주제
공공데이터 기상청 단기 예보 시각화
1일차에는 절차 작성 및 역할 분담
https://www.figma.com/file/30XvvJD7L4g7YENlwLnMuZ/Team05_-airflow?type=whiteboard&node-id=0-1&t=v7dthsbFx2NZuGT8-0
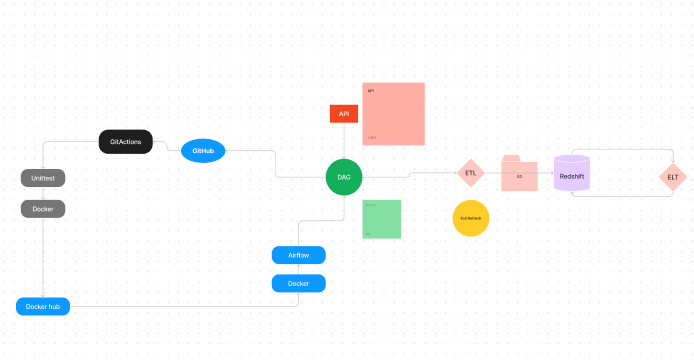
절차는
- airflow를 통해 dags 작성하여 ETL 수행. (redshift 적재)
- git action을 통한 CI. (flake8 사용)
- CI종료 후, git action을 통해 도커 허브로 CD 수행.
- Superset으로 시각화 대시보드 구현.
- 추가 기능 구현
- 보고서, PPT 작성
ETL 작성
공공데이터 API
https://www.data.go.kr/data/15043494/fileData.do
에서 단기 예보 데이터를 얻기로 함.

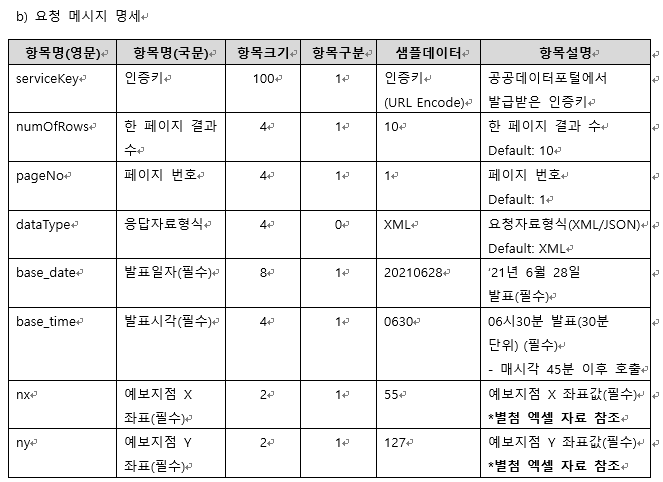
핵심 내용으로 날짜, 시간, 좌표를 입력하면 + 6시간 까지의 일기를 예보해줌.
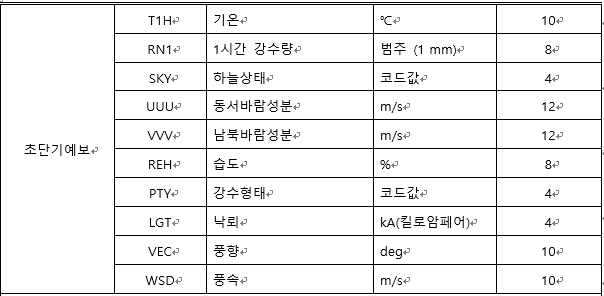
초단기예보의 경우, 기온, 강수량, 습도, 풍속 등이 있다.
우선 Redshift 적재를 위해 기온만 적재해보기로 한다.
url = weather_url
params ={'serviceKey' : api_key, 'pageNo' : '1', 'numOfRows' : '1000', 'dataType' : 'JSON', 'base_date' : base_date, 'base_time' : base_time, 'nx' : '55', 'ny' : '127' }
response = requests.get(url, params=params, timeout=30)
data = json.loads(response.content)
ret =[]
if data['response']['header']['resultCode'] == '00':
data = data['response'].get('body',"")['items']['item']
for d in data:
day = datetime.strptime(d["baseDate"]+d["fcstTime"],'%Y%m%d%H%M')
if d["category"] == 'T1H':
ret.append("('{}', {})".format(day, d["fcstValue"]))
print(ret) etl 함수를 구현하여 외부로 부터 인자를 받음.
airflow Variable을 이용하여 API_Key 등을 은닉함.
