스파크 파일포맷에 대해 알아본다.
parquet에 대해 알아보고
2가지 실습 진행.
입력이 되는 데이터는 대부분 HDFS에서 오게 될 것임. 클라우드 스토리지 포함.
내가 처리하려는 데이터가 어떤 포맷으로 저장됨이 성능에 영향.
파일의 포맷이 굉장히 중요해짐.
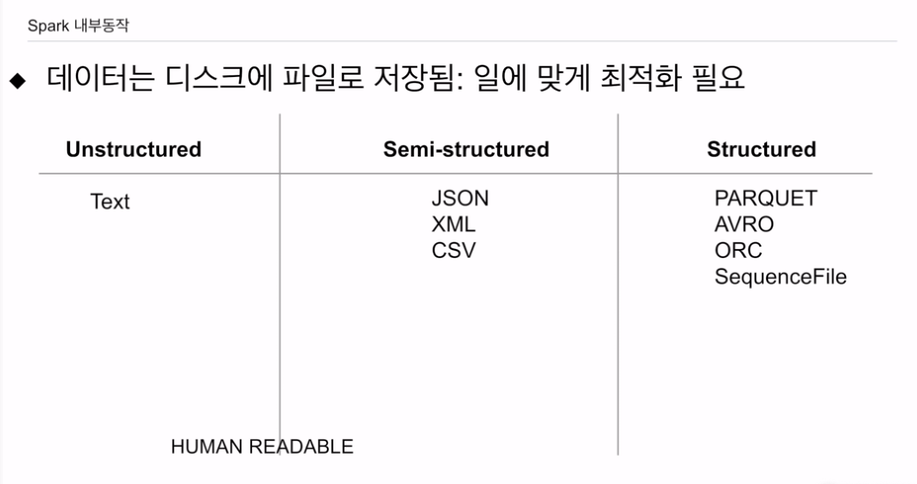
JSON, CSV - 텍스트 파일 포맷. 장점. 눈으로 확인할 수 있음. 바이너리가 아님.
xml이 있을 수 있음.
스트럭쳐가 되었으나 파일 정보가 없음.
비구조화된 타입으로 텍스트가 있음
이 두가지는 사람이 읽을 수 있다는 장점이 있음.
가장 선호는 스트럭처 타입임.
parquet이 스파크가 애용.
그 외 등등이 있음
시퀀스파일은 하둡 맵리듀스에서 사용.
일단 바이너리고, 압축이되어 있고, 내부 스키마 정보있음. 필드 타입정보도 들어있음. 스키마에볼루션 지원 -. 파일 포맷이 바뀌어도 머지해서 사용 가능.
몇가지 파일 포맷을 비교해본다.
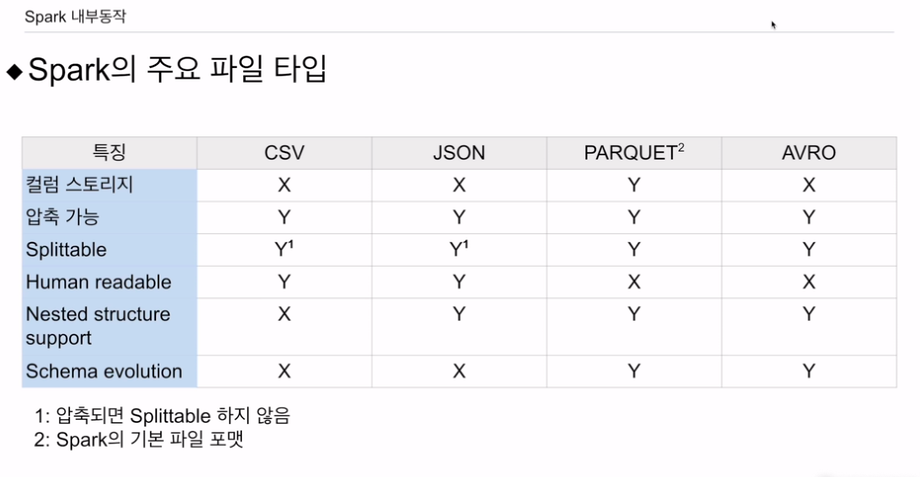
컬럼스토리지는 나중에 설명.
