agg
join
udf
에 대해 알아본다.
꼭 스파크sql 과 관계는 아니라, 데이터프레임도 같이 알아본다.

순수하게 SQL로 처리하는게 좋음.
- Group by
= Sum, min, max, avg, count - Window
= row_number, first_value, last_value - Rank
세가지를 조금씩 실습 때 문제를 풀면서
공통 필드를 가지고 머지. - 새로운 테이블 생성
다수의 테이블에 정보가 흩어져 있는 경우 묶어서 완전한 정보를 얻기 위함.
왼쪽을 LEFT, 오른쪽을 RIGHT
방식에 따라
6가지 있음
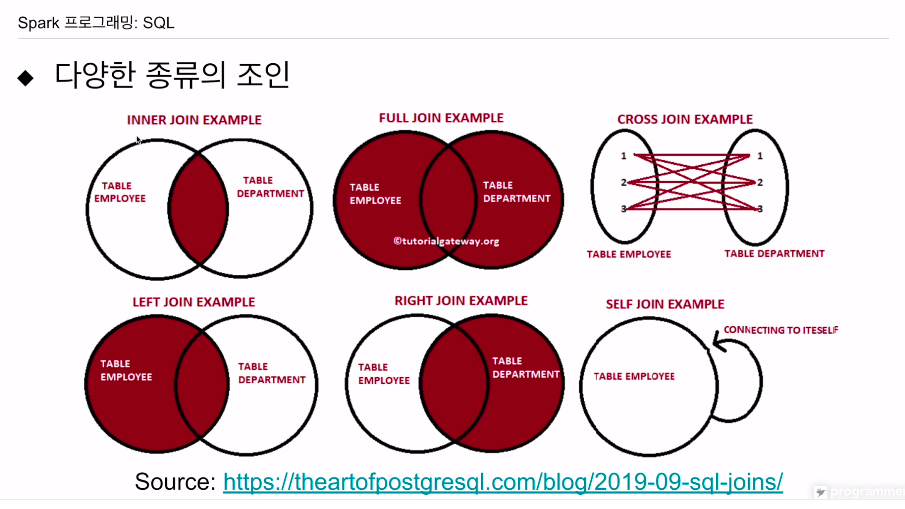
inner join = 매칭 되는애들만 가져옴
full join = 매칭 관계 없디 다 읽어옴 (매칭되지 않는 경우 비어있음. NULL 값 세팅)
left join = 왼쪽 테이블 다 리턴, 오른쪽은 매칭이 되는 경우 리턴
right join = 오른쪽 테이블 다 리턴, 왼쪽은 매칭이 되는 경우 리턴. 오른쪽 테이블에서 매칭 되지 않는 레코드는 왼쪽 테이블의 필드값은
cross join은 하나의 레코드가 반대쪽 모든레코드와 대응함
n*m 식임
self join은 자기 자신과 조인
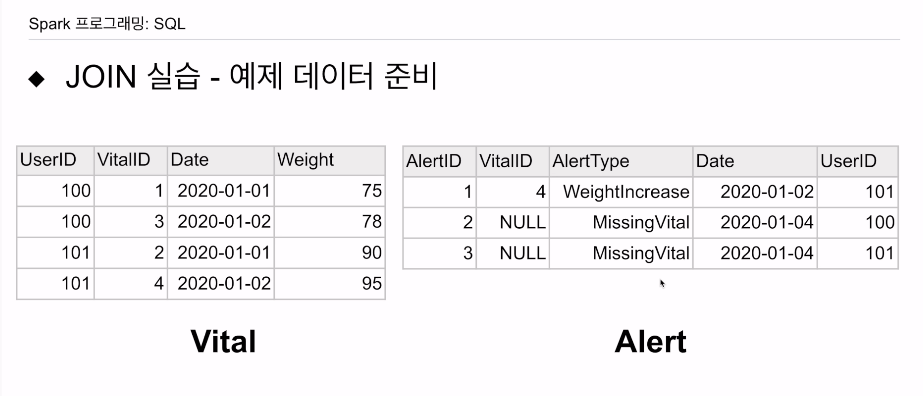
유저 ID, 바이탈 ID
조인키 옵션으로 선택 가능.