JSON 형태로 반환되며,
값이 없는 경우 resultCode == '10', 값이 있을 경우 resultCode ='00'을 반환함.
이에 딕셔너리의 경우 없는 값에 접근할 경우 에러가 나기에 이를 방지함.
내부적으로 카테고리에 따라 다양한 값이 있어 for문으로 원하는 값만 ret에 적재.
redshift_connection은 airflow의 connection을 이용하여 미리 구현해놓고 연결하였음.
def get_Redshift_connection():
# autocommit is False by default
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
return hook.get_conn().cursor()데이터 적재의 경우, 일기예보 특성상 예보 시간에 가까울 경우 정확도가 높아지기에 새로운 데이터가 기존의 데이터를 대체하는 Incremental Update 사용함. 중간에 트랜잭션을 사용하여 ACID를 보장하고, SQL문을 멱등성을 보장하도록 설계.
- 최초 원본 테이블 생성.
- 임시테이블에 원본테이블 값 복사
- 임시테이블에 새로운 값 복사
- ROW_NUMBER로 최신 값 대체
- 본 테이블 적재
cur = get_Redshift_connection()
# 원본 테이블이 없다면 생성
create_table_sql = f"""CREATE TABLE IF NOT EXISTS {schema}.{table} (
date timestamp,
temp int,
created_date timestamp default GETDATE()
);"""
logging.info(create_table_sql)
# 임시 테이블 생성
create_t_sql = f"""CREATE TEMP TABLE t AS SELECT * FROM {schema}.{table};"""
logging.info(create_t_sql)
try:
cur.execute(create_table_sql)
cur.execute(create_t_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
# 임시 테이블 데이터 입력
if ret:
insert_sql = f"INSERT INTO t VALUES " + ",".join(ret)
logging.info(insert_sql)
try:
cur.execute(insert_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
# 기존 테이블 대체
alter_sql = f"""DELETE FROM {schema}.{table};
INSERT INTO {schema}.{table}
SELECT date, temp FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY date ORDER BY created_date DESC) seq
FROM t
)
WHERE seq = 1;"""
logging.info(alter_sql)
try:
cur.execute(alter_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
1회 적재가 되는 것을 확인하여, 이제 백필이 가능하게 하기위해 {{ execution_date }}를 사용하기로 함.
{{ execution_date }}는 전역변수로 내부 함수 etl에서 인식하지 못하였음. 또한 인자로 바로 넘겨주려고 해도 인식하지 못하여, @task 데코레이터 대신 PythonOperator를 사용하여 args에 넘겨줌. jinja 템플릿이라고도 하며, 겉에 ''로 감싸줌. {{ ds }}의 경우 타임스탬프 UTC 형식을 년-월-일 형식으로 바꾼 유사성이 있음. 그러나 이번엔 ROW_NUMBER()의 그룹 기준이 시,분이 되기에 그대로 execution_date 사용함.
이는 바로 datetime으로 사용할수 없고 형 변환을 거쳐야 함.
execution_date = datetime.fromisoformat(execution_date.replace("Z", "+00:00"))
base_date = execution_date.strftime('%Y%m%d')
base_time = execution_date.strftime('%H%M')그 후 날짜와, 시간을 분리하여 넣어줌. 마지막으로 DAG와 오퍼레이터 구성. 시작 날짜는 6월 27이고, 스케줄을 보면 0시에 시작한다고 되어 있음. 그럼 처음 가져올 데이터는 27일 0시가 되고 실행은 27일 1시에 이뤄짐. 만일 27일 매일 1시마다 실행이라면 최초 실행은 28일 1시에 실행함.
오퍼레이터의 경우 PythonOperator를 사용, etl 함수를 호출하고, 인자를 키, 밸류 형식으로 넘겨줌.
마지막으로 태스크 수행 순서 명시.
dag = DAG(
dag_id = 'Project_Weather',
start_date = datetime(2023,6,27), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 * * * *', # 적당히 조절
max_active_runs = 1,
catchup = True,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
etl_task = PythonOperator(
task_id='etl_task',
python_callable=etl,
op_kwargs={'schema': 'kjw9684k', 'table': 'project_weather', 'execution_date': '{{ execution_date }}',
'api_key': Variable.get("project_weather_api_key"),'weather_url': Variable.get("project_weather_url"),},
dag=dag
)
etl_task
CI/CD
깃허브에 대그의 변동사항을 확인하기 위해 적재 시도.

