
마스터 노드로 .ssh로 로그인해본다

ssh 로그인
22번 포트 오픈해줘야함
서밋으로 잡을 실행. 두개의 예제 불러봄
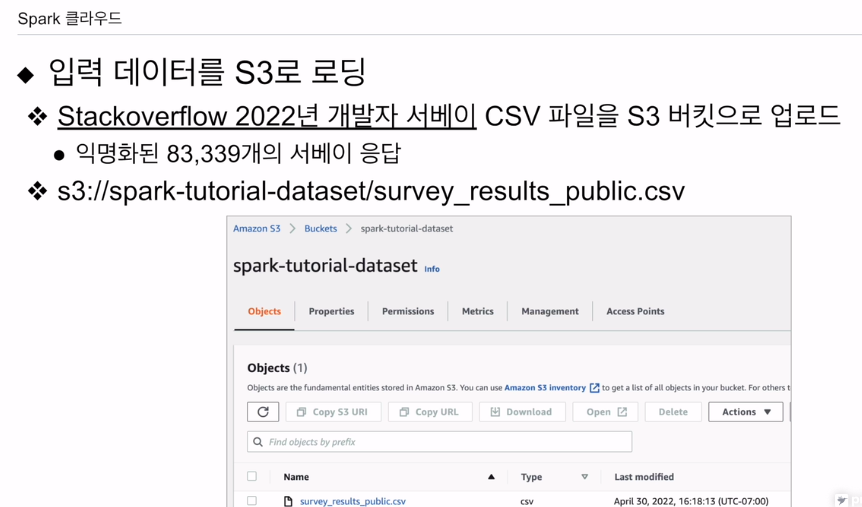
지금 HDFS의 s3에 올려본다.

s3는 HDFS에 해당함.
csv보면
Country, LearnCode(어떻게 코딩을 배웠는지)