환자가 집에서 측정을 하고, 모바일 앱에 서버에 정보를 보내고, 이걸 머신러닝 알고리즘로 아플지 예측해서 병원에 연락을 함.
Vital - 환자들이 측정한 몸무게 정보.
alter - vital 정보를 보고 아플지 안아플지 판단해, 병원에 경보를 보냄.
하루사이에 5키로 이상 늘면 아플 확률이 높다 라는 규칙을 alter rule 생성.
2일 이상 체중을 측정하지 않아면 경보가 나게 함. missingvital
VitalID는 측정 할때마다 증가하는 필드 - 체중을 기록
alter에선 그러한 경보를 발생시킨 vitalID를 기록함.
AlterID로 증가하는 필드
앞의 6가지 방식으로 조인했을 때 리턴 확인한다

매칭 레코드만 리턴
양쪽이 채워진 상태임.
SELECT * FROM Vital v
JOIN Alert a ON v.vitalID = a.vitalID오른쪽테이블 Alert가 JOIN다음에 오는 걸확인.
INNER는 생략됨. 디폴트는 inner 조인임

매칭은 vitalID 4만 매칭되기에 이게 합쳐짐.
양쪽 테이블의 모든 필드가 채워짐.
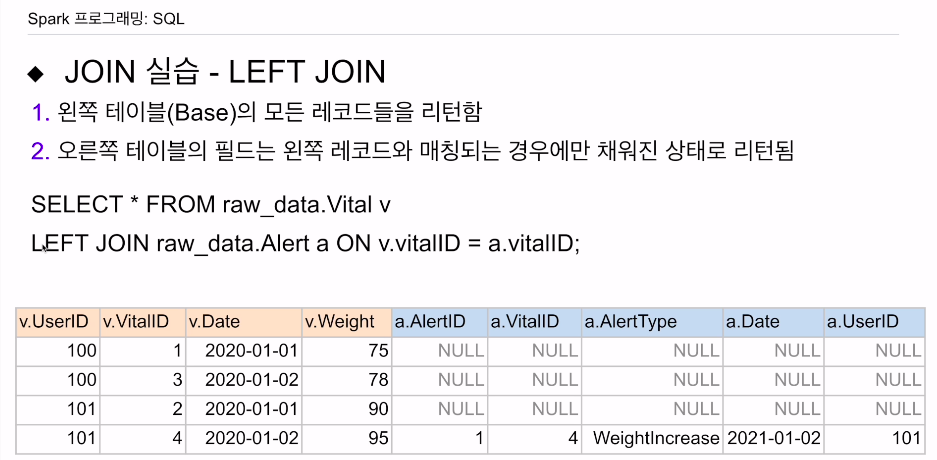
앞에 LEFT가 추가됨.
왼쪽 테이블 레코드는 다 리턴됨. 오른쪽은 매칭이 되는 경우만 채워지고, 나머지는 널값.
- 왼쪽 테이블은 다 킵하고 싶고, 매칭되는 오른쪽만 보고싶다.
RIGHT은 반대로 하면 됨.
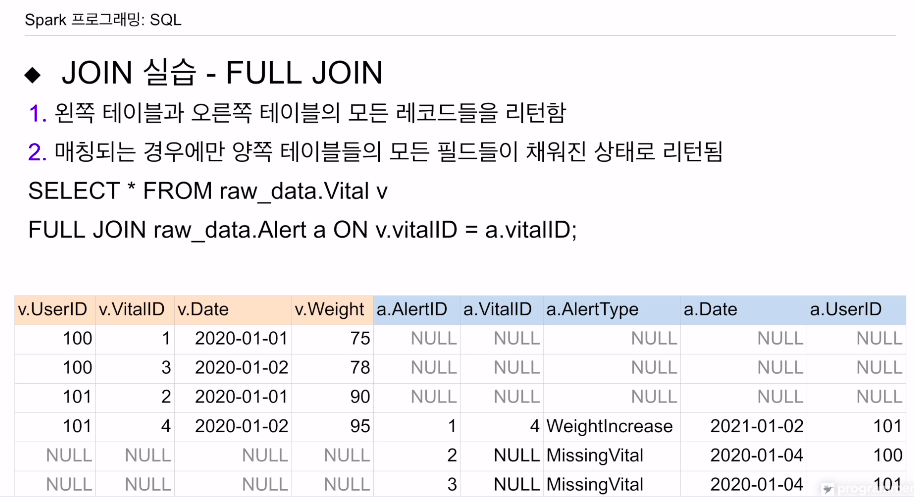
full join은 양쪽이 다 채워지는 형태임.