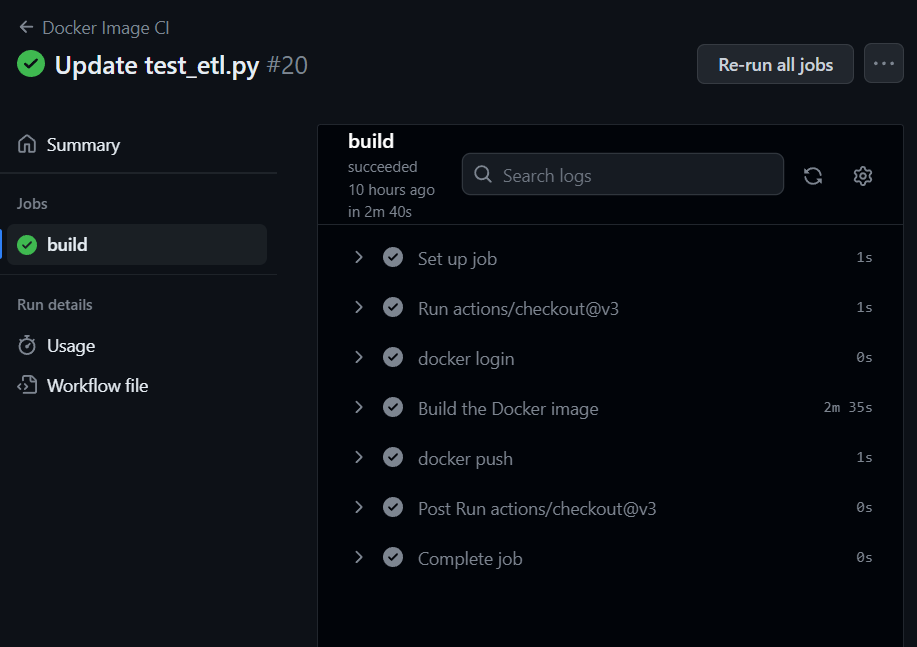
name: Docker Image CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: docker login
env:
DOCKER_USER: ${{secrets.DOCKER_USER}}
DOCKER_PASSWORD: ${{secrets.DOCKER_PASSWORD}}
run: |
docker login -u $DOCKER_USER -p $DOCKER_PASSWORD
- name: Build the Docker image
run: docker-compose build
- name: docker push
