
강사님 노을에서 근무 중이심. 20년 넘게 데이터 엔지니어하심.
1년차 데이터 엔지니어이신 박진형님
노을에서 진행했던 프로젝트 강의.
작은 회사에서 일어날만한 일들에 대한 공유

네이버 - 성장하는 회사에서의 기회
동료들을 얻으심
스타트업 조인했다가 잘 안됨.
fancy.com 12년부터 full remote 6년 근무 - 미국 스타트업
미국 회사에 대한 환상도 깨지고, 좋은점도 있었음
Studio XID
Noul 디지털 헬스케어. 진단 회사, 소프트웨어 엔지니어, DB 엔지니어

피를 채취해 AI로 분석

데이터팀 구축이 안된 상황에서, 의사결정이 데이터로 안이뤄짐. 목소리 큰 사람이 우세한 경향이 있었음.
데이터 기반의 의사결정이 가능케 하는 환경은 어떻게
성장하는 조직의 문제는? 데이터 관리. 큰 조직이라면 당연히 있어야할께 없는 경우가 많음. 내가 발견한 문제를 개선해 나가는 경험 공유
지식을 가지고 가치를 만들어 내는 경험 공유

하이 리스크, 하이 리턴
어떤 종류의 문제든 사회에서 해결하면 돈 많이 벌 수 있는 아이템
가설 검증, 스케일 업, 기업의 가치를 높임.
해야될게 많음.. 사람은 적고
당연히 있어야할 게 없고, 그럼에도 불구하고 이런걸 했다고?

제조라인도 갖고 있음
소프트웨어 엔지니어가 3명이었음

스타트업은 내가 안해봤더라고 요구하면 학습해서 아웃풋을 내야함
오브젝트 디텍션 AI모델을 만드는게 주 제품
말라리아가 걸렸는지, 걸렸다면 어떤 종류의 말라리아
형태학적 분석
혈구 분석
5종 백혈구 분류. 정상적인지.

꽤 작동을 잘 하는 모델을 갖고 있고 개선 작업 중
ML 엔지니어로써 서포트를 하려고 보니
학습데이터 결과물들이 주로 이미지.
사내 NaS에 저장되어 있고, 이미지들을 트레이닝을 하려면 어노테이션으로 학습데이터.
AI 모르는 사람들이 봤을 때는 개선 정도를 알 수가 없음.
셀의 크롭 이미지만 갖고있고 이의 추적이 되지 않음

NAS 는 iO 쓰루풋이 낮음. 굉장히 오래걸림.
12시간 ~ 24시간이 소요됨
AUC score, PR curve
똑간은 PR curve라도 어느쪽 문제인지 분석 평가하기 어려웠음

어노테이션 만드는 곳에서도 크게 상황이 다르지 않았음
말라리아, 백혈구가 아무나 어노테이션 할 수 있는 상황 아니었음.
자율주행이라면 이미지 안에 사람인지, 자전거인지 쉽게 구분함.
그러나 말라리아 같은경우 굉장히 구분하기 어려움.
잘 훈련된 임상병리사여야만 어노테이션을 할 수 있었음.
각 백혈구 별로도 잘 성숙했는지, 미성숙한 개체가 혈액 안으로 흘러들어왔는지
잘 어노테이션 할 수 있어야 했음. 어노테이터에 따라 달라짐.
효과적으로 데이터를 생산할 수 있는 환경이어야 하는데 그렇지 못함.
다른 결과물 대비해 임상데이터를 관리하는것도
잘 안됨
만들어진 슬라이드도 관리가 안되고 있음.

가지고 있는 데이터가 어떤 특성, 쓸만한게 어느건지, 어느정도 섞여있는지, 알기 어려움
트레이닝에 비해 갖고있는 데이터는 많음. 그럼 거기서 가져올 수 있는가?

데이터 기반이 없으면
회의가 많음. 어떻게 해결해야할까요? 답이 나오질 않음. 그 근거를 뒷받침할만한 데이터, 납득할만한 데이터가 없음. 다음에 얘기합시다. 또는 회의에 참석한 사람 중 목소리가 가장 크거나, 의사결정 권한이 있는 사람이 결정. 그 분의 생각이 바뀌거나, 새로운 데이터를 얻게되면 생각이 바뀜. 영업에서 샘플을 보내서 자체적으로 잠재 고객이신분이 validation. 위음성, 위양성 케이스가 들어옴. 음성인데 너네 장비가 양성. 우리 양성인데 너네가 음성이라했어. 이 한건한건이 임팩트가 크게 느껴짐. 전체 모수에서 통계적 데이터가 없기 때문에 위음성 리포트가 들어오면 특이도가 굉장히 중요해짐. 음성은 음성으로 맞추는거에 갑자기 집중. 얘기가 자꾸 바뀜.

