학습주제
학습내용

분산시스템의 필요성과 특징에 대해 알아보았다.
1세대 분산시스템인 하둡에 대해 알아보고, 구성 시스템에 대해 알아본다.
하둡의 여러 버전을 통해 발전해왔는데, 버전별 특징에 대해 알아본다.

2개의 논문에서 시작함.
2003년 the google file system
굉장히 큰 데이터를 어떻게 저장할 수 있을지, 분산 파일 시스템에 대한 설명.
분산 파일 시스템이 있어야 분산 처리가 가능함.
2004년 맵 리듀스
분산 파일 시스템 위에 있는 시스템을 어떻게 처리할지에 대한 논문.
구글 내부에선 이런 정보는 신기술이 아니었을 것임.
구글이 얼마나 앞서고 있고, 더 좋은 개발자들이 조인할 수 있도록 PR함.
두개의 논문으로 아이디어를 구현, 하둡이라고 명명.
야후 검색엔진 팀에서 하둡을 이용해 빅데이터 저장과 프로세싱을 용이하게 하려고 했음.
2013년에 공식적으로 소송을 걸지 않겠다고 선언.

하둡으로 먹고사는 회사가 많음.
클라우데라 등
정의: 오픈소스 플랫폼인데, 데이터를 싸구려 컴퓨터로 구축된 다수의 컴퓨터로 처리를 할 수 있는 시스템.
- 분산 파일 시스템 (HDFS)
- 분산 컴퓨팅 시스템 (맵 리듀스)
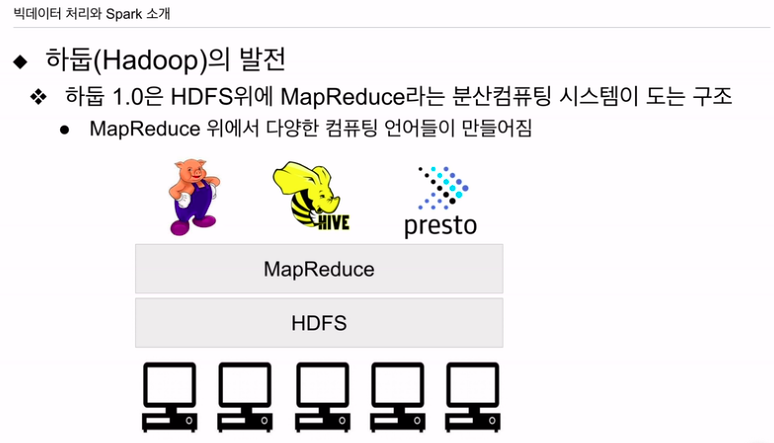
제일 처음 버전. 이후 맵리듀스 이외에 다른 분산 컴퓨팅 시스템을 지원함. 예. 스파크
굉장히 많은 수의 서버로 구성됨. 사용자 입장에선 하나의 컴퓨터로 쓸 수 있음. 4000대의 서버로 구성되어 있기도 함. 그 때 최대 서버 수가 4000대였음.
1.0 버전
아까 두가지 컴포넌트로
HDFS를 이용해서 큰 데이터를 저장. 그 위에서 맵 리듀스를 사용해서 큰 데이터를 병렬처리하는게 가능.
맵 리듀스는 문제가 있었음. 딱 두개의 오퍼레이션, 맵, 리듀스만 지원. 프로그래밍이 너무 어려워짐. 생산성이 떨어지기 시작. 맵 리듀스 위에서 처리가 쉬운 하이레벨 프로그래밍.
피그 - 판다스 데이터 프레임과 비슷. 더이상 안쓰임. 직관적이지 않음.
하이브, 프레스토 - 사실상 SQL 언어
발전
맵리듀스 위에 프레임워크들을 만듦. 피그, 하이브, 프레스토 같은 시스템.
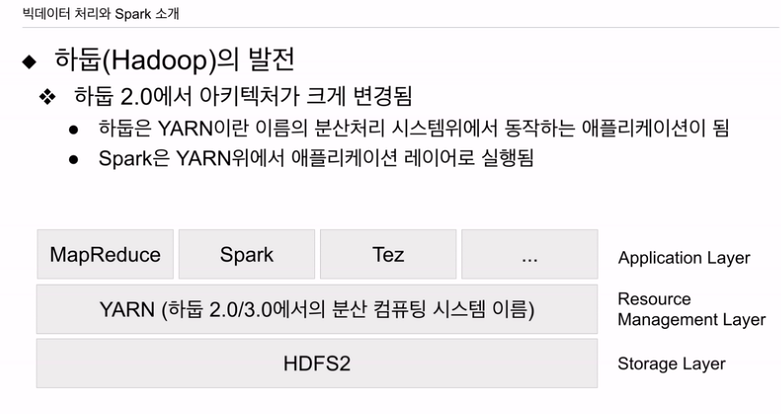
맵 리듀스 말고, 조금 더 제너럴한 분산처리 시스템을 만들면 어떻겠느냐. 그 위에 사용자들이 원하는 형태의 분산처리 시스템 만들자. 굉장히 많이 바뀜.
기본은 HDFS 버전2. 신뢰성, 견고성이 개선된 버전. 크게 달라지진 않음. 분산처리 시스템 같은경우 맵리듀스 대신 일반적인 컴퓨팅프레임워그 YARN이 올라가고 그 위에 맵리듀스가 앱처럼 동작함