run: docker-compose pushdocker compose를 사용하여 build, push
push의 경우, 네임스페이스/이미지이름 으로 yml에서 지정해주지 않아서 그런지 따로 push 기록이 없음.
테스트 코드의 경우,
API 호출, 에어플로우 환경에서 대그를 직접 구현해야 하는지?
그렇다면 깃 액션에서 airflow 설치해서 돌려야하는지 잘 모르겠음.
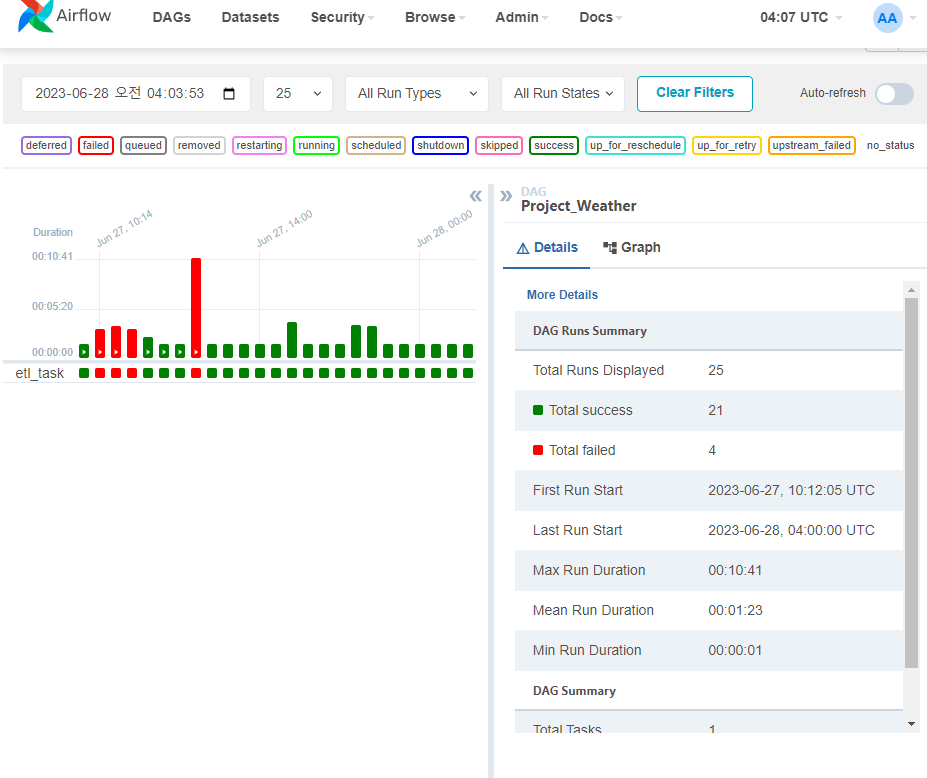
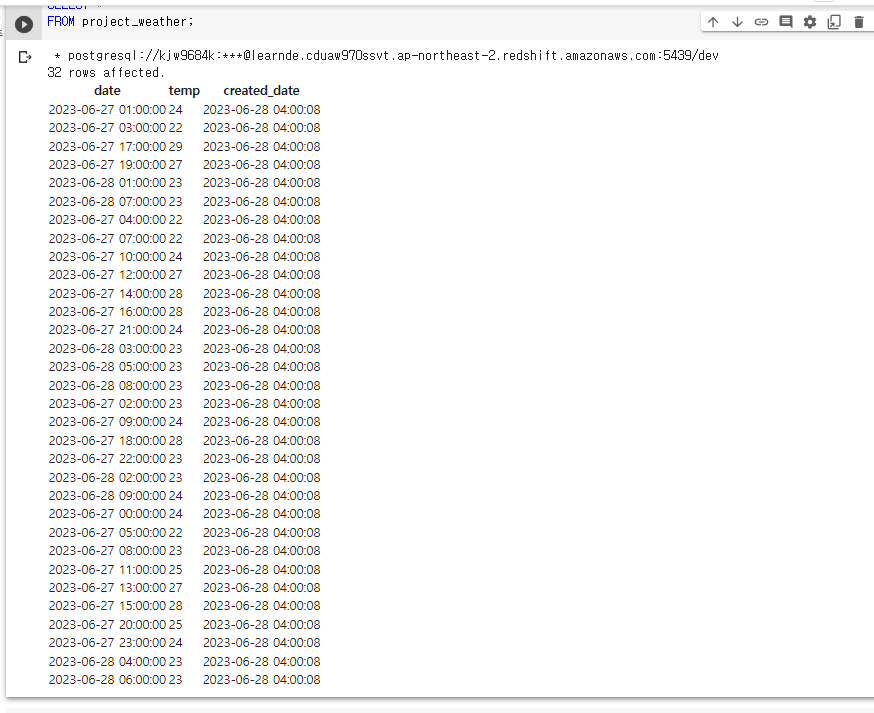
데이터는 어제 밤 사이 잘 적재되는 중.
적재할 데이터를 더 늘려보자. -> 대시보드 시각화를 더 풍부하게 하기 위해서.
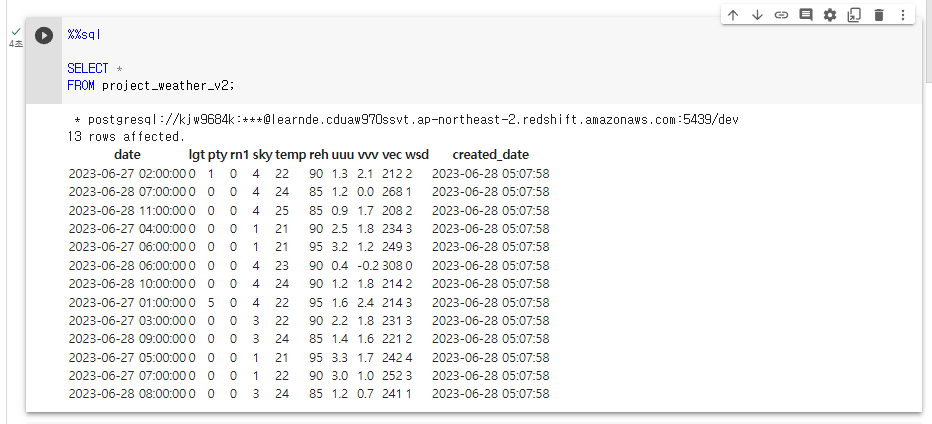
성공함.