이 문제를 어떻게 해결, 누가 해결, 시키는 일이나 할까

회사에서 문제를 발견했을 때, 이 문제에 대해 아무도 문제삼지 않으면 문제가 되지 않음. 비효율이런걸 조직이 떠안고 가는 경우가 많음
문제는 당연히 혼자 해결할 수 있는 사이즈는 아니었음
상위 조직장에게 문제 공유
데이터 다루는 부서들에게 상태를 공유하고 이것은 해결을 해야되는 문제라는 공감대 형성
이 문제를 주도적으로 해결하겠다. 오너십은 내가 갖되 스폰싱을 해달라는 부탁함
필요한 지원을 받을 수 있다는 약속을 받고 문제해결 시작

변화하려고 하면 변화를 거부하는 조직원이 생기기 마련.
왜 바꾸려고 하냐 하던대로 잘 돌아가는데
조직이 커지면 밥그릇 싸움. 왜 우리꺼에 간섭하냐는 등 투쟁을 만날 수 있음
스타트업의 경우 굉장히 짧은 시간에 적은인력으로 압축적으로 성장하다보니 제대로 안굴러가는 경우가 많음.
완료주의와 완벽주의가 출돌하기 시작
시간과 자원이 한정된 경우 완벽을 추구하면 결국 끝나지 않음.
스타트업은 자금이 마르기 전에 아웃풋을 내야함.
완벽하게 하려다 보면 자금이 말라 회사가 문을 닫는 경우가 많음
강사님도 점진적으로 개선하는 쪽으로 가려고 함.
완벽해야 하는 부분 - 한번 세팅해놓고 결과물이 나오면 바꾸기 어려운 경우. 비가역적인 경우
대부분의 경우. 다시 문제만 해결하면 되는경우가 있어서 일단 완료하는게 좋음

노을에 입사하기 전까진 웹 엔지니어였음
필요 지식, 도구는 없는 상태
회사에서 반년 컨설팅을 따로 받으심

혼자서 할만한 사이즈가 아니었기에 같이 해줄만한 사람 찾음
상황 공유
채용 + 교육

etl 파이프라인에 람다, sqs

문제를 카테고리화 함
데이터가 단일 진실 공급원이 아니었음
분석 환경 개선해야 했음
어노테이션 데이터베이스화 필요
AI에서 만들어진 모델 환경도 개선

데이터를 복사해서 쓰던 상황
원본 소스는 계속해서 업데이트 되는 상황
어느 시점의 스냅샷을 복사해서 연구데이터로 쓰는 상황이었음
날짜로 기록
과거의 데이터를 사본으로 복사, 어디에서 복사했는지 출처를 잘 안달음
카트리지 부서에서 연구임상에서 데이터를 가져왔는데, 원본은 22년 8월, 10일, 11월 리비전이 쌓임.
카트리지 사본은 어디서 왔는지에 대한 출처가 없음
사람이 손으로 데이터를 다루기 때문에 에러
무결성 보장 힘듦
원본소스는 에디딩 지정.
사본 참조를, 참조할 수 있도록 분리
에어플로우 등을 이용해 etl 파이프라인을 만듦.
구글 시트를 뽑아서 etl 데이터 베이스 넣음
필요한건 데이터베이스에서 스프레드 시트에 넣음
가지고 있는 데이터의 소스에 대한 신뢰성 확보

사내 Nas에 저장
디스크 IO 한계, 데이터 분석을 하고 싶다면 사내 access 가능한 서버, 컴퓨터에서만 가능
3달정도 걸려서 S3로 이전
S3 이전되면 이미지 전체를 대상으로 분석이 가능한 환경
AWS에서 이런 작업을 위해 람다 배치 이용
비용이 들긴 함.
어노테이션 때 사람이 개입하다보니 실수할 수 있음
업데이트 주기가 매우 길었음.
라벨 정보를 메타데이터화 시켜 데이터베이스로 만들어 관리함

