학습주제
학습내용

기존 프로그래밍과 어떻게 다른지, 동작방식을 자바 기준으로 살펴볼 예정.
맵 리듀스 프로그래밍이 동작할수 있도록 시스템이 제공하는 다양한 기능들이 있는데 그 기능들을 조금 더 자세하게 살펴본다.
Spark에도 똑같이 있기 때문
셔플과 솔트
특징
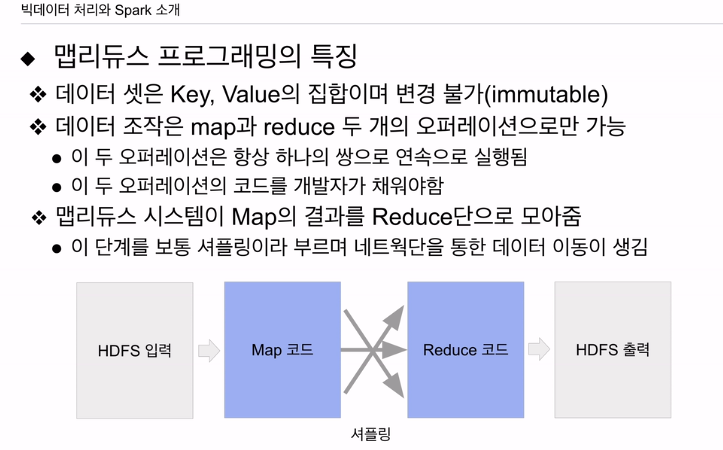
큰 데이터를 처리할 수 있는데 목표를 두고 있음. 데이터 셋의 포맷도 하나로 단순화. 한번 만들어 지면 못 바꿈 변경 불가. 셋을 하나로 고정시켰는데, 맵 리듀스에서 처리할 수 있는 데이터는 키, 밸류 페어임. 키는 말 그대로 하나의 값임. 여러 필드로 하나의 키로 만드려면 concat으로 붙임.
밸류는 하나의 밸류가 있을 수도 있고 없을 수도 있고, 밸류 자체가 리스트일 수도 있음.
데이터 셋 자체는 키 밸류 집합.
오퍼레이션 2개
맵 - 입력으로 들어온 키밸류 페어를 다른 키밸류 페이버 집합, 리스트로 만들어줌. 아웃풋이 없을 수도 있음.
리듀스 - 맵의 출력 중에 같은 키를 갖는 출력들을 모아서 새로운 키 밸류 페어로 만들어줌.
개발자 관점에선 안의 맵과 리듀스 안의 함수를 채워주는 것
맵 입력, 리듀스 입력은 맵리듀스 시스템에서 만들어줌. 모든 데이터 조작은 항상 맵과 리듀스의 쌍으로 이뤄짐. 보통은 맵 리듀스 한번으로 내가 원하는 최종 결과물을 얻지 못하고, 오퍼레이션을 몇번 반복해서 원하는 결과를 얻어내는게 일반적.
다이어그램 보면 입력 데이터가
HDFS에 있어서 입력으로 지정하면 시스템이 입력을 맵 코드에 입력으로 넣어줌. 모든 입력이 키밸류 페어 형태임. 여기까지 시스템, 나는 이 안에 코드를 채워서 시스템이 제공하는 맵의 입력, 키밸류 페어를 보고 원하는 형태의 키밸류 페어, 페어 리스트로 바꾸어줌. 다시 아웃풋을 맵리듀스 시스템이 받아서 맵의 아웃풋 중에 같은 키를 갖는 밸류들만 모아서 리듀스의 입력으로, 키와 밸류의 집합으로 구성됨. 받는 코드를 작성해 새로운 키밸류 코드 내는 작성을 하면, HDFS에 파일로 저장이 됨.
내가 할일은 맵 코드, 리듀스 코드 채우고, HDFS 입력 위치, 저장 위치 지정.
나머지는 시스템이 알아서 해줌. 맵 코드 입력도, 내 코드가 출력한 리스트 출력을 받아 같은 키를 갖는 애들을 리듀스에 넣는것도 시스템, 내가 작성한 코드의 리듀스 출력을 받아서 최종적으로 HDFS에 저장도 시스템. 이런 맵 코드와 리듀스 코드가 하둡에서 태스크 매니저에 의해 동작 (1.0) 2.0은 얀의 노드매니저를 통해 컨테이너가 할당 그 안에서 태스크 형태로 실행됨. 맵의 입력으로 들어가는 데이터의 크기, 파일 수에 따라 맵 코드를 실행하는 태스크의 수가 결정됨. 리듀스 코드를 동작시키는 태스크 수는 개발자가 지정. (하둡의 맹점)
맵의 아웃풋을 받아 같은 키를 받는 밸류들을 묶어서 리듀스 코드로 넣는 과정을 셔플링이라고 함.