from airflow import DAG
from airflow.decorators import task
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.operators.python import PythonOperator
from collections import defaultdict
from datetime import datetime
from datetime import timedelta
import requests
import logging
import json
def get_Redshift_connection():
# autocommit is False by default
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
return hook.get_conn().cursor()
def etl(schema, table, execution_date, api_key, weather_url):
# `execution_date`를 datetime 객체로 변환합니다.
logging.info(f"execution_date: {execution_date}")
execution_date = datetime.fromisoformat(execution_date.replace("Z", "+00:00"))
# 년월일 스트링으로 변환합니다.
base_date = execution_date.strftime('%Y%m%d')
# 시분 스트링으로 변환합니다.
base_time = execution_date.strftime('%H%M')
logging.info(f"base_date: {base_date}")
logging.info(f"base_time: {base_time}")
url = weather_url
params ={'serviceKey' : api_key, 'pageNo' : '1', 'numOfRows' : '1000', 'dataType' : 'JSON', 'base_date' : base_date, 'base_time' : base_time, 'nx' : '55', 'ny' : '127' }
response = requests.get(url, params=params, timeout=30)
data = json.loads(response.content)
ret =[]
if data['response']['header']['resultCode'] == '00':
data = data['response'].get('body',"")['items']['item']
# LGT, PTY, RN1(강수없음), SKY, T1H, REH, UUU, VVV, VEC, WSD
data_dict = defaultdict(dict)
for d in data:
day = datetime.strptime(d["baseDate"]+d["fcstTime"],'%Y%m%d%H%M')
if d['fcstValue'] == '강수없음':
data_dict[day][d['category']] = '0'
else:
data_dict[day][d['category']] = d['fcstValue']
# 딕셔너리를 리스트로 변환합니다.
data_list = [(k,) + tuple(v.values()) for k, v in data_dict.items()]
ret = [f"('{dt.strftime('%Y-%m-%d %H:%M:%S')}', {rest[0]}, {rest[1]}, {rest[2]}, {rest[3]}, {rest[4]}, {rest[5]}, {rest[6]}, {rest[7]}, {rest[8]}, {rest[9]})" for dt, *rest in data_list]
print(ret)
logging.info(f"ret: {ret}")
cur = get_Redshift_connection()
# 원본 테이블이 없다면 생성
# LGT, PTY, RN1, SKY, T1H, REH, UUU, VVV, VEC, WSD
# ('2023-06-28 07:00:00', 0, 0, 0, 4, 23, 85, 0.3, 0.1, 254, 0)
create_table_sql = f"""CREATE TABLE IF NOT EXISTS {schema}.{table} (
date timestamp,
LGT int,
PTY int,
RN1 int,
SKY int,
TEMP int,
REH int,
UUU float,
VVV float,
VEC int,
WSD int,
created_date timestamp default GETDATE()
);"""
logging.info(create_table_sql)
# 임시 테이블 생성
create_t_sql = f"""CREATE TEMP TABLE t AS SELECT * FROM {schema}.{table};"""
logging.info(create_t_sql)
try:
cur.execute(create_table_sql)
cur.execute(create_t_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
# 임시 테이블 데이터 입력
if ret:
insert_sql = f"INSERT INTO t VALUES " + ",".join(ret)
logging.info(insert_sql)
try:
cur.execute(insert_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise
# 기존 테이블 대체
# date, LGT, PTY, RN1, SKY, TEMP, REH, UUU, VVV, VEC, WSD
alter_sql = f"""DELETE FROM {schema}.{table};
INSERT INTO {schema}.{table}
SELECT date, LGT, PTY, RN1, SKY, TEMP, REH, UUU, VVV, VEC, WSD FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY date ORDER BY created_date DESC) seq
FROM t
)
WHERE seq = 1;"""
logging.info(alter_sql)
try:
cur.execute(alter_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raise시각화
superset을 도커에 이미지를 빌드하여 실행하였다.
웹에 띄우는 것 까지 성공하였으나, 로그인하면 airflow가 로그아웃 되는 현상 발생.
Superset과 Airflow가 동시에 로그아웃되는 현상은 두 애플리케이션이 같은 인증 세션을 공유하거나, 같은 쿠키를 사용하고 있어서 발생하는 문제일 가능성이 높습니다.
현재로는 잘 모르기에, 일단 superset 부터 다뤄본다.