병렬처리 가능
추론결과를 단계별로 데이터베이스에 저장
다음에 다시 돌리지 않아도 가져다 쓸수 있게 함
이전에 비해 세부적인 분석 가능

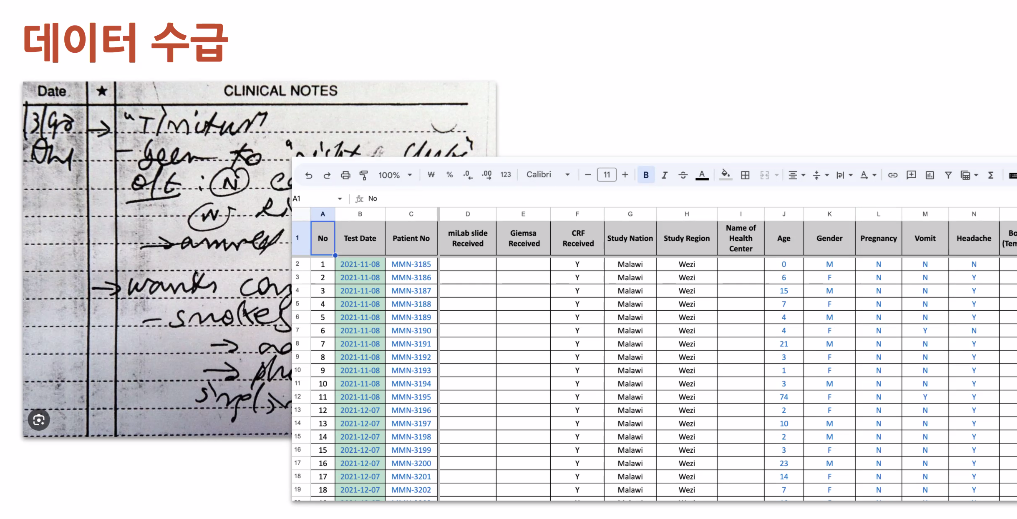
임상데이터의 경우 구글 시트에 손으로 메뉴얼하게 타이핑
나이입력의 경우 숫자로 있음. 당연하게도. int로 타입을 선언해서 가져오려니 에러가 남. 19m, 0.9y 이런식으로 예상하지 못한, 정규화되지 못한 데이터가 입력됨.
증상도 구토, 발열, 오한. 쓰는 사람마다 다른 표현으로 적음. 정규화시키는데 꽤 많은 노력이 들음.
진단 결과가 JSON으로 저장되는데, JSON 포맷이 히스토리가 있음
말라리아 진단결과가 지금은 Nagitve, Positive인데, 이전엔 suspected, PT, 1,0 데이터도 있음.
연구자들이 카트리지를 재사용하고 그 위에 글라스만 바꾸면서 테스트해버림. 같은 ID가 생산되는 상황이 있었음.
그중 하나가 AI 트레이닝 데이터로 들어가는 상황이 있었음
데이터베이스 구축
대시보드로 만들고