맵 코드와 리듀스 코드는 궁극적으로 얀이라면 컨테이너라면 JVM 코드. 어떤 서버에서 돌아가는 코드. 맵이 돌아가는 서버, 리듀스가 돌아가는 서버가 다를 확률이 높음. 맵의 출력이 시스템에 의해 같은 키를 갖는 경우 묶어져서 특정 리듀스가 돌고 있는 서버로 전송이 되어야 함. 이 과정에서 데이터의 크기에 따라 네트워크를 통한 데이터 전송이 굉장히 활발하게 벌어지게 됨. 이때 이런 과정을 셔플링이라고 함.
셔플링으로 이동하는 데이터의 크기가 커진다면 이 과정이 시간을 잡아먹고 프로세싱 비용 증가.
스파크도 이 이슈가 있음. 셔플링 얘기를 다시 할 예정.
맵리듀스 특징은 이렇다.
데이터 셋 자체가 키밸류 포맷 고정. 내용 바뀔 수 없음.
맵 리듀스 오퍼레이션을 연속 실행. 데이터 셋을 한포맷에서 다른 포맷으로 바꿈
맵, 리듀스 코드는 입력은 시스템, 내용은 개발자가
맵 출력을 모아 리듀스 입력으로 넣는건 시스템. 셔플링
셔플링은 네트워크를 통한 데이터 전송 많이 발생. 전송량에 따라 전체 오퍼레이션이 걸리는 시간이 늘어날 수 있다.

맵과 리듀스의 오퍼에대해 설명한다.
맵은 기본적으로 트랜스포메이션임.
출력이 키밸류 리스트, 그대로 나올수도 있음. 내가 원하는 결과에 따라 달라짐.
맵의 입력은 내가 만드는게 아니라, HDFS 입력 파일에서 자동으로 들어감.
스파크를 이해할때 이런 히스토리를 아는게 도움됨. 아주 자세히는 안말함.
맵에서 출력했던 키 밸류 페어를 보고 시스템에서 갖은 키를 갖는 페어를 묶어서 밸류를 하나의 리스트로 묶어서 리듀스에 넣음
입력은 시스템이 만들어줌
맵의 아웃풋을 보고 같은 키를 갖는 밸류들을 보고 시스템이 리스트로 묶어서 넣어주게 됨.
개발자가 키밸류 페어를 만들어주면 됨.
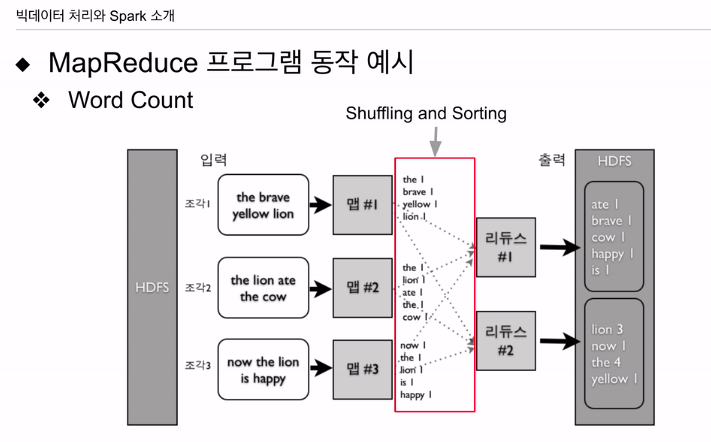
다이어그램으로 알아본다
단어의 수를 알고 싶은 텍스트가 HDFS 파일에 주어졌다고 가정.
맵에 입력으로 주고, 이런식으로 라인 하나씩 텍스트가 들어가게 세팅. 1번 맵에 문장 하나, 2번 맵에 다른 문장 하나, 3번 맵에 또 다른 문장 하나가 입력으로 들어간다. 3개의 태스크가 돌고 있음. 맵에선 새로운 키 밸류 페어를 만든다. the 1, brave 1, yellow 1 처럼 4개의 키 밸류 페어를 출력으로 냈음. 다른 맵도 마찬가지임.
맵의 입력이 키 밸류 페어가 되어야 한다고 했는데, 키인지 벨류인지 하나만 있다. 이 경우 키 값으로 랜덤값을 주고 밸류로 파싱할 텍스트를 주는게 일반적. 맵 관점에서 보면 키밸류 페어가 되고, 이를 파싱해서 단어가 키가 되고 밸류가 1인 식으로 출력해줌. 이런식으로 코드를 짜놓으면 출력을 시스템이 모아서 갖은 키를 갖는 레코드들을 하나의 레코드로 묶어서 리듀스에 넣어줌 리듀스도 서버의 태스크가 됨. 맵, 리듀스가 각 다른 서버에서 돌면 시스템은 네트워크를 통해 전송해줌(셔플링) 다양한 맵에서 나온 결과들이 다수의 리듀스로 보내지면 코드 실행전, 맵 태스크 레코드들을 한 번 묶어줌(소팅) 키 값을 해싱해서, 리듀스의 수로 나머지 연산을 해서, 리듀스에 보내는게 일반적. 특정 리듀스에 데이터가 몰리는 데이터스큐가 발생할 수 있음 빅데이터 시스템의 흔한 이슈. 스파크도 있음.