각기 매칭이 되지 않을 경우 널값으로 비워질 것임.
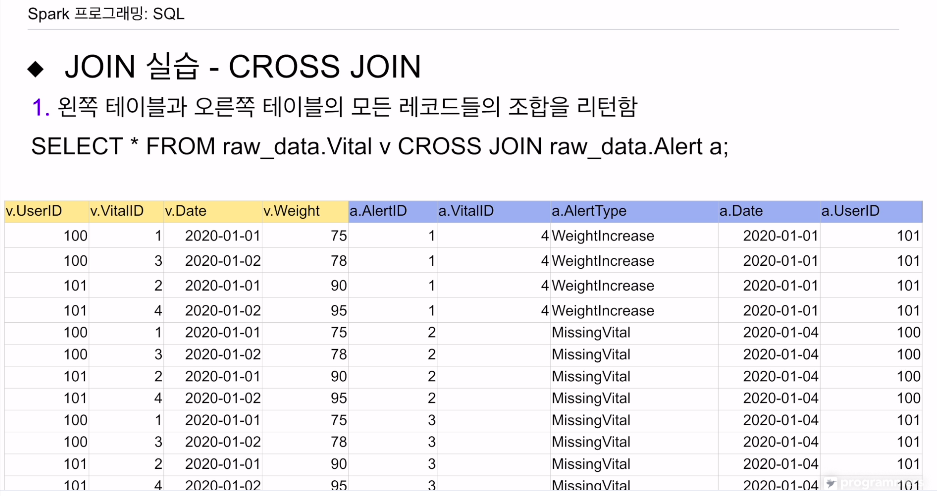
모든 레코드들 간의 조합을 만들어내는 cross join.
4*3
동일한 테이블을 두번 조인하는 셀프 조인.
각각 다른 앨리어스를 부여함.
v1, v2 => 결국 같은 테이블.
잘 안쓰기도 함.

하다보면 슬슬 최적화가 필요해짐.
스파크로 조인을 하다보면 최적화가 필요함.
데이터셋의 크기가 큰 경우, 파티션 여러개로 구성. JOIN을 바탕으로 셔플링이 발생. 셔플을 되도록 피하는게 퍼포먼스에서 중요함.
어떤것들이 있는지만 대략 살펴보고, spark 고급에서 살펴보낟.
일반적인 join은 셔플. 해싱을 하든지, 같은 키를 갖는 왼, 오 레코드들이 하나의 서버로 가게 엑시큐터가 작동.
버킷. 조인 키로 파티션들을 만들어놓고, 조인 때 셔플링 발생 방지 가능.
브로드캐스트
한쪽이 굉장히 작을 때. 두개의 데이터프레임을 큰 데이터프레임을 그대로 냅두고 작은 데이터프레임을 모든 파티션으로 브로드캐스팅함. 그럼 셔플링 없이 join
저 파라미터로 충분히 작은지 체크함. 기본적으로 엑시큐터 메모리보다 조금 작게 지정. 한 엑시큐터에서 처리 가능하기 때문.
스파크 고급에서 좀 더 다룬다.