ssh 키페어를 가지고 로그인할 것임.
해당 코드를 실행.
디폴트는 클러스터모드임
리소스 매니저를 얀으로 쓰겠다고 선언
잘 되고 나면 그결과를 s3에 다시 저장하게 되어있음
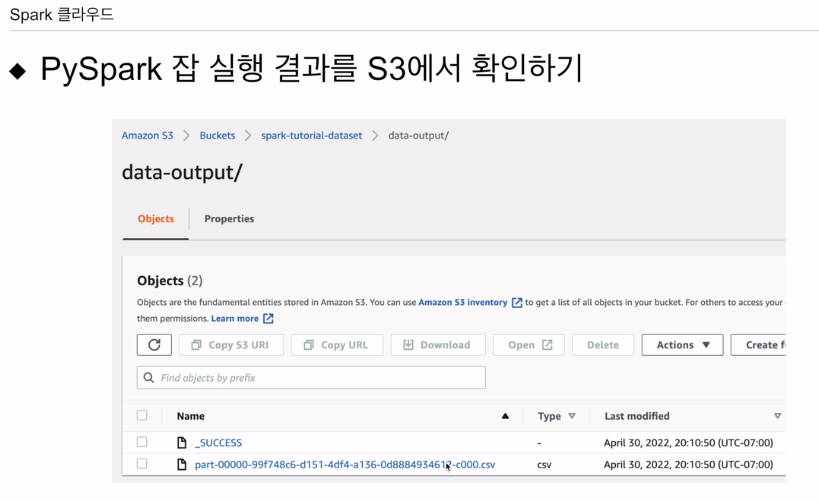
csv라고 했기에 잘 저장된 것을 확인할 수 있음
터미널로 넘어간다
실습
.ssh 로그인을 시도해본다
만들어놓은 코드가 있음
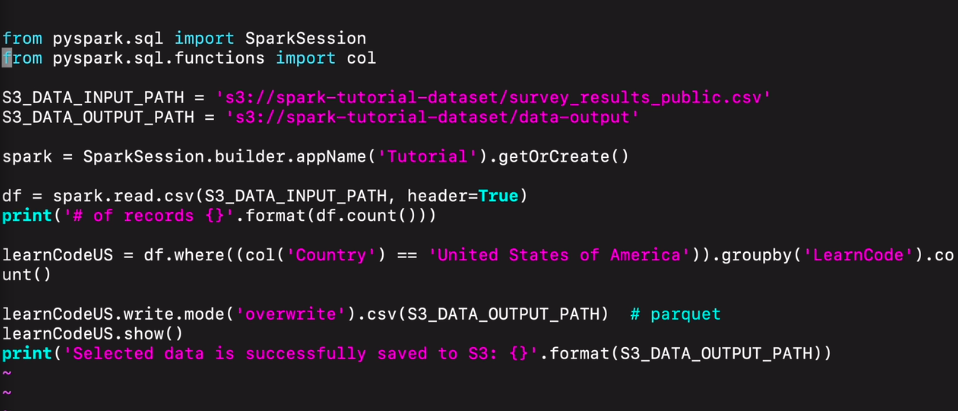
경로를 설정하고,
세션을 생성함.
다음으로 csv를 주어진 경로로 불러들임.
스키마를 찍어볼 수도 있을 것임.
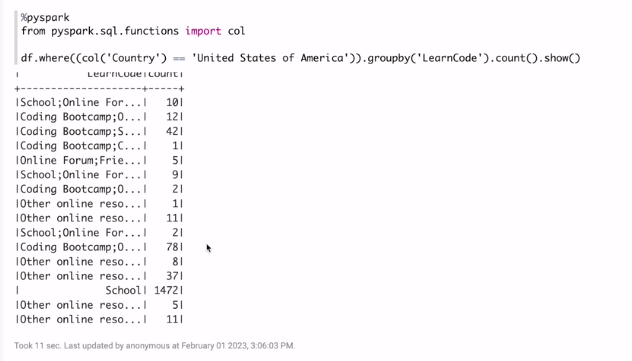
df 가지고 필터링을 함 col함수로 필드 내에 값이 미국인 경우에 learncode로 묶어서 수를 셈.
이걸 csv로 작성, 덮어쓰기함.
그결과를 show
최종적으로 결과가 저장이 됐다고 프린트함.
스파크 서밋으로 이 코드 실행해본다.
spark-summit --master yarn stackoverflow.py
파이썬 스크리브로 지정 후 실행
바쁘게 실행됨
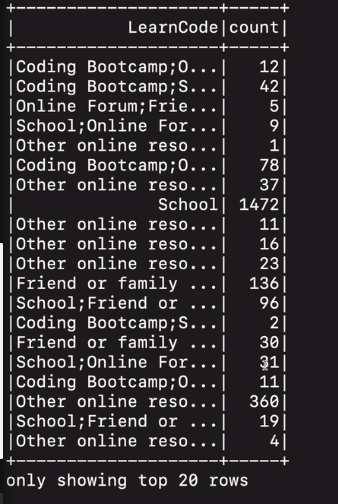
결과가 프린트됨.
프린트 스키마 했던게 있음
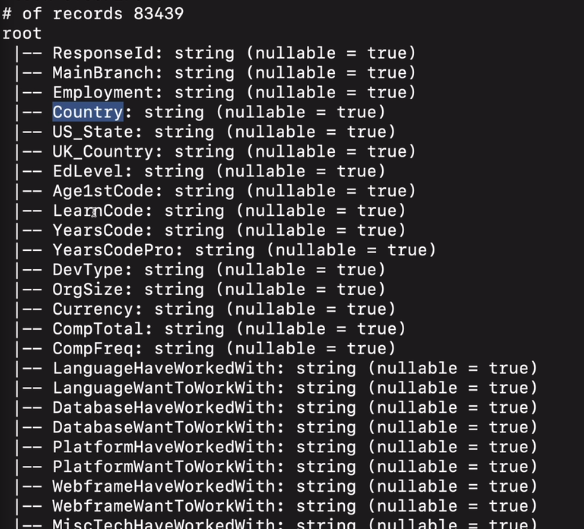
다양한 컬럼들이 있음.
스택오버플로우 데모를 마치고.
웹 UI에서 어떻게 보이나,
앱을 클릭해본다
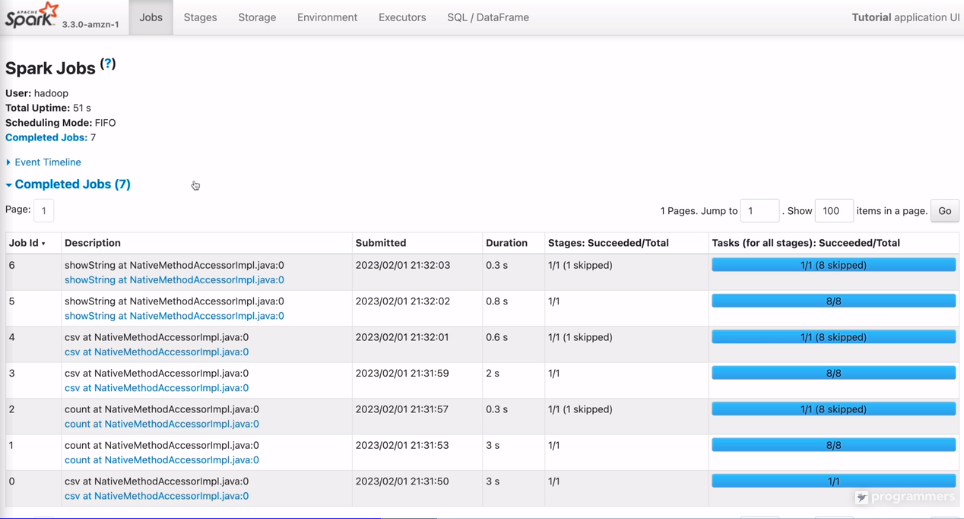
카운팅을 해본 예제는
7개의 잡으로 구성되어 있고
각 잡은 스테이지로 구성되어 있음.
잡을 하나 클릭해본다
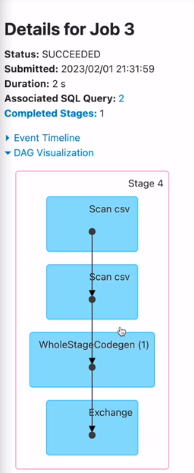
대그의 형태로 스테이지 잡을 구성하는 태스크들이 구성
이게 엑시큐션 플랜 - 고급 때 설명
AWS 클라우드에서 실행키신 클러스터나 동일함. UI는
다만 capacity 차이가 있음
다른 실습을 더 진행함.
다시 터미널로 돌아와
앞에서 만들어본 스택 오버플로우 코드를