이에 같은 the 키들을 묶어서 밸류를 묶어줌. 키워드별로 카운드하여 최종 출력. 리듀스 두개면 최종 파일도 2개. 이에 생산성이 높지 않음

매퍼쪽 코드
입력이 주어지면, 100이 키, 밸류는 스트링. 키는 아무값이나,
밸류를 보고 스페이스를 가지고 토큰화, the 1, brave 1, 키 단어, 밸류 카운트의 리스트가 출력으로 나감.
인풋이 비어있는 스트링, 아웃풋도 아무것도 없음.
코드에 map 코드가 있고, 토큰나이저 클래스에 있음. 이는 매퍼에서 계승됨. 하둡에서 제공하는 기본 클래스, 맵 함수를 보면 키, 밸류, 콘텍스트는 헬퍼 파라미터. 밸류를 보고 텍스트로 들어오는 밸류를 스트링 토큰나이저로 만들고, 토큰 하나씩 읽어서 아웃풋으로 단어와 one이라는 카운트를 출력함. context 카운터가 맵퍼의 출력에 사용. write이라는 헬퍼함수를 통해 맵의 아웃풋을 키밸류 형태로 출력. one이란건 위에 만들어놓음 그냥 1이라고 생각해도 되나 IntWritable로 하면 직렬화, 쓰기 쉬운형태의 타입이 됨. 단어별로 값을 1로 세팅해서 출력함.

리듀스 보면 카운트들이 밸류의 리스트로 들어올텐데, 이부분은 항상 다 1이 될것임. 코드 안에선 이 리스트에 들어온 값들을 다 더해 새로운 밸류로 만들고 키는 같은 키를 그대로 출력함. 예를들어 lion에 대해 [1,1,1] 입력으로 주어지면 합산한 3으로 출력시킴.
코드를 보면 reduce 함수도 Reducer에서 계승된 IntSumReducer에 정의
키, 밸류가 정의되어 있는데 벨류는 Iterable타입으로 정의 value 리스트를 루프를 돌면서 값을 합산함. 앞에 마찬가지로 context를 통해 키밸류를 출력함. HDFS 파일로 나가게 됨. 간단하게 워드 카운트를 하는 프로그래밍 코드를 보았음.
나는 굉장히 낯설음.
일단 어떻게 돌아가는지 알겠음
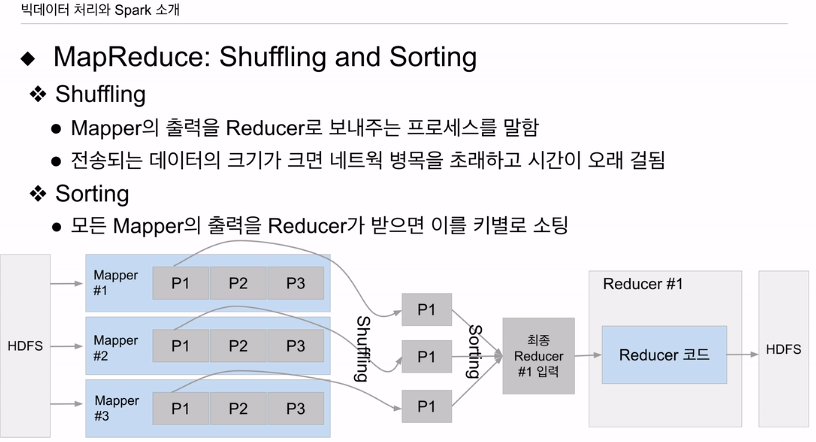
셔플링과 소팅에 대해 알아본다.
스파크가 돌때도 꼭 필요한 과정임
HDFS에 인풋이 있고, 예를들어 3개의 파일로 구성되어 있다, 각 파일별로 맵 태스크가 하나씩 할당이 됨. 파일의 크기에 따라 다르긴 함. 여러개의 블럭이 되어 있다면, 한 블럭 최대 128MB임. 블럭의 수 만큼 매퍼가 생성되게 되어 있음.