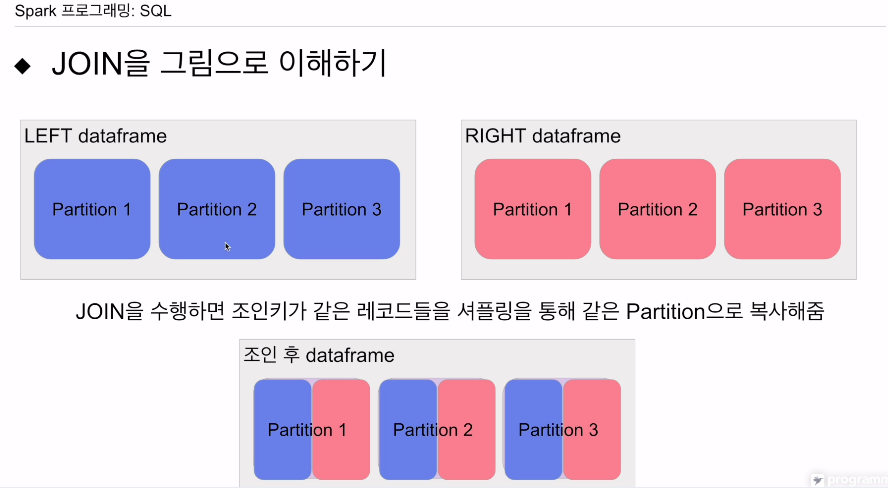
각각 세개의 파티션으로 구성.
조인 결과로 세개의 파티션을 가진 데이터 프레임이 만들어진다고 가정.
조인 후 새 데이터 프레임의 파티션 수는 셔플링 후에 스파크 환경변수로 결정
디폴트 값이 200
여기선 그냥. 3개가 생겼다고 가정.
JOIN이 동작하려면,
왼쪽, 오른쪽 모두 각 레코드 JOIN 키에 해싱을 적용. 조인 후 파티션 수로 나머지 계산을 해서. 해당하는 파티션으로 카피
머지가 되어야 하는 레코드들이 같은 파티션으로 복사가 될 것임.
엑시큐터가 이 파티션을 읽어서 조인 작업을 수행.
이러다보면 엄청난 이동이 발생할 수 있음
조인 연산을 이해하려면, 우선 스파크의 분산 처리 방식과 해시 함수를 이해해야 합니다.
스파크는 데이터를 여러 개의 파티션으로 분리하여 병렬 처리를 합니다. 이러한 처리 방식은 매우 큰 데이터셋에 대해 연산을 빠르게 수행할 수 있도록 합니다. 여기에서 중요한 개념은 각 파티션의 데이터가 다른 파티션의 데이터에 의존하지 않아야 한다는 것입니다. 즉, 하나의 파티션에서의 연산이 다른 파티션에 영향을 주면 안 됩니다.
조인 연산에서는 두 데이터셋의 특정 열(조인 키)을 기준으로 데이터를 합칩니다. 예를 들어, '고객 ID'를 기준으로 고객 정보 데이터셋과 주문 정보 데이터셋을 합친다면, 같은 '고객 ID'를 가진 레코드끼리 합쳐집니다.
이렇게 조인 연산을 수행하려면, 같은 조인 키를 가진 레코드가 같은 파티션에 위치해야 합니다. 이를 위해 스파크는 해시 함수를 사용합니다.
해시 함수는 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수입니다. 이 함수는 동일한 입력값에 대해서는 항상 동일한 출력값을 반환하므로, 조인 키를 해시 함수의 입력값으로 사용하면 동일한 조인 키를 가진 레코드는 항상 같은 출력값(즉, 파티션 번호)을 가지게 됩니다.
스파크는 각 레코드의 조인 키에 해시 함수를 적용하고, 그 결과를 조인 후의 파티션 수로 나눈 나머지를 해당 레코드의 파티션 번호로 사용합니다. 이렇게 하면 동일한 조인 키를 가진 레코드가 항상 같은 파티션에 위치하게 됩니다.
이 과정에서 레코드의 이동(= 셔플링)이 발생합니다. 왜냐하면 각 레코드가 원래 있던 파티션에서 계산된 파티션 번호에 따른 새로운 파티션으로 이동해야 하기 때문입니다. 이러한 셔플링은 네트워크 통신을 많이 필요로 하므로 연산 비용이 많이 드는 작업입니다.