조직 문해력 향상
슬랙에 공유

예: 말라리야 양성 셀 카운트 도구화

대부분은 SQL 쓸줄 모름

휴먼 에러, 비정규화
현지 NaS에 있는 이미지를 항공운송으로 받고 있었음
운송 도중 디스크 파손 경우
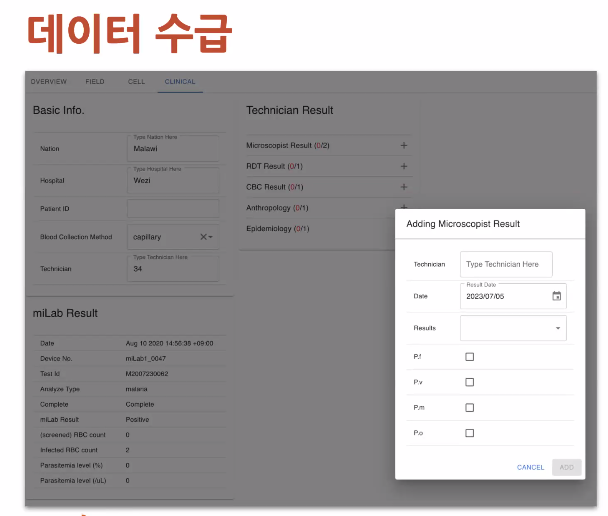
현지에서 더이상 손으로 작성하지 않고, 입력 폼을 구현해 입력단계에서부터 정규화가 가능하게 함. 현지에 적용함
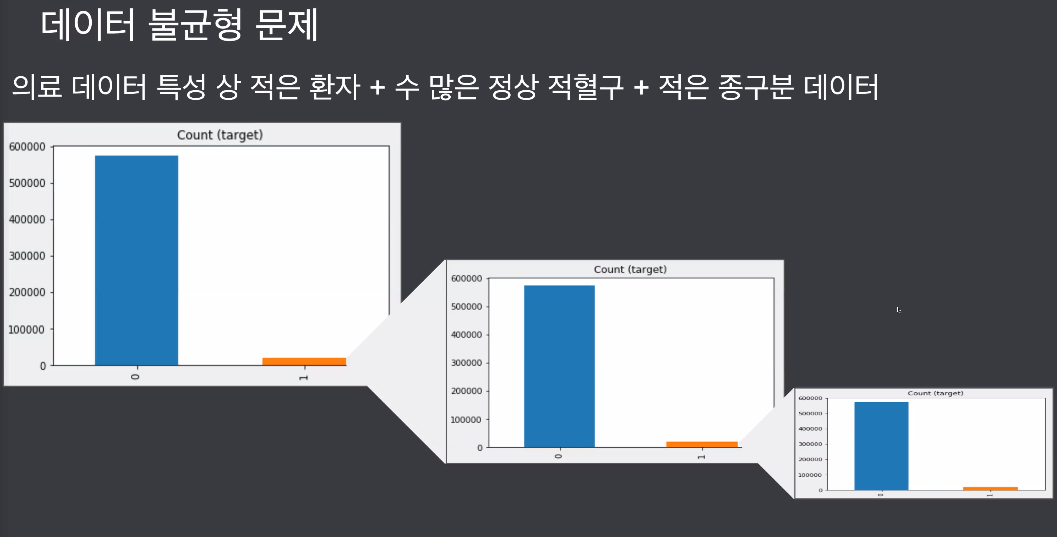
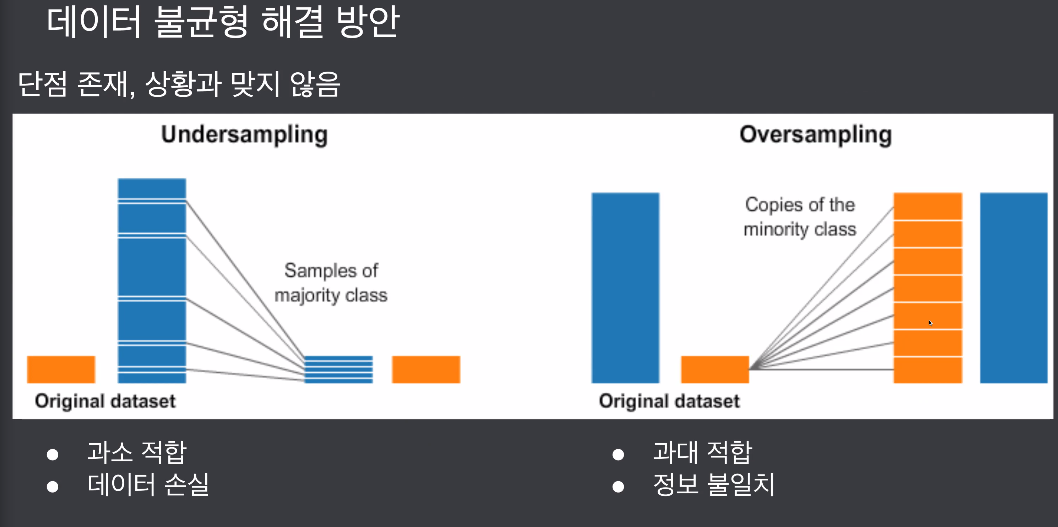
현업에선 사용하기 힘든 기법, 정합성 문제도 있고 단점이 많음
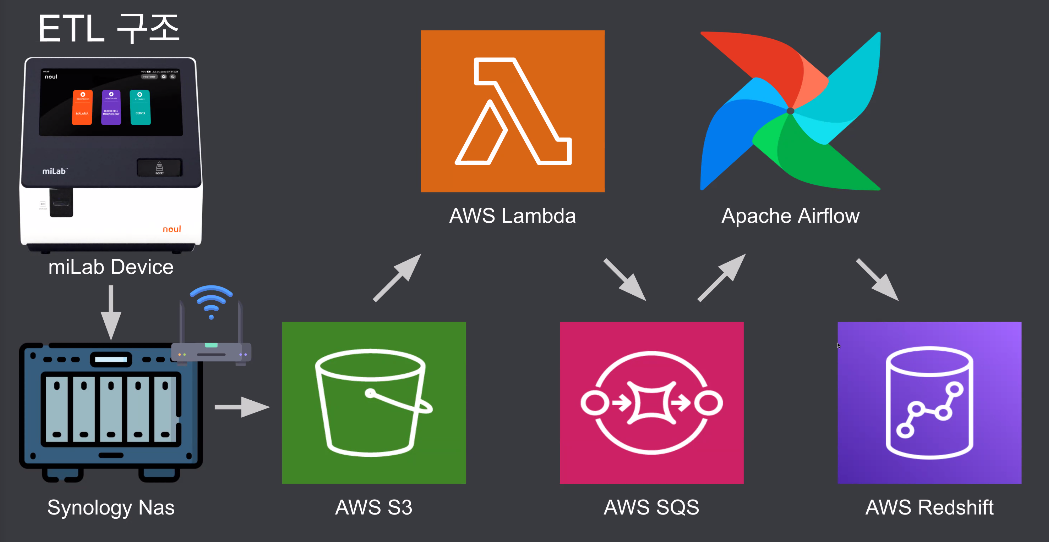
NaS 자체를 스토리지로 일단 사용
S3로 이동하는 모듈을 붙이고
정형만 에어플로우
이미지는 바로 s3
디바이스 - Nas 설치