입력은 시스템이 주어짐, 코드는 개발자 작성. 코드에 입력 ->출력 키밸류 작성됨. 리듀스의 수에 맞춰 리듀서 어디로 갈건지 시스템이 정리하게됨. 리듀서가 3개가 있다면 각 맵의 출력을 보고 1번 리듀서로 갈 데이터, 2번 리듀서로 갈 데이터 등을 결정함. 맵이 다 끝나면, 입력으로 주어진 키밸류 페어를 다 처리하고 나면 이 리듀서 별로 맵의 출력을 네트워크를 타고 송신을 함. 이 과정을 셔플링이라 함. 맵 2, 3도 끝나면 아웃풋 중에 리듀서 1번으로 갈 것들이 리듀서 서버로 이동할 것임. 이 입력들을 한번 더 머지를 하게 됨. 같은 키끼리 밸류를 묶어줌. 이를 소팅이라고 함. 처리 가능한 리듀서로 송신하는 걸 셔플링. 리듀서에서 입력을 같은 키를 묶어주는건 소팅이라함.
결과는 HDFS에 쓰여짐.
하나의 맵과, 리듀스 코드로 원하는 결과를 얻기가 힘듦. 몇번 돌려서 최종 결과를 얻음.
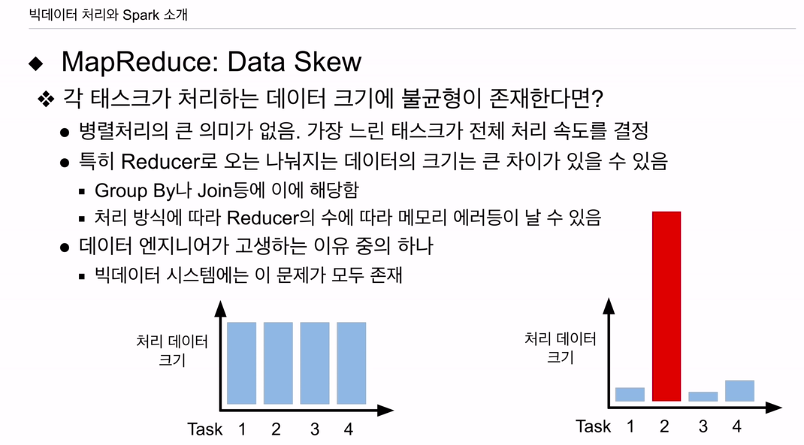
흔히 생기는 데이터 스큐.
맵이건 리듀스건 태스크 처리 데이터가 균등하다면 처리 시간이 비슷하게 걸릴 것임. 병렬처리가 의미가 있어짐. 무슨 이유가 됐건 처리 크기가 불균등, 특정 태스크가 처리해야할 인풋데이터가 훨씬 크다면 문제됨. 나머지는 금방 끝나고, 태스크 2만 오래걸림. 이게 전체 작업의 시간의 결정할 것이기에 병렬처리가 의미가 없음.
시작할 땐 저 인풋 사이즈가 키가 안다름. 근데 리듀서에 넣을 때 키의 분포에 따라 특정 리듀서에 데이터가 확 몰리는 현상 있음. 특정 리듀서의 처리 데이터의 크기가 확 늘어남.
리듀서로 오는 작업은 GROUP BY, JOIN에 대당.
메모리 에러도 있고 여러 이슈 있음.
데이터 엔지니어가 고생하는 가장 흔한 이슈임. 스파크, 하이브나 모든 빅데이터에 있는 이슈

-
작업에 따라 좋은 작업도 있지만 많은 경우 생산성이 떨어짐. 키밸류 하나의 포맷밖에 없기 때문, 데이터 스큐가 생기는 경우 튜닝이나, 최적화가 쉽지 않음.
-
배치작업밖에 지원을 안함. 큰데이터 처리에 초점 맞춰져있음. 얀과 같은 시스템 위에 스파크처럼 유스케이스를 사용하는 경우가 만들어짐

대안들 등장.
배치 말고 스트리밍들 다양한 방법 처리.
범용 리소스 매니저 얀이 만들어짐.
융통성 있는 스파크 시스템 만들어짐.
적어도 구조화 된 데이터 처리엔 SQL 만한게 없다고 다시 떠오름. 하이브, 프레스토가 1.0 땐 맵 리듀스 위에서 구현됐었음. 2.0 부턴 얀 위에서 맵리듀스 상관 없이 돌아감. 둘다 SQL 동작. SQL로 데이터 조작하는 명령어 내리면, 1.0는 맵 리듀스로 동작, 2.0 이후는 얀
태즈라는 시스템?
ETL에 적합 - 하이브
프레스토 - 애드혹으로 빠르게 결과, 속도에 초점.
요즘은 두개가 비슷해짐. 하이브도 adhoc 쿼리 빨리 날릴 수 있게, 메모리를 통한 처리.
프레스토도 etl 하고 싶어서 디스크를 쓰기 시작함.
하이브 - etl
프레스토 - adhoc으로 구분이 요즘은 비슷해짐.
aws 아테나는 프레스토 기반. 옛날 프레스토는 대용량 etl에 쓸 수 없었으나 etl 지원 가능함.