나머지는 행별로 저장함.
압축이 다 가능.
splittable
HDFS에서 저장될 땐 데이터 블럭이고 다시 스파크 데이터프레임으로 올라올 때 파티션으로 바로 올라갈 수 있느냐. 데이터 블락이 하나의 파티션이 됨. 예를들어 압축된 경우, 스피릿터블, 데이터블락으로 나눌 수 있느냐? -CSV, JSON은 압축되면 X임
사람이 읽을 수 있는가? - csv, json
nested 스트럭처 지원? 자료구조 안에 자료구조
csv만 불가능.
스키마 에볼루션 지원? - parquet, avro 지원
파일이 어떤 컬럼들이 없다가 새로운 컬럼이 나왔다가 문제없이 같이 사용할 수 있음.
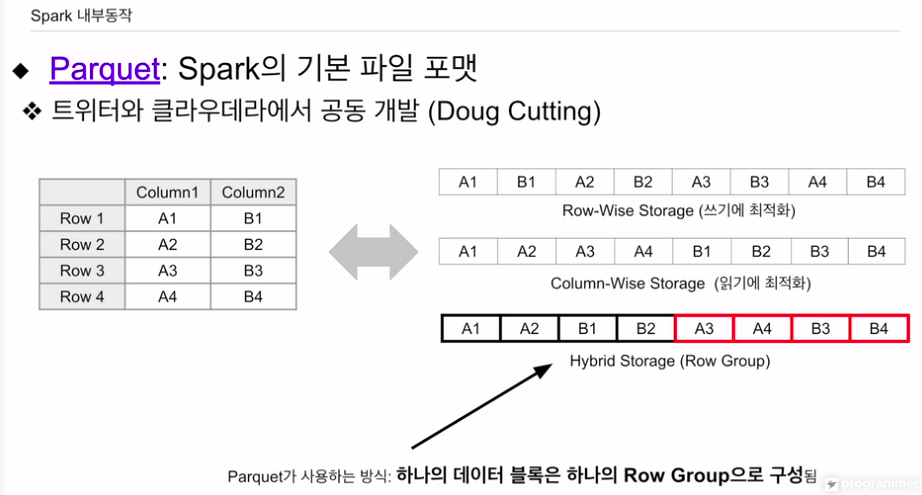
행별로, 열별로 저장 여부를 설명
왼쪽의 구조화된 데이터 있음.
csv, json, avro처럼 row-wise 면, 레코드 하나쓰고, 다음 레코드 쓰고, 레코드 별로 쓰게됨. 이는 쓰기에 최적화. 차례대로 추가해나가면 되기 때문.
이걸 열별로 저장하는 형태로 가면
첫번째 컬럼 적재, 이후 두번째 적재. 이는 읽기에 최적화 되어있음.
보통 select를 하면 모든 필드를 다 읽지는 않음. 일부만 컬럼 읽게 되어 있음.
컬럼 스토리지의 장점: 읽기에 최적화. 컬럼의 특성을 활용한 압축이 가능함.
하이브리드 스토리지가 있음. row group. 데이터 블락단위로 하나의 그룹. 같은 그룹안에선 컬럼 스토리지 형식으로 저장함.
그냥 컬럼 스토리지가 아닌, 로우 그룹안에서 컬럼 스토리지임.

데이터 프레임을 두개의 다른 포맷으로 저장해본다. 파티션의 수를 바꿔 저장했을 때 HDFS에 어케 저장되는지.
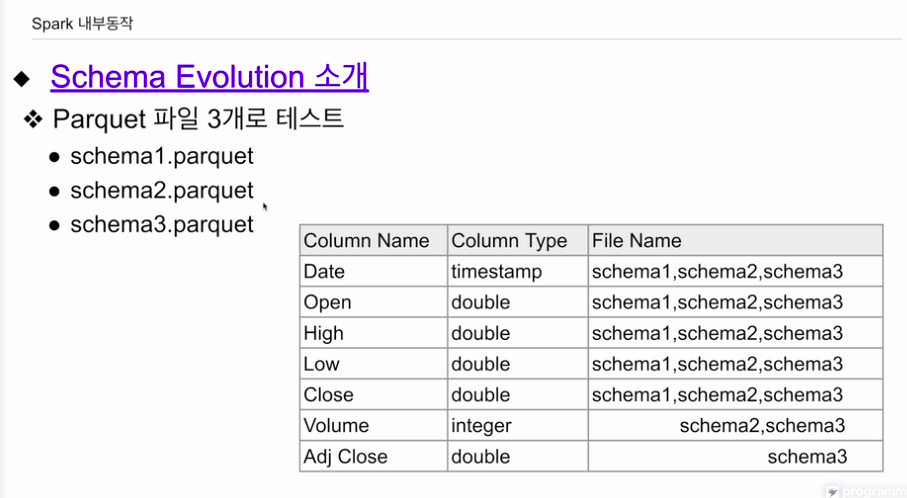
스키마 에볼루션이 어떻게 지원되는지 확인.