디바이스 NaS에 VPN 원격접속 가능케 함
현지 인터넷 통신사 확인

도착해서 짐 다뺏김
에티오피아 악명 높음. 세금메기는 과정
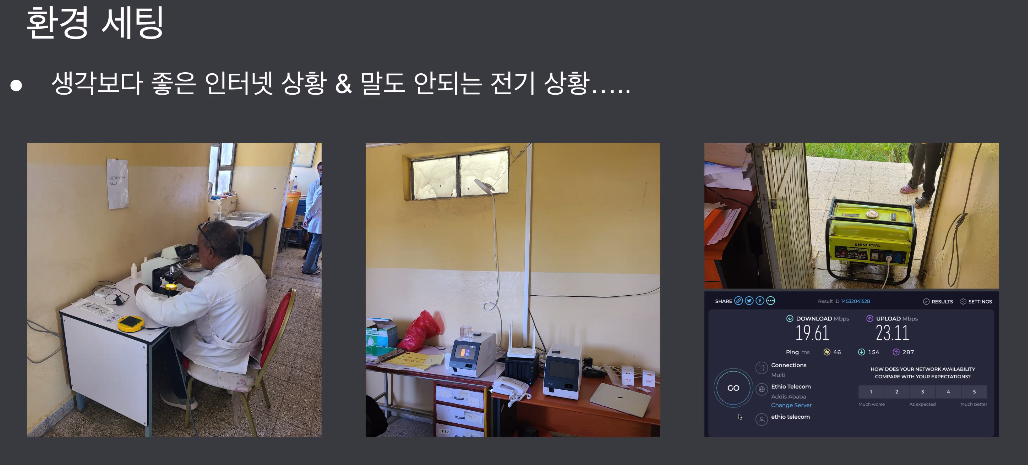
LTE되는 상황, 전기가 매우 안좋음
사실상 보조배터리

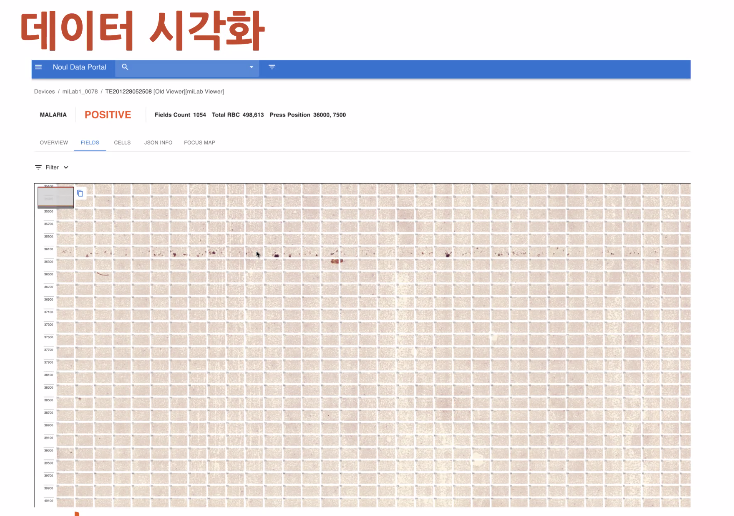
카트리지 개발부서에서 전체 슬라이드 이미지를 보고싶어함
아무도 필드(한개 이미지)를 붙여서 볼 생각을 안함
의외로 그럴듯하게 전체 경향성을 볼 수 있는 데이터가 생성됨