적재 오류
3일차
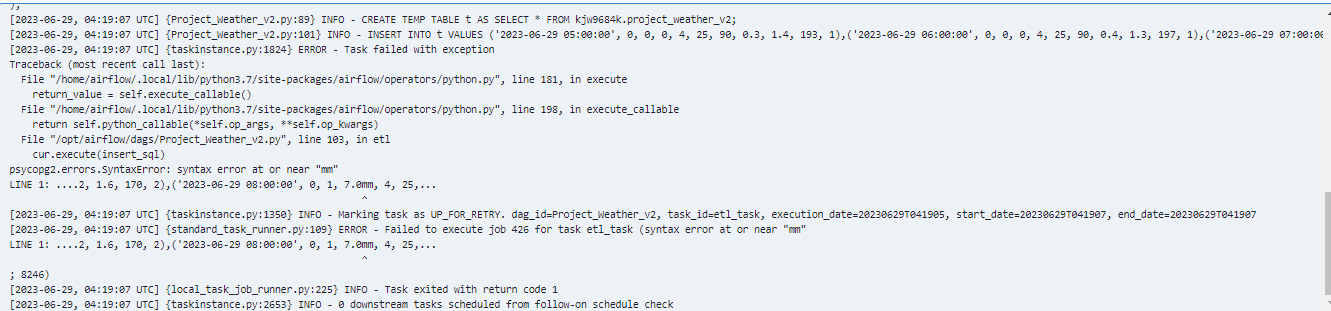
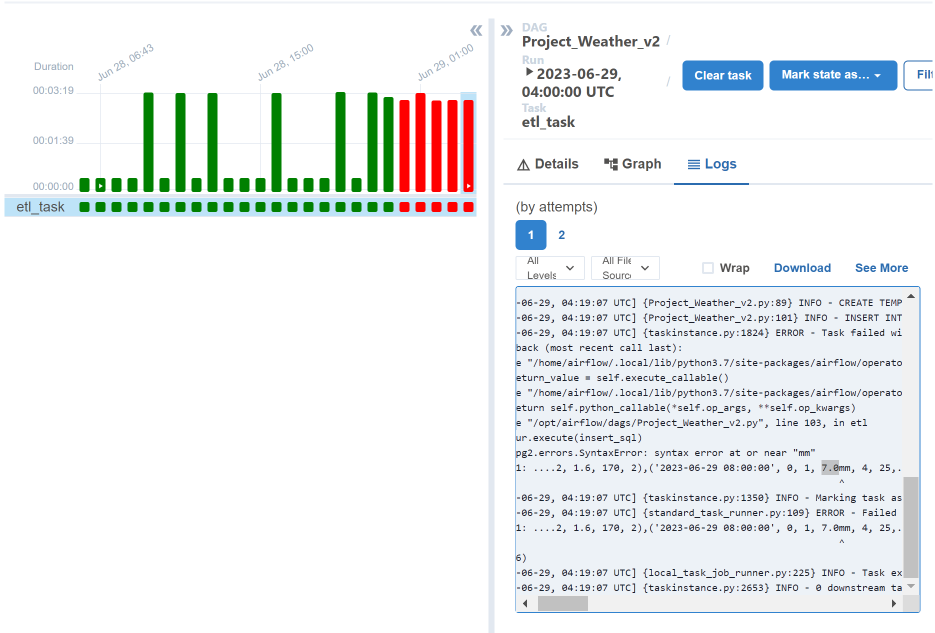
R1N 값이 변함.
기상청 데이터 소스 값이 변함. 뒤에 mm을 붙어서 '0' -> '0mm'으로 변함.
레드쉬프트에서 R1N의 데이터 형은 int고, 현재 들어오는 값은 float임.
이에 임시테이블을 만들어서 데이터를 받은 뒤,
다시 적재하고, 넣어보기로 한다.
for d in data:
day = datetime.strptime(d["baseDate"]+d["fcstTime"],'%Y%m%d%H%M')
if d['category'] == 'RN1' and d['fcstValue'].endswith('mm'):
# 'mm'를 제거하고 float형으로 변환하여 저장합니다.
data_dict[day][d['category']] = float(d['fcstValue'].replace('mm', ''))
elif d['fcstValue'] == '강수없음':
data_dict[day][d['category']] = '0'
else:
data_dict[day][d['category']] = d['fcstValue']
컬럼을 만지는 방법으로 rn1 데이터 형을 바꾸었고, 그랬더니 순서가 변해 데이터 삽입이 안되는 상황.
바꾸니까 백필 성공함.