파일들이 공통적으로 갖는 컬럼이 있음.
스키마 2는 volume이 별도로 있음
스키마 3는 volume, ajd close
동시에 스키마들 불러왔을 때 스키마가 어떻게 결정되는지? csv, json이 다른 컬럼을 갖는 경우 스파크에선 에러를 내게 되어있음. 에볼루션지원하면 에러 안내고, 존재하지 않는 필드를 NULL로 스키마 변경처리를 해줌.
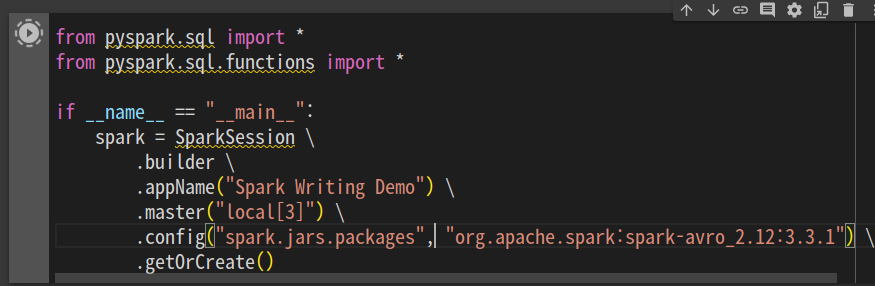
세션을 만드는데, config에 avro를 추가하는거 같음. avro, parquet
저장했을 때 형태가 어떻게 바뀌는지?
avro는 디폴드로 로딩되지 않기에 이렇게 별도로 지정해줘야함.
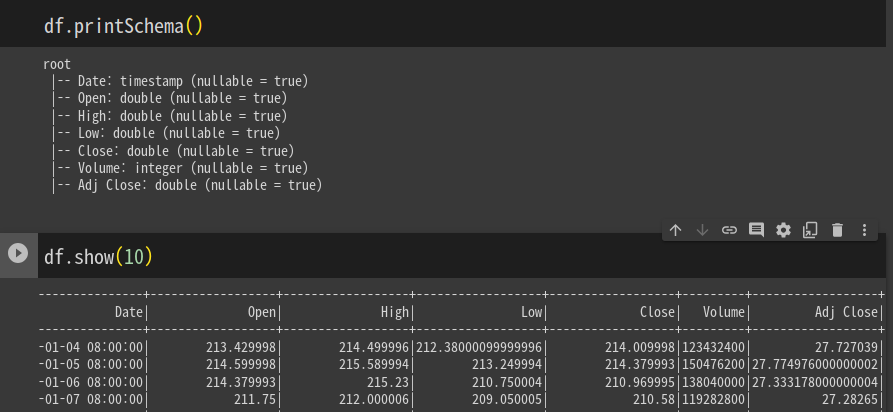
입력용 csv를 받아본다.