이것이 스파크에서 조인 연산이 이루어지는 과정입니다. 해싱은 이 과정에서 같은 조인 키를 가진 레코드를 같은 파티션으로 모으는 역할을 합니다.
셔플링을 기본적으로 이동도 문제지만, 이동 후에 파티션 크기가 다를 수 있는 것도 문제. 또 병렬처리의 이점이 사라짐.
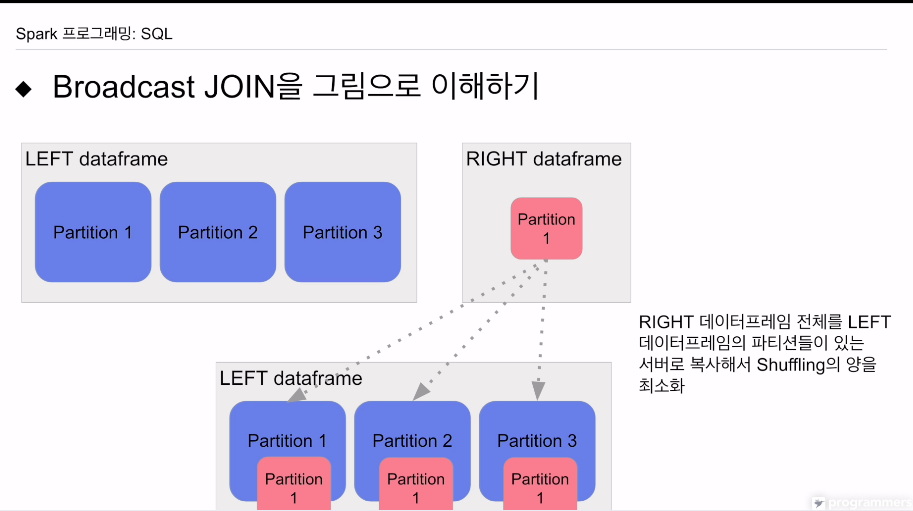
데이터 프레임이 작은 사실을 알고 있다면, 파티션 1개 안에 들어가는 정도.
큰 파티션에 각자 하나씩 복사를 시켜버림.
이렇게 함으로써 셔플링 양을 최소화 함.
작은 데이터프레임이기에 오버헤드가 없음.
버킷조인은,
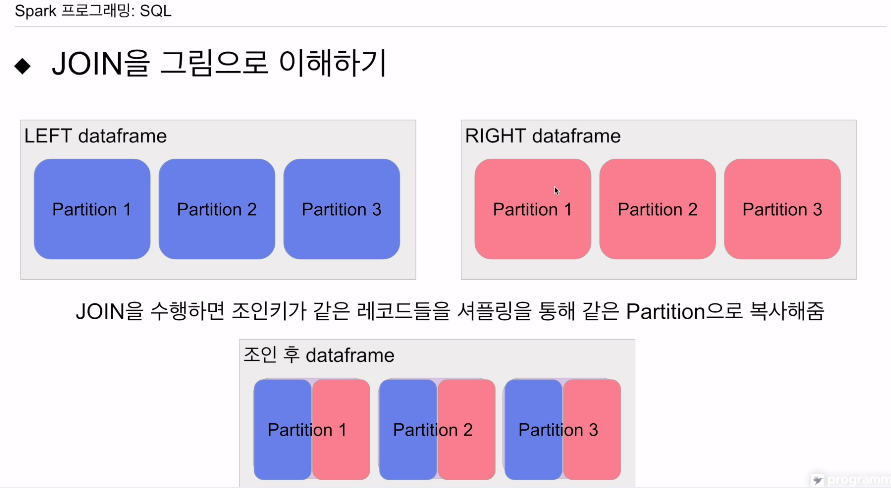
바로 파티션을 리셔플링을 통해 파티션을 새로 만듦
JOIN 키에 맞춰, 같은 조인 키인 애들을 한 파티션에 모아버림.
나중에 고급에서 다룰 예정.
