인자로 스키마를 지정해줘야 함.
파이썬 리스트의 경우 튜플도 아니고, 그냥 스트링 타입의 리스트. 이에 스트링타입이라고 지정. 필드의 이름을 디폴트로 'value'라고 지정해줌.
from pyspark.sql.types import StringType
types 패키지 밑에 다양한 타입들이 있음. 나중에 스키마에서 자세히 설명.
df라는 스파크 데이터 프레임 생성.
count로 세보면 레코드의 수가 나옴.
printSchema()

데이터 프레임이 제공하는 다양한 함수를 불러서 다른 데이터 프레임으로 변환 가능.
select라는 메소드를 부를 수 있으나 일단 *로 모드 부르고. collect로 파이썬 으로 호출해본다.
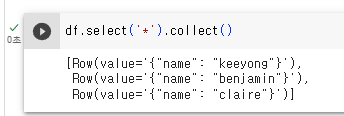
3개의 아이템이 표시됨.
보면 Row라는 타입으로 표시되고 있음. 데이터셋 -> 데이터프레임 지원하기 위한 타입. 데이터 프레임 스키마 설명때 자세히 설명. 데이터 프레임을 파이썬 쪽으로 읽어오면 레코드들이 Row 타입으로 표시된다.
RDD 중 pasres_rdd를 프레임으로 만들어본다. 람다함수를 써서

이렇게 스트링으로 들어왔던 값을 JSON 형태를 키와 필드 값으로 바꿨었음. name이라는 필드가 이미 들어가 있음. 별다른 문제 없이 바로 toDF로 바꾸면 됨.
df_parsed_rdd = parsed_rdd.toDF()
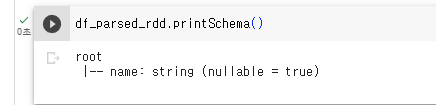
스키마를 프린트해보면,
df_parsed_rdd.printSchema()
이렇게 name이라는 필드가 있음
특정 필드만 불러보자
df_parsed_rdd.select('name').collect()

레코드 3개가 불러와짐
각 레코드는 Row라는 타입으로 나오고 있다
마지막으로,
csv 파일 하나를 데이터프레임으로 로드해본다
구글 콜랩이 동작하는 서버로 받아본다. !wget으로 파일을 받는다
이 파일을 읽어본다. 스파크 세션 밑 read, csv 헬퍼 함수를 써서. 파일을 로딩을 하고 스키마를 프린트해본다.
df = spark.read.csv("name_gender.csv")
df.printSchema()
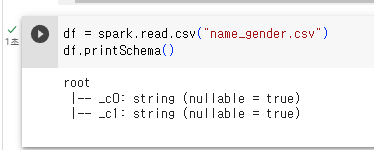
이 csv 파일은 헤더가 있음에도 불구하고 c0, c1 컬럼으로 나옴. csv 로딩할 때 헤더가 있다고 알려줘야 함.
df = spark.read.option("header", True).csv("name_gender.csv")
df.printSchema()

중간에 옵션, 헤더 true라는 함수 콜이 추가됨.
스키마를 프린트해보면, 이번에는 name, gender라는 컬럼 이름이 출력됨.
어떤 내용들이 있는지 show() 로 레코드를 본다

컬럼이 있고, 각 값들이 잘 들어가 있음.
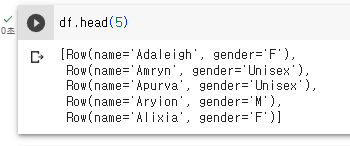
head 메소드 쓰면
그냥 5개를 보여줌.
Row타입이 여전히 표시됨을 보임,
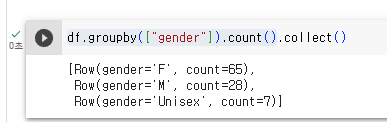
데이터 프레임이 되었기에, groupby를 사용하여, gender를 중심으로 카운트를 해볼 수 있다.
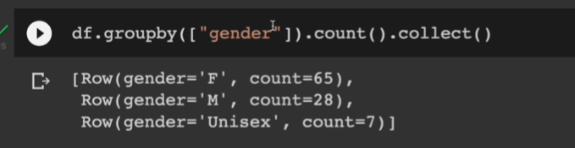
df.groupby(["gender"]).count()
여기까지만 해보면 아무른 출력이 없음. 이 작업은 스파크 클러스터에서 벌어진 작업이라 그럼. collect로 호출을 해서 파이써 드라이버 프로그램으로 가져와야 함.
df.groupby(["gender"]).count().collect()
데이터 프레임도 결국 RDD 위에서 돌아감. RDD프로퍼티 사용 getNumPartions를 호출하면 몇개의 파티션으로 데이터 프레임이 구성되어 있는지 알 수 있음.
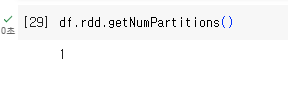
1개로 구성
다음시간에 스파크 API 중 스파크 SQL 살펴볼 예정.
이를 SQL로 변환하면 얼마나 더 쉬워지는지 맛만 본다
데이터 프레임은 name_gender를 가져왔었음
함수를 호출했어야 했었음.
그럼 테이블이 있어야하는데, 데이터 프레임들이 테이블이 됨. 이에 테이블 이름을 지정해줘야 함.
df.createOrReplaceTempView("namegender")
마치 테이블처럼 처리하고 싶고 이름은 namegender로 주었음
이 데이터프레임을 스파크 SQL에서 사용할 수 있고 호출명은 namegender가 됨
이에 스파크 SQL을 써서
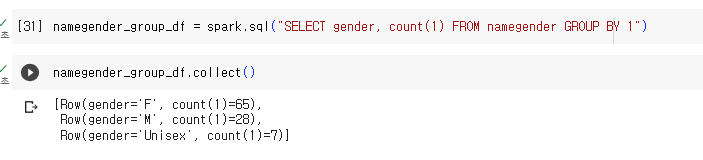
namegender_group_df = spark.sql("SELECT gender, count(1) FROM namegender GROUP BY 1")
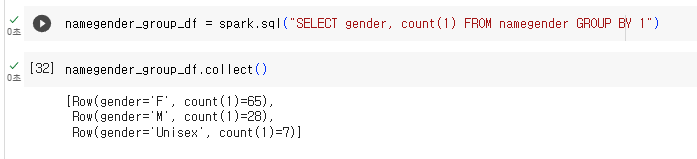
namegender_group_df.collect()
spark.catalog.listTables()

현재 테이블은 1개
하이브같은걸 쓰게 세팅했으면, 하이브가 갖고있는 메타데이터 스토어와 연결됨. 하이브 데이터도 보이게 됨.

파티션은 여전히 1개
리파티션을 써서 2로 나눠볼 수 있음

해싱 방법 지정 X했기에 랜덤하게 파티션 2개를 만들게 될 것임.

getNumPartions() 2개가 설치됨
후기
뭔가 어렵다고 자꾸 주저하는 거같은데, 다 처음배우는거라 어려운게 맞음. 강사님 특성상 반복해서 가르쳐주실 예정이니까 너무 부담갖지 말고 일단 완료주의로 가자.