다음으로 파일을 데이터프레임으로 읽어본다.
df = spark.read \
.format("csv") 7
.load("appl_stock.csv")파티션의 수와 그 파티션의 레코드 수를 출력해본다.
id별로 묶어줌. 파티션 하나밖에 없음. 오른쪽에 레코드 수 잘 보임.
print("Num Partitions before: " + str(df.rdd.getNumPartitions()))
df.groupBy(spark_partition_id()).count().show()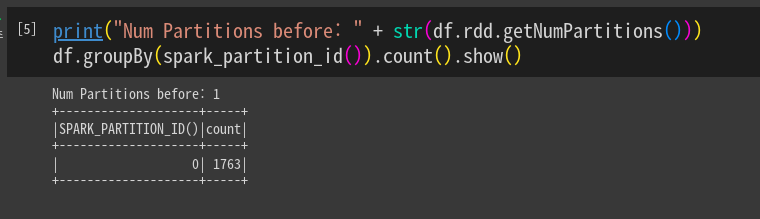
파티션의 수를 4개로 조정하고 다시 출력해본다. 해싱을 통해 균등하게 재분배
df2 = df.repartition(4)
print("Num Partitions before: " + str(df2.rdd.getNumPartitions()))
df2.groupBy(spark_partition_id()).count().show()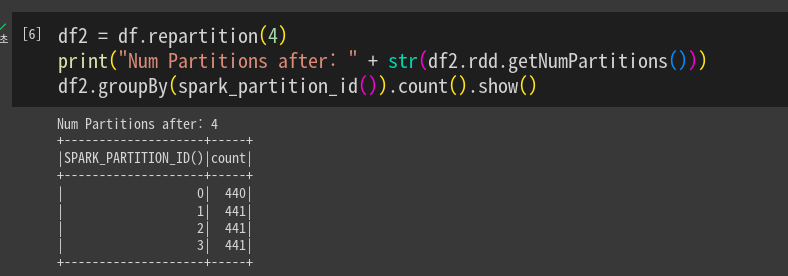
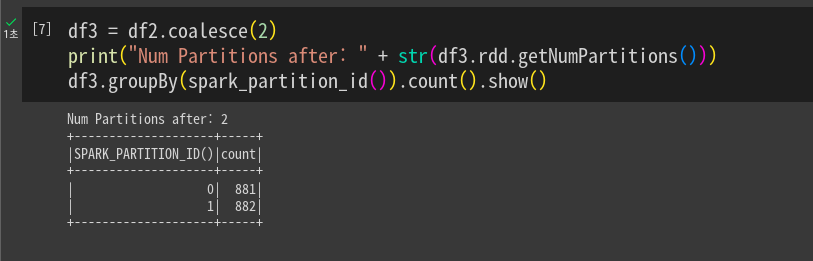
다시 줄임. 줄일 때 셔플링을 최소화하는 방향으로 동작함. 지금 데이터프레임의 파티션 수보다 늘릴수는 없으나 줄일 수 있음. 해싱,셔플링 안하는 쪽으로.
df3 = df2.coalesce(2)
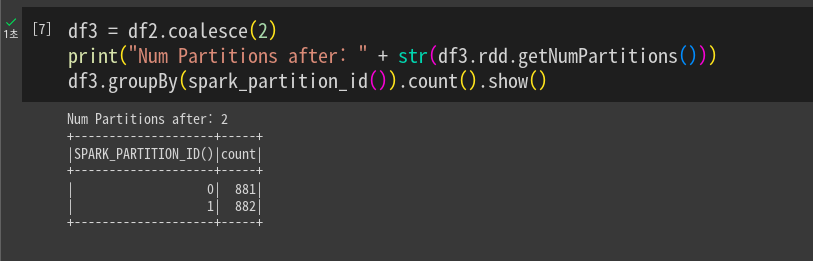
각 데이터 프레임을 다른 포맷으로 저장해본다.
df.write \
.format("avro") \
.mode("overwrite") \
.option("path", "dataOutput/avro/" \
.save()
df2.write \
.format("parquet") \
.mode("overwrite") \
.option("path", "dataOutput/parquet/")\
.save()
df3.write \
.format("json")\
.mode("overwrite")\
.option("path", "dataOutput/parquet/")\
.save()
parquet는 기본 압축, 압축이 되었어도 스피릿터블함 snappy 방식 압축.
avro는 파일이 하나밖에 없음.