코드를 바꿔본다
df.createOrReplaceTempView("stackoverflow")
spark.sql("""
SELECT LearnCode, COUNT(1) count
FROM stackoverflow
WHERE Country = 'United States of Ameriaca'
GROUP BY 1""")
다시 코드를 돌려본다.
show, schema 다 잘 찍혀있음
UI로 돌아와서 마지막에 실행한 걸 클릭
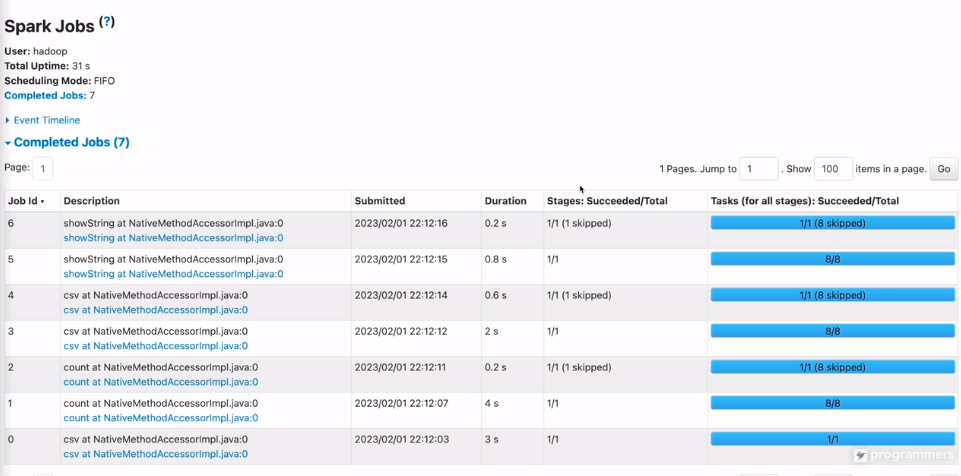
7개 잡
각 잡은 1개의 스테이지
각 스테이지는 1~8개 태스크
재플린 실습
재플린 말고도, 얀에도 노드매니저 등 많은 서비스가 있음. .ssh가 활성화 되어 있어야함
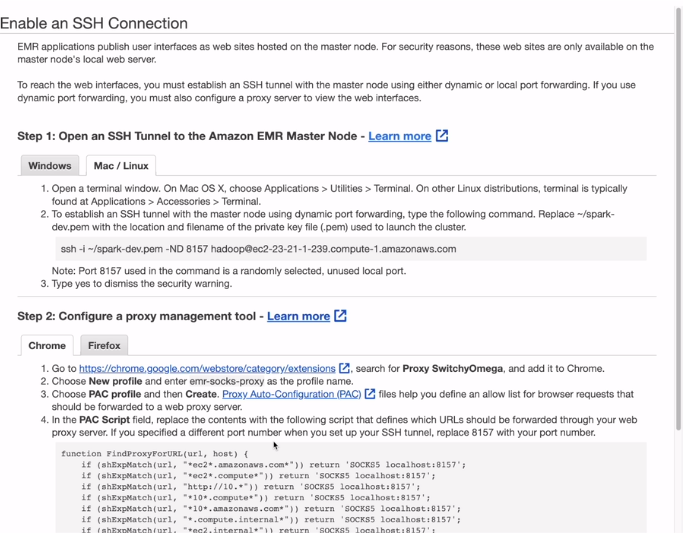
터널링을 해야하고, 크롬이면 익스텐션을 붙여야함.
이러면 재플린 엑세스 가능
맨 아래에 링크가 있음