YARN - 분산 처리 시스템. 리소스 매니지먼트. 제너럴한 컴퓨팅 프레임워크
하이브, 프레스토, 피그는 이 맵리듀스를 통해 돌아가거나, 얀을 사용해서 바로 돌아가게 할 수 있음.
스파크는 얀 위에서 돌아가는 얀 애플리케이션. 하둡 2.0 부터 등장함. 하둡 2.0 부터는 크게 3가지 레이어
HDFS - 얀 - 분산 컴퓨팅 레이어(스파크)
HDFS
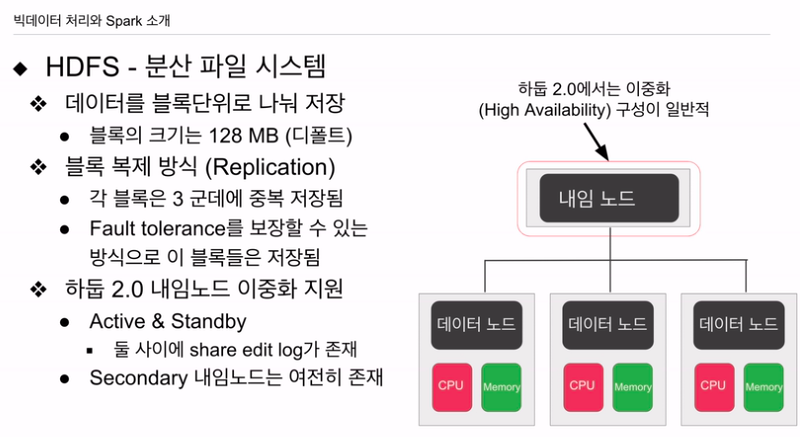
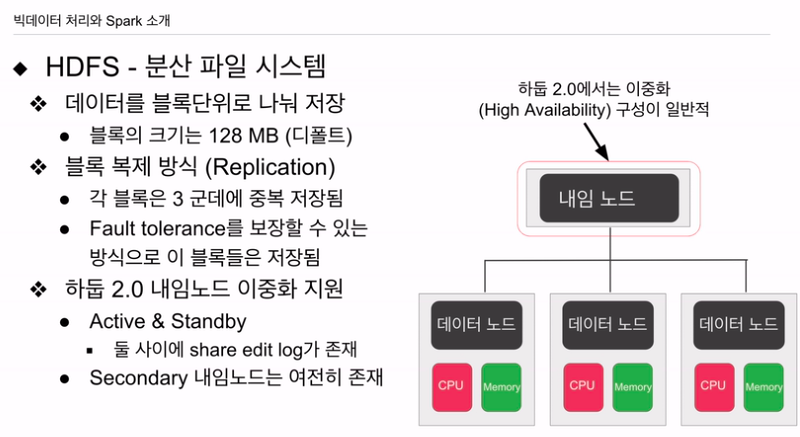
하나의 큰 파일이 있으면 블록 단위로 나뉨. 128mb. 큰 다수의 서버로 구성된 시스템이몇 몇개 서버는 고장남. 그 서버 저장 블록은 유실될 것임. 레플리케이션 팩터라고 해서 적어도 3개의 서버에 중복해서 저장함. 3개 서버 다 나가지 않는 한 데이터 복구할 수 있는 방법 구현. Fault tolerance를 보장.
데이터 블럭을 저장하는 데이터 노드(슬레이브). 다수의 서버로 구성. 이 파일 시스템에 데이터 블럭들이 저장.
이를 관리하는 네임노드. 어디에 저장알 수 있는 디렉토리. 고장이 나면 그 노드에 어떤 데이터들이 있는지, 같은 데이터 블럭을 찾아서 복구해줌.(다시 3대의 서버에 블록 복제)
데이터 노드가 다 살아있어도 네임노드가 동작을 안하면 HDFS 파일은 의미가 없음. 네임노드 이중화가 굉장히 중요해짐. 현재 네임 노드가 동작을 안하면 백업 노드가 있어야 함.
1.0 때는 세컨더리 네임 노드 - 주기적 복제해서 가짐. 네임노드가 다운 됐을 때 세컨더리가 자동으로 네임 노드 역할 하진 않음. 운영자가 세컨더리를 가지고 메인 노드를 만들어내는 메뉴얼 작업이 필요해짐. 2.0 나오면서, 이중화해서 액티브, 스탠바이 네임노드. 액티브 문제 생기면 스탠바이가 자동으로 실제 네임노드 역할을 하도록 바뀜. 세컨더리 네임노드는 여전히 존재.
맵리듀스
1.0 부터 소개됨.
HDFS에서 다수의 태스크 트래커와 하나의 잡 트래커로 구성.
잡 트래커는 마스터에 해당. 태스크는 슬레이브에 해당. 실제 코드는 태크스에서 실행되지만, 일을 나눠주는건 잡 트래커가 함. HDFS와 구조가 동일함.
하둡 클러스터 구성하는 서버들이 파일, 처리를 둘 다 함.
마스터는 잡 트래커와, 네임 노드를 동시에 설치하기도 하지만 여유가 된다면 각기 별도의 서버에 설치.
문제점: 맵 리듀스만 지원. 생상성이 높지 않음.
-> 하이브, 프레스토, 피그를 올려서 씀.
2.0 때 얀을 도입해서 달라짐.