스키마 에볼루션
from pyspark.sql import *
from pyspark.sql.functions import *
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Spark Schema Evolution Demo") \
.master("local[3]")
.getOrCreate()스키마 1을 읽어본다.
df1 = spark.read.parquet("schema1.parquet")
df1.printShcema()
df1.show()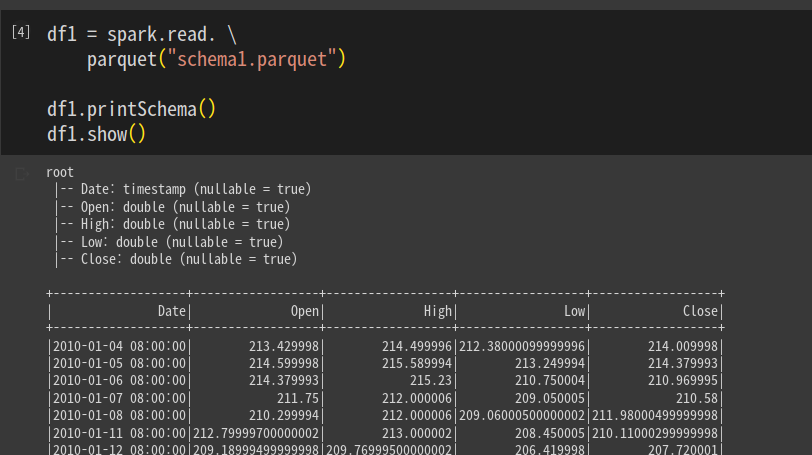
컬럼 5개 확인함.
스키마 2를 읽어본다.
df2 = spark.read.parquet("schema2.parquet")
df2 = parintSchema()
df2.show()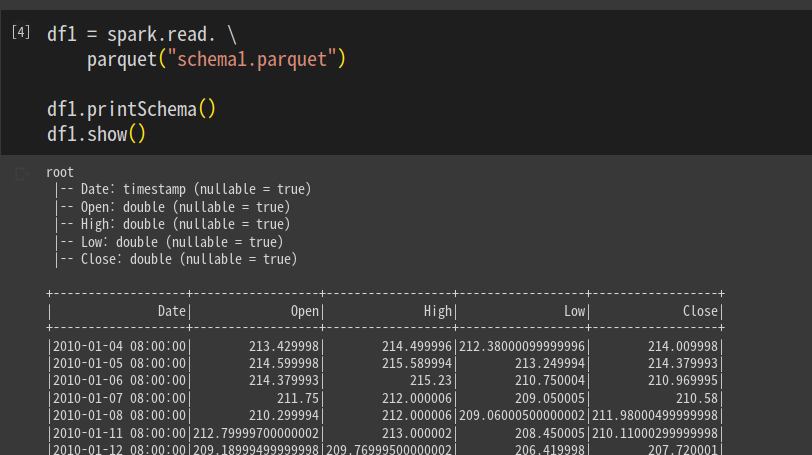
Volume이 하나 더 들어있음
마찬가지로 3도 읽어본다.
df3 = spark.read.parquet('schema3.parquet")
df3 = printSchema()
df3.show()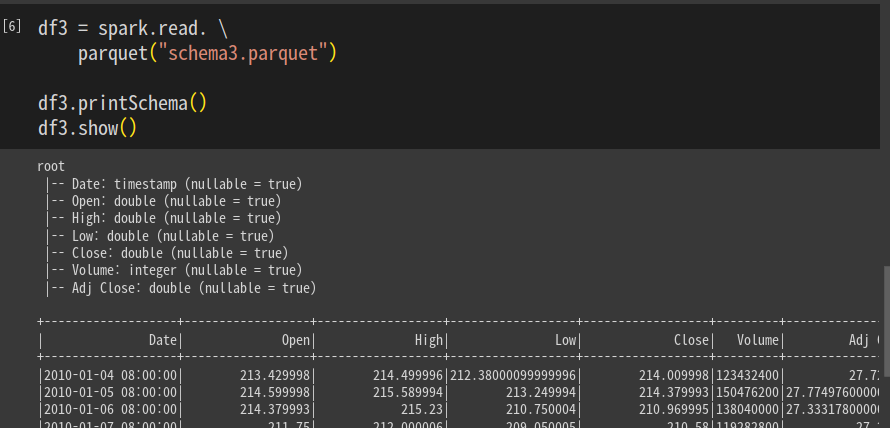
앞서개별로 불러왔던 테이블들을 한번에 합쳐본다.
option("mergeSchema", True)로 옵션을 넣어준다.
df = spark.read.\
option("mergeSchema", True). \
parquet("*.parquet")
df.printSchema()