emr을 론치하면
포트넘버가 조금씩 다름

8890을 사용하면 재플린을 내 브라우저에서 엑세스할 수 있음
터널링, 문서 작업 따름
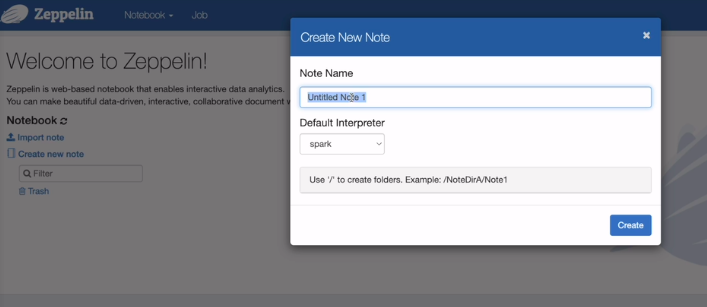
PysparkTest로 생성
%pyspark로 파이썬 쓰겠다고 명시
한번 카운트를 여기서 해본다
여기선 스파크 세션이 자동으로 만들어져 있는 상황임.
df = spark.read.csv('~~~,header=True)
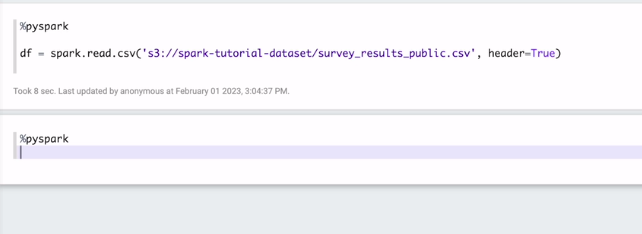
헤더 트루라 레이지 엑시큐션 안됨
스키마를 찍어보면
그룹바이 코드를 가져다가
show를 해본다.
그 전에 col이라는 함수를 임포트 하고 실행

좋은 글 감사합니다 :)