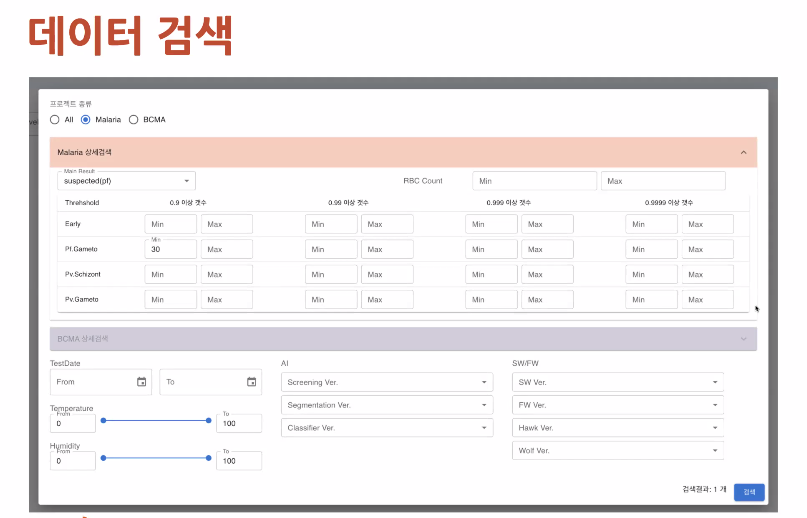
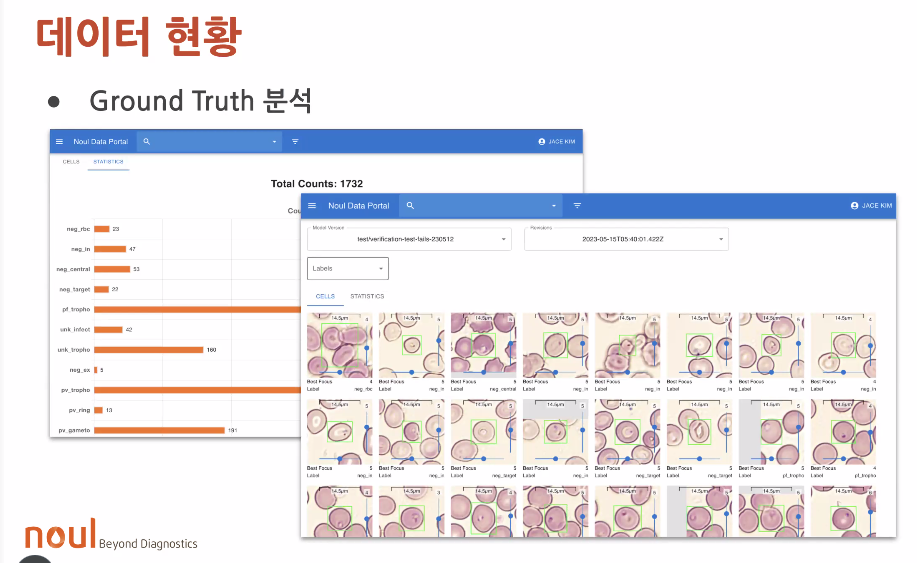
트레이닝 데이터에 대한 현황 파악이 어려웠음
이미지 데이터를 확인하긴 어려웠음
눈으로 확인하고 검수할 수 있게 함
외부 어노테이션 툴을 쓰지 않게 됨. 전, 후처리 비용 아낌.
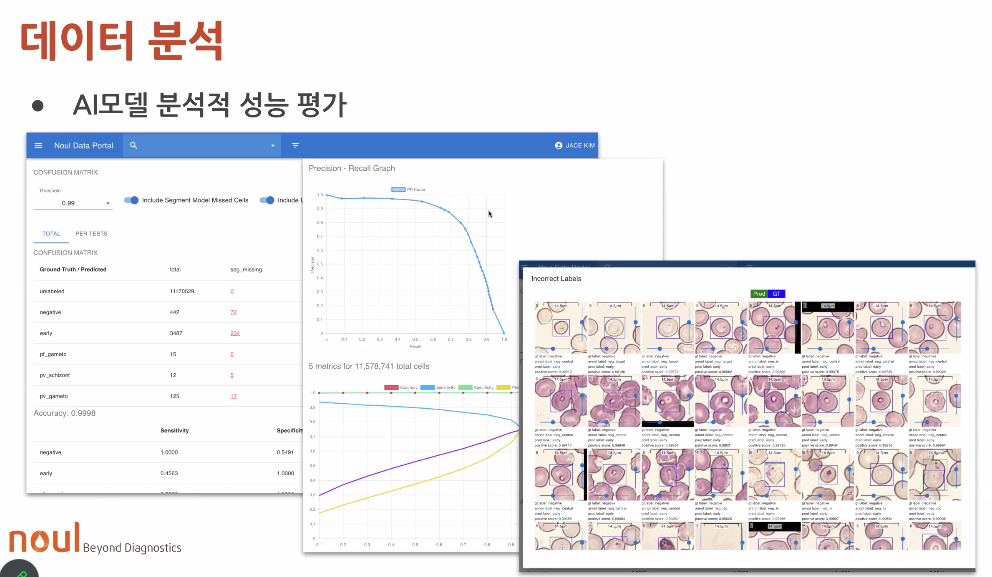
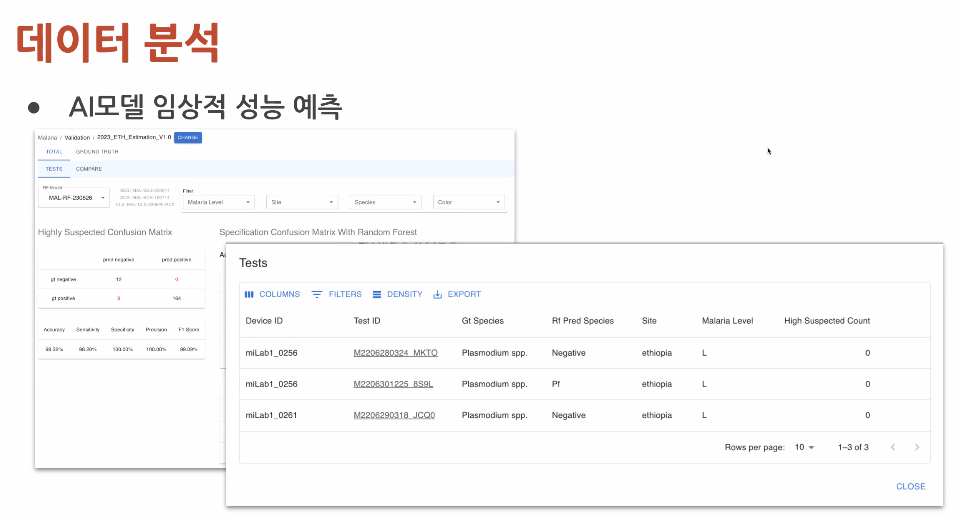

모델 1개월 1개 -> 며칠에 하나 개발로 개선



주니어들은 스스로 보여주고 싶어하기에 끙끙거리며 질문을 안하는 경향이 있는데
질문을 많이 할수록, 좋음
내가 모은 데이터를 웹으로 구현하는 기술도 있으면 좋음
쉘
S3에서 조건에 맞는 데이터를 땡겨와서
파이프라인 이용해 후처리
쉘환경에서 VM, AWS CLI
데이터 - AWS 람다로 리소스 분산
데이터 엔지니어라는 직무가, 회사입장에서 채용시 요구하는 일이 매우 다름
데이터 엔지니어라고 잡 오픈,
ML 엔지니어 잡 오픈
근데 하는일은 똑같은 경우가 많음.
회사가 작을수록 요구하는게 많을 수 있음
데이터엔지니어 + 웹개발 하는 중임
scope를 너무 좁히지 말자. 많은쪽으로 생각.
배우고 익히는게 부담이 된다면 환경을 좁혀서 찾아야함.
데이터 엔지니어링으로 들어왔지만 웹개발도 같이 학습하는 